La guida essenziale dell’analisi esplorativa dei dati per un Data Scientist
The essential guide to exploratory data analysis for a Data Scientist.
Le migliori pratiche, tecniche e strumenti per comprendere completamente i tuoi dati.

Introduzione
L’Analisi Esplorativa dei Dati (EDA) è il compito più importante da svolgere all’inizio di ogni progetto di scienze dei dati.
In sostanza, consiste nell’esaminare e caratterizzare approfonditamente i dati al fine di trovare le loro caratteristiche sottostanti, possibili anomalie e modelli e relazioni nascoste.
- Serie AI Frontiers Risorse Umane
- Grafici a ragnatela e paralleli in R con il pacchetto ggvanced.
- Prevedere il successo di un programma di ricompensa presso Starbucks.
Questa comprensione dei dati è ciò che alla fine guiderà i passaggi successivi del tuo pipeline di apprendimento automatico, dalla pre-elaborazione dei dati alla costruzione del modello e all’analisi dei risultati.
Il processo di EDA comprende fondamentalmente tre compiti principali:
- Passaggio 1: Panoramica del dataset e statistiche descrittive
- Passaggio 2: Valutazione e visualizzazione delle caratteristiche e
- Passaggio 3: Valutazione della qualità dei dati
Come avrai capito, ognuno di questi compiti può comportare una quantità molto ampia di analisi, che ti faranno facilmente tagliare, stampare e plottare i tuoi dataframe pandas come un pazzo.
A meno che tu non scelga lo strumento giusto per il lavoro.
In questo articolo, approfondiremo ogni passaggio di un processo EDA efficace e discuteremo perché dovresti utilizzare “ydata-profiling” come punto di riferimento per padroneggiarlo.
Per dimostrare le migliori pratiche e indagare le informazioni, utilizzeremo il dataset Adult Census Income, liberamente disponibile su Kaggle o UCI Repository (Licenza: CC0: Public Domain).
Passaggio 1: Panoramica dei dati e statistiche descrittive
Quando ci troviamo per la prima volta con un dataset sconosciuto, ci viene subito in mente un pensiero automatico: con cosa sto lavorando?
Abbiamo bisogno di una comprensione profonda dei nostri dati per gestirli in modo efficiente nei futuri compiti di apprendimento automatico
Come regola generale, iniziamo tradizionalmente caratterizzando i dati relativamente al numero di osservazioni, al numero e ai tipi di caratteristiche, al tasso complessivo di mancanza e al percentuale di osservazioni duplicate.
Con un po’ di manipolazione di pandas e la giusta cheat sheet, potremmo eventualmente stampare le informazioni sopra con alcune brevi porzioni di codice:
Panoramica del dataset: Adult Census Dataset. Numero di osservazioni, caratteristiche, tipi di caratteristiche, righe duplicate e valori mancanti. Snippet di autore.
Nel complesso, il formato di output non è ideale… Se sei familiare con pandas, saprai anche il modus operandi standard per avviare un processo EDA – df.describe():
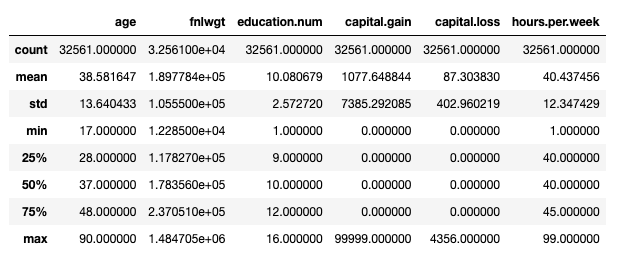
Tuttavia, questo considera solo le caratteristiche numeriche. Potremmo utilizzare df.describe(include='object') per stampare ulteriori informazioni sulle caratteristiche categoriche (conteggio, unicità, moda, frequenza), ma una semplice verifica delle categorie esistenti implicherebbe qualcosa di un po’ più verboso:
Panoramica del dataset: Adult Census Dataset. Stampa delle categorie esistenti e delle rispettive frequenze per ogni caratteristica categorica nei dati. Snippet di autore.
Tuttavia, possiamo fare questo – e indovina un po’, tutti i successivi compiti EDA! – in una sola riga di codice, utilizzando “ydata-profiling”:
Profilo del report del dataset Adult Census, utilizzando ydata-profiling. Snippet di autore.
Il codice sopra genera un rapporto di profilazione completo dei dati, che possiamo utilizzare per spostare ulteriormente il nostro processo EDA, senza la necessità di scrivere altro codice!
Esamineremo le varie sezioni del rapporto nelle sezioni seguenti. Per quanto riguarda le caratteristiche generali dei dati, tutte le informazioni che stavamo cercando sono incluse nella sezione Panoramica:
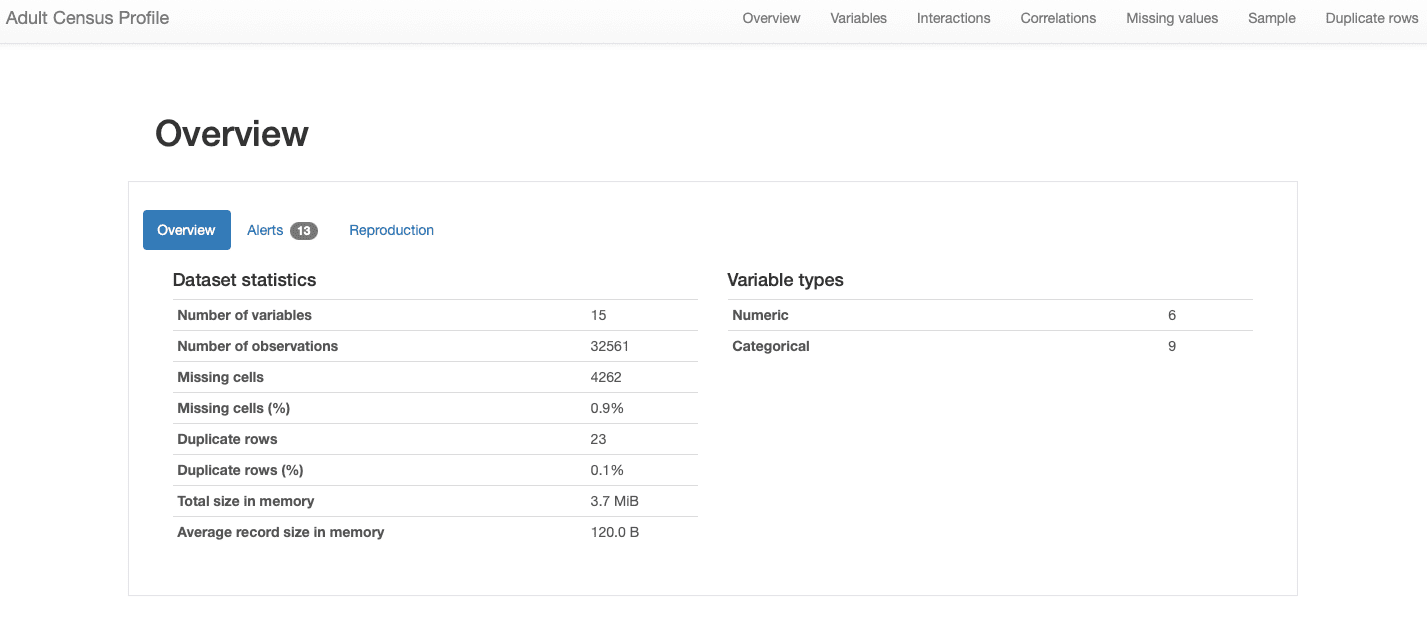
Possiamo vedere che il nostro dataset comprende 15 caratteristiche e 32561 osservazioni, con 23 record duplicati e un tasso di dati mancanti complessivo del 0,9% .
Inoltre, il dataset è stato correttamente identificato come un dataset tabellare , e piuttosto eterogeneo, presentando sia caratteristiche numeriche che categoriche . Per i dati di serie temporale , che hanno una dipendenza dal tempo e presentano diversi tipi di pattern, ydata-profiling incorporerebbe altre statistiche e analisi nel rapporto .
Possiamo ispezionare ulteriormente i dati grezzi e i record duplicati esistenti per avere una comprensione generale delle caratteristiche, prima di passare ad analisi più complesse:
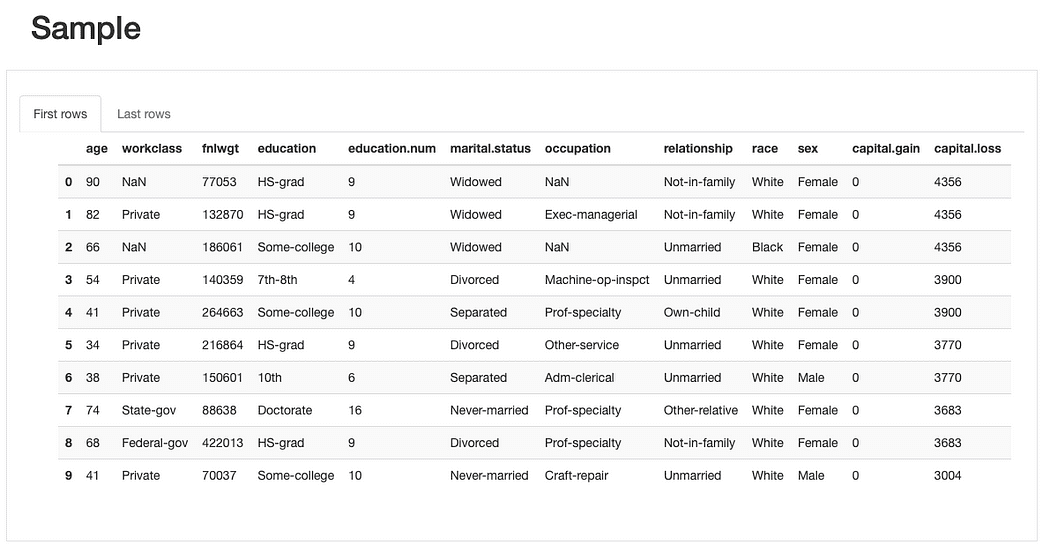
Dalla breve anteprima campione del campione di dati, possiamo vedere subito che sebbene il dataset abbia un basso percentuale di dati mancanti complessivamente, alcune caratteristiche potrebbero essere maggiormente influenzate da esso rispetto ad altre. Possiamo anche identificare un numero piuttosto considerabile di categorie per alcune caratteristiche e caratteristiche con valori pari a 0 (o almeno con una quantità significativa di 0).
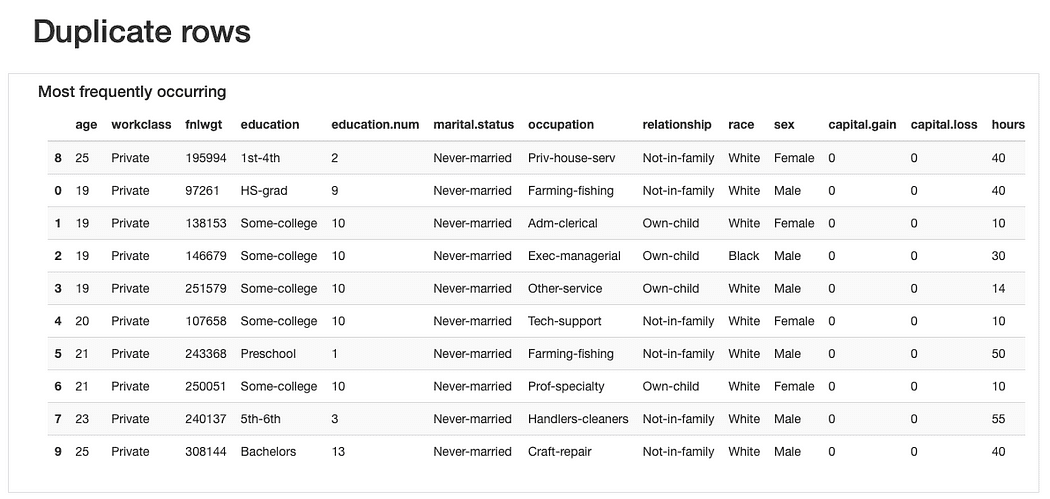
Riguardo ai record duplicati , non sarebbe strano trovare osservazioni “ripetute” dato che la maggior parte delle caratteristiche rappresenta categorie in cui diverse persone potrebbero “incastrarsi” contemporaneamente.
Tuttavia, forse un “odore di dati” potrebbe essere che queste osservazioni condividono gli stessi valori di età (che è plausibile) e lo stesso fnlwgt che, considerando i valori presentati, sembra più difficile da credere. Quindi ulteriori analisi sarebbero necessarie, ma dovremmo probabilmente eliminare questi duplicati in seguito.
In generale, la panoramica dei dati potrebbe essere un’analisi semplice, ma estremamente impattante , poiché ci aiuterà a definire i compiti futuri nella nostra pipeline.
Passaggio 2: Valutazione e visualizzazione delle caratteristiche
Dopo aver dato un’occhiata alle descrizioni generali dei dati, dobbiamo zoomare sulle caratteristiche del nostro dataset , al fine di ottenere alcune intuizioni sulle loro proprietà individuali — Analisi univariata — così come le loro interazioni e relazioni — Analisi multivariata .
Entrambi i compiti si basano pesantemente sull’investigazione di statistiche e visualizzazioni adeguate , che devono essere adattate al tipo di caratteristica in questione (ad esempio, numerica, categorica), e il comportamento che stiamo cercando di analizzare (ad esempio, interazioni, correlazioni).
Diamo un’occhiata alle migliori pratiche per ogni compito.
Analisi univariata
L’analisi delle caratteristiche individuali di ogni feature è cruciale poiché ci aiuterà a decidere sulla rilevanza per l’analisi e sul tipo di preparazione dei dati che potrebbero richiedere per ottenere risultati ottimali.
Ad esempio, potremmo trovare valori che sono estremamente fuori scala e potrebbero riferirsi a incoerenze o outlier . Potremmo aver bisogno di standardizzare i dati numerici o eseguire una codifica one-hot delle caratteristiche categoriche, a seconda del numero di categorie esistenti. Oppure potremmo dover eseguire una preparazione aggiuntiva dei dati per gestire le caratteristiche numeriche che sono sfasate o asimmetriche, se l’algoritmo di machine learning che intendiamo utilizzare si aspetta una distribuzione particolare (normalmente gaussiana).
Le migliori pratiche richiedono quindi l’approfondita indagine delle proprietà individuali come le statistiche descrittive e la distribuzione dei dati.
Queste evidenzieranno la necessità di compiti successivi di rimozione degli outlier, standardizzazione, codifica etichetta, imputazione dei dati, aumento dei dati e altri tipi di preprocessing.
Approfondiamo razza e guadagno di capitale in maggior dettaglio. Cosa possiamo notare immediatamente?
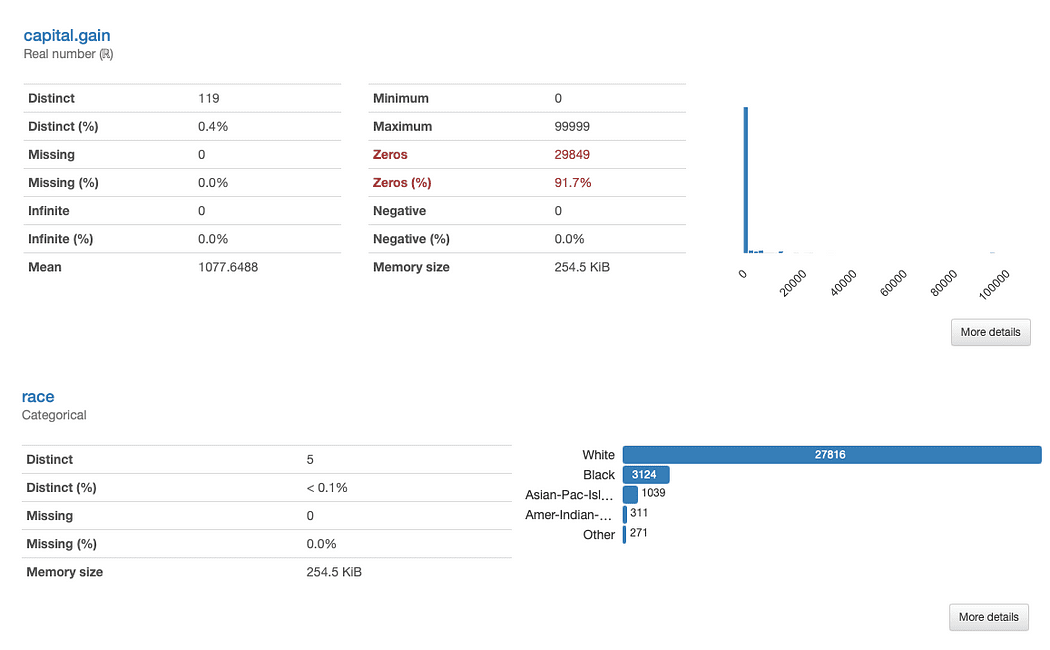
La valutazione di “ guadagno di capitale è semplice:
Dati i dati distributivi, potremmo chiederci se la funzione aggiunge valore alla nostra analisi, poiché il 91,7% dei valori è “0”.
L’analisi di “ razza è leggermente più complessa:
C’è una chiara sottorappresentazione di razze diverse da Bianco. Ciò comporta due problemi principali:
- Uno è la tendenza generale degli algoritmi di apprendimento automatico a trascurare i concetti meno rappresentati, noto come problema dei disgiunti piccoli, che porta a una ridotta prestazione di apprendimento;
- L’altro è in qualche modo derivato da questo problema: poiché stiamo affrontando una funzione sensibile, questa “tendenza di trascurare” potrebbe avere conseguenze direttamente correlate a problematiche di pregiudizio e equità. Qualcosa che sicuramente non vogliamo insinuare nei nostri modelli.
Tenendo conto di ciò, forse dovremmo considerare la realizzazione di un’elaborazione dati condizionata alle categorie sottorappresentate, nonché la considerazione di metriche sensibili all’equità per la valutazione del modello, per verificare eventuali discrepanze nelle prestazioni che si riferiscono ai valori della razza.
Approfondiremo ulteriormente su altre caratteristiche dei dati che devono essere affrontate quando discutiamo delle migliori pratiche sulla qualità dei dati (Passo 3). Questo esempio dimostra solo quanto possiamo imparare valutando le proprietà individuali di ogni funzione.
Infine, si noti come, come già menzionato, diversi tipi di funzioni richiedono strategie di statistica e di visualizzazione diverse:
- Le funzioni numeriche comprendono più spesso informazioni riguardanti la media, la deviazione standard, l’asimmetria, la curtosi e altre statistiche di quantili, e sono meglio rappresentate utilizzando grafici a istogramma;
- Le funzioni categoriali sono di solito descritte utilizzando la moda, la mediana e le tabelle di frequenza, e rappresentate utilizzando grafici a barre per l’analisi delle categorie.
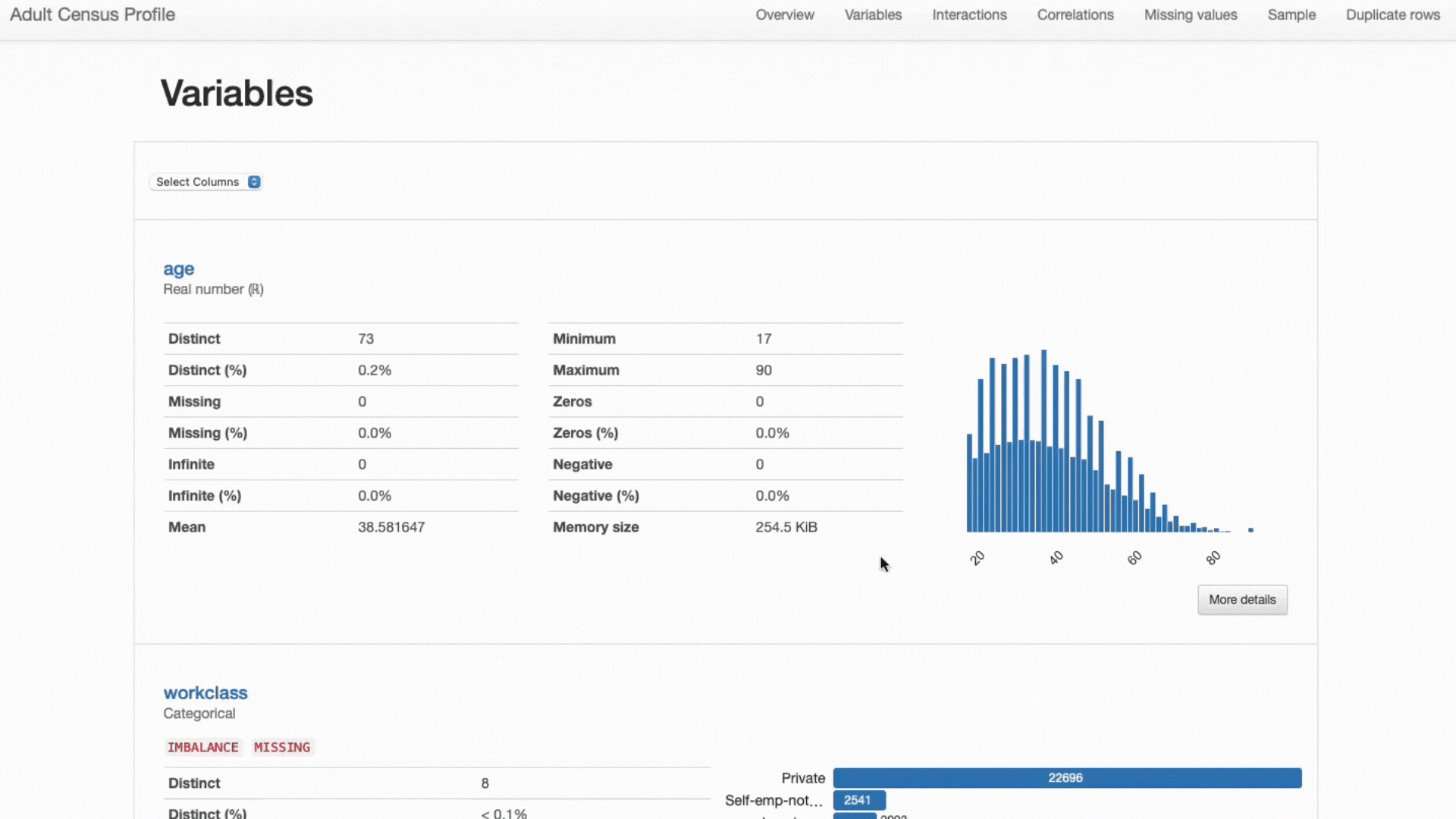
Un’analisi così dettagliata sarebbe onerosa da effettuare con una manipolazione generale dei dati, ma fortunatamente ydata-profiling ha tutta questa funzionalità integrata nel ProfileReport per la nostra convenienza: non sono state aggiunte righe di codice aggiuntive allo snippet!
Analisi Multivariata
Per l’analisi multivariata, le migliori pratiche si concentrano principalmente su due strategie: l’analisi delle interazioni tra le funzioni e l’analisi delle loro correlazioni.
Analisi delle Interazioni
Le interazioni ci permettono di esplorare visivamente come si comporta ogni coppia di funzioni, ovvero come i valori di una funzione si relazionano ai valori dell’altra.
Ad esempio, possono mostrare relazioni positive o negative, a seconda che l’aumento dei valori di una sia associato ad un aumento o una diminuzione dei valori dell’altra.
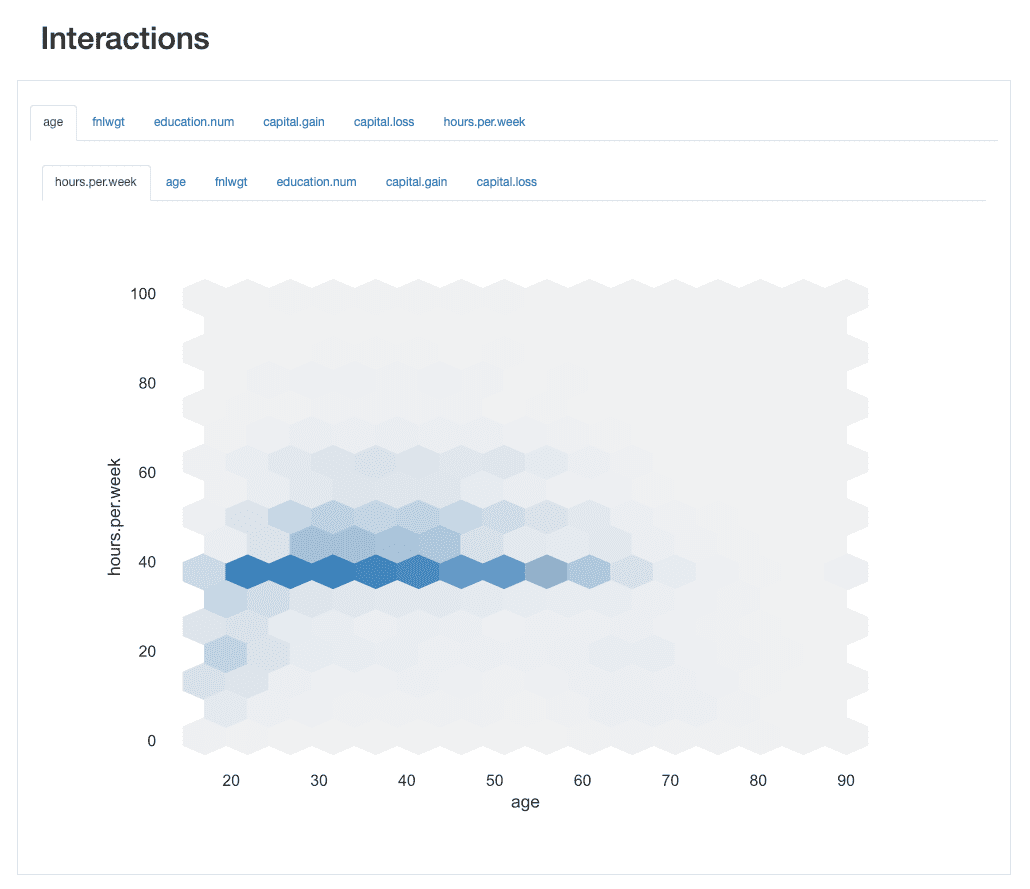 ydata-profiling: Profiling Report — Interactions. Image by Author.
ydata-profiling: Profiling Report — Interactions. Image by Author.
Prendendo come esempio l’interazione tra età e ore alla settimana, possiamo vedere che la grande maggioranza della forza lavoro lavora in media 40 ore. Tuttavia, ci sono alcuni “api operaie” che lavorano oltre (fino a 60 o addirittura 65 ore) tra i 30 e i 45 anni. Le persone dai 20 anni in su sono meno propense a lavorare troppo e potrebbero avere un programma di lavoro più leggero in alcune settimane.
Analisi delle Correlazioni
Come per le interazioni, le correlazioni ci permettono di analizzare la relazione tra le funzioni. Le correlazioni, tuttavia, “attribuiscono un valore” ad esse, in modo che sia più facile per noi determinare la “forza” di quella relazione.
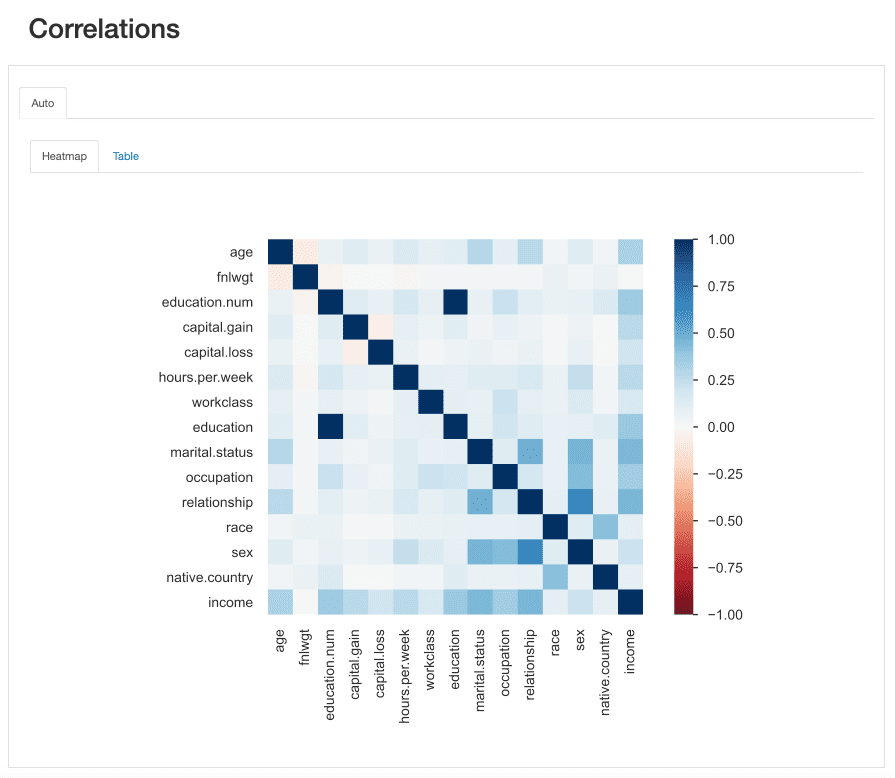
Questa “forza” è misurata dai coefficienti di correlazione e può essere analizzata numericamente (ad esempio, ispezionando una matrice di correlazione) o con una mappa termica, che utilizza colori e sfumature per evidenziare visivamente modelli interessanti:
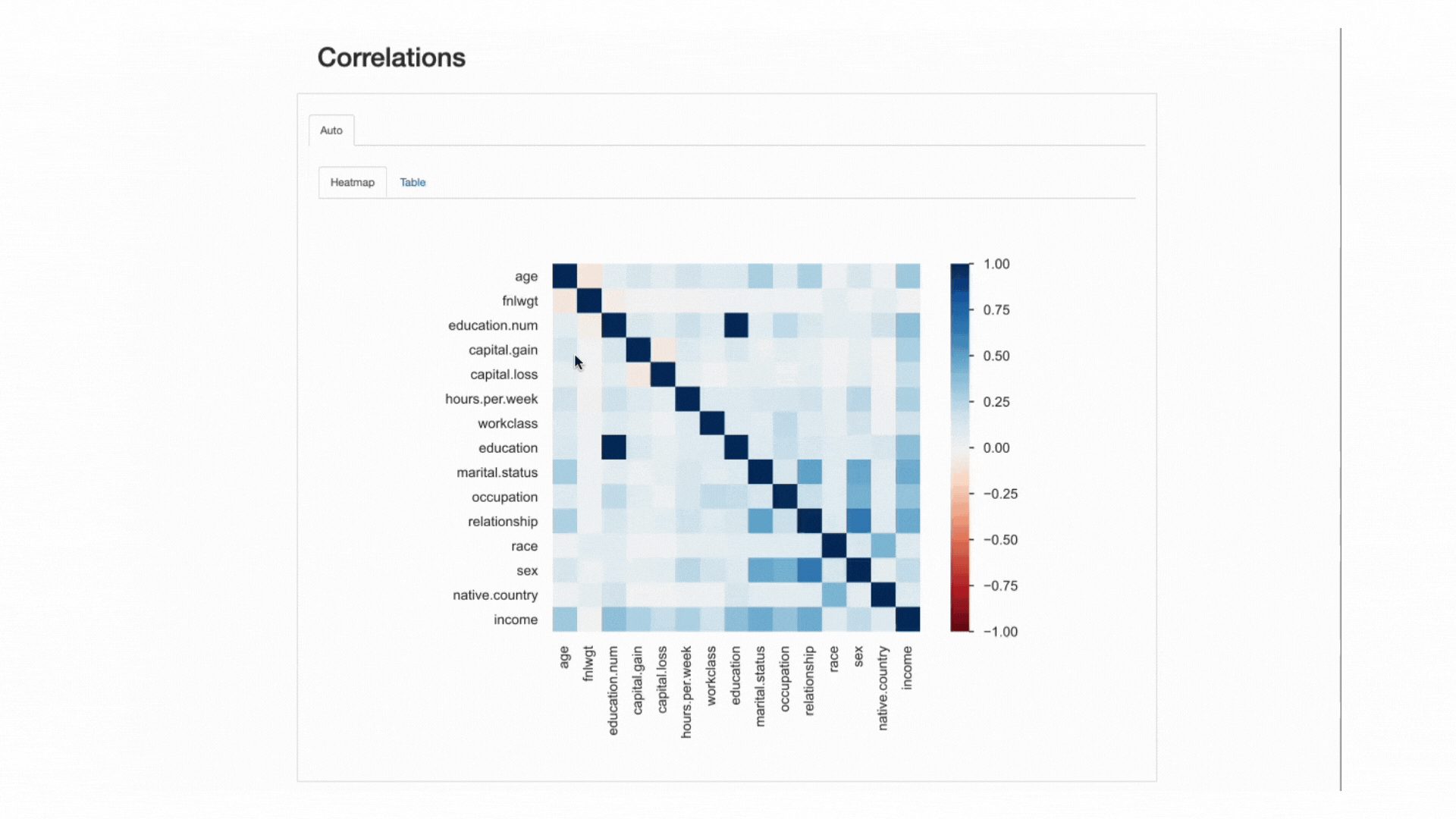 ydata-profiling: Rapporto di profilazione dei dati – Mappa termica e matrice di correlazione. Screencast dell’autore.
ydata-profiling: Rapporto di profilazione dei dati – Mappa termica e matrice di correlazione. Screencast dell’autore.
Riguardo al nostro dataset, notare come la correlazione tra educazione e educazione.num risalti. Infatti, contengono le stesse informazioni e educazione.num è solo una suddivisione dei valori di educazione.
Un altro pattern che cattura l’attenzione è la correlazione tra sesso e relazione, sebbene ancora una volta non molto informativa: guardando i valori di entrambe le caratteristiche, ci si renderebbe conto che queste caratteristiche sono molto probabilmente correlate perché maschio e femmina corrisponderanno rispettivamente a marito e moglie.
Questi tipi di ridondanze possono essere controllati per vedere se possiamo rimuovere alcune di queste caratteristiche dall’analisi (ad esempio, stato civile è anche correlato a relazione e sesso; paese di origine e razza, tra gli altri).
 ydata-profiling: Rapporto di profilazione dei dati – Correlazioni. Immagine dell’autore.
ydata-profiling: Rapporto di profilazione dei dati – Correlazioni. Immagine dell’autore.
Tuttavia, ci sono altre correlazioni che spiccano e potrebbero essere interessanti per lo scopo della nostra analisi.
Ad esempio, la correlazione tra sesso e occupazione, o sesso e ore alla settimana.
Infine, le correlazioni tra reddito e le rimanenti caratteristiche sono veramente informative, soprattutto nel caso in cui stiamo cercando di mappare un problema di classificazione. Sapere quali sono le caratteristiche più correlate alla nostra classe target ci aiuta a identificare le caratteristiche più discriminanti e trovare eventuali perdite di dati che possono influire sul nostro modello.
Dalla mappa termica, sembra che stato civile o relazione siano tra i predittori più importanti, mentre fnlwgt ad esempio, non sembra avere un grande impatto sul risultato.
Allo stesso modo dei descrittori e delle visualizzazioni dei dati, le interazioni e le correlazioni devono anche prestare attenzione ai tipi di caratteristiche presenti.
In altre parole, diverse combinazioni saranno misurate con diversi coefficienti di correlazione. Per impostazione predefinita, ydata-profiling esegue le correlazioni su auto, il che significa che:
- Correlazioni numeriche versus numeriche vengono misurate utilizzando il coefficiente di correlazione di Spearman;
- Correlazioni categoriche versus categoriche sono misurate utilizzando il Cramer’s V;
- Correlazioni numeriche versus categoriche usano anche il Cramer’s V, dove la caratteristica numerica viene prima discretizzata;
E se vuoi controllare altri coefficienti di correlazione (ad esempio, Pearson’s, Kendall’s, Phi) puoi facilmente configurare i parametri del rapporto.
Passaggio 3: Valutazione della qualità dei dati
Mentre ci muoviamo verso un paradigma di sviluppo dell’AI incentrato sui dati, essere al top dei possibili fattori complicanti che sorgono nei nostri dati è essenziale.
Con “fattori complicanti”, ci riferiamo agli errori che possono verificarsi durante la raccolta o l’elaborazione dei dati, o alle caratteristiche intrinseche dei dati che sono semplicemente una riflessione della natura dei dati stessi.
Tra questi ci sono dati mancanti, dati sbilanciati, valori costanti, duplicati, caratteristiche altamente correlate o ridondanti, dati rumorosi, tra gli altri.
 Problemi di qualità dei dati: errori e caratteristiche intrinseche dei dati. Immagine dell’autore.
Problemi di qualità dei dati: errori e caratteristiche intrinseche dei dati. Immagine dell’autore.
Trovare questi problemi di qualità dei dati all’inizio di un progetto (e monitorarli continuamente durante lo sviluppo) è critico.
Se non vengono identificati e risolti prima della fase di costruzione del modello, possono compromettere l’intero pipeline di Machine Learning e le successive analisi e conclusioni che possono derivarne.
Senza un processo automatizzato, la capacità di identificare e risolvere questi problemi sarebbe lasciata interamente all’esperienza personale e alla competenza della persona che conduce l’analisi EDA, il che ovviamente non è ideale. Inoltre, che peso avere sulle proprie spalle, soprattutto considerando i dataset ad alta dimensionalità. Allarme incubo in arrivo!
Questa è una delle funzionalità più apprezzate di ydata-profiling, la generazione automatica di avvisi di qualità dei dati:
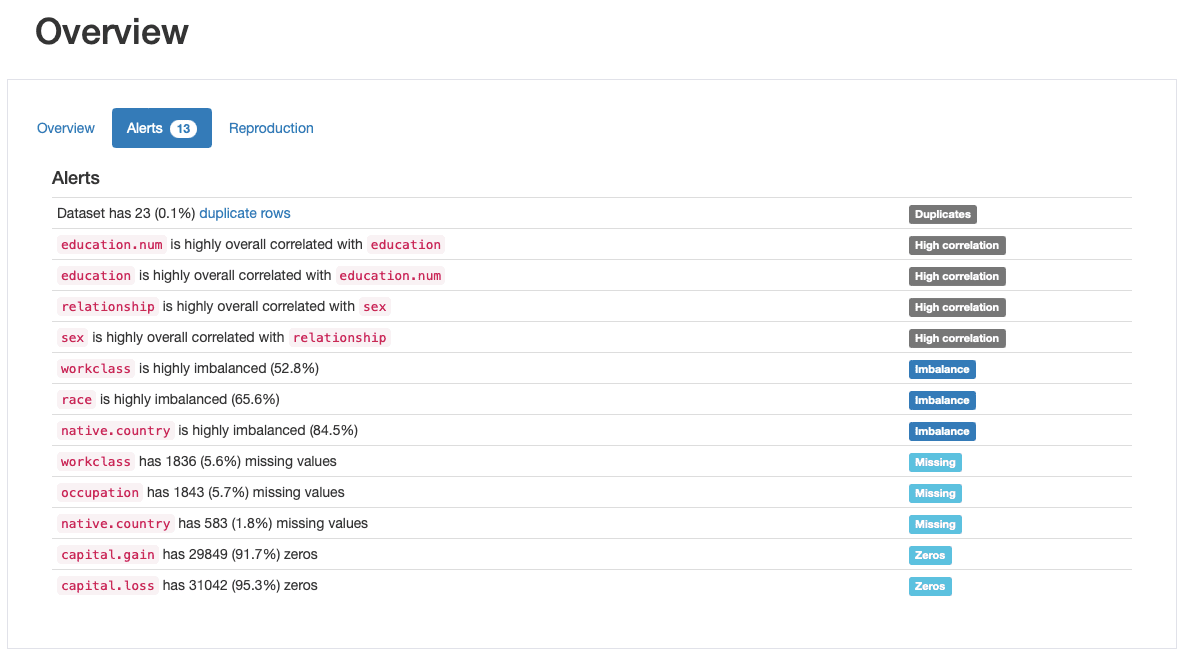 ydata-profiling: Profiling Report — Data Quality Alerts. Immagine dell’autore.
ydata-profiling: Profiling Report — Data Quality Alerts. Immagine dell’autore.
Il profilo restituisce almeno 5 diversi tipi di problemi di qualità dei dati, ovvero duplicati, alta correlazione, sbilanciamento, mancanti e zeri.
In effetti, ne avevamo già identificati alcuni in precedenza, mentre passavamo alla fase 2: race è una feature altamente sbilanciata e capital.gain è prevalentemente popolata da 0. Abbiamo anche visto la stretta correlazione tra education e education.num e relationship e sex.
Analisi dei modelli di dati mancanti
Tra la vasta gamma di avvisi considerati, ydata-profiling è particolarmente utile nell’analisi dei modelli di dati mancanti.
Dato che i dati mancanti sono un problema molto comune nei domini del mondo reale e possono compromettere l’applicazione di alcuni classificatori o biasimare gravemente le loro previsioni, un’altra buona pratica è analizzare attentamente la percentuale di dati mancanti e il comportamento che le nostre caratteristiche possono mostrare:
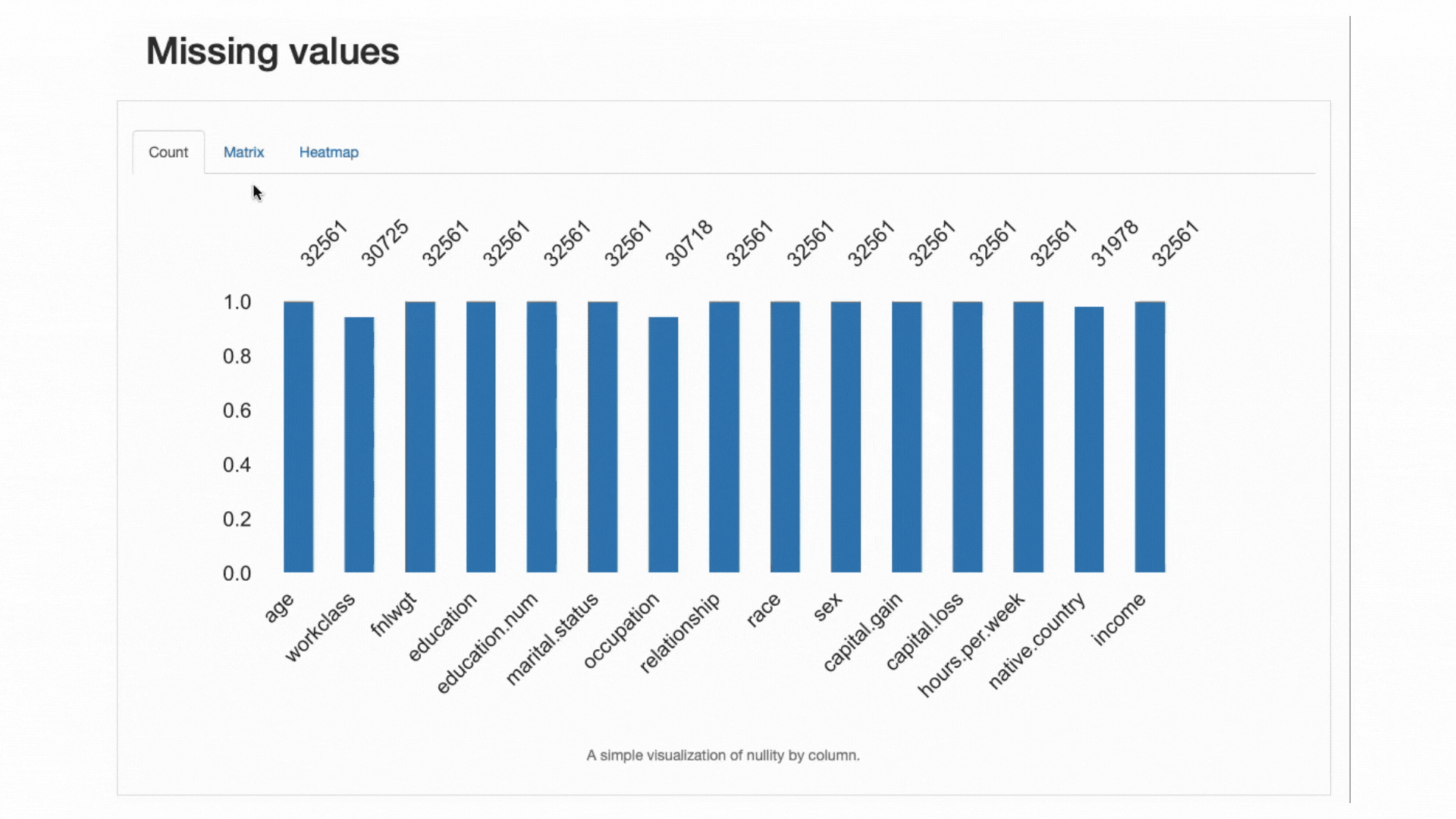 ydata-profiling: Profiling Report — Analyzing Missing Values. Screencast dell’autore.
ydata-profiling: Profiling Report — Analyzing Missing Values. Screencast dell’autore.
Dalla sezione degli avvisi sui dati, sapevamo già che workclass, occupation e native.country avevano osservazioni assenti. La mappa termica ci dice inoltre che c’è una relazione diretta con il modello mancante in occupation e workclass: quando c’è un valore mancante in una caratteristica, anche l’altra sarà mancante.
Insight chiave: il Data Profiling va oltre EDA!
Fino ad ora, abbiamo discusso delle attività che costituiscono un processo EDA completo e come la valutazione dei problemi di qualità e delle caratteristiche dei dati – un processo a cui ci riferiamo come Data Profiling – sia sicuramente una buona pratica.
Tuttavia, è importante chiarire che il Data Profiling va oltre EDA. Mentre generalmente definiamo EDA come il passaggio esplorativo e interattivo prima di sviluppare qualsiasi tipo di pipeline dati, il Data Profiling è un processo iterativo che dovrebbe avvenire in ogni passaggio di pre-elaborazione dei dati e di costruzione del modello.
Conclusioni
Un’efficace EDA getta le basi per una pipeline di machine learning di successo.
È come eseguire una diagnosi sui tuoi dati, imparando tutto ciò che devi sapere su ciò che implica – le sue proprietà, relazioni, problemi – in modo da poterli affrontare nel modo migliore possibile.
È anche l’inizio della nostra fase di ispirazione: è dall’EDA che iniziano ad emergere domande e ipotesi, e vengono pianificate analisi per convalidarle o respingerle lungo il percorso.
In tutto l’articolo, abbiamo coperto i 3 principali passaggi fondamentali che ti guideranno attraverso un’efficace EDA, e discusso dell’impatto di avere uno strumento di prim’ordine – ydata-profiling – per indicarci la giusta direzione e risparmiarci una quantità enorme di tempo e carico mentale.
Spero che questa guida ti aiuti a padroneggiare l’arte di “giocare al detective dei dati” e come sempre, feedback, domande e suggerimenti sono molto apprezzati. Fammi sapere su quali altri argomenti vorresti che scrivessi, o meglio ancora, vieni a incontrarmi presso la Community di Data-Centric AI e collaboriamo insieme!
Miriam Santos si concentra sull’educazione delle comunità di Data Science e Machine Learning su come passare da dati grezzi, sporchi, “cattivi” o imperfetti a dati intelligenti e di alta qualità, consentendo ai classificatori di machine learning di trarre inferenze accurate e affidabili in diverse industrie (Fintech, Healthcare & Pharma, Telecomm e Retail).
Originale. Ripubblicato con il permesso.