Decodificare la sinfonia del suono Elaborazione del segnale audio per l’Ingegneria Musicale
Decoding the symphony of sound Audio signal processing for Music Engineering
La guida definitiva all’estrazione delle caratteristiche audio nel dominio del tempo e della frequenza utilizzando Python
Immagine di OpenClipart-Vectors da Pixabay
Contenuti
Introduzione
Estrazione delle caratteristiche nel dominio del tempo 2.1 Fondamenti dell’elaborazione del segnale audio: dimensione del frame e lunghezza di salto 2.2 Caratteristica 1: Inviluppo di ampiezza 2.3 Caratteristica 2: Energia media quadratica 2.4 Caratteristica 3: Fattore di cresta 2.5 Caratteristica 4: Tasso di attraversamento dello zero
Estrazione delle caratteristiche nel dominio della frequenza 3.1 Caratteristica 5: Rapporto di energia delle bande 3.2 Caratteristica 6: Centroide spettrale 3.3 Caratteristica 7: Larghezza di banda spettrale 3.4 Caratteristica 8: Pianezza spettrale
Conclusioni
Riferimenti
Introduzione
La capacità di elaborare e analizzare dati di diverso tipo per ottenere informazioni pratiche è una delle competenze più vitali dell’era dell’informazione. I dati sono ovunque: dai libri che leggiamo ai film che guardiamo, dai post di Instagram che ci piacciono alla musica che ascoltiamo. In questo articolo, cercheremo di comprendere i fondamenti dell’Elaborazione del Segnale Audio:
Come legge un computer un segnale audio
Cosa sono le caratteristiche nel dominio del tempo e della frequenza?
Come vengono estratte queste caratteristiche?
Perché è necessario estrarre queste caratteristiche?
In particolare, approfondiremo le seguenti caratteristiche:
Caratteristiche nel dominio del tempo: inviluppo di ampiezza, energia media quadratica, fattore di cresta (e rapporto di potenza picco-valle), tasso di attraversamento dello zero.
Caratteristiche nel dominio della frequenza: rapporto di energia delle bande, centroide spettrale, larghezza di banda spettrale (spread), pianezza spettrale.
Descriveremo la teoria e scriveremo codici Python da zero per estrarre ciascuna di queste caratteristiche per segnali audio provenienti da 3 diversi strumenti musicali: chitarra acustica, strumenti a fiato e batteria. I file audio di esempio utilizzati possono essere scaricati qui: https://github.com/namanlab/Audio-Signal-Processing-Feature-Extraction
L’intero file di codice è disponibile anche nel repository sopra citato o può essere accessibile tramite questo link: https://github.com/namanlab/Audio-Signal-Processing-Feature-Extraction/blob/main/Audio_Signal_Extraction.ipynb
Estrazione delle caratteristiche nel dominio del tempo
Iniziamo ricordando cos’è il suono e come viene percepito da noi. Come alcuni di voi potrebbero ricordare dalle lezioni di scuola superiore, il suono è la propagazione delle vibrazioni attraverso un mezzo. La produzione del suono imposta le molecole d’aria circostanti in vibrazione, che si manifesta in regioni alternate di compressione (alta pressione) e rarefazione (bassa pressione). Queste compressioni e rarefazioni si propagano attraverso il mezzo e raggiungono le nostre orecchie, permettendoci di percepire il suono così com’è. Pertanto, la propagazione del suono comporta la trasmissione di queste variazioni di pressione nel tempo. La rappresentazione nel dominio del tempo del suono implica la cattura e l’analisi di queste variazioni di pressione a diversi intervalli di tempo campionando l’onda sonora in punti discreti nel tempo (tipicamente utilizzando una tecnica di registrazione audio digitale). Ciascun campione rappresenta il livello di pressione del suono in un momento specifico. Tracciando questi campioni, otteniamo una forma d’onda che mostra come il livello di pressione del suono cambia nel tempo. L’asse orizzontale rappresenta il tempo, mentre l’asse verticale rappresenta l’ampiezza o l’intensità del suono, di solito scalata per adattarsi tra -1 e 1, dove i valori positivi indicano compressione e i valori negativi indicano rarefazione. Questo ci aiuta a dare una rappresentazione visiva delle caratteristiche dell’onda sonora, come la sua ampiezza, frequenza e durata.
Fondamenti della propagazione del suono [Immagine di Author]
Per estrarre la forma d’onda di un determinato audio utilizzando Python, iniziamo caricando i pacchetti necessari:
import numpy as npimport matplotlib.pyplot as pltimport librosaimport librosa.displayimport IPython.display as ipdimport scipy as spp
NumPy è un popolare pacchetto Python per il processo e il lavoro con array e matrici. Contiene una vasta gamma di strumenti dall’algebra lineare a semplificare molte attività!
librosa è il pacchetto Python per il processo e l’analisi audio e contiene diverse funzioni e strumenti per rendere piuttosto facile sfruttare diversi tipi di caratteristiche audio. Come detto in precedenza, analizzeremo le forme d’onda per 3 diversi strumenti musicali: Chitarra acustica, Ottone e Batteria. Puoi scaricare i file audio dal link condiviso in precedenza e caricarli nel tuo repository locale. Per ascoltare i file audio utilizziamo IPython.display. Il codice è riportato di seguito:
# Ascolta i file audio# Assicurati che il percorso relativo/assoluto dei file audio sia corretto.acoustic_guitar_path = "acoustic_guitar.wav"ipd.Audio(acoustic_guitar_path)brass_path = "brass.wav"ipd.Audio(brass_path)# Mantieni il volume basso!drum_set_path = "drum_set.wav"ipd.Audio(drum_set_path)
In seguito, carichiamo i file musicali in librosa utilizzando la funzione librosa.load(). Questa funzione ci consente di analizzare il file audio e restituire due oggetti:
y (Array NumPy): Contiene i valori di ampiezza per diversi intervalli di tempo. Prova a stampare l’array per vederlo!
sr (numero > 0): Frequenza di campionamento
La frequenza di campionamento si riferisce al numero di campioni prelevati per unità di tempo durante la conversione di un segnale analogico nella sua rappresentazione digitale. Come discusso in precedenza, la variazione di pressione attraverso la VoAGI costituisce un segnale analogico, uno che ha una forma d’onda che varia continuamente nel tempo. Teoricamente, memorizzare dati continui richiederebbe una quantità infinita di spazio. Pertanto, al fine di elaborare e memorizzare questi segnali analogici in modo digitale, è necessario convertirli in una rappresentazione discreta. Qui entra in gioco il campionamento per catturare screenshot dell’onda sonora a intervalli di tempo discreti (uniformemente spaziati). Lo spazio tra questi intervalli è catturato dall’inverso della frequenza di campionamento.
La frequenza di campionamento determina con quale frequenza vengono prelevati campioni dal segnale analogico ed è quindi misurata in campioni al secondo o hertz (Hz). Una frequenza di campionamento più elevata significa che vengono prelevati più campioni ogni secondo, risultando in una rappresentazione più accurata del segnale analogico originale, ma richiedendo più risorse di memoria. Al contrario, una frequenza di campionamento più bassa significa che vengono prelevati meno campioni ogni secondo, risultando in una rappresentazione meno accurata del segnale analogico originale, ma richiedendo meno risorse di memoria.
La frequenza di campionamento predefinita solita è 22050. Tuttavia, in base all’applicazione/memoria, l’utente può scegliere una frequenza di campionamento più bassa o più alta, che può essere specificata dall’argomento sr di librosa.load(). Quando si sceglie una frequenza di campionamento appropriata per la conversione analogico-digitale, potrebbe essere importante conoscere il teorema del campionamento di Nyquist-Shannon, che afferma che al fine di catturare e ricostruire accuratamente un segnale analogico, la frequenza di campionamento deve essere almeno il doppio della componente di frequenza più alta presente nel segnale audio (chiamata Frequenza/Tasso di Nyquist).
Campionando a una frequenza superiore alla Frequenza di Nyquist, possiamo evitare un fenomeno chiamato aliasing, che può distorto il segnale originale. La discussione sull’aliasing non è particolarmente rilevante per lo scopo di questo articolo. Se sei interessato a saperne di più, ecco una fonte eccellente: https://thewolfsound.com/what-is-aliasing-what-causes-it-how-to-avoid-it/
Di seguito è riportato il codice per leggere i segnali audio:
# Carica la musica in librosasr = 22050acoustic_guitar, sr = librosa.load(acoustic_guitar_path, sr = sr)brass, sr = librosa.load(brass_path, sr = sr)drum_set, sr = librosa.load(drum_set_path, sr = sr)
Nell’esempio precedente, la frequenza di campionamento è di 22050 (che è anche la frequenza predefinita). Eseguendo il codice precedente vengono restituiti 3 array, ciascuno dei quali memorizza i valori di ampiezza in intervalli di tempo discreti (specificati dalla frequenza di campionamento). Successivamente, visualizziamo le forme d’onda per ciascuno dei 3 campioni audio utilizzando librosa.display.waveshow(). È stata aggiunta un po’ di trasparenza (impostando alpha = 0.5) per una visualizzazione più chiara della densità di ampiezza nel tempo.
def show_waveform(signal, name=""): # Crea una nuova figura con una dimensione specifica plt.figure(figsize=(15, 7)) # Mostra la forma d'onda del segnale usando librosa librosa.display.waveshow(signal, alpha=0.5) # Imposta il titolo del grafico plt.title("Forma d'onda per " + name) # Mostra il grafico plt.show()show_waveform(acoustic_guitar, "Chitarra acustica")show_waveform(brass, "Ottone")show_waveform(drum_set, "Batteria")
Waveform per Chitarra Acustica [Immagine dell’Autore]Waveform per Ottone [Immagine dell’Autore]Waveform per Set di Batteria [Immagine dell’Autore]
Prenditi del tempo per esaminare i grafici sopra riportati. Pensa ai pattern che vedi. Nella waveform della chitarra acustica, possiamo identificare un pattern periodico caratterizzato da oscillazioni regolari nell’ampiezza, che riflettono la natura armonicamente ricca del suono della chitarra. Le oscillazioni corrispondono alle vibrazioni prodotte dalle corde pizzicate che generano una complessa waveform composta da molteplici armoniche che contribuiscono al tono e al timbro caratteristici della chitarra.
Allo stesso modo, la waveform per l’ottone mostra anche un pattern periodico che determina un’intonazione e un timbro costanti. Gli strumenti a fiato producono suoni attraverso il ronzio delle labbra del musicista nel bocchino. Questa azione di ronzio genera una waveform con armoniche distinte e un pattern regolare di variazioni di ampiezza.
Al contrario, la waveform di un set di batteria non mostra un chiaro pattern periodico poiché le percussioni producono suoni attraverso l’impatto di una bacchetta o di una mano su una pelle del tamburo o altre superfici percosse, creando waveform complesse e irregolari, con ampiezze e durate variabili. L’assenza di un pattern periodico evidente riflette la natura percussiva e non tonale dei suoni della batteria.
Fondamenti dell’Elaborazione del Segnale Audio: Dimensione del Frame e Lunghezza dell’Avanzamento
Prima di discutere le importanti caratteristiche temporali dell’elaborazione del segnale audio, è fondamentale parlare di due parametri vitali per l’estrazione delle caratteristiche: la dimensione del frame e la lunghezza dell’avanzamento. Di solito, una volta che un segnale è stato elaborato digitalmente, viene diviso in frame (un insieme di intervalli di tempo discreti che possono sovrapporsi o meno). La dimensione del frame descrive la dimensione di questi frame, mentre la lunghezza dell’avanzamento contiene informazioni su quanto i frame si sovrappongono. Ma, perché è importante la frammentazione?
Lo scopo della frammentazione è quello di catturare la variazione temporale delle diverse caratteristiche del segnale. I metodi di estrazione delle caratteristiche usuali forniscono un riassunto numerico del segnale di input (ad esempio, media, minimo o massimo). Il problema nell’utilizzare direttamente questi metodi di estrazione delle caratteristiche è che ciò annulla completamente qualsiasi informazione associata al tempo. Ad esempio, se sei interessato a calcolare l’ampiezza media del tuo segnale, ottieni un riassunto numerico singolo, diciamo x. Tuttavia, naturalmente, ci sono intervalli in cui la media è minore e altri in cui la media è maggiore. L’uso di un riassunto numerico singolo elimina ogni informazione sulla variazione temporale della media. La soluzione, quindi, è suddividere i segnali in frame come ad esempio [0 ms, 10 ms), [10 ms, 20 ms), … Successivamente, viene calcolata la media per la porzione del segnale in ciascuno di questi intervalli di tempo e questo insieme collettivo di caratteristiche fornisce il vettore delle caratteristiche estratte finale, un riassunto delle caratteristiche dipendente dal tempo, non è fantastico?
Ora, parliamo dei due parametri in dettaglio:
Dimensione del Frame: Descrive la dimensione di ciascun frame. Ad esempio, se la dimensione del frame è 1024, includi 1024 campioni in ogni frame e calcoli le caratteristiche necessarie per ciascuno di questi insiemi di 1024 campioni. In generale, è consigliabile avere la dimensione del frame come una potenza di 2. La ragione di ciò non è importante ai fini di questo articolo. Ma se sei curioso, è perché la Trasformata di Fourier Rapida (un algoritmo molto efficiente per trasformare un segnale dal dominio del tempo al dominio della frequenza) richiede che i frame abbiano una dimensione che sia una potenza di 2. Ne parleremo di più nelle sezioni successive.
Lunghezza dell’Avanzamento: Si riferisce al numero di campioni di cui un frame si sposta in avanti ad ogni passo lungo la sequenza di dati, ovvero il numero di campioni che spostiamo a destra prima di generare un nuovo frame. Può essere utile pensare al frame come a una finestra scorrevole che si sposta lungo il segnale in passi definiti dalla lunghezza dell’avanzamento. Ad ogni passo, la finestra viene applicata a una nuova sezione del segnale o della sequenza e viene eseguita l’estrazione delle caratteristiche su quel segmento. La lunghezza dell’avanzamento, quindi, determina la sovrapposizione tra i frame audio consecutivi. Una lunghezza dell’avanzamento uguale alla dimensione del frame significa che non c’è sovrapposizione poiché ogni frame inizia esattamente dove finisce il precedente. Tuttavia, per mitigare l’impatto di un fenomeno chiamato perdita spettrale (che si verifica durante la conversione di un segnale dal suo dominio temporale a quello delle frequenze), viene applicata una funzione di finestra che comporta la perdita di dati intorno ai bordi di ciascun frame (la spiegazione tecnica va oltre lo scopo di questo articolo, ma se sei curioso, sentiti libero di consultare questo link: https://dspillustrations.com/pages/posts/misc/spectral-leakage-zero-padding-and-frequency-resolution.html). Pertanto, spesso si scelgono lunghezze di avanzamento intermedie per preservare i campioni di bordo, ottenendo così gradi variabili di sovrapposizione tra i frame.
In generale, una lunghezza di passo più piccola fornisce una maggiore risoluzione temporale che ci permette di catturare più dettagli e cambiamenti rapidi nel segnale. Tuttavia, aumenta anche i requisiti di memoria. Al contrario, una lunghezza di passo più grande riduce la risoluzione temporale ma aiuta anche a ridurre la complessità dello spazio.
Dimensione del frame e lunghezza del passo [Immagine dell’autore]
Nota: per una visualizzazione più chiara, la dimensione del frame viene mostrata come piuttosto grande nell’immagine sopra. Per scopi pratici, la dimensione del frame scelta è molto più piccola (forse alcune migliaia di campioni, circa 20-40 ms).
Prima di procedere con i diversi metodi di estrazione delle caratteristiche nel dominio temporale, chiariremo alcune notazioni matematiche. Utilizzeremo le seguenti notazioni in tutto questo articolo:
xᵢ: l’ampiezza dell’i-esimo campione
K: Dimensione del frame
H: Lunghezza del passo
Caratteristica 1: Inviluppo dell’ampiezza
Prima di tutto, parliamo dell’inviluppo dell’ampiezza. Questa è una delle caratteristiche più facili da calcolare (ma molto utili) nell’analisi del dominio temporale. L’inviluppo dell’ampiezza per un frame di un segnale audio è semplicemente il valore massimo della sua ampiezza in quel frame. Matematicamente, l’inviluppo dell’ampiezza (per frame non sovrapposti) del k-esimo frame è dato da:
In generale, per qualsiasi frame k che contiene campioni xⱼ₁ , xⱼ₂ , · · · , xⱼₖ, l’inviluppo dell’ampiezza è:
Il codice Python per calcolare l’inviluppo dell’ampiezza di un dato segnale è il seguente:
DIMENSIONE_FRAME = 1024LUNGHEZZA_PASSO = 512def inviluppo_ampiezza(segnale, dimensione_frame=1024, lunghezza_passo=512): """ Calcola l'inviluppo dell'ampiezza di un segnale utilizzando una finestra scorrevole. Args: segnale (array): Il segnale di input. dimensione_frame (int): La dimensione di ogni frame in campioni. lunghezza_passo (int): Il numero di campioni tra frame consecutivi. Returns: np.array: Un array di valori di inviluppo dell'ampiezza. """ res = [] for i in range(0, len(segnale), lunghezza_passo): # Ottieni una porzione del segnale porzione_corrente = segnale[i:i + dimensione_frame] # Calcola il valore massimo nella porzione val_ia = max(porzione_corrente) # Memorizza il valore dell'inviluppo dell'ampiezza res.append(val_ia) # Converte il risultato in un array NumPy return np.array(res)def traccia_inviluppo_ampiezza(segnale, nome, dimensione_frame=1024, lunghezza_passo=512): """ Traccia l'onda del segnale con sovrapposizione dei valori dell'inviluppo dell'ampiezza. Args: segnale (array): Il segnale di input. nome (str): Il nome del segnale per il titolo del grafico. dimensione_frame (int): La dimensione di ogni frame in campioni. lunghezza_passo (int): Il numero di campioni tra frame consecutivi. """ # Calcola l'inviluppo dell'ampiezza ia = inviluppo_ampiezza(segnale, dimensione_frame, lunghezza_passo) # Genera gli indici dei frame frames = range(0, len(ia)) # Converte i frame in tempo tempo = librosa.frames_to_time(frames, hop_length=lunghezza_passo) # Crea un nuovo grafico con una dimensione specifica plt.figure(figsize=(15, 7)) # Mostra l'onda del segnale librosa.display.waveshow(segnale, alpha=0.5) # Traccia l'inviluppo dell'ampiezza nel tempo plt.plot(tempo, ia, color="r") # Imposta il titolo del grafico plt.title("Onda per " + nome + " (Inviluppo dell'ampiezza)") # Mostra il grafico plt.show() traccia_inviluppo_ampiezza(chitarra_acustica, "Chitarra Acustica")traccia_inviluppo_ampiezza(ottone, "Ottone")traccia_inviluppo_ampiezza(batteria, "Set di Batteria")
Nel codice sopra, abbiamo definito una funzione chiamata amplitude_envelope che prende in ingresso l’array del segnale di input (generato utilizzando la funzione librosa.load()), la dimensione del frame (K) e la lunghezza di salto (H), restituendo un array di dimensione uguale al numero di frame. Il valore k-esimo nell’array corrisponde al valore dell’involucro dell’ampiezza per il k-esimo frame. Il calcolo viene effettuato utilizzando un semplice ciclo for che scorre l’intero segnale con passi determinati dalla lunghezza di salto. Viene definita una lista (res) per memorizzare questi valori che viene infine convertita in un array NumPy prima di essere restituita. Un’altra funzione chiamata plot_amplitude envelope è definita che prende gli stessi input (insieme a un argomento name) e sovrappone il grafico dell’involucro dell’ampiezza sul frame originale. Per tracciare la forma d’onda, è stata utilizzata la funzione tradizionale librosa.display.waveform(), come spiegato nella sezione precedente.
Per tracciare l’involucro dell’ampiezza, abbiamo bisogno del tempo e dei corrispondenti valori dell’involucro dell’ampiezza. I valori di tempo vengono ottenuti utilizzando la funzione molto utile librosa.frames_to_times(), che richiede due input: un iterabile corrispondente al numero di frame (che è definito utilizzando la funzione range) e la lunghezza di salto) per generare il tempo medio per ogni frame. Successivamente, viene utilizzato matplotlib.pyplot per sovrapporre il grafico rosso. Il processo descritto sopra verrà utilizzato in modo coerente per tutti i metodi di estrazione delle caratteristiche nel dominio temporale.
Le seguenti figure mostrano l’involucro dell’ampiezza calcolato per ciascuno degli strumenti musicali. Sono stati aggiunti come una linea rossa sulla forma d’onda originale e tendono ad approssimare il limite superiore della forma d’onda. L’involucro dell’ampiezza non solo conserva il modello periodico, ma indica anche la differenza generale nelle ampiezze audio come riflessa nelle intensità più basse dei fiati rispetto alla chitarra acustica e alla batteria.
Involucro dell’ampiezza per chitarra acustica [Immagine dell’autore]Involucro dell’ampiezza per strumenti a fiato [Immagine dell’autore]Involucro dell’ampiezza per set di batteria [Immagine dell’autore]
Caratteristica 2: Energia media quadratica radice
Successivamente, parliamo dell’energia media quadratica radice (RMSE), un’altra caratteristica vitale nell’analisi del dominio temporale. L’energia media quadratica radice per un frame di un segnale audio viene ottenuta prendendo la radice quadrata della media del quadrato di tutti i valori di ampiezza in un frame. Matematicamente, l’energia media quadratica radice (per frame non sovrapposti) del k-esimo frame è data da:
In generale, per qualsiasi frame k contenente campioni xⱼ₁ , xⱼ₂ , · · · , xⱼₖ, l’RMSE è:
L’energia RMS fornisce una rappresentazione dell’intensità complessiva o della potenza di un segnale sonoro tenendo conto sia delle escursioni positive che negative della forma d’onda, fornendo una misura più accurata della potenza del segnale rispetto ad altre misure come l’ampiezza di picco. Il codice Python per calcolare l’RMSE di un segnale dato è riportato di seguito. La struttura del codice è la stessa per la generazione dell’involucro dell’ampiezza. L’unica differenza è nella funzione utilizzata per l’estrazione della caratteristica. Invece del valore massimo, il valore RMSE viene calcolato prendendo la media dei valori quadrati nella porzione corrente del segnale seguita dalla radice quadrata.
def RMS_energy(signal, frame_size=1024, hop_length=512): """ Calcola l'energia RMS (Root Mean Square) di un segnale utilizzando una finestra scorrevole. Args: signal (array): Il segnale di input. frame_size (int): La dimensione di ogni frame in campioni. hop_length (int): Il numero di campioni tra frame consecutivi. Returns: np.array: Un array di valori di energia RMS. """ res = [] for i in range(0, len(signal), hop_length): # Estrai una porzione del segnale cur_portion = signal[i:i + frame_size] # Calcola l'energia RMS per la porzione rmse_val = np.sqrt(1 / len(cur_portion) * sum(i**2 for i in cur_portion)) res.append(rmse_val) # Converti il risultato in un array NumPy return np.array(res)def plot_RMS_energy(signal, name, frame_size=1024, hop_length=512): """ Traccia la forma d'onda di un segnale con la sovrapposizione dei valori di energia RMS. Args: signal (array): Il segnale di input. name (str): Il nome del segnale per il titolo del grafico. frame_size (int): La dimensione di ogni frame in campioni. hop_length (int): Il numero di campioni tra frame consecutivi. """ # Calcola l'energia RMS rmse = RMS_energy(signal, frame_size, hop_length) # Genera gli indici dei frame frames = range(0, len(rmse)) # Converti i frame in tempo time = librosa.frames_to_time(frames, hop_length=hop_length) # Crea una nuova figura con una dimensione specifica plt.figure(figsize=(15, 7)) # Mostra la forma d'onda come un grafico simile a uno spettrogramma librosa.display.waveshow(signal, alpha=0.5) # Traccia i valori di energia RMS plt.plot(time, rmse, color="r") # Imposta il titolo del grafico plt.title("Forma d'onda per " + name + " (Energia RMS)") plt.show()plot_RMS_energy(acoustic_guitar, "Chitarra acustica")plot_RMS_energy(brass, "Fiati")plot_RMS_energy(drum_set, "Set di batteria")
Le seguenti figure mostrano l’energia RMS calcolata per ciascuno degli strumenti musicali. Sono state aggiunte come linea rossa sopra la forma d’onda originale e tendono ad approssimare il centro di massa della forma d’onda. Come prima, questa misura non solo preserva il modello periodico ma approssima anche il livello di intensità complessivo dell’onda sonora.
RMSE per Chitarra Acustica [Immagine dell’autore]RMSE per Brass [Immagine dell’autore]RMSE per Batteria [Immagine dell’autore]
Caratteristica 3: Fattore di Cresta
Ora, parliamo del fattore di cresta, una misura della estremità dei picchi nella forma d’onda. Il fattore di cresta per un frame di un segnale audio è ottenuto dividendo l’ampiezza di picco (il valore assoluto più grande dell’ampiezza) per l’energia RMS. Matematicamente, il fattore di cresta (per frame non sovrapposti) del k-esimo frame è dato da:
In generale, per qualsiasi frame k che contiene campioni xⱼ₁ , xⱼ₂ , · · · , xⱼₖ, il fattore di cresta è:
Il fattore di cresta indica il rapporto tra il livello del picco più alto e il livello di intensità medio di una forma d’onda. Il codice Python per calcolare il fattore di cresta di un segnale dato è il seguente. La struttura segue quanto sopra, coinvolgendo il calcolo del valore RMSE (il denominatore) e il valore di picco più alto (il numeratore), che viene poi utilizzato per ottenere la frazione desiderata (il fattore di cresta!).
def fattore_cresta(segnale, dimensione_frame=1024, lunghezza_hop=512): """ Calcola il fattore di cresta di un segnale utilizzando una finestra scorrevole. Args: segnale (array): Il segnale di input. dimensione_frame (int): La dimensione di ogni frame in campioni. lunghezza_hop (int): Il numero di campioni tra i frame consecutivi. Returns: np.array: Un array di valori di fattore di cresta. """ res = [] for i in range(0, len(segnale), lunghezza_hop): # Ottieni una porzione del segnale porzione_corrente = segnale[i:i + dimensione_frame] # Calcola l'energia RMS per la porzione valore_rmse = np.sqrt(1 / len(porzione_corrente) * sum(i ** 2 for i in porzione_corrente)) # Calcola il fattore di cresta valore_cresta = max(np.abs(porzione_corrente)) / valore_rmse # Memorizza il valore del fattore di cresta res.append(valore_cresta) # Converti il risultato in un array NumPy return np.array(res) def plot_fattore_cresta(segnale, nome, dimensione_frame=1024, lunghezza_hop=512): """ Traccia il fattore di cresta di un segnale nel tempo. Args: segnale (array): Il segnale di input. nome (str): Il nome del segnale per il titolo del grafico. dimensione_frame (int): La dimensione di ogni frame in campioni. lunghezza_hop (int): Il numero di campioni tra i frame consecutivi. """ # Calcola il fattore di cresta cresta = fattore_cresta(segnale, dimensione_frame, lunghezza_hop) # Genera gli indici dei frame frame = range(0, len(cresta)) # Converti i frame in tempo tempo = librosa.frames_to_time(frame, hop_length=lunghezza_hop) # Crea una nuova figura con una dimensione specifica plt.figure(figsize=(15, 7)) # Traccia il fattore di cresta nel tempo plt.plot(tempo, cresta, color="r") # Imposta il titolo del grafico plt.title(nome + " (Fattore di Cresta)") # Mostra il grafico plt.show() plot_fattore_cresta(chitarra_acustica, "Chitarra Acustica")plot_fattore_cresta(brass, "Brass")plot_fattore_cresta(batteria, "Batteria")
Le seguenti figure mostrano il fattore di cresta calcolato per ciascuno degli strumenti musicali:
Fattore di cresta per chitarra acustica [Immagine dell’autore]Fattore di cresta per ottoni [Immagine dell’autore]Fattore di cresta per ottoni insieme [Immagine dell’autore]
Un fattore di cresta più elevato, come si può osservare per chitarra acustica e ottoni, indica una maggiore differenza tra i livelli di picco e i livelli medi, suggerendo un segnale più dinamico o “piccante” con maggiori variazioni di ampiezza. Un fattore di cresta più basso, come si può osservare per una batteria, suggerisce un segnale più uniforme o compresso con variazioni minori di ampiezza. Il fattore di cresta è particolarmente rilevante nei casi in cui è indispensabile considerare il margine di testa o la gamma dinamica disponibile del sistema. Ad esempio, un alto fattore di cresta in una registrazione musicale potrebbe richiedere un’attenta considerazione per evitare distorsioni o clipping durante la riproduzione su apparecchiature con limitato margine di testa.
In realtà, esiste un’altra caratteristica chiamata rapporto di potenza picco-valore medio (PAPR), strettamente correlata al fattore di cresta. Il PAPR è semplicemente il valore al quadrato del fattore di cresta, generalmente convertito in un rapporto di potenza in decibel. In generale, per qualsiasi frame k contenente campioni xⱼ₁ , xⱼ₂ , · · · , xⱼₖ, il rapporto di potenza picco-valore medio è:
Come sfida divertente, prova a modificare il codice sopra per generare un grafico del PAPR per ciascuno dei 3 strumenti musicali e analizza i risultati.
Caratteristica 4: Tasso di attraversamenti dello zero
Infine, parleremo del tasso di attraversamenti dello zero (ZCR). Il tasso di attraversamenti dello zero per un frame di un segnale audio è semplicemente il numero di volte che il segnale attraversa lo zero (l’asse x/tempo). Matematicamente, lo ZCR (per frame non sovrapposti) del k-esimo frame è dato da:
Se i valori consecutivi hanno lo stesso segno, l’espressione all’interno del valore assoluto si annulla, dando 0. Se hanno segni opposti (indicando che il segnale ha attraversato l’asse temporale), i valori si sommano dando 2 (dopo aver preso il valore assoluto). Poiché ogni attraversamento dello zero dà un valore di 2, moltiplichiamo il risultato per un fattore di metà per ottenere il conteggio richiesto. In generale, per qualsiasi frame k contenente campioni xⱼ₁ , xⱼ₂ , · · · , xⱼₖ, lo ZCR è:
Si noti che, nell’espressione precedente, il tasso di attraversamenti dello zero è calcolato semplicemente sommando il numero di volte in cui il segnale attraversa l’asse. Tuttavia, a seconda dell’applicazione, è anche possibile normalizzare i valori (dividendo per la lunghezza del frame). Il codice Python per il calcolo del fattore di cresta di un segnale dato è riportato di seguito. La struttura segue quanto sopra, con la definizione di un’altra funzione chiamata num sign changes, che determina il numero di volte in cui cambia il segno nel segnale dato.
def ZCR(signal, frame_size=1024, hop_length=512): """ Calcola il tasso di attraversamenti dello zero (ZCR) di un segnale utilizzando una finestra scorrevole. Args: signal (array): Il segnale di input. frame_size (int): La dimensione di ogni frame in campioni. hop_length (int): Il numero di campioni tra frame consecutivi. Returns: np.array: Un array di valori ZCR. """ res = [] for i in range(0, len(signal), hop_length): # Ottieni una porzione del segnale cur_portion = signal[i:i + frame_size] # Calcola il numero di cambi di segno nella porzione zcr_val = num_sign_changes(cur_portion) # Memorizza il valore ZCR res.append(zcr_val) # Converti il risultato in un array NumPy return np.array(res) def num_sign_changes(signal): """ Calcola il numero di cambi di segno in un segnale. Args: signal (array): Il segnale di input. Returns: int: Il numero di cambi di segno. """ res = 0 for i in range(0, len(signal) - 1): # Verifica se c'è un cambio di segno tra campioni consecutivi if (signal[i] * signal[i + 1] < 0): res += 1 return resdef plot_ZCR(signal, name, frame_size=1024, hop_length=512): """ Traccia il tasso di attraversamenti dello zero (ZCR) di un segnale nel tempo. Args: signal (array): Il segnale di input. name (str): Il nome del segnale per il titolo del grafico. frame_size (int): La dimensione di ogni frame in campioni. hop_length (int): Il numero di campioni tra frame consecutivi. """ # Calcola lo ZCR zcr = ZCR(signal, frame_size, hop_length) # Genera gli indici dei frame frames = range(0, len(zcr)) # Converti i frame in tempo time = librosa.frames_to_time(frames, hop_length=hop_length) # Crea un nuovo grafico con una dimensione specifica plt.figure(figsize=(15, 7)) # Traccia lo ZCR nel tempo plt.plot(time, zcr, color="r") # Imposta il titolo del grafico plt.title(name + " (Tasso di attraversamenti dello zero)") # Mostra il grafico plt.show() plot_ZCR(acoustic_guitar, "Chitarra acustica")plot_ZCR(brass, "Ottoni")plot_ZCR(drum_set, "Batteria")
Le seguenti figure mostrano il tasso di attraversamento dello zero calcolato per ciascuno degli strumenti musicali.
Attraversamento dello zero per chitarra acustica [Immagine di Autore]Attraversamento dello zero per ottoni [Immagine di Autore]Attraversamento dello zero per batteria [Immagine di Autore]
Un tasso di attraversamento dello zero più elevato indica che il segnale cambia direzione frequentemente, suggerendo la presenza di componenti ad alta frequenza o un’onda più dinamica. Al contrario, un tasso di attraversamento dello zero più basso indica un’onda relativamente più fluida o costante.
Il tasso di attraversamento dello zero è particolarmente utile nelle applicazioni di analisi del parlato e della musica grazie alla sua capacità di fornire indicazioni sulle proprietà come il timbro e i pattern ritmici. Ad esempio, nell’analisi del parlato, il tasso di attraversamento dello zero aiuta a distinguere tra suoni vocalizzati e non vocalizzati poiché i suoni vocalizzati tendono ad avere un tasso di attraversamento dello zero più elevato a causa delle vibrazioni delle corde vocali. È fondamentale notare che, sebbene il tasso di attraversamento dello zero sia una caratteristica semplice ed efficiente dal punto di vista computazionale, potrebbe non catturare tutti gli aspetti della complessità di un segnale (come si può vedere nelle figure sopra, la periodicità è completamente persa). Pertanto, spesso viene utilizzato in combinazione con altre caratteristiche per un’analisi più completa dei segnali audio.
Estrazione delle caratteristiche nel dominio delle frequenze
Il dominio delle frequenze offre una rappresentazione alternativa di un’onda audio. A differenza del dominio temporale, in cui il segnale è rappresentato come una funzione del tempo, nel dominio delle frequenze il segnale è decomposto nelle sue frequenze costituenti, rivelando le informazioni di ampiezza e fase associate a ciascuna frequenza, ovvero il segnale è rappresentato come una funzione della frequenza. Invece di guardare l’ampiezza del segnale in vari punti nel tempo, esaminiamo le ampiezze dei diversi componenti di frequenza che costituiscono il segnale. Ciascun componente di frequenza rappresenta un’onda sinusoidale di una determinata frequenza e combinando questi componenti possiamo ricostruire il segnale originale nel dominio temporale.
Lo strumento matematico (più comune) utilizzato per convertire un segnale dal dominio temporale al dominio delle frequenze è la trasformata di Fourier. La trasformata di Fourier prende in input il segnale e lo decompone in una somma di onde sinusoidali e cosinusoidali di frequenze variabili con la propria ampiezza e fase. La rappresentazione risultante è ciò che costituisce lo spettro delle frequenze. Matematicamente, la trasformata di Fourier di un segnale continuo nel suo dominio temporale g(t) è definita come segue:
dove i = √−1 è il numero immaginario. Sì, la trasformata di Fourier produce un output complesso, con la fase e l’ampiezza corrispondenti a quelle dell’onda sinusoidale costituente! Tuttavia, per la maggior parte delle applicazioni, ci interessa solo l’ampiezza della trasformata e semplicemente ignoriamo la fase associata. Poiché il suono elaborato digitalmente è discreto, possiamo definire la corrispondente trasformata di Fourier discreta (DFT):
dove T è la durata di un campione. In termini di frequenza di campionamento:
Poiché le rappresentazioni delle frequenze sono anche continue, valutiamo la trasformata di Fourier su intervalli di frequenza discretizzati per ottenere una rappresentazione discreta del dominio delle frequenze dell’onda audio. Questo è chiamato trasformata di Fourier a breve termine. Matematicamente,
Non ti preoccupare! Rivediamolo attentamente. L’operazione h(h) è la funzione che mappa un intero k ∈ {0, 1, · · · , N − 1} alla magnitudine della frequenza k · Sᵣ/N. Nota che consideriamo solo i bin di frequenza discreti che sono multipli interi di Sᵣ/N, dove N è il numero di campioni nel segnale. Se sei ancora incerto su come funziona, ecco una spiegazione eccellente delle trasformate di Fourier: https://www.youtube.com/watch?v=spUNpyF58BY&t=393s
La trasformata di Fourier è una delle più belle innovazioni matematiche, quindi vale la pena saperne di più, anche se la discussione non è specificamente rilevante per lo scopo di questo articolo. In Python, puoi ottenere facilmente la trasformata di Fourier a breve termine utilizzando librosa.stft().
Nota: Per dati audio di grandi dimensioni, esiste un modo più efficiente per calcolare la trasformata di Fourier, chiamato Trasformata di Fourier Rapida (FFT), sentiti libero di darci un’occhiata se sei curioso!
Come prima, non siamo interessati solo a sapere quali frequenze sono più dominanti: vogliamo anche mostrare quando queste frequenze sono dominanti. Quindi, cerchiamo una rappresentazione simultanea di frequenza-tempo che mostra quali frequenze dominano in quale punto nel tempo. Qui entra in gioco il framing: dividiamo il segnale in frame temporali e otteniamo la magnitudine della trasformata di Fourier risultante in ogni frame. Questo ci dà una matrice di valori, dove il numero di righe è dato dal numero di bin di frequenza (Φ, di solito uguale a K/2 + 1, dove K è la dimensione del frame), e il numero di colonne è dato dal numero di frame. Poiché la trasformata di Fourier restituisce un output a valori complessi, la matrice generata è a valori complessi. In Python, la dimensione del frame e i parametri di lunghezza del salto possono essere facilmente specificati come argomenti e la matrice risultante può essere semplicemente calcolata utilizzando librosa.stft(segnale, n_fft=dimensione del frame, hop length=lunghezza del salto). Poiché ci interessa solo la magnitudine, possiamo usare numpy.abs() per convertire la matrice a valori complessi in una a valori reali. È molto conveniente tracciare la matrice ottenuta per avere una rappresentazione visivamente accattivante del segnale che fornisce preziose informazioni sul contenuto di frequenza e sulle caratteristiche temporali del suono dato. La cosiddetta rappresentazione è chiamata Spettrogramma.
Gli spettrogrammi vengono ottenuti tracciando i frame temporali sull’asse x e i bin di frequenza sull’asse y. I colori vengono quindi utilizzati per indicare l’intensità o la magnitudine della frequenza per il dato frame temporale. Di solito, l’asse delle frequenze viene convertito in una scala logaritmica (poiché è noto che gli esseri umani le percepiscono meglio sotto una trasformazione logaritmica), e la magnitudine viene espressa in decibel.
Il codice Python per generare uno spettrogramma è mostrato di seguito:
FRAME_SIZE = 1024HOP_LENGTH = 512def plot_spectrogram(signal, sample_rate, frame_size=1024, hop_length=512): """ Traccia lo spettrogramma di un segnale audio. Args: signal (array-like): Il segnale audio in ingresso. sample_rate (int): Il tasso di campionamento del segnale audio. frame_size (int): La dimensione di ogni frame in campioni. hop_length (int): Il numero di campioni tra frame consecutivi. """ # Calcola la STFT spettrogramma = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # Converti la STFT in scala dB spettrogramma_db = librosa.amplitude_to_db(np.abs(spettrogramma)) # Crea una nuova figura con una dimensione specifica plt.figure(figsize=(15, 7)) # Mostra lo spettrogramma librosa.display.specshow(spettrogramma_db, sr=sample_rate, hop_length=hop_length, x_axis='time', y_axis='log') # Aggiungi una barra dei colori per mostrare la scala della magnitudine plt.colorbar(format='%+2.0f dB') # Imposta il titolo del grafico plt.title('Spettrogramma') # Imposta l'etichetta per l'asse x plt.xlabel('Tempo') # Imposta l'etichetta per l'asse y plt.ylabel('Frequenza (Hz)') # Regola il layout del grafico plt.tight_layout() # Mostra il grafico plt.show() plot_spectrogram(acoustic_guitar, sr)plot_spectrogram(brass, sr)plot_spectrogram(drum_set, sr)
Nel codice sopra, abbiamo definito una funzione chiamata plot_spectrogram che prende in input 4 argomenti: l’array del segnale di ingresso, il tasso di campionamento, la dimensione del frame e la lunghezza del salto. Prima, viene utilizzato librosa.stft() per ottenere la matrice dello spettrogramma. Successivamente, np.abs() viene utilizzato per estrarre la magnitudine seguita da una conversione dei valori di ampiezza in decibel utilizzando la funzione librosa.amplitude_to_db(). Infine, viene utilizzata la funzione librosa.display.specshow() per tracciare lo spettrogramma. Questa funzione prende in input la matrice dello spettrogramma trasformato, il tasso di campionamento, la lunghezza del salto e le specifiche per gli assi x e y. Un asse y trasformato in logaritmo può essere specificato utilizzando l’argomento y_axis = ‘log’. È possibile aggiungere una barra dei colori opzionale utilizzando plt.colorbar(). Gli spettrogrammi risultanti per i 3 strumenti musicali sono mostrati di seguito:
Spectrogram per Chitarra Acustica [Immagine di Autore]Spectrogram per Strumenti a Fiato [Immagine di Autore]Spectrogram per Batteria [Immagine di Autore]
Lo spettrogramma offre un modo unico di visualizzare il trade-off tempo-frequenza. Il dominio del tempo ci fornisce una rappresentazione precisa di come un segnale evolve nel tempo, mentre il dominio della frequenza ci permette di vedere la distribuzione di energia tra diverse frequenze. Ciò ci consente di identificare non solo la presenza di frequenze specifiche, ma ci aiuta anche a comprendere la loro durata e variazioni temporali. Gli spettrogrammi sono uno dei modi più utili per rappresentare il suono e vengono frequentemente utilizzati nelle applicazioni di apprendimento automatico del segnale audio (ad esempio, alimentando lo spettrogramma di un’onda sonora in una rete neurale convoluzionale profonda per fare previsioni).
Prima di procedere ai diversi metodi di estrazione delle caratteristiche nel dominio delle frequenze, chiariremo alcune notazioni matematiche. Utilizzeremo le seguenti notazioni per le sezioni successive:
mₖ(i): l’ampiezza dell’i-esima frequenza del k-esimo frame.
K: Dimensione del frame
H: Lunghezza del salto
Φ: Il numero di bin di frequenza (= K/2 + 1)
Caratteristica 5: Rapporto di Energia delle Bande
Prima di tutto, parliamo del rapporto di energia delle bande. Il rapporto di energia delle bande è una metrica utilizzata per quantificare il rapporto tra le energie delle frequenze basse e quelle delle frequenze alte in un determinato frame temporale. Matematicamente, per qualsiasi frame k, il rapporto di energia delle bande è:
dove σբ indica il bin di frequenza di separazione: un parametro per distinguere le frequenze basse dalle frequenze alte. Durante il calcolo del rapporto di energia delle bande, tutte le frequenze che hanno un valore inferiore alla frequenza corrispondente a σբ (chiamata frequenza di separazione) vengono trattate come frequenze basse. La somma delle energie al quadrato di queste frequenze determina il numeratore. Allo stesso modo, tutte le frequenze che hanno un valore superiore alla frequenza di separazione vengono trattate come frequenze alte e la somma delle energie al quadrato di queste frequenze determina il denominatore. Di seguito è riportato il codice Python per il calcolo del rapporto di energia delle bande di un segnale:
def find_split_freq_bin(spec, split_freq, sample_rate, frame_size=1024, hop_length=512): """ Calcola l'indice del bin corrispondente a una data frequenza di separazione. Argomenti: spec (array): Lo spettrogramma. split_freq (float): La frequenza di separazione in Hz. sample_rate (int): Il tasso di campionamento dell'audio. frame_size (int, opzionale): La dimensione di ogni frame in campioni. Il valore predefinito è 1024. hop_length (int, opzionale): Il numero di campioni tra frame consecutivi. Il valore predefinito è 512. Restituisce: int: L'indice del bin corrispondente alla frequenza di separazione. """ # Calcola l'intervallo delle frequenze range_of_freq = sample_rate / 2 # Calcola la variazione di frequenza per ogni bin change_per_bin = range_of_freq / spec.shape[0] # Calcola il bin corrispondente alla frequenza di separazione split_freq_bin = split_freq / change_per_bin return int(np.floor(split_freq_bin))def band_energy_ratio(signal, split_freq, sample_rate, frame_size=1024, hop_length=512): """ Calcola il rapporto di energia delle bande (BER) di un segnale. Argomenti: signal (array): Il segnale in ingresso. split_freq (float): La frequenza di separazione in Hz. sample_rate (int): Il tasso di campionamento dell'audio. frame_size (int, opzionale): La dimensione di ogni frame in campioni. Il valore predefinito è 1024. hop_length (int, opzionale): Il numero di campioni tra frame consecutivi. Il valore predefinito è 512. Restituisce: ndarray: I rapporti di energia delle bande per ogni frame del segnale. """ # Calcola lo spettrogramma del segnale spec = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # Trova il bin corrispondente alla frequenza di separazione split_freq_bin = find_split_freq_bin(spec, split_freq, sample_rate, frame_size, hop_length) # Estrai la magnitudine e trasponila modified_spec = np.abs(spec).T res = [] for sub_arr in modified_spec: # Calcola l'energia nell'intervallo delle frequenze basse low_freq_density = sum(i ** 2 for i in sub_arr[:split_freq_bin]) # Calcola l'energia nell'intervallo delle frequenze alte high_freq_density = sum(i ** 2 for i in sub_arr[split_freq_bin:]) # Calcola il rapporto di energia delle bande ber_val = low_freq_density / high_freq_density res.append(ber_val) return np.array(res)def plot_band_energy_ratio(signal, split_freq, sample_rate, name, frame_size=1024, hop_length=512): """ Traccia il rapporto di energia delle bande (BER) di un segnale nel tempo. Argomenti: signal (ndarray): Il segnale in ingresso. split_freq (float): La frequenza di separazione in Hz. sample_rate (int): Il tasso di campionamento dell'audio. name (str): Il nome del segnale per il titolo del grafico. frame_size (int, opzionale): La dimensione di ogni frame in campioni. Il valore predefinito è 1024. hop_length (int, opzionale): Il numero di campioni tra frame consecutivi. Il valore predefinito è 512. """ # Calcola il rapporto di energia delle bande (BER) ber = band_energy_ratio(signal, split_freq, sample_rate, frame_size, hop_length) # Genera gli indici dei frame frames = range(0, len(ber)) # Converti i frame in tempo time = librosa.frames_to_time(frames, hop_length=hop_length) # Crea un nuovo grafico con una dimensione specifica plt.figure(figsize=(15, 7)) # Traccia il BER nel tempo plt.plot(time, ber) # Imposta il titolo del grafico plt.title(name + " (Rapporto di Energia delle Bande)") # Mostra il grafico plt.show() plot_band_energy_ratio(acoustic_guitar, 2048, sr, "Chitarra Acustica")plot_band_energy_ratio(brass, 2048, sr, "Strumenti a Fiato")plot_band_energy_ratio(drum_set, 2048, sr, "Batteria")
La struttura del codice sopra è abbastanza simile a quella dell’estrazione nel dominio del tempo. Il primo passo è definire una funzione chiamata find split_freq_bin() che prende in input lo spettrogramma, il valore della frequenza di divisione e il tasso di campionamento per determinare il bin della frequenza di divisione (σբ) corrispondente alla frequenza di divisione. Il processo è piuttosto semplice. Comprende la ricerca dell’intervallo delle frequenze (che, come spiegato in precedenza, è la frequenza di Nyquist, Sᵣ/2). Il numero di bin di frequenza è dato dal numero di righe degli spettrogrammi, che viene estratto come spec.shape[0]. Dividendo l’intervallo totale delle frequenze per il numero di bin di frequenza, possiamo calcolare la variazione della frequenza per bin, che può essere divisa per la frequenza di divisione data per determinare il bin della frequenza di divisione.
Successivamente, utilizziamo questa funzione per calcolare il vettore del rapporto di energia di banda. La funzione band_energy_ratio() prende in input il segnale di ingresso, la frequenza di divisione, il tasso di campionamento, la dimensione del frame e la lunghezza del salto. Prima, utilizza librosa.stft() per estrarre lo spettrogramma, seguito dal calcolo del bin della frequenza di divisione. Successivamente, viene calcolata la magnitudine dello spettrogramma utilizzando np.abs(), seguita dalla trasposizione per facilitare l’iterazione su ogni frame. Durante l’iterazione, viene calcolato il rapporto di energia di banda per ogni frame utilizzando la formula definita e il bin della frequenza di divisione trovato. I valori vengono memorizzati in una lista, res, che viene infine restituita come un array NumPy. Infine, i valori vengono rappresentati utilizzando la funzione plot_band_energy_ratio().
Di seguito sono mostrati i grafici del rapporto di energia di banda per i 3 strumenti musicali. Per questi grafici, la frequenza di divisione è stata scelta come 2048 Hz, ovvero le frequenze al di sotto di 2048 Hz sono considerate frequenze a bassa energia e quelle al di sopra sono considerate frequenze ad alta energia.
Rapporto di energia di banda per chitarra acustica [Immagine dell’autore]Rapporto di energia di banda per ottoni [Immagine dell’autore]Rapporto di energia di banda per batteria [Immagine dell’autore]
Un alto rapporto di energia di banda (per ottoni) indica una maggiore presenza di componenti a bassa frequenza rispetto alle componenti ad alta frequenza. Pertanto, osserviamo che gli strumenti a fiato producono una quantità significativa di energia nelle bande a bassa frequenza rispetto alle bande ad alta frequenza. La chitarra acustica ha un BER inferiore rispetto agli strumenti a fiato, indicando un contributo di energia relativamente minore nelle bande a bassa frequenza rispetto alle bande ad alta frequenza. In generale, le chitarre acustiche tendono ad avere una distribuzione dell’energia più bilanciata in tutto lo spettro delle frequenze, con un’attenzione relativamente minore alle basse frequenze rispetto ad altri strumenti. Infine, la batteria ha il BER più basso tra i tre, suggerendo un contributo di energia comparativamente inferiore nelle bande a bassa frequenza rispetto ad altri strumenti.
Feature 6: Centroide spettrale
Successivamente, parleremo del centroide spettrale, una misura che quantifica le informazioni sul centro di massa o sulla frequenza media dello spettro di un segnale in un determinato intervallo di tempo. Matematicamente, per qualsiasi frame k, il centroide spettrale è:
Pensalo come una somma pesata degli indici dei bin di frequenza, dove il peso è determinato dal contributo energetico del bin nel dato intervallo di tempo. La normalizzazione viene anche effettuata dividendo la somma pesata per la somma di tutti i pesi per facilitare il confronto uniforme tra diversi segnali. Il codice Python per calcolare il centroide spettrale di un segnale è mostrato di seguito:
def spectral_centroid(signal, sample_rate, frame_size=1024, hop_length=512): """ Calcola il centroide spettrale di un segnale. Argomenti: signal (array): Il segnale di ingresso. sample_rate (int): Il tasso di campionamento dell'audio. frame_size (int, opzionale): La dimensione di ogni frame in campioni. Il valore predefinito è 1024. hop_length (int, opzionale): Il numero di campioni tra frame consecutivi. Il valore predefinito è 512. Restituisce: ndarray: I centroidi spettrali per ogni frame del segnale. """ # Calcola lo spettrogramma del segnale spec = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # Estrai la magnitudine e trasponila modified_spec = np.abs(spec).T res = [] for sub_arr in modified_spec: # Calcola il centroide spettrale sc_val = sc(sub_arr) # Memorizza il valore del centroide spettrale per il frame corrente res.append(sc_val) return np.array(res)def sc(arr): """ Calcola il centroide spettrale in un segnale. Argomenti: arr (array): Array nel dominio delle frequenze per il frame corrente. Restituisce: float: Il valore del centroide spettrale per il frame corrente. """ res = 0 for i in range(0, len(arr)): # Calcola la somma pesata res += i*arr[i] return res/sum(arr)def bin_to_freq(spec, bin_val, sample_rate, frame_size=1024, hop_length=512): """ Calcola la frequenza corrispondente a un dato valore di bin Argomenti: spec (array): Lo spettrogramma. bin_val (): Il valore del bin. sample_rate (int): Il tasso di campionamento dell'audio. frame_size (int, opzionale): La dimensione di ogni frame in campioni. Il valore predefinito è 1024. hop_length (int, opzionale): Il numero di campioni tra frame consecutivi. Il valore predefinito è 512. Restituisce: int: L'indice del bin corrispondente alla frequenza di divisione. """ # Calcola l'intervallo delle frequenze range_of_freq = sample_rate / 2 # Calcola la variazione di frequenza per bin change_per_bin = range_of_freq / spec.shape[0] # Calcola la frequenza corrispondente al bin split_freq = bin_val*change_per_bin return split_freqdef plot_spectral_centroid(signal, sample_rate, name, frame_size=1024, hop_length=512, col = "black"): """ Disegna il centroide spettrale di un segnale nel tempo. Argomenti: signal (ndarray): Il segnale di ingresso. sample_rate (int): Il tasso di campionamento dell'audio. name (str): Il nome del segnale per il titolo del grafico. frame_size (int, opzionale): La dimensione di ogni frame in campioni. Il valore predef
Nel codice sopra, la funzione del centroide spettrale è definita per produrre l'array dei centroidi spettrali per tutti i frame temporali. Successivamente, la funzione sc() è definita per calcolare il centroide spettrale di un frame attraverso un semplice processo iterativo che moltiplica i valori dell'indice con la magnitudine seguita da una normalizzazione per ottenere il bin di frequenza media. Prima di tracciare i valori del centroide spettrale restituiti da spectral_centroid(), viene definita una funzione aggiuntiva chiamata bin to freq come funzione di supporto per il tracciamento. Questa funzione converte i valori del bin medio nei corrispondenti valori di frequenza che possono essere tracciati sullo spettrogramma originale per avere un'idea coerente sulla variazione del centroide spettrale nel tempo. Di seguito sono mostrati i grafici di output (con sovrapposizione della variazione del centroide sullo spettrogramma originale):
Centroide Spettrale per Chitarra Acustica [Immagine dell'Autore]Centroide Spettrale per Ottoni [Immagine dell'Autore]Centroide Spettrale per Batteria [Immagine dell'Autore]
Il centroide spettrale è abbastanza analogo alla metrica RMSE per l'analisi del dominio temporale ed è comunemente usato come descrizione del timbro e della brillantezza del suono. I suoni con centroidi spettrali più alti tendono ad avere una qualità più brillante o orientata agli alti, mentre valori di centroide più bassi sono associati a un carattere più scuro o orientato ai bassi. Il centroide spettrale è una delle caratteristiche più importanti per l'apprendimento automatico audio, spesso utilizzato in applicazioni che coinvolgono la classificazione di genere audio/musica.
Caratteristica 7: Larghezza Spettrale
Ora parleremo della larghezza/spread spettrale, una misura che quantifica le informazioni sulla distribuzione delle energie tra le frequenze componenti dello spettro di un segnale in un dato frame temporale. Pensalo in questo modo: se il centroide spettrale è il valore medio/mediano, la larghezza spettrale è una misura della sua distribuzione/varianza intorno al centroide. Matematicamente, per qualsiasi frame k, la larghezza spettrale è:
dove SCₖ indica il centroide spettrale del k-esimo frame. Come prima, la normalizzazione viene effettuata dividendo la somma ponderata per la somma di tutti i pesi per facilitare un confronto uniforme tra diversi segnali. Il codice Python per calcolare la larghezza spettrale di un segnale è mostrato di seguito:
def larghezza_spettrale(segnale, frequenza_campionamento, dimensione_frame=1024, passo=512): """ Calcola la Larghezza Spettrale di un segnale. Argomenti: segnale (array): Il segnale in ingresso. frequenza_campionamento (int): La frequenza di campionamento dell'audio. dimensione_frame (int, opzionale): La dimensione di ogni frame in campioni. Il valore predefinito è 1024. passo (int, opzionale): Il numero di campioni tra frame consecutivi. Il valore predefinito è 512. Restituisce: ndarray: Le larghezze spettrali per ogni frame del segnale. """ # Calcola lo spettrogramma del segnale spec = librosa.stft(segnale, n_fft=dimensione_frame, hop_length=passo) # Estrai la magnitudine e trasponi spec_modificato = np.abs(spec).T res = [] for sotto_arr in spec_modificato: # Calcola la larghezza spettrale larghezza_val = sb(sotto_arr) # Memorizza il valore della larghezza spettrale per il frame corrente res.append(larghezza_val) return np.array(res)def sb(arr): """ Calcola la larghezza spettrale in un segnale. Argomenti: arr (array): Array nel dominio delle frequenze per il frame corrente. Restituisce: float: Il valore della larghezza spettrale per il frame corrente. """ res = 0 sc_val = sc(arr) for i in range(0, len(arr)): # Calcola la somma ponderata res += (abs(i - sc_val))*arr[i] return res/sum(arr)def traccia_larghezza_spettrale(segnale, frequenza_campionamento, nome, dimensione_frame=1024, passo=512): """ Traccia la larghezza spettrale di un segnale nel tempo. Argomenti: segnale (ndarray): Il segnale in ingresso. frequenza_campionamento (int): La frequenza di campionamento dell'audio. nome (str): Il nome del segnale per il titolo del grafico. dimensione_frame (int, opzionale): La dimensione di ogni frame in campioni. Il valore predefinito è 1024. passo (int, opzionale): Il numero di campioni tra frame consecutivi. Il valore predefinito è 512. """ # Calcola la larghezza spettrale larghezza_arr = larghezza_spettrale(segnale, frequenza_campionamento, dimensione_frame, passo) # Genera gli indici dei frame frame = range(0, len(larghezza_arr)) # Converti i frame in tempo tempo = librosa.frames_to_time(frame, hop_length=passo) # Crea una nuova figura con una dimensione specifica plt.figure(figsize=(15, 7)) # Traccia la larghezza spettrale nel tempo plt.plot(tempo, larghezza_arr) # Imposta il titolo del grafico plt.title(nome + " (Larghezza Spettrale)") # Mostra il grafico plt.show() traccia_larghezza_spettrale(chitarra_acustica, sr, "Chitarra Acustica")traccia_larghezza_spettrale(ottoni, sr, "Ottoni")traccia_larghezza_spettrale(batteria, sr, "Batteria")
Come prima, nel codice sopra, la funzione di larghezza di banda spettrale è definita per produrre l'array di spread spettrale per tutti i frame temporali utilizzando la funzione di aiuto sb, che calcola in modo iterativo la larghezza di banda di un frame. Infine, la funzione plot spectral bandwidth viene utilizzata per tracciare questi valori di larghezza di banda. I grafici di output sono mostrati di seguito:
Larghezza di banda spettrale per chitarra acustica [Immagine di Autore]Larghezza di banda spettrale per ottone [Immagine di Autore]Larghezza di banda spettrale per batteria [Immagine di Autore]
La larghezza di banda spettrale può essere utilizzata in vari compiti di analisi/classificazione audio grazie alla sua capacità di fornire informazioni sulla diffusione o larghezza delle frequenze presenti in un segnale. Una larghezza di banda spettrale più alta (come si vede per ottone e batterie) indica un'ampia gamma di frequenze, suggerendo un segnale più diversificato o complesso. D'altra parte, una larghezza di banda inferiore suggerisce una gamma più stretta di frequenze, indicando un segnale più focalizzato o tonalmente puro.
Caratteristica 8: Piattezza spettrale
Infine, parleremo di piattezza spettrale (aka entropia di Weiner), una misura che informa sulla piattezza o uniformità dello spettro di potenza di un segnale audio. Ci aiuta a capire quanto il segnale audio si avvicini a un tono puro (rispetto a uno simile al rumore) ed è quindi chiamato anche coefficiente di tonalità. Per ogni frame k, la piattezza spettrale è il rapporto tra la sua media geometrica e la media aritmetica. Matematicamente,
Il codice Python per calcolare la piattezza spettrale di un segnale è mostrato di seguito:
def spectral_flatness(signal, sample_rate, frame_size=1024, hop_length=512): """ Calcola la piattezza spettrale di un segnale. Args: signal (array): Il segnale di input. sample_rate (int): Il tasso di campionamento dell'audio. frame_size (int, opzionale): La dimensione di ogni frame in campioni. Il valore predefinito è 1024. hop_length (int, opzionale): Il numero di campioni tra i frame consecutivi. Il valore predefinito è 512. Returns: ndarray: La piattezza spettrale per ogni frame del segnale. """ # Calcola lo spettrogramma del segnale spec = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # Estrai la magnitudine e trasponila modified_spec = np.abs(spec).T res = [] for sub_arr in modified_spec: # Calcola la media geometrica geom_mean = np.exp(np.log(sub_arr).mean()) # Calcola la media aritmetica ar_mean = np.mean(sub_arr) # Calcola la piattezza spettrale sl_val = geom_mean/ar_mean # Memorizza il valore di piattezza spettrale per il frame corrente res.append(sl_val) return np.array(res)def plot_spectral_flatness(signal, sample_rate, name, frame_size=1024, hop_length=512): """ Traccia la piattezza spettrale di un segnale nel tempo. Args: signal (ndarray): Il segnale di input. sample_rate (int): Il tasso di campionamento dell'audio. name (str): Il nome del segnale per il titolo del grafico. frame_size (int, opzionale): La dimensione di ogni frame in campioni. Il valore predefinito è 1024. hop_length (int, opzionale): Il numero di campioni tra i frame consecutivi. Il valore predefinito è 512. """ # Calcola la larghezza di banda spettrale sl_arr = spectral_flatness(signal, sample_rate, frame_size, hop_length) # Genera gli indici di frame frames = range(0, len(sl_arr)) # Converti i frame in tempo time = librosa.frames_to_time(frames, hop_length=hop_length) # Crea una nuova figura con una dimensione specifica plt.figure(figsize=(15, 7)) # Traccia la piattezza spettrale nel tempo plt.plot(time, sl_arr) # Imposta il titolo del grafico plt.title(name + " (Piattezza Spettrale)") # Mostra il grafico plt.show() plot_spectral_flatness(acoustic_guitar, sr, "Chitarra Acustica")plot_spectral_flatness(brass, sr, "Ottone")plot_spectral_flatness(drum_set, sr, "Batteria")
La struttura del codice precedente è la stessa di quella per altri metodi di estrazione nel dominio delle frequenze. L'unica differenza risiede nella funzione di estrazione delle caratteristiche all'interno del ciclo for, che calcola la media aritmetica e geometrica utilizzando le funzioni di NumPy e ne calcola il rapporto per produrre i valori di planarità spettrale per ogni frame temporale. I grafici di output sono mostrati di seguito:
Pianità spettrale per chitarra acustica [Immagine dell'autore]Pianità spettrale per strumenti a fiato [Immagine dell'autore]Pianità spettrale per batteria [Immagine dell'autore]
Un valore elevato di pianità spettrale (uno che si avvicina a 1) indica una distribuzione più uniforme o bilanciata dell'energia nelle diverse frequenze del segnale. Questo è evidente in modo coerente per la batteria, suggerendo un suono più "simile al rumore" o a banda larga, senza picchi o enfasi su frequenze specifiche (come si era notato in precedenza dalla mancanza di periodicità).
D'altra parte, un valore basso di pianità spettrale (soprattutto per la chitarra acustica e in parte per gli strumenti a fiato) implica uno spettro di potenza più irregolare, con l'energia concentrata attorno a poche frequenze specifiche. Ciò indica la presenza di componenti tonali o armoniche nel suono (come riflessa nella loro struttura periodica nel dominio temporale). In generale, la musica con un'intonazione/frequenze distinte tende ad avere valori più bassi di pianità spettrale, mentre i suoni più rumorosi (e non tonali) presentano valori più alti di pianità spettrale.
Conclusioni
In questo articolo, abbiamo approfondito le diverse strategie e tecniche per l'estrazione delle caratteristiche che costituiscono una parte integrale dell'elaborazione dei segnali audio nell'ingegneria musicale. Abbiamo iniziato con l'apprendimento dei fondamenti della produzione e propagazione del suono, che possono essere efficacemente tradotti in variazioni di pressione nel tempo che danno origine alla sua rappresentazione nel dominio temporale. Abbiamo discusso la rappresentazione digitale del suono e i suoi parametri fondamentali, inclusi il tasso di campionamento, la dimensione del frame e la lunghezza dei passi. Le caratteristiche del dominio temporale come l'involucro di ampiezza, l'energia media quadratica, il fattore di cresta, il rapporto picco-potenza e il tasso di attraversamento dello zero sono state discusse teoricamente e valutate computazionalmente su 3 strumenti musicali: chitarra acustica, strumenti a fiato e batterie. Successivamente, è stata presentata e analizzata la rappresentazione nel dominio delle frequenze del suono, attraverso varie discussioni teoriche sulla trasformata di Fourier e gli spettrogrammi. Ciò ha aperto la strada a una vasta gamma di caratteristiche nel dominio delle frequenze, come il rapporto di energia tra bande, il centroide spettrale, le larghezze di banda e il coefficiente di tonalità, ciascuno dei quali può essere utilizzato in modo efficiente per valutare una particolare caratteristica dell'audio in ingresso. Ci sono molte altre applicazioni nell'elaborazione dei segnali, tra cui mel-spettrogrammi, coefficienti cepstrali, controllo del rumore, sintesi audio, ecc. Spero che questa spiegazione possa servire come base per ulteriori esplorazioni di concetti avanzati nel campo.
Spero che tu abbia apprezzato la lettura di questo articolo! In caso di dubbi o suggerimenti, rispondi nella sezione dei commenti.
Non esitare a contattarmi via email.
Se ti è piaciuto il mio articolo e vuoi leggerne altri, seguimi.
Nota: Tutte le immagini (tranne quella di copertina) sono state realizzate dall'autore.
Riferimenti
Crest factor. (2023). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Crest_factor&oldid=1158501578
librosa — Librosa 0.10.1dev documentation. (n.d.). Retrieved June 5, 2023, from https://librosa.org/doc/main/index.html
Spectral flatness. (2022). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Spectral_flatness&oldid=1073105086
The Sound of AI. (2020, August 1). Valerio Velardo. https://valeriovelardo.com/the-sound-of-ai/

![Fondamenti della propagazione del suono [Immagine di Author]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*73LlzPPzLmX6DsLrFVheeA.jpeg)

![Waveform per Chitarra Acustica [Immagine dell'Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Kf0MmP8_mqIZUyBRxgjHAA.png)
![Waveform per Ottone [Immagine dell'Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*AY_urpb3jkZyrs7DwIEwRg.png)
![Waveform per Set di Batteria [Immagine dell'Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*1VDVlwQ_W_FKFgr1HPMoCA.png)
![Dimensione del frame e lunghezza del passo [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*6jeBOA2R3sXcNADsXfEjuQ.png)

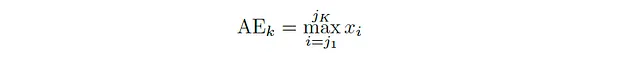
![Involucro dell'ampiezza per chitarra acustica [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*-ruXOgSVNITu35WV0yuAtw.png)
![Involucro dell'ampiezza per strumenti a fiato [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*NhwUexulu7bWENkWEbr5XQ.png)
![Involucro dell'ampiezza per set di batteria [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*yi2fVD67-CZ_b2kL6VfLmg.png)
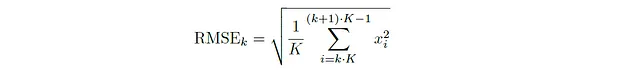

![RMSE per Chitarra Acustica [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*mKwBIq_5NMQ-QW-xd6T72Q.png)
![RMSE per Brass [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*eZWBylUC8FxqTS3jQnI9tw.png)
![RMSE per Batteria [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*WRDjgDkjMjTGC9ha87fWZw.png)


![Fattore di cresta per chitarra acustica [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*OXJqmGmFU2pq1yaYrG3mHQ.png)
![Fattore di cresta per ottoni [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*ic8zGIUhRa-nz3pOssyUFA.png)
![Fattore di cresta per ottoni insieme [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*uo2ACou50jdvkmETLVS7Iw.png)



![Attraversamento dello zero per chitarra acustica [Immagine di Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*jIW9ZcSzwnANrDp9tWL7bw.png)
![Attraversamento dello zero per ottoni [Immagine di Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*8rUxSjDDA95_GSZ_oQRL9Q.png)




![Spectrogram per Chitarra Acustica [Immagine di Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*cs5iAD0d6SIAjt4TxYrTfA.png)
![Spectrogram per Strumenti a Fiato [Immagine di Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*GUnA6RZXx8RA1T2dlnKhVw.png)
![Spectrogram per Batteria [Immagine di Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*JjFO1kDacts055p-u241GQ.png)
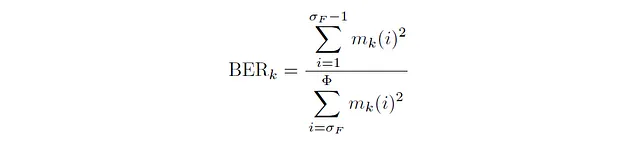
![Rapporto di energia di banda per chitarra acustica [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Fk1Y0M9l7nYkX3wzHEbluA.png)
![Rapporto di energia di banda per ottoni [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*dgHIkYXnmbp9fs02Kwr8JQ.png)
![Rapporto di energia di banda per batteria [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*IHpTCLmDdEPOKXlmpJ6GOw.png)

![Centroide Spettrale per Chitarra Acustica [Immagine dell'Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*CpQGq2geei3hJdl4sQvrKg.png)
![Centroide Spettrale per Ottoni [Immagine dell'Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*NOkciC8-vrK58ZY1W5-SsQ.png)
![Centroide Spettrale per Batteria [Immagine dell'Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*q4RWqeUuo9hPhNRpHiyZOA.png)

![Larghezza di banda spettrale per chitarra acustica [Immagine di Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Td--j-QnYI7aBd3jWwXf6g.png)
![Larghezza di banda spettrale per ottone [Immagine di Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*nl_g33qWsFmwxErGksZB1g.png)
![Larghezza di banda spettrale per batteria [Immagine di Autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*LWAAj53HTRpmBC-wOqfDDQ.png)

![Pianità spettrale per chitarra acustica [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*6LvWubMfSszLjZBSairoAg.png)
![Pianità spettrale per strumenti a fiato [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*OzhJvcyF8ZZ7tmovy1bxIA.png)
![Pianità spettrale per batteria [Immagine dell'autore]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*gnekroUcZKW_QFQuyEg3PQ.png)





