Prevedere il successo di un programma di ricompensa presso Starbucks.
Predict the success of a reward program at Starbucks.
Guida per principianti – spiegazione passo passo di un progetto completo dall’inizio alla fine
Panoramica del progetto
Questo progetto si concentra sull’individuazione di offerte di programmi di ricompensa che coinvolgono efficacemente i clienti attuali di Starbucks e ne attirano di nuovi.
Starbucks è un’azienda basata sui dati che investe nell’ottenere una comprensione completa dei suoi clienti utilizzando set di dati contenenti informazioni sui clienti, offerte speciali e dati di transazione.
Per sviluppare un modello in grado di determinare il successo di un programma di ricompensa, ho diviso il progetto in tre fasi:
- Ispezione e pulizia dei dati forniti da Udacity.
- Creazione di un set di dati che combina tutte le informazioni rilevanti.
- Costruzione e valutazione delle prestazioni di tre modelli di classificazione per prevedere il successo o il fallimento di un programma di ricompensa per una persona specifica.
Enunciato del problema
Effettuare un investimento significativo in una campagna di marketing è una decisione complessa che richiede l’approvazione di vari stakeholder, risorse finanziarie e tempo. Pertanto, avere un modello predittivo in grado di classificare se è conveniente lanciare una particolare offerta per un gruppo target specifico diventa un asset strategico per qualsiasi azienda.
- Come prevedere la perdita di giocatori, con l’aiuto di ChatGPT
- Perfeziona MPT-7B su Amazon SageMaker
- Regressione Lineare e Discesa del Gradiente
Per creare questo modello, utilizzeremo tecniche di apprendimento supervisionato per la classificazione binaria.
L’esito del modello indicherà se ci si aspetta che l’offerta sia efficace o meno.
Esplorazione e pulizia del dataset
Udacity ci ha fornito tre dataset in formato JSON: portfolio, profile e transcript. Ogni dataset serve uno scopo diverso e fornisce informazioni preziose per la nostra analisi.
Dataset di portafoglio
Questo dataset fornisce informazioni sulle offerte attive disponibili presso Starbucks.
- id (stringa) – id dell’offerta
- offer_type (stringa) – tipo di offerta, ad esempio BOGO, sconto, informativo
- difficulty (int) – spesa minima richiesta per completare un’offerta
- reward (int) – ricompensa data per il completamento di un’offerta
- duration (int) – tempo per cui l’offerta è aperta, in giorni
- channels (elenco di stringhe)

Ci sono dieci righe e sei colonne nel dataset di portafoglio. È un dataset semplice senza valori mancanti, nulli o duplicati.
Le colonne ‘channels’, ‘id’, ‘offer_type’ sono categoriche mentre ‘difficulty’, ‘duration’, ‘reward’ sono intere.
Vedi di seguito le modifiche che ho apportato al dataset:
- codifica one-hot dei ‘canali’ e ‘offer_type’
- cambiare l’‘id’ con ‘offer_id’
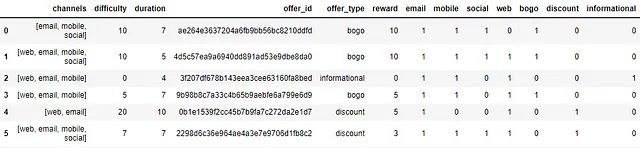
Dataset del profilo
Il dataset del profilo contiene informazioni demografiche sui clienti di Starbucks.
- età (int) — età del cliente
- became_member_on (int) — data in cui il cliente ha creato un account nell’app
- sesso (str) — sesso del cliente (alcune voci contengono ‘O’ per altro invece di M o F)
- id (str) — ID del cliente
- reddito (float) — reddito del cliente
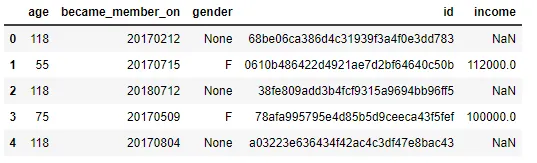
In questo dataset ci sono 17000 righe (numero di persone uniche nel dataset) e 5 colonne con 2175 elementi nulli (sia nelle colonne sesso che reddito). Poiché il valore dell’età è anche 118 in queste righe, ho rimosso tutte le 2175 righe dal dataset.
Vedi di seguito le modifiche che ho apportato al dataset:
- rimozione di 2175 righe con valore mancante (anche con valore di età di 118)
- modifica di ‘id’ in ‘customer_id’
- conversione della stringa ‘become_member_on’ in data
- creazione delle colonne ‘year_joined’ e ‘membership_days’
- codifica one-hot di ‘sesso’
- creazione di ‘age_group’ per categorizzare i clienti come adolescenti, giovani adulti, adulti, anziani
- creazione di ‘income_range’ per categorizzare i clienti come medi, sopra la media, elevati
- creazione di ‘member_type’ per categorizzare i clienti come nuovi, regolari, fedeli

Si nota che il numero di persone che aderiscono al programma ha una tendenza crescente tra gli anni 2013 e 2017, con il 2017 come miglior anno. Il 50% dei membri ha un’età compresa tra i 42 e i 66 anni.
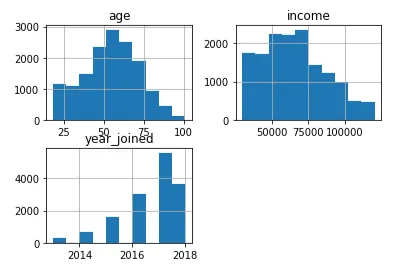
Come si può vedere di seguito, la popolazione maschile supera quella femminile nella fascia di reddito basso e medio, mentre la popolazione femminile supera quella maschile nella fascia di reddito alto.
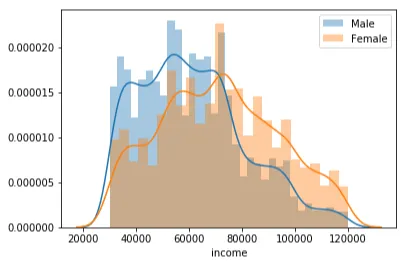
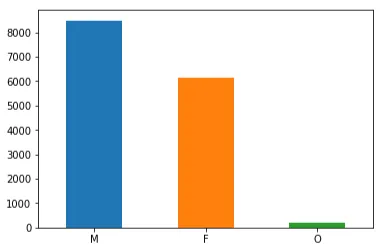
Considerando il genere, il dataset è un po’ sbilanciato, poiché il numero di persone di sesso maschile supera quello di sesso femminile e c’è un piccolo numero di persone per la categoria “altro”. Parlando con cifre esatte; ci sono 8484 maschi, 6129 femmine e solo 212 altri nel dataset.
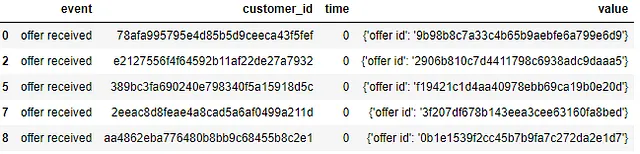
Dataset delle trascrizioni
Il dataset delle trascrizioni cattura le interazioni dei clienti con le offerte.
- evento (str) — descrizione del record (ad esempio transazione, offerta ricevuta, offerta visualizzata, ecc.)
- persona (str) — ID del cliente
- tempo (int) — tempo in ore dall’inizio del test. I dati iniziano al tempo t=0
- valore — (dizionario di stringhe) — ID dell’offerta o importo della transazione a seconda del record
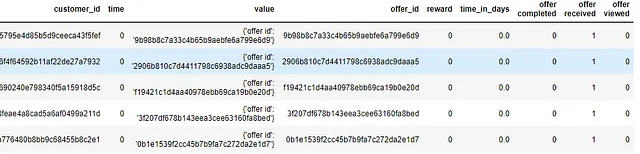
Se un evento nel dataset delle trascrizioni corrisponde a uno dei tre possibili stati dell’offerta (visualizzata, ricevuta o completata), la colonna valore contiene l’ID dell’offerta. Oltre all’ID dell’offerta, ci sarà un valore di ricompensa nel caso in cui l’evento sia in stato “offerta completata”.
Tuttavia, se l’evento è una transazione, la colonna valore visualizzerà solo l’importo della transazione.
Vedi di seguito le modifiche che ho effettuato sul dataset:
- Ampliamento del valore in nuove colonne ‘offer_id’, ‘amount’ e ‘rewards’.
- Creazione di ‘time_in_days’ convertendo il tempo (ore) in giorni.
- Cambiamento di ‘persona’ in ‘customer_id’
- Divisione del dataset delle trascrizioni in due sottodataset come offer_tr (dati dell’offerta) e transaction_tr (dati delle transazioni)
Creazione dei modelli
Dopo aver pulito i dataset e fatto le modifiche necessarie, dobbiamo combinare i dati in un unico dataset. Creeremo quindi una nuova colonna chiamata offer_successful. Questa colonna indicherà se l’offerta è stata o meno di successo per un determinato cliente. Ciò ci permetterà di costruire modelli in grado di prevedere se una determinata offerta avrà successo per un particolare tipo di cliente.
Un cliente deve visualizzare e completare un’offerta entro il periodo di tempo consentito affinché l’offerta sia considerata di successo. Ho sviluppato una funzione di supporto che calcola il valore target considerando i dati sulle offerte completate e visualizzate, nonché il range di tempo tra questi eventi.
Per creare un modello in grado di prevedere se un’offerta avrà successo o meno, dovremo addestrare un modello sul dataset finale.
I numeri di offerte di successo e insuccesso sono rispettivamente 35136 e 31365. Ciò significa che abbiamo un dataset bilanciato per quanto riguarda l’obiettivo. Quindi non abbiamo alcuna limitazione (che si presenta con dataset non bilanciati) riguardo ai modelli che possiamo scegliere.
In quanto si tratta di un problema di classificazione binaria, utilizzeremo tre diversi algoritmi di apprendimento supervisionato.
- Regressione logistica
- Foresta casuale
- Boosting del gradiente
Utilizzerò RandomizedSearchCV con 12 iterazioni per ottimizzare gli iperparametri dei modelli, poiché è meno costoso computazionalmente rispetto a GridSearchCV. RandomizedSearchCV funziona campionando casualmente i valori degli iperparametri da una distribuzione specificata.
Metriche e risultati
Ci si avvale della matrice di confusione e delle seguenti metriche per valutare le prestazioni dei modelli.
Si focalizza in particolare sulla precisione, poiché lo scopo principale dello studio è definire le classi positive il più possibile.
- Accuratezza: L’accuratezza è la metrica più comune utilizzata per valutare l’accuratezza di un modello di classificazione. Viene calcolata dividendo il numero di previsioni corrette per il numero totale di previsioni.
- Precisione: La precisione è una misura di quanto accurato sia il modello quando prevede una classe positiva. Viene calcolata dividendo il numero di veri positivi per il numero di veri positivi più il numero di falsi positivi.
- Recall: Recall è una misura di quanto completo sia il modello quando prevede una classe positiva. Viene calcolata dividendo il numero di veri positivi per il numero di veri positivi più il numero di falsi negativi.
- F1 score: L’F1 score è una media ponderata di precisione e recall. Viene calcolata dividendo 2 * (precisione * recall) per (precisione + recall).
Risultati:
- Regressione Logistica ……. → Accuratezza: 0.69, Precisione: 0.66
- Foresta Casuale …………. → Accuratezza: 0.70, Precisione: 0.66
- Gradient Boosting ……… → Accuratezza: 0.69, Precisione: 0.66
Anche se tutti i modelli forniscono metriche di prestazione simili, la Foresta Casuale ha una leggermente migliore accuratezza.
Conclusioni e miglioramenti
Anche se i modelli forniscono un buon punto di partenza, i risultati con una precisione del 66% hanno margine di miglioramento.
Un miglioramento intrigante per questo progetto è quello di creare più modelli di apprendimento supervisionato e combinarli in un modello di insieme personalizzato. La creazione di un modello di insieme combinando più modelli di apprendimento supervisionato offre il vantaggio della compensazione degli errori. Sfruttando i punti di forza di diversi modelli e compensando le loro debolezze, il modello di insieme raggiunge una migliore prestazione di generalizzazione, portando a un’accuratezza e una robustezza migliorate.
Per migliorare l’accuratezza delle previsioni del nostro programma di ricompense, potremmo considerare di separare i diversi tipi di ricompense e sviluppare modelli individuali per ogni programma. Adottando questo approccio, possiamo adeguare le nostre tecniche di modellizzazione alle caratteristiche e agli obiettivi specifici di ogni programma di ricompense, portando infine a previsioni più precise e a risultati migliori. Questo approccio può anche aiutarci a identificare eventuali tendenze o modelli unici all’interno di ogni programma di ricompense, portando a una progettazione e un’attuazione del programma più efficaci.
Un altro modo per ottimizzare l’efficacia del nostro programma di ricompense è identificare ed escludere le persone che acquistano indipendentemente dai programmi di ricompensa. In questo modo, possiamo concentrare le nostre risorse su coloro che sono più propensi a influire positivamente sui risultati del programma, massimizzando infine i benefici che otteniamo dal programma.





