Un team di ricerca composto da Google, Cornell e UC Berkeley ha presentato OmniMotion un metodo di intelligenza artificiale rivoluzionario per la stima del movimento denso e a lungo raggio nei video.
Google, Cornell, and UC Berkeley research team presented OmniMotion, a revolutionary AI method for long-range dense motion estimation in videos.


Il tracciamento delle caratteristiche sparse o il flusso ottico denso sono storicamente le due principali metodologie utilizzate negli algoritmi di stima del movimento. Entrambi i tipi di metodi hanno avuto successo nelle loro particolari applicazioni. Tuttavia, nessuna di queste rappresentazioni cattura completamente il movimento di un video: il tracciamento sparso non può descrivere il movimento di tutti i pixel. Al contrario, il flusso ottico a due a due non può catturare le traiettorie di movimento attraverso grandi fotogrammi temporali. Per ridurre questo divario, molti metodi sono stati utilizzati per prevedere traiettorie dense e a lungo raggio di pixel nei video. Questi vanno dalle semplici tecniche di concatenazione di campi di flusso ottico a due fotogrammi a algoritmi più avanzati che prevedono direttamente traiettorie per pixel per diversi fotogrammi.
Tuttavia, tutti questi approcci ignorano le informazioni dal contesto temporale o geografico corrente durante il calcolo della velocità. Questa localizzazione potrebbe causare stime di movimento con inconsistenze spatiotemporali e errori cumulativi su traiettorie estese. Anche quando le tecniche precedenti consideravano il contesto a lungo raggio, lo facevano nel dominio 2D, il che portava alla perdita di tracciamento durante situazioni di occlusione. La creazione di traiettorie dense e a lungo raggio presenta ancora diverse problematiche, tra cui il tracciamento dei punti attraverso le occlusioni, la preservazione della coerenza nello spazio e nel tempo e il mantenimento di tracciati accurati per lunghi periodi. In questo studio, i ricercatori dell’Università di Cornell, di Google Research e dell’UC Berkeley forniscono un metodo completo per stimare le traiettorie di movimento a lunghezza intera per ogni pixel in un film utilizzando tutti i dati video disponibili.
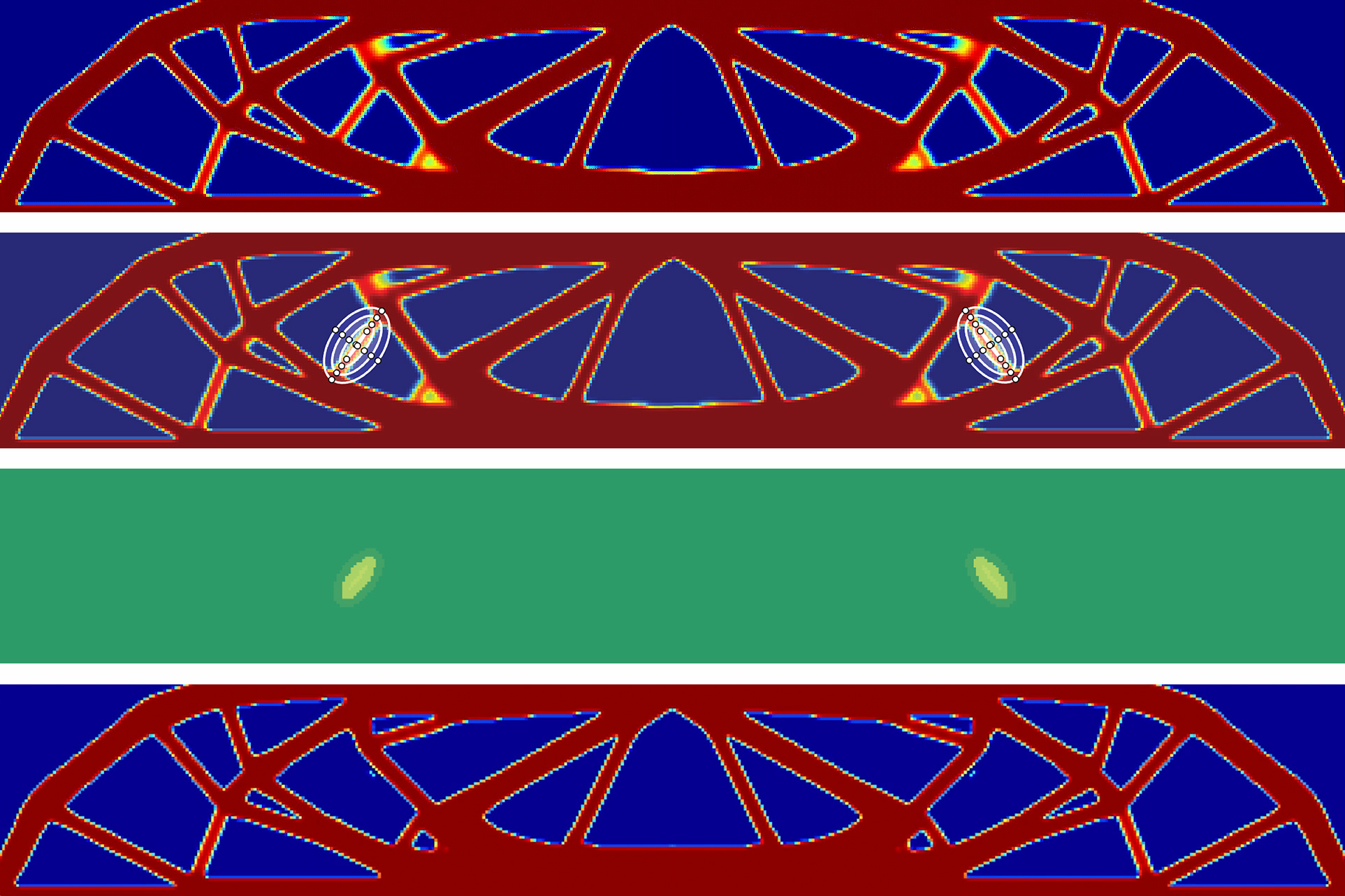
Il loro approccio, chiamato OmniMotion, utilizza una rappresentazione quasi-3D in cui una collezione di biezioni locali-canoniche mappa un volume 3D canonico a volumi locali per ogni fotogramma. Queste biezioni descrivono una combinazione di movimento di fotocamera e di scena come una flessibile rilassazione della geometria multi-vista dinamica. Possono monitorare tutti i pixel, anche quelli oscurati, e la loro rappresentazione garantisce la coerenza del ciclo (“Tutto, Ovunque”). Per risolvere congiuntamente il movimento dell’intero video “All at Once”, ottimizzano la loro rappresentazione per ogni video. Dopo l’ottimizzazione, qualsiasi coordinata continua nel film può interrogare la sua rappresentazione per ottenere una traiettoria di movimento che copre l’intero video.
- NVIDIA Research vince la sfida di guida autonoma e il premio per l’innovazione al CVPR.
- Ricercatori di Harvard introducono Intervento durante l’Inferenza Temporale (ITI) una tecnica di intelligenza artificiale che migliora la veridicità dei modelli di linguaggio dal 32,5% al 65,1%.
- Abilitare esperienze utente deliziose attraverso modelli predittivi dell’attenzione umana.
In conclusione, forniscono un metodo che può gestire film “in the-wild” con qualsiasi combinazione di movimento di fotocamera e di scena:
- Genera traiettorie di movimento a lunghezza intera globalmente coerenti per tutti i punti in un intero video.
- Può tracciare punti attraverso le occlusioni.
- Può tracciare punti attraverso le occlusioni.
Dimostrano statisticamente questi punti di forza sul benchmark di tracciamento video TAP, dove raggiungono prestazioni all’avanguardia e superano di gran lunga tutte le precedenti tecniche. Hanno rilasciato diversi video dimostrativi sul loro sito web e pianificano di rilasciare presto il codice.

Come si può vedere dalle traiettorie di movimento sopra, forniscono una nuova tecnica per il calcolo delle traiettorie di movimento a lunghezza intera per ogni pixel in ogni fotogramma di un film. Visualizzano solo traiettorie sparse per oggetti in primo piano per mantenere la chiarezza, nonostante il fatto che la loro tecnica calcoli il movimento per tutti i pixel. Il loro approccio produce un movimento preciso, coerente e a lungo raggio, anche per oggetti in rapido movimento, e traccia in modo affidabile attraverso le occlusioni, come dimostrato dalle istanze del cane e dell’altalena. L’oggetto in movimento viene mostrato nella seconda riga in vari momenti per fornire contesto.