Come dovremmo archiviare le immagini AI? I ricercatori di Google propongono un metodo di compressione delle immagini utilizzando modelli generativi basati sul punteggio.
Google researchers propose compressing AI images using score-based generative models.


Un anno fa, generare immagini realistiche con l’AI era un sogno. Eravamo impressionati vedendo facce generate che assomigliavano a quelle reali, nonostante la maggior parte degli output avesse tre occhi, due nasi, ecc. Tuttavia, le cose sono cambiate abbastanza rapidamente con il rilascio di modelli di diffusione. Oggi è difficile distinguere un’immagine generata dall’AI da una reale.
La capacità di generare immagini di alta qualità è una parte dell’equazione. Se volessimo utilizzarle correttamente, la compressione efficiente gioca un ruolo essenziale in compiti come la generazione di contenuti, la conservazione dei dati, la trasmissione e l’ottimizzazione della larghezza di banda. Tuttavia, la compressione delle immagini si è basata principalmente su metodi tradizionali come la codifica di trasformazione e le tecniche di quantizzazione, con una limitata esplorazione di modelli generativi.
Nonostante il loro successo nella generazione di immagini, i modelli di diffusione e i modelli generativi basati su punteggio non sono ancora emersi come gli approcci principali per la compressione delle immagini, rimanendo indietro rispetto ai metodi basati su GAN. Spesso si comportano peggio o alla pari con gli approcci basati su GAN come HiFiC su immagini ad alta risoluzione. Anche i tentativi di riprogettare i modelli di testo per immagini per la compressione di immagini hanno prodotto risultati insoddisfacenti, producendo ricostruzioni che si discostano dall’input originale o che contengono artefatti indesiderati.
- Ricercatori di Microsoft e UC Santa Barbara propongono LONGMEM un framework di intelligenza artificiale che consente a LLM di memorizzare una lunga storia.
- Ricercatori dell’Università di Berkeley e di Google presentano un framework di intelligenza artificiale che formula la risposta a domande visive come generazione di codice modulare.
- Rivoluzionando la navigazione ricercatori del MIT svelano un nuovo approccio di apprendimento automatico per la stabilizzazione dei veicoli autonomi e l’evitamento degli ostacoli.
Il divario tra le prestazioni dei modelli generativi basati su punteggio nei compiti di generazione di immagini e il loro limitato successo nella compressione delle immagini solleva domande intriganti e motiva ulteriori indagini. È sorprendente che i modelli capaci di generare immagini di alta qualità non siano stati in grado di superare i GAN nel compito specifico di compressione delle immagini. Questa discrepanza suggerisce che potrebbero esserci sfide e considerazioni uniche quando si applicano i modelli generativi basati su punteggio a compiti di compressione, rendendo necessari approcci specializzati per sfruttare appieno il loro potenziale.
Quindi sappiamo che c’è un potenziale per l’utilizzo di modelli generativi basati su punteggio nella compressione delle immagini. La domanda è: come si può fare? Passiamo alla risposta.
I ricercatori di Google hanno proposto un metodo che combina un autoencoder standard, ottimizzato per l’errore quadratico medio (MSE), con un processo di diffusione per recuperare e aggiungere dettagli fini scartati dall’autoencoder. Il tasso di bit per la codifica di un’immagine è determinato esclusivamente dall’autoencoder, poiché il processo di diffusione non richiede bit aggiuntivi. Sfruttando modelli di diffusione specificamente per la compressione delle immagini, si dimostra che possono superare diversi approcci generativi recenti in termini di qualità dell’immagine.

Il metodo esplora due approcci strettamente correlati: i modelli di diffusione, che mostrano prestazioni impressionanti ma richiedono un elevato numero di passaggi di campionamento, e i flussi rettificati, che funzionano meglio quando si consentono meno passaggi di campionamento.
L’approccio a due fasi consiste prima di codificare l’immagine di input utilizzando l’autoencoder ottimizzato per l’MSE e poi di applicare il processo di diffusione o i flussi rettificati per migliorare il realismo della ricostruzione. Il modello di diffusione utilizza un programma di rumore che viene spostato nella direzione opposta rispetto ai modelli di testo-per-immagine, dando priorità ai dettagli rispetto alla struttura globale. D’altra parte, il modello di flusso rettificato sfrutta l’accoppiamento fornito dall’autoencoder per mappare direttamente le uscite dell’autoencoder su immagini non compresse.
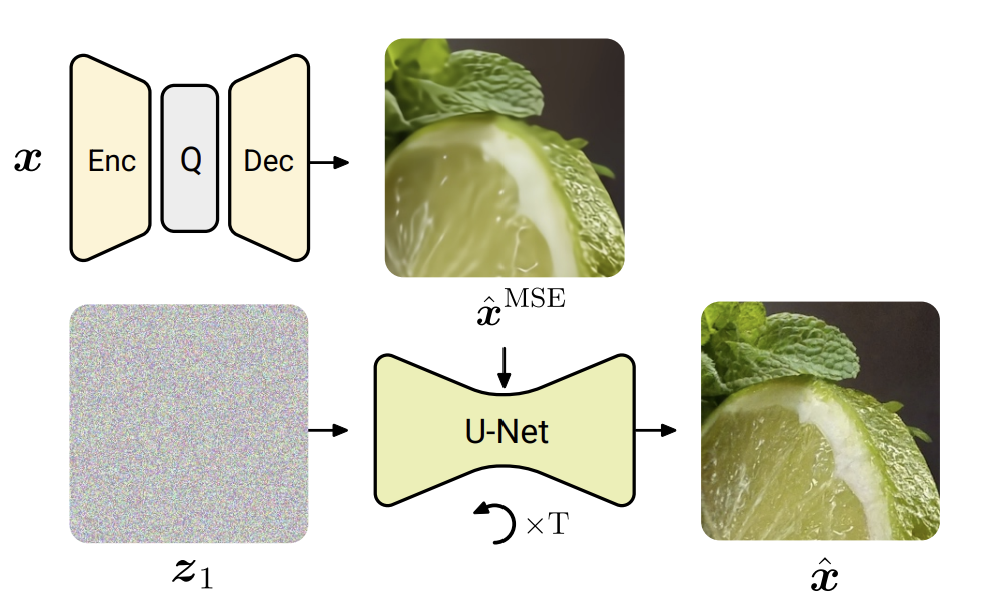
Inoltre, lo studio ha rivelato dettagli specifici che possono essere utili per future ricerche in questo campo. Ad esempio, si dimostra che il programma di rumore e la quantità di rumore iniettato durante la generazione di immagini influiscono significativamente sui risultati. Interessante notare che mentre i modelli di testo-per-immagine traggono beneficio dall’aumento dei livelli di rumore durante la formazione su immagini ad alta risoluzione, si è scoperto che la riduzione complessiva del rumore del processo di diffusione è vantaggiosa per la compressione. Questo aggiustamento consente al modello di concentrarsi maggiormente sui dettagli fini, poiché i dettagli grossolani sono già adeguatamente catturati dalla ricostruzione dell’autoencoder.