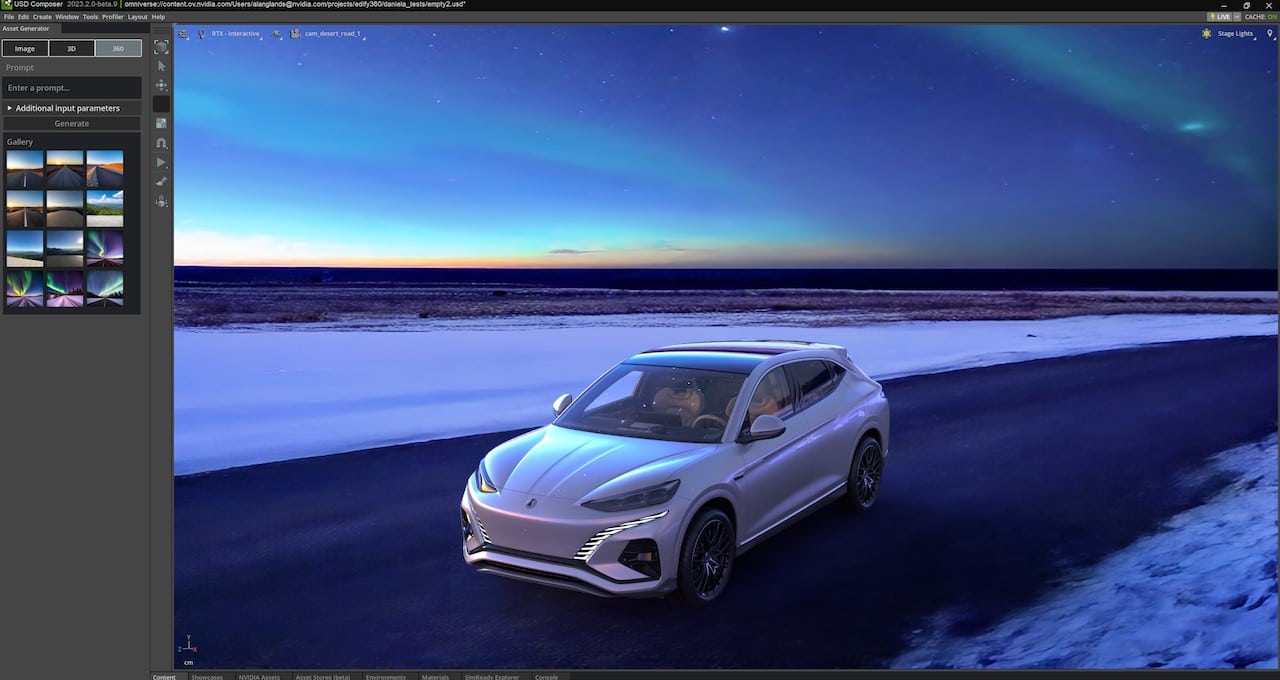
Ospita l’interfaccia utente di Spark su Amazon SageMaker Studio
Spark's UI hosted on Amazon SageMaker Studio
Amazon SageMaker offre diversi modi per eseguire lavori di elaborazione dati distribuiti con Apache Spark, un popolare framework di elaborazione dati distribuita per il big data.
Puoi eseguire applicazioni Spark in modo interattivo da Amazon SageMaker Studio, collegando i notebook di SageMaker Studio e le sessioni interattive di AWS Glue per eseguire lavori Spark con un cluster serverless. Con le sessioni interattive, puoi scegliere Apache Spark o Ray per elaborare facilmente grandi dataset, senza preoccuparti della gestione del cluster.
In alternativa, se hai bisogno di maggior controllo sull’ambiente, puoi utilizzare un container pre-costruito di SageMaker Spark per eseguire applicazioni Spark come lavori batch su un cluster distribuito completamente gestito con Amazon SageMaker Processing. Questa opzione ti consente di selezionare diversi tipi di istanze (ottimizzate per il calcolo, ottimizzate per la memoria e altro), il numero di nodi nel cluster e la configurazione del cluster, consentendo quindi maggiore flessibilità per l’elaborazione dati e l’addestramento dei modelli.
Infine, puoi eseguire applicazioni Spark collegando i notebook di Studio con cluster Amazon EMR o eseguendo il tuo cluster Spark su Amazon Elastic Compute Cloud (Amazon EC2).
- Rilascio di Swift Transformers Esegui LLM on-device sui dispositivi Apple
- Perfeziona Llama 2 con DPO
- La GPU NVIDIA H100 Tensor Core utilizzata sulla nuova serie di macchine virtuali Microsoft Azure ora disponibile in generale
Tutte queste opzioni ti consentono di generare e archiviare registri eventi Spark per analizzarli tramite l’interfaccia utente basata sul web comunemente chiamata Spark UI, che esegue un Spark History Server per monitorare il progresso delle applicazioni Spark, tenere traccia dell’utilizzo delle risorse e risolvere errori.
In questo post, condivideremo una soluzione per l’installazione e l’esecuzione di Spark History Server su SageMaker Studio e l’accesso diretto all’interfaccia utente Spark UI direttamente dall’IDE di SageMaker Studio, per analizzare i registri Spark prodotti da diversi servizi AWS (sessioni interattive di AWS Glue, lavori di SageMaker Processing e Amazon EMR) e archiviati in un bucket Amazon Simple Storage Service (Amazon S3).
Panoramica della soluzione
La soluzione integra Spark History Server nell’applicazione Jupyter Server in SageMaker Studio. Ciò consente agli utenti di accedere direttamente ai registri Spark dall’IDE di SageMaker Studio. L’integrato Spark History Server supporta quanto segue:
- Accesso ai registri generati dai lavori Spark di SageMaker Processing
- Accesso ai registri generati dalle applicazioni Spark di AWS Glue
- Accesso ai registri generati da cluster Spark gestiti autonomamente e Amazon EMR
È inoltre fornita un’interfaccia della riga di comando (CLI) di utilità chiamata sm-spark-cli per interagire con l’interfaccia utente Spark dall’ambiente terminale di sistema di SageMaker Studio. Il sm-spark-cli consente di gestire Spark History Server senza uscire da SageMaker Studio.

La soluzione consiste in script shell che eseguono le seguenti azioni:
- Installazione di Spark sul Server Jupyter per i profili utente di SageMaker Studio o per uno spazio condiviso di SageMaker Studio
- Installazione di
sm-spark-cliper un profilo utente o uno spazio condiviso
Installazione manuale di Spark UI in un dominio di SageMaker Studio
Per ospitare Spark UI su SageMaker Studio, completa i seguenti passaggi:
- Scegli Terminale di sistema dal launcher di SageMaker Studio.

- Esegui i seguenti comandi nel terminale di sistema:
curl -LO https://github.com/aws-samples/amazon-sagemaker-spark-ui/releases/download/v0.1.0/amazon-sagemaker-spark-ui-0.1.0.tar.gz
tar -xvzf amazon-sagemaker-spark-ui-0.1.0.tar.gz
cd amazon-sagemaker-spark-ui-0.1.0/install-scripts
chmod +x install-history-server.sh
./install-history-server.shI comandi impiegheranno alcuni secondi per completarsi.
- Quando l’installazione è completa, puoi avviare Spark UI utilizzando il
sm-spark-clifornito e accedervi da un browser web eseguendo il seguente codice:
sm-spark-cli start s3://DOC-EXAMPLE-BUCKET/<SPARK_EVENT_LOGS_LOCATION>
La posizione S3 in cui vengono memorizzati i log degli eventi generati da SageMaker Processing, AWS Glue o Amazon EMR può essere configurata durante l’esecuzione delle applicazioni Spark.
Per i notebook di SageMaker Studio e le sessioni interattive AWS Glue, è possibile configurare direttamente la posizione dei log degli eventi Spark dal notebook utilizzando il kernel sparkmagic.
Il kernel sparkmagic contiene un insieme di strumenti per interagire con cluster Spark remoti tramite notebook. Offre comandi magici (%spark, %sql) per eseguire codice Spark, eseguire query SQL e configurare impostazioni Spark come memoria executor e core.

Per il job SageMaker Processing, è possibile configurare direttamente la posizione dei log degli eventi Spark dal SDK Python di SageMaker.

Per ulteriori informazioni, consultare la documentazione AWS:
- Per SageMaker Processing, fare riferimento a PySparkProcessor
- Per le sessioni interattive AWS Glue, fare riferimento alla Configurazione dell’interfaccia utente Spark (console)
- Per Amazon EMR, fare riferimento alla Configurazione di una posizione di output

È possibile scegliere l’URL generato per accedere all’interfaccia utente Spark.

La seguente immagine mostra un esempio dell’interfaccia utente Spark.

È possibile verificare lo stato del server di cronologia Spark utilizzando il comando sm-spark-cli status nel terminale di sistema di Studio.

È inoltre possibile arrestare il server di cronologia Spark quando necessario.

Automatizzare l’installazione dell’interfaccia utente Spark per gli utenti in un dominio SageMaker Studio
Come amministratore IT, è possibile automatizzare l’installazione per gli utenti di SageMaker Studio utilizzando una configurazione del ciclo di vita. Questo può essere fatto per tutti i profili utente in un dominio SageMaker Studio o per profili specifici. Consultare Personalizzare Amazon SageMaker Studio utilizzando le configurazioni del ciclo di vita per ulteriori dettagli.
È possibile creare una configurazione del ciclo di vita dallo script install-history-server.sh e allegarla a un dominio SageMaker Studio esistente. L’installazione viene eseguita per tutti i profili utente nel dominio.
Da un terminale configurato con l’interfaccia della riga di comando di AWS (AWS CLI) e le autorizzazioni appropriate, eseguire i seguenti comandi:
curl -LO https://github.com/aws-samples/amazon-sagemaker-spark-ui/releases/download/v0.1.0/amazon-sagemaker-spark-ui-0.1.0.tar.gz
tar -xvzf amazon-sagemaker-spark-ui-0.1.0.tar.gz
cd amazon-sagemaker-spark-ui-0.1.0/install-scripts
LCC_CONTENT=`openssl base64 -A -in install-history-server.sh`
aws sagemaker create-studio-lifecycle-config \
--studio-lifecycle-config-name install-spark-ui-on-jupyterserver \
--studio-lifecycle-config-content $LCC_CONTENT \
--studio-lifecycle-config-app-type JupyterServer \
--query 'StudioLifecycleConfigArn'
aws sagemaker update-domain \
--region {YOUR_AWS_REGION} \
--domain-id {YOUR_STUDIO_DOMAIN_ID} \
--default-user-settings \
'{
"JupyterServerAppSettings": {
"DefaultResourceSpec": {
"LifecycleConfigArn": "arn:aws:sagemaker:{YOUR_AWS_REGION}:{YOUR_STUDIO_DOMAIN_ID}:studio-lifecycle-config/install-spark-ui-on-jupyterserver",
"InstanceType": "system"
},
"LifecycleConfigArns": [
"arn:aws:sagemaker:{YOUR_AWS_REGION}:{YOUR_STUDIO_DOMAIN_ID}:studio-lifecycle-config/install-spark-ui-on-jupyterserver"
]
}}'Dopo il riavvio del server Jupyter, l’interfaccia utente di Spark e il sm-spark-cli saranno disponibili nell’ambiente di SageMaker Studio.
Pulizia
In questa sezione, ti mostriamo come pulire l’interfaccia utente di Spark in un dominio di SageMaker Studio, manualmente o automaticamente.
Disinstallare manualmente l’interfaccia utente di Spark
Per disinstallare manualmente l’interfaccia utente di Spark in SageMaker Studio, segui i seguenti passaggi:
- Scegli Terminale di sistema nel launcher di SageMaker Studio.

- Esegui i seguenti comandi nel terminale di sistema:
cd amazon-sagemaker-spark-ui-0.1.0/install-scripts
chmod +x uninstall-history-server.sh
./uninstall-history-server.shDisinstallare automaticamente l’interfaccia utente di Spark per tutti i profili utente di SageMaker Studio
Per disinstallare automaticamente l’interfaccia utente di Spark in SageMaker Studio per tutti i profili utente, segui i seguenti passaggi:
- Nella console di SageMaker, scegli Domini nel riquadro di navigazione, quindi scegli il dominio di SageMaker Studio.

- Nella pagina dei dettagli del dominio, passa alla scheda Ambiente.
- Seleziona la configurazione del ciclo di vita per l’interfaccia utente di Spark in SageMaker Studio.
- Scegli Stacca.

- Elimina e riavvia le app del server Jupyter per i profili utente di SageMaker Studio.

Conclusioni
In questo post, abbiamo condiviso una soluzione che puoi utilizzare per installare rapidamente l’interfaccia utente di Spark su SageMaker Studio. Con l’interfaccia utente di Spark ospitata su SageMaker, i team di machine learning (ML) e data engineering possono utilizzare il calcolo su cloud scalabile per accedere e analizzare i log di Spark da qualsiasi luogo e accelerare la consegna dei loro progetti. Gli amministratori IT possono standardizzare ed accelerare la fornitura della soluzione nel cloud e evitare la proliferazione di ambienti di sviluppo personalizzati per i progetti di ML.
Tutto il codice mostrato in questo post è disponibile nel repository GitHub.