Una guida per gestire variabili categoriche in Python.
A guide for managing categorical variables in Python.
Guida su come approcciare le variabili categoriche per scopi di machine learning e data science

Gestire le variabili categoriche in un progetto di data science o machine learning non è un compito facile. Questo tipo di lavoro richiede una profonda conoscenza del campo di applicazione e una vasta comprensione delle molteplici metodologie disponibili.
Per questo motivo, il presente articolo si concentrerà su spiegare i seguenti concetti
- cosa sono le variabili categoriche e come dividerle nei diversi tipi
- come convertirle in valori numerici in base al loro tipo
- strumenti e tecnologie per la loro gestione principalmente usando Sklearn
Una corretta gestione delle variabili categoriche può migliorare notevolmente il risultato del nostro modello predittivo o analisi. Infatti, la maggior parte delle informazioni rilevanti per apprendere e comprendere i dati potrebbe essere contenuta nelle variabili categoriche disponibili.
Basta pensare ai dati tabulari, suddivisi in base alla variabile sesso o a un certo colore. Queste suddivisioni, in base al numero di categorie, possono evidenziare differenze significative tra i gruppi e che possono informare l’analista o l’algoritmo di apprendimento.
- Le Soft Skills necessarie per avere successo come Data Scientist.
- Test Bootstrap per Principianti
- Il Docker Compose di ETL Meerschaum Compose
Iniziamo definendo cosa sono e come possono presentarsi.
Definizione di variabile categorica
Le variabili categoriche sono un tipo di variabile utilizzato in statistica e data science per rappresentare dati qualitativi o nominali. Queste variabili possono essere definite come una classe o categoria di dati che non possono essere quantificati continuamente, ma solo discretamente.
Ad esempio, un esempio di variabile categorica potrebbe essere il colore degli occhi di una persona, che può essere blu, verde o marrone.
La maggior parte dei modelli di apprendimento non funziona con i dati in formato categorico. Dobbiamo prima convertirli in formato numerico in modo che l’informazione sia preservata.
Le variabili categoriche possono essere classificate in due tipi:
- Nominale
- Ordinale
Le variabili nominali sono variabili che non sono vincolate da un ordine preciso. Il sesso, il colore o i marchi sono esempi di variabili nominali poiché non sono ordinabili.
Le variabili ordinali sono invece variabili categoriche divise in livelli logicamente ordinabili. Una colonna in un dataset che consiste in livelli come Primo, Secondo e Terzo può essere considerata una variabile categorica ordinale.
Puoi approfondire la suddivisione delle variabili categoriche considerando variabili binarie e cicliche.
Una variabile binaria è semplice da capire: è una variabile categorica che può assumere solo due valori.
Una variabile ciclica, invece, è caratterizzata dalla ripetizione dei suoi valori. Ad esempio, i giorni della settimana sono ciclici, così come le stagioni.
Come trasformare le variabili categoriche
Ora che abbiamo definito cosa sono le variabili categoriche e come appaiono, affrontiamo la questione della loro trasformazione usando un esempio pratico – un dataset Kaggle chiamato “cat-in-the-dat”.
Il dataset
Si tratta di un dataset open source alla base di una competizione introduttiva alla gestione e modellizzazione di variabili categoriche, chiamata Categorical Feature Encoding Challenge II. Puoi scaricare i dati direttamente dal link sottostante.
Categorical Feature Encoding Challenge II
Classificazione binaria, con ogni caratteristica una categoria (e interazioni!)
www.kaggle.com
La particolarità di questo dataset è che contiene esclusivamente dati categorici. Quindi diventa il caso d’uso perfetto per questa guida. Include variabili nominali, ordinali, cicliche e binarie.
Vedremo le tecniche per trasformare ogni variabile in un formato utilizzabile da un modello di apprendimento.
Il dataset si presenta così
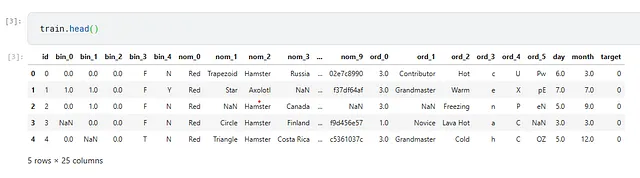
Dato che la variabile obiettivo può assumere solo due valori, si tratta di un compito di classificazione binaria. Utilizzeremo la metrica AUC per valutare il nostro modello.
Ora applicheremo tecniche per gestire le variabili categorical usando il dataset menzionato.
1. Codifica Label (mappatura su un numero arbitrario)
La tecnica più semplice per convertire una categoria in un formato utilizzabile è assegnare ad ogni categoria un numero arbitrario.
Prendiamo ad esempio la colonna ord_2 che contiene le categorie
array(['Hot', 'Warm', 'Freezing', 'Lava Hot', 'Cold', 'Boiling Hot', nan], dtype=object)La mappatura potrebbe essere fatta in questo modo utilizzando Python e Pandas:
df_train = train.copy()mapping = { "Cold": 0, "Hot": 1, "Lava Hot": 2, "Boiling Hot": 3, "Freezing": 4, "Warm": 5}df_train["ord_2"].map(mapping)>> 0 1.01 5.02 4.03 2.04 0.0 ... 599995 4.0599996 3.0599997 4.0599998 5.0599999 3.0Name: ord_2, Length: 600000, dtype: float64Tuttavia, questo metodo ha un problema: devi dichiarare manualmente la mappatura. Per un piccolo numero di categorie questo non è un problema, ma per un grande numero potrebbe esserlo.
Per questo useremo Scikit-Learn e l’oggetto LabelEncoder per ottenere lo stesso risultato in modo più flessibile.
from sklearn import preprocessing# gestiamo i valori mancanti df_train["ord_2"].fillna("NONE", inplace=True)# inizializziamo l'encoder di Scikitlear le = preprocessing.LabelEncoder()# fit + transformdf_train["ord_2"] = le.fit_transform(df_train["ord_2"])df_train["ord_2"]>>0 31 62 23 44 1 ..599995 2599996 0599997 2599998 6599999 0Name: ord_2, Length: 600000, dtype: int64La mappatura è controllata da Sklearn. Possiamo visualizzarla in questo modo:
mapping = {label: index for index, label in enumerate(le.classes_)}mapping>>{'Boiling Hot': 0, 'Cold': 1, 'Freezing': 2, 'Hot': 3, 'Lava Hot': 4, 'NONE': 5, 'Warm': 6}Nota il .fillna("NONE") nello snippet di codice sopra. Infatti, l’encoder di Sklearn non gestisce i valori vuoti e darà un errore quando si applica se ne trovano.
Una delle cose più importanti da tenere a mente per la corretta gestione delle variabili categorical è quella di gestire sempre i valori vuoti. Infatti, molte delle tecniche rilevanti non funzionano se questi non sono curati.
L’encoder di label mappa numeri arbitrari per ogni categoria nella colonna, senza una dichiarazione esplicita della mappatura. Questo è conveniente, ma introduce un problema per alcuni modelli predittivi: introduce la necessità di scalare i dati se la colonna non è quella target.
Infatti, i principianti del machine learning spesso chiedono qual è la differenza tra label encoder e one hot encoder, che vedremo a breve. L’encoder di label, per design, dovrebbe essere applicato alle etichette, ovvero la variabile target che vogliamo prevedere e non alle altre colonne.
Detto ciò, alcuni modelli anche molto rilevanti nel campo funzionano bene anche con una codifica di questo tipo. Sto parlando di modelli ad albero, tra cui spiccano XGBoost e LightGBM.
Quindi sentiti libero di usare gli encoder di label se decidi di usare modelli ad albero, ma in caso contrario, dobbiamo usare la codifica one hot.
2. One Hot Encoding
Come ho già menzionato nel mio articolo sulle rappresentazioni vettoriali nel machine learning, la codifica one hot è una tecnica di vettorizzazione molto comune e famosa (ovvero la conversione di un testo in un numero).
Funziona così: per ogni categoria presente, viene creata una matrice quadrata i cui unici valori possibili sono 0 e 1. Questa matrice informa il modello che tra tutte le categorie possibili, questa riga osservata ha il valore indicato da 1.
Ecco un esempio:
| | | | | | -------------|---|---|---|---|---|--- Freezing | 0 | 0 | 0 | 0 | 0 | 1 Warm | 0 | 0 | 0 | 0 | 1 | 0 Cold | 0 | 0 | 0 | 1 | 0 | 0 Boiling Hot | 0 | 0 | 1 | 0 | 0 | 0 Hot | 0 | 1 | 0 | 0 | 0 | 0 Lava Hot | 1 | 0 | 0 | 0 | 0 | 0 L’array ha dimensioni n_categories. Questa è un’informazione molto utile, perché la codifica one-hot richiede tipicamente una rappresentazione sparsa dei dati convertiti.
Cosa significa? Significa che per un gran numero di categorie, la matrice potrebbe diventare altrettanto grande. Essendo popolata solo da valori di 0 e 1 e poiché solo una delle posizioni può essere popolata da un 1, ciò rende la rappresentazione one-hot molto ridondante e ingombrante.
Una matrice sparsa risolve questo problema – vengono salvate solo le posizioni dei 1, mentre i valori uguali a 0 non vengono salvati. Questo semplifica il problema menzionato e ci consente di salvare un enorme array di informazioni in cambio di un uso di memoria molto ridotto.
Vediamo com’è fatto un tale array in Python, applicando di nuovo il codice precedente
from sklearn import preprocessing# gestiamo i valori mancanti df_train["ord_2"].fillna("NONE", inplace=True)# inizializziamo l'encoder di sklearn ohe = preprocessing.OneHotEncoder()# addestramento + trasformazione ohe.fit_transform(df_train["ord_2"].values.reshape(-1, 1))>><600000x7 sparse matrix of type '<class 'numpy.float64'>' with 600000 stored elements in Compressed Sparse Row format>Python restituisce un oggetto per impostazione predefinita, non una lista di valori. Per ottenere una tale lista, è necessario utilizzare .toarray()
ohe.fit_transform(df_train["ord_2"].values.reshape(-1, 1)).toarray()>>array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 1.], [0., 0., 1., ..., 0., 0., 0.], ..., [0., 0., 1., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 1.], [1., 0., 0., ..., 0., 0., 0.]])Non preoccuparti se non comprendi appieno il concetto: presto vedremo come applicare l’encoder di etichette e one-hot al dataset per addestrare un modello predittivo.
L’encoding delle etichette e l’encoding one-hot sono le tecniche più importanti per gestire le variabili categoriche. Conoscere queste due tecniche ti permetterà di gestire la maggior parte dei casi che coinvolgono variabili categoriche.
3. Trasformazioni e aggregazioni
Un altro metodo di conversione dal formato categorico a quello numerico consiste nel eseguire una trasformazione o una aggregazione sulla variabile.
Raggruppando con .groupby() è possibile utilizzare il conteggio dei valori presenti nella colonna come output della trasformazione.
df_train.groupby(["ord_2"])["id"].count()>>ord_2Boiling Hot 84790Cold 97822Freezing 142726Hot 67508Lava Hot 64840Warm 124239Name: id, dtype: int64utilizzando .transform() possiamo sostituire questi numeri alla cella corrispondente
df_train.groupby(["ord_2"])["id"].transform("count")>>0 67508.01 124239.02 142726.03 64840.04 97822.0 ... 599995 142726.0599996 84790.0599997 142726.0599998 124239.0599999 84790.0Name: id, Length: 600000, dtype: float64È possibile applicare questa logica anche con altre operazioni matematiche – il metodo che migliora maggiormente le prestazioni del nostro modello dovrebbe essere testato.
4. Creare nuove caratteristiche categoricali dalle variabili categoricali
Osserviamo insieme la colonna ord_1 insieme a ord_2
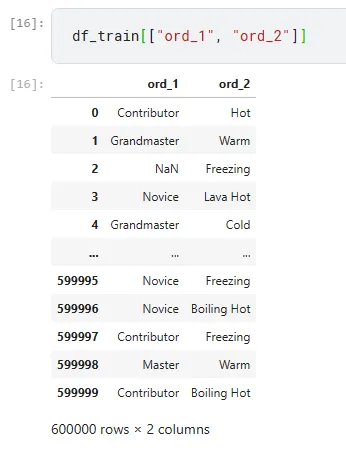
Possiamo creare nuove variabili categoricali unendo variabili esistenti. Ad esempio, possiamo unire ord_1 con ord_2 per creare una nuova caratteristica
df_train["new_1"] = df_train["ord_1"].astype(str) + "_" + df_train["ord_2"].astype(str)df_train["new_1"]>>0 Contributor_Hot1 Grandmaster_Warm2 nan_Freezing3 Novice_Lava Hot4 Grandmaster_Cold ... 599995 Novice_Freezing599996 Novice_Boiling Hot599997 Contributor_Freezing599998 Master_Warm599999 Contributor_Boiling HotName: new_1, Length: 600000, dtype: objectQuesta tecnica può essere applicata praticamente in ogni caso. L’idea che deve guidare l’analista è di migliorare le prestazioni del modello aggiungendo informazioni che erano originariamente difficili da comprendere al modello di apprendimento.
5. Utilizzare NaN come variabile categorica
Molto spesso i valori nulli vengono rimossi. Questo non è tipicamente una mossa che raccomando, poiché i NaN contengono informazioni potenzialmente utili per il nostro modello.
Una soluzione è quella di trattare i NaN come una categoria a sé stante.
Osserviamo di nuovo la colonna ord_2
df_train["ord_2"].value_counts()>>Freezing 142726Warm 124239Cold 97822Boiling Hot 84790Hot 67508Lava Hot 64840Name: ord_2, dtype: int64Ora proviamo ad applicare il .fillna(“NONE") per vedere quanti sono le celle vuote
df_train["ord_2"].fillna("NONE").value_counts()>>Freezing 142726Warm 124239Cold 97822Boiling Hot 84790Hot 67508Lava Hot 64840NONE 18075Come percentuale, NONE rappresenta circa il 3% dell’intera colonna. È una quantità abbastanza notevole. Sfruttare i NaN ha ancora più senso e può essere fatto con l’encoder One Hot menzionato in precedenza.
Trovare categorie rare
Ricordiamo cosa fa l’OneHotEncoder: crea una matrice sparsa il cui numero di colonne e righe è uguale al numero di categorie uniche nella colonna di riferimento. Ciò significa che dobbiamo prendere in considerazione anche le categorie che potrebbero essere presenti nel set di test e che potrebbero essere assenti nel set di train.
La situazione è simile per il LabelEncoder – potrebbero esserci categorie nel set di test che non sono presenti nel set di training e questo potrebbe creare problemi durante la trasformazione.
Risolviamo questo problema concatenando i dataset. Ciò ci consentirà di applicare gli encoder a tutti i dati e non solo ai dati di training.
test["target"] = -1data = pd.concat([train, test]).reset_index(drop=True)features = [f for f in train.columns if f not in ["id", "target"]]for feature in features: le = preprocessing.LabelEncoder() temp_col = data[feature].fillna("NONE").astype(str).values data.loc[:, feature] = le.fit_transform(temp_col) train = data[data["target"] != -1].reset_index(drop=True)test = data[data["target"] == -1].reset_index(drop=True)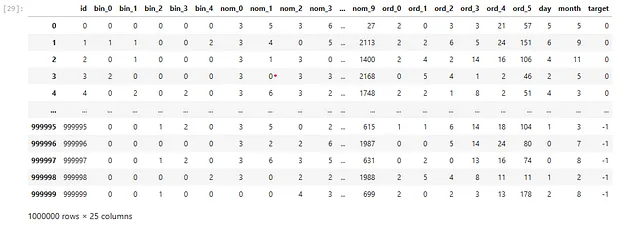
Questa metodologia ci aiuta se abbiamo il set di test. Se non abbiamo il set di test, prenderemo in considerazione un valore come NONE quando una nuova categoria diventa parte del nostro set di training.
Modellare dati categorici
Ora passiamo all’addestramento di un modello semplice. Seguiremo i passaggi dell’articolo su come progettare e implementare una cross-validation al seguente link 👇
Cos’è la cross-validation nell’apprendimento automatico
Scopri cos’è la cross-validation, una tecnica fondamentale per la creazione di modelli generalizzabili
towardsdatascience.com
Iniziamo da zero, importando i nostri dati e creando i nostri fold con StratifiedKFold di Sklearn.
train = pd.read_csv("/kaggle/input/cat-in-the-dat-ii/train.csv")test = pd.read_csv("/kaggle/input/cat-in-the-dat-ii/test.csv")df = train.copy()df["kfold"] = -1df = df.sample(frac=1).reset_index(drop=True)y = df.target.valueskf = model_selection.StratifiedKFold(n_splits=5)for f, (t_, v_) in enumerate(kf.split(X=df, y=y)): df.loc[v_, 'kfold'] = fQuesto piccolo frammento di codice creerà un dataframe di Pandas con 5 gruppi per testare il nostro modello.
Ora definiamo una funzione che testerà un modello di regressione logistica su ogni gruppo.
def run(fold: int) -> None: features = [ f for f in df.columns if f not in ("id", "target", "kfold") ] for feature in features: df.loc[:, feature] = df[feature].astype(str).fillna("NONE") df_train = df[df["kfold"] != fold].reset_index(drop=True) df_valid = df[df["kfold"] == fold].reset_index(drop=True) ohe = preprocessing.OneHotEncoder() full_data = pd.concat([df_train[features], df_valid[features]], axis=0) print("Fitting OHE on full data...") ohe.fit(full_data[features]) x_train = ohe.transform(df_train[features]) x_valid = ohe.transform(df_valid[features]) print("Training the classifier...") model = linear_model.LogisticRegression() model.fit(x_train, df_train.target.values) valid_preds = model.predict_proba(x_valid)[:, 1] auc = metrics.roc_auc_score(df_valid.target.values, valid_preds) print(f"FOLD: {fold} | AUC = {auc:.3f}")run(0)>>Fitting OHE on full data...Training the classifier...FOLD: 0 | AUC = 0.785Invito il lettore interessato a leggere l’articolo sulla cross-validation per capire in modo più dettagliato il funzionamento del codice mostrato.
Ora vediamo invece come applicare un modello ad albero come XGBoost, che funziona anche bene con un LabelEncoder.
def run(fold: int) -> None: features = [ f for f in df.columns if f not in ("id", "target", "kfold") ] for feature in features: df.loc[:, feature] = df[feature].astype(str).fillna("NONE") print("Fitting the LabelEncoder on the features...") for feature in features: le = preprocessing.LabelEncoder() le.fit(df[feature]) df.loc[:, feature] = le.transform(df[feature]) df_train = df[df["kfold"] != fold].reset_index(drop=True) df_valid = df[df["kfold"] == fold].reset_index(drop=True) x_train = df_train[features].values x_valid = df_valid[features].values print("Training the classifier...") model = xgboost.XGBClassifier(n_jobs=-1, n_estimators=300) model.fit(x_train, df_train.target.values) valid_preds = model.predict_proba(x_valid)[:, 1] auc = metrics.roc_auc_score(df_valid.target.values, valid_preds) print(f"FOLD: {fold} | AUC = {auc:.3f}")# esegui su 2 foldfor fold in range(2): run(fold)>>Fitting the LabelEncoder on the features...Training the classifier...FOLD: 0 | AUC = 0.768Fitting the LabelEncoder on the features...Training the classifier...FOLD: 1 | AUC = 0.765Conclusioni
In conclusione, ci sono anche altre tecniche che vale la pena menzionare per gestire le variabili categoriche:
- Codifica basata sul target, dove la categoria viene convertita nel valore medio assunto dalla variabile target in corrispondenza di essa
- Le embeddings di una rete neurale, che possono essere utilizzate per rappresentare l’entità testuale
In sintesi, ecco i passaggi essenziali per una corretta gestione delle variabili categoriche:
- trattare sempre i valori nulli
- applicare LabelEncoder o OneHotEncoder in base al tipo di variabile e al modello che vogliamo utilizzare
- ragionare in termini di arricchimento della variabile, considerando NaN o NONE come variabili categoriche che possono informare il modello
- Modellare i dati!
Grazie per il tuo tempo, Andrea