Regressione Lineare e Discesa del Gradiente
Linear Regression and Gradient Descent.
Scopri l’algoritmo di apprendimento automatico più fondamentale
La regressione lineare è uno degli algoritmi fondamentali esistenti nell’apprendimento automatico. Comprendere il suo flusso di lavoro interno aiuta a capire i concetti principali di altri algoritmi in scienza dei dati. La regressione lineare ha una vasta gamma di applicazioni in cui viene utilizzata per prevedere una variabile continua.
Prima di immergersi nel funzionamento interno della regressione lineare, comprendiamo prima un problema di regressione.
Introduzione
La regressione è un problema di apprendimento automatico che mira a prevedere un valore di una variabile continua data un vettore di caratteristiche che di solito è indicato come x = <x₁, x₂, x₃, …, xₙ> dove xᵢ rappresenta un valore della i-esima caratteristica nei dati. Affinché un modello possa effettuare previsioni, deve essere allenato su un set di dati che contiene mappe dai vettori di caratteristiche x ai corrispondenti valori di una variabile target y. Il processo di apprendimento dipende dal tipo di algoritmo utilizzato per una determinata attività.
- Boto3 vs AWS Wrangler Semplificare le operazioni con S3 con Python
- Serie di Apprendimento Non Supervisionato Esplorare il Clustering Gerarchico
- Samsung adotta l’AI e il Big Data, rivoluziona il processo di produzione dei chip.

Nel caso della regressione lineare, il modello apprende un tale vettore di pesi w = <x₁, x₂, x₃, …, xₙ> e un parametro di bias b che cercano di approssimare un valore target y come <w, x> + b = x₁ * w₁ + x₂ * w₂ + x₃ * w₃ + … + xₙ * wₙ + b nel modo migliore possibile per ogni osservazione del dataset (x, y).
Formulazione
Nel costruire un modello di regressione lineare, l’obiettivo finale è trovare un vettore di pesi w e un termine di bias b che porteranno ŷ, il valore previsto, a essere più vicino possibile al valore target y per tutte le voci:
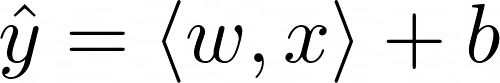
Per semplificare le cose, nell’esempio che stiamo per esaminare, verrà utilizzato un dataset con una singola caratteristica x. Pertanto, x e w sono vettori unidimensionali. Per semplicità, eliminiamo la notazione del prodotto interno e riscriviamo l’equazione sopra nel seguente modo:
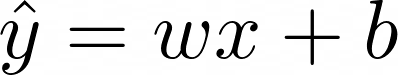
Funzione di perdita
Per allenare un algoritmo, deve essere scelta una funzione di perdita. La funzione di perdita misura quanto le previsioni dell’algoritmo siano state buone o cattive per un insieme di oggetti in una singola iterazione di addestramento. In base al suo valore, l’algoritmo regola i parametri del modello nella speranza che in futuro il modello produca meno errori.
Una delle funzioni di perdita più popolari è l’errore quadratico medio (o semplicemente MSE), che misura la deviazione media quadratica tra i valori previsti e quelli veri.
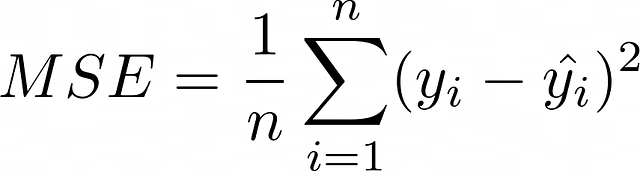
Discesa del gradiente
La discesa del gradiente è un algoritmo iterativo di aggiornamento del vettore dei pesi per minimizzare una data funzione di perdita cercando un minimo locale. La discesa del gradiente utilizza la seguente formula ad ogni iterazione:
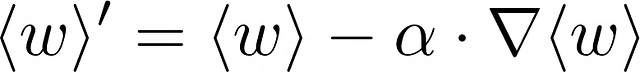
- <w> è un vettore di pesi del modello alla corrente iterazione. I pesi calcolati sono assegnati a <w>’. Durante la prima iterazione dell’algoritmo, i pesi sono di solito inizializzati casualmente, ma esistono anche altre strategie.
- alpha è di solito un piccolo valore positivo, anche conosciuto come tasso di apprendimento, — iperparametro che controlla la velocità di ricerca di un minimo locale.
- Il triangolo rovesciato denota un gradiente — un vettore di derivate parziali di una funzione di perdita. Nell’esempio corrente, il vettore dei pesi consiste di 2 componenti. Quindi, per calcolare un gradiente di <w> sono necessarie 2 derivate parziali da calcolare (f rappresenta una funzione di perdita):
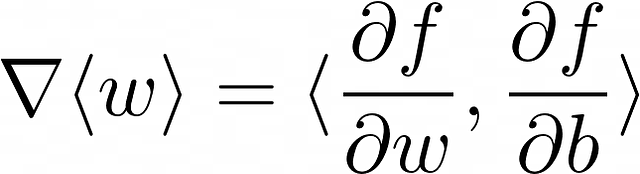
Le formule di aggiornamento possono essere riscritte in questo modo:

In questo momento, l’obiettivo è trovare derivate parziali di f. Supponendo che l’MSE sia scelto come funzione di perdita, calcoliamolo per una singola osservazione (n = 1 nella formula MSE), quindi f = (y — ŷ)² = (y — wx — b)² .
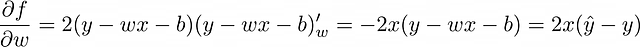
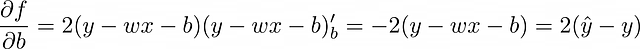
Il processo di aggiustamento dei pesi del modello basato su un singolo oggetto è chiamato discesa del gradiente stocastica.
Discesa del Gradiente Batch
Nella sezione precedente, i parametri del modello sono stati aggiornati calcolando l’MSE per un singolo oggetto (n = 1). In realtà, è possibile eseguire una discesa del gradiente per diversi oggetti in una singola iterazione. Questo modo di aggiornare i pesi è chiamato discesa del gradiente batch.
Le formule per l’aggiornamento dei pesi in questo caso possono essere ottenute in un modo molto simile, rispetto alla discesa del gradiente stocastica nella sezione precedente. L’unica differenza è che qui il numero di oggetti n deve essere preso in considerazione. In definitiva, la somma dei termini di tutti gli oggetti in un batch viene calcolata e poi divisa per n — la dimensione del batch.
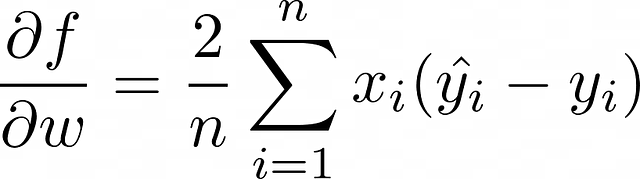
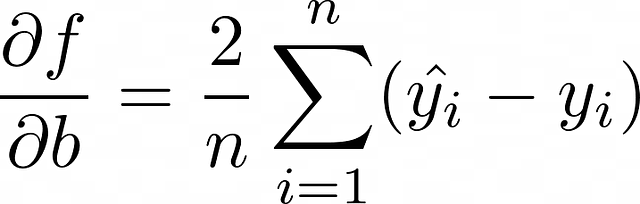
Visualizzazione
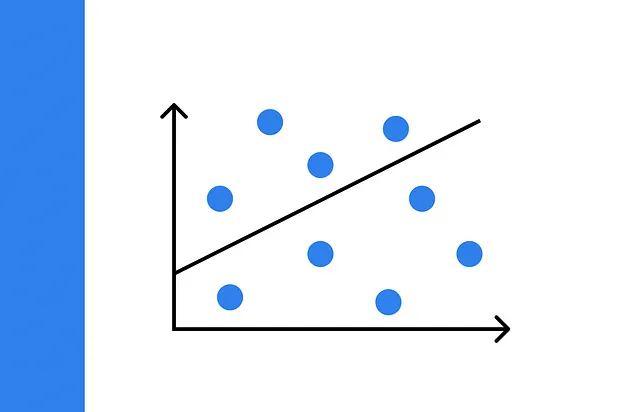
Quando si lavora con un dataset composto da una singola caratteristica, i risultati di regressione possono essere facilmente visualizzati su un grafico 2D. L’asse orizzontale rappresenta i valori della caratteristica mentre l’asse verticale contiene i valori target.
La qualità di un modello di regressione lineare può essere valutata visivamente dal quanto si adatta ai punti del dataset: più è vicina la distanza media tra ogni punto del dataset e la linea, migliore è l’algoritmo.
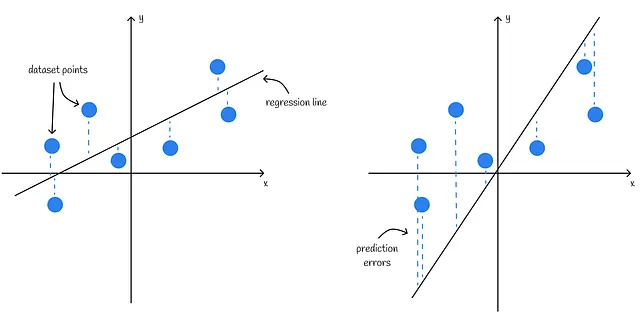
Se un dataset contiene più funzionalità, la visualizzazione può essere fatta utilizzando tecniche di riduzione della dimensionalità come PCA o t-SNE applicate alle funzionalità per rappresentarle in una dimensionalità inferiore. Dopo di che, le nuove funzionalità vengono tracciate su grafici 2D o 3D, come al solito.
Analisi
La regressione lineare ha una serie di vantaggi:
- Velocità di addestramento. Grazie alla semplicità dell’algoritmo, la regressione lineare può essere rapidamente addestrata, rispetto ad algoritmi di machine learning più complessi. Inoltre, può essere implementato attraverso il metodo LSM che è anche relativamente veloce e facile da capire.
- Interpretabilità. Un’equazione di regressione lineare costruita per diverse funzionalità può essere facilmente interpretata in termini di importanza delle funzionalità. Più è alto il valore del coefficiente di una funzionalità, maggiore è l’effetto che ha sulla previsione finale.
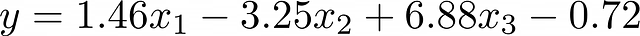
D’altra parte, presenta diversi svantaggi:
- Assunzioni dei dati. Prima di adattare un modello di regressione lineare, è importante verificare il tipo di dipendenza tra le funzionalità di output e di input. Se è lineare, non dovrebbero esserci problemi con l’adattamento. In caso contrario, il modello non è normalmente in grado di adattare bene i dati poiché l’equazione ha solo termini lineari. Infatti, è possibile aggiungere gradi superiori all’equazione per trasformare l’algoritmo in una regressione polinomiale, ad esempio. Tuttavia, nella realtà, senza molte conoscenze di dominio spesso è difficile prevedere correttamente il tipo di dipendenza. Questo è uno dei motivi per cui la regressione lineare potrebbe non adattarsi ai dati forniti.
- Problema di multicollinearità. La multicollinearità si verifica quando due o più predittori sono altamente correlati tra loro. Immagina una situazione in cui una modifica di una variabile influenza un’altra variabile. Tuttavia, un modello addestrato non ha informazioni a riguardo. Quando queste modifiche sono grandi, è difficile per il modello essere stabile durante la fase di inferenza sui dati non visti. Pertanto, ciò causa un problema di sovradattamento. Inoltre, i coefficienti di regressione finali potrebbero anche essere instabili per l’interpretazione a causa di ciò.
- Normalizzazione dei dati. Per utilizzare la regressione lineare come strumento di importanza delle funzionalità, i dati devono essere normalizzati o standardizzati. Ciò garantirà che tutti i coefficienti di regressione finali siano sulla stessa scala e possano essere interpretati correttamente.
Conclusione
Abbiamo esaminato la regressione lineare, un algoritmo semplice ma molto popolare nel machine learning. I suoi principi fondamentali vengono utilizzati in algoritmi più complessi.
Anche se la regressione lineare è raramente utilizzata nei moderni sistemi di produzione, la sua semplicità consente di utilizzarlo spesso come base standard nei problemi di regressione che viene poi confrontata con soluzioni più sofisticate.
Il codice sorgente utilizzato nell’articolo può essere trovato qui:
ML-Nisoo/linear_regression.ipynb at master · slavafive/ML-Nisoo
Non è possibile eseguire questa azione in questo momento. Hai effettuato l’accesso con un’altra scheda o finestra. Hai effettuato l’accesso in un’altra scheda o…
github.com
Risorse
- Minimi quadrati | Wikipedia
- Regressione polinomiale | Wikipedia
Tutte le immagini, salvo diversa indicazione, sono dell’autore.



