Trasformare i pixel in etichette descrittive Padronanza della classificazione multiclasse delle immagini con TensorFlow
Transforming pixels into descriptive labels Mastering multiclass image classification with TensorFlow
Costruzione di Sistemi Intelligenti che Vedono e Comprendono il Mondo Visivo

Nel paesaggio digitale di oggi, guidato dalle immagini, la capacità di classificare le immagini in modo accurato è più importante che mai. Che tu sia nel settore sanitario, nell’e-commerce, nei veicoli autonomi o in qualsiasi altro campo che si occupa di dati visivi, capire il linguaggio dei pixel è cruciale e padroneggiare l’arte della classificazione delle immagini può darti un vantaggio competitivo.
Quindi sei pronto per intraprendere un’avventura in cui i pixel prendono vita e le immagini rivelano i loro segreti? Non cercare oltre! In questo post del blog, sveleremo le complessità della classificazione multiclasse delle immagini e ti permetteremo di creare sistemi intelligenti che percepiranno il mondo che li circonda, coprendo i concetti fondamentali della preparazione dei dati, della creazione del modello e della valutazione. Alla fine, avrai una solida comprensione di come costruire un solido modello di classificazione delle immagini utilizzando TensorFlow.
La formazione di un modello di classificazione delle immagini personalizzato comporta diversi passaggi. Strutturerò il concetto nelle seguenti sezioni.
Comprensione della Classificazione Multiclasse delle ImmaginiPreparazione dei DatiCostruzione di un Modello di Rete Neurale Convoluzionale (CNN)Effettuare Predizioni con il Tuo Modello di Classificazione delle Immagini
Quindi, mettiamoci all’opera e immergiamoci in questa affascinante avventura.
- Il decoratore Python che potenzia l’esperienza dello sviluppatore 🚀
- Questa ricerca sull’IA presenta un modello di deep learning che può rubare dati ascoltando le pressioni dei tasti registrate da un telefono vicino con un’accuratezza del 95%.
- Phil the Gaps Svelare i fili nascosti della rete commerciale delle Filippine del 2022
Sezione 1: Che cos’è la Classificazione delle Immagini?
La classificazione delle immagini è un compito fondamentale nella computer vision che ci dice quale è il contenuto di un’immagine, categorizzando le immagini in classi o etichette predefinite.
Un modello di machine learning per la classificazione delle immagini imita le capacità cognitive del cervello umano.
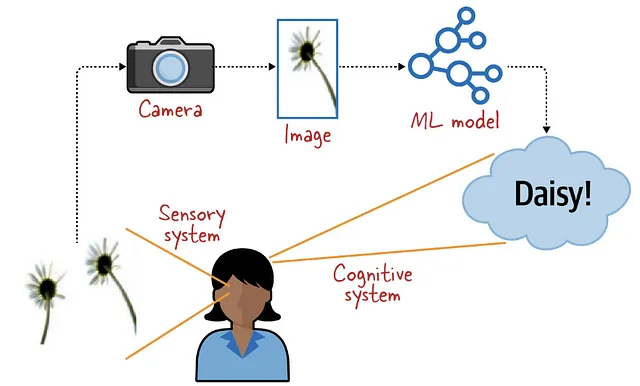
Per quanto riguarda la classificazione delle immagini, la procedura solita prevede l’insegnamento di un modello di machine learning utilizzando un dataset etichettato con classi o etichette distinte (pensa ai famosi gatti e cani). Il modello acquisisce la capacità di estrarre caratteristiche significative dalle immagini e di collegarle alle rispettive etichette attraverso una sequenza di calcoli matematici. L’obiettivo finale è utilizzare questi modelli addestrati per riconoscere ed assegnare etichette accurate a immagini non viste in base alle loro caratteristiche visive.
& Che cos’è la Classificazione Multiclasse delle Immagini?
Quindi, a differenza della classificazione binaria, che consiste nel distinguere solo due categorie (0 o 1), la classificazione multiclasse si occupa dell’identificazione simultanea di più classi. Ad esempio, in un compito di classificazione multiclasse per la classificazione degli animali, potremmo avere classi come “cane”, “gatto”, “uccello” e “cavallo”.

Lo screenshot fornito mostra il dataset CIFAR-10, che consiste in 101 categorie di cibo, ognuna delle quali contiene 1000 immagini, per un totale di 101.000 immagini. Il dataset copre una vasta gamma di alimenti di diverse cucine, tra cui frutta, verdura, dolci e piatti. Questo dataset rappresenta un punto di riferimento ampiamente riconosciuto per valutare l’efficacia dei modelli di classificazione multiclasse delle immagini. Ora che abbiamo esplorato il dataset, passiamo alla prossima sezione del nostro percorso: la preparazione dei dati.
Sezione 2: Familiarizzarsi con i Dati
In questa sezione, ci concentreremo sulla preparazione dei dati utilizzando il dataset Food-101, una collezione completa di immagini di cibo. Mentre il dataset Food-101 consiste in 101 categorie di cibo con 101.000 immagini, semplificheremo il nostro approccio selezionando cinque categorie di cibo per creare un modello più gestibile e risparmiare tempo di calcolo.
Prima di tutto, scaricheremo il dataset Food-101 e lo organizzeremo in una gerarchia di cartelle strutturata. Crea una directory chiamata “data” all’interno della cartella principale e inserisci le cartelle delle immagini all’interno come mostrato qui 👇
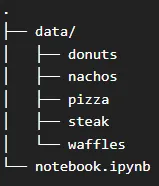
Questa organizzazione faciliterà la gestione efficiente dei dati e l’accesso semplice durante le fasi di addestramento e valutazione.
Successivamente, sfruttando il modulo tf.data di TensorFlow, costruiremo un flusso di dati che trasmette senza soluzione di continuità le immagini di cibo dal dataset. Utilizzeremo l’API image_dataset_from_directory di Keras che ti consente di creare un oggetto TensorFlow tf.data.Dataset da una struttura di directory contenente file di immagini. Genera automaticamente un dataset con etichette basate sui nomi delle sotto-directory, eliminando così la necessità di assegnare esplicitamente le etichette. Ogni file di immagine all’interno delle sotto-directory è associato alla sua etichetta corrispondente. Fornisce anche opzioni per configurare parametri come la dimensione del batch, la dimensione dell’immagine, la mescolatura e l’aumento. Codifichiamolo.
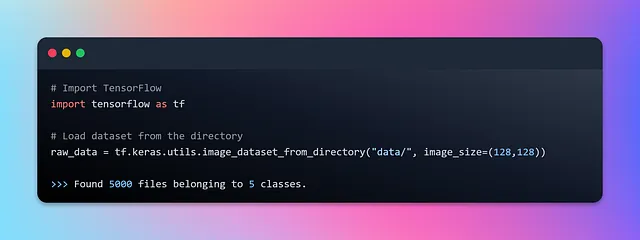
Ora è il momento di esaminare il dataset grezzo e acquisire una comprensione più approfondita di come questa API converta immagini ed etichette, nonché di come costruisca i batch. Per impostazione predefinita, l’API elabora le immagini in batch di 32 set alla volta. Inoltre, le immagini vengono ridimensionate a una dimensione di (256, 256). Tuttavia, è consigliabile considerare una dimensione sicura come dimensione minima, garantendo che tutte le immagini soddisfino o superino tale dimensione.
Diamo un’occhiata al dataset grezzo.

Qui raw_data è un dataset di batch che contiene elementi che sono tuple contenenti due componenti. Il primo componente di ogni elemento nel dataset di batch è un tensore con una dimensione di batch variabile (indicata da None), un’altezza e una larghezza di 128 pixel e 3 canali colore (RGB). Il secondo componente di ogni elemento nel dataset di batch è un tensore con una dimensione di batch variabile (indicata da None) che rappresenta le etichette. Le etichette sono ordinate in base all’ordine alfanumerico dei percorsi dei file di immagine. Diamo un’occhiata a un batch e al suo primo elemento per una comprensione più approfondita.
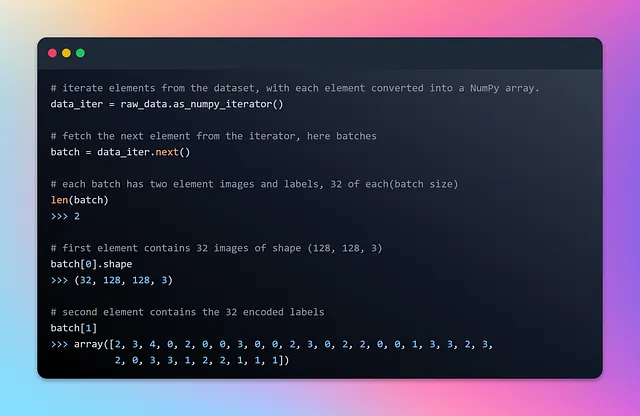
Ora che abbiamo acquisito una certa comprensione di come il dataset di batch venga trasmesso durante l’iterazione, è il momento di eseguire la normalizzazione dei dati e dividere il dataset in set di addestramento e di test. Questa divisione garantisce che il modello apprenda da una porzione dei dati mentre viene testato su immagini di cibo non viste in precedenza. Questo processo di valutazione ci consente di valutare la capacità del modello di generalizzare a nuovi alimenti e di valutarne accuratamente le prestazioni.
Questo passaggio di preprocessing garantirà che i dati siano in un formato adatto per l’alimentazione nella rete neurale.
Dividendo ciascun array di immagini per 255, i valori dei pixel vengono normalizzati nell’intervallo da 0 a 1. Questa normalizzazione viene comunemente eseguita per garantire che i valori dei pixel siano su una scala simile, facilitando così la capacità della rete neurale di apprendere dai dati.
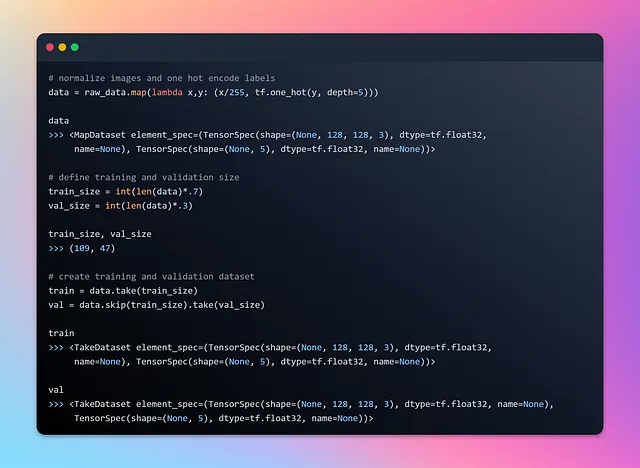
La funzione tf.one_hot() viene utilizzata per creare una codifica “one-hot”, in cui ogni etichetta è rappresentata da un vettore binario di lunghezza pari al parametro depth (in questo caso, 5). La codifica “one-hot” viene spesso utilizzata in problemi di classificazione multiclasse per rappresentare le etichette categoriche in un formato adatto per la rete neurale.
Con il processo di creazione dei dati completato, ora abbiamo i nostri set di addestramento e di convalida pronti per essere inseriti nella rete neurale. Quindi, senza perdere ulteriore tempo, immergiamoci subito nella prossima sezione in cui costruiremo la nostra rete da zero.
Sezione 3: Creazione di un’architettura CNN efficace per la classificazione delle immagini
Preparati per un’avventura entusiasmante mentre ci addentriamo nel mondo della costruzione di una rete di classificazione utilizzando le reti neurali convoluzionali (CNN). Che tu sia un esperto navigato o qualcuno che cerca di rinfrescare la memoria sulle CNN, non temere! Ho tutto sotto controllo. Prima di immergersi in questa sezione, consiglio vivamente di dare un’occhiata al mio primo blog sulle CNN per rinfrescare le basi e familiarizzare con il potere delle CNN.
Comprensione delle reti neurali convoluzionali 🧠: Un viaggio per principianti nell’architettura 🚀
Cos’è una rete neurale convoluzionale (CNN)?
VoAGI.com
Quindi, intraprendiamo questo emozionante viaggio, armati della conoscenza e della fiducia necessarie per creare una rete di classificazione incredibile utilizzando le CNN!
Eccoci qua ⚡
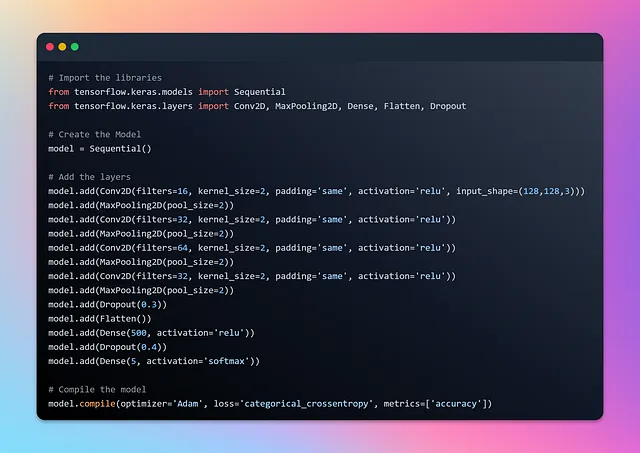
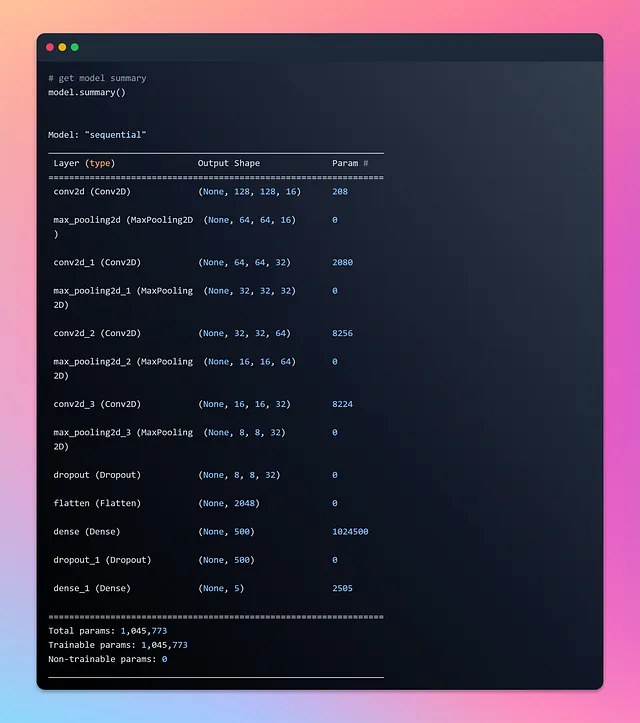
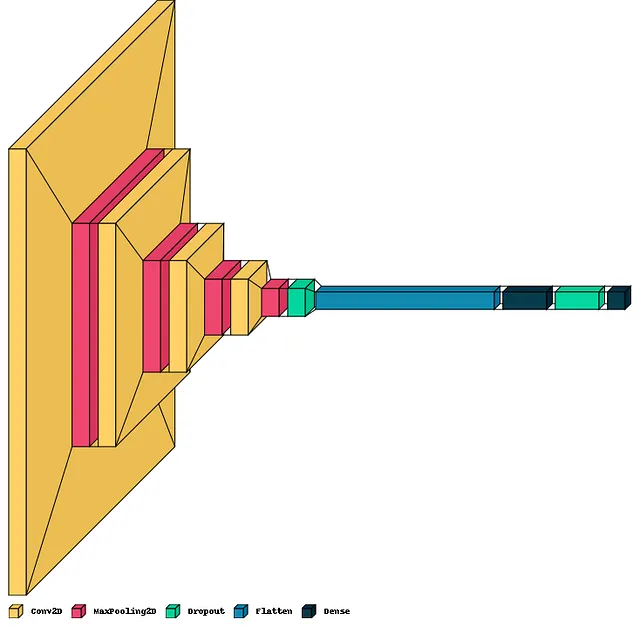
Diamo un’occhiata al riepilogo del modello e visualizziamolo utilizzando visualkeras.
Con il nostro modello creato con successo, è ora di alimentare i dati meticolosamente preparati dalla sezione precedente nel modello e iniziare l’addestramento. Per tenere traccia del progresso dell’addestramento, salveremo la cronologia dell’addestramento in una variabile chiamata “history”. La bellezza dell’utilizzo del dataset TensorFlow è che non è necessario definire esplicitamente la dimensione del batch durante l’addestramento. Il dataset si occupa di generare automaticamente i batch mentre alimentiamo i dati nel modello per l’addestramento.
Allacciate le cinture mentre ci addentriamo nel viaggio dell’addestramento, puntando a 100 epoche di eccellenza nell’addestramento. Abbracciamo la comodità e l’efficienza della generazione automatica dei batch mentre avanziamo nel nostro addestramento del modello. Che l’addestramento abbia inizio 🚀
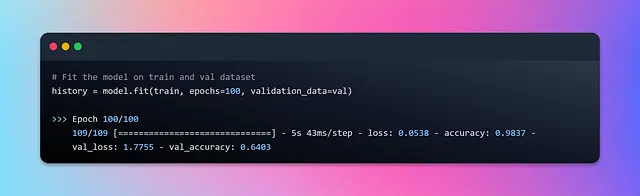
E con questo, il nostro processo di addestramento del modello giunge al termine. Ora visualizziamo il progresso dell’addestramento tracciando i grafici di accuratezza e perdita utilizzando la cronologia dell’addestramento.
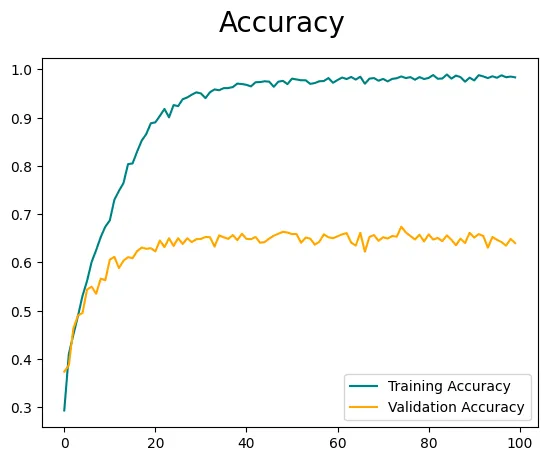
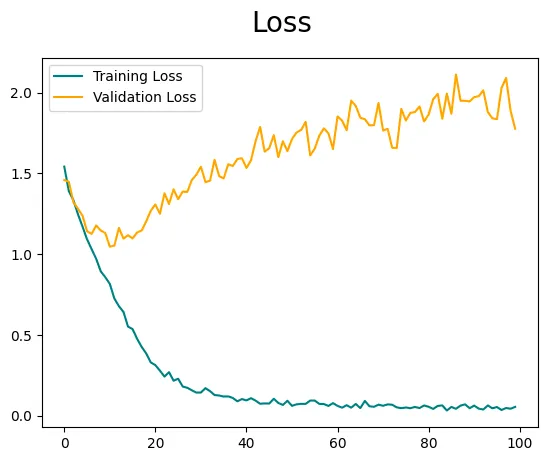
È importante notare che l’accuratezza e le perdite potrebbero non essere ottimali, poiché abbiamo alimentato direttamente le immagini nel modello senza incorporare tecniche di ingegneria delle caratteristiche o di aumento delle immagini. Per migliorare ulteriormente le prestazioni del modello, è consigliato il sintonizzamento degli iperparametri, ma questo è argomento per un altro blog. Tuttavia, se sei interessato a esplorare e capire l’aumento delle immagini, l’ho già trattato nel mio blog precedente qui 👇
Migliora il tuo gioco di Visione Artificiale: Sfruttando il potenziale dell’aumento delle immagini
Migliorare le prestazioni e la robustezza tramite le trasformazioni
ai.plainenglish.io
Implementando queste tecniche, senza dubbio eleverai le prestazioni dei tuoi modelli di visione.
Ora è il momento di passare alla nostra sezione finale, dove sveleremo il potere del nostro modello addestrato per fare previsioni e scoprire le vere etichette nascoste all’interno dei pixel.
Sezione 4: Fare previsioni con il modello
Prima di intraprendere il viaggio delle previsioni, è fondamentale ricordare che le immagini che alimentiamo nel modello devono avere le stesse dimensioni dello strato di input della rete neurale. Per garantire la compatibilità, ridimensioneremo le immagini di conseguenza prima di passarle alle previsioni. Il modello genererà un array di probabilità, con ogni elemento che rappresenta la probabilità dell’etichetta codificata one-hot corrispondente. Utilizzando la potenza della funzione argmax di NumPy, possiamo estrarre l’indice corrispondente all’etichetta prevista. Caricherò un’immagine casualmente selezionata di una pizza succulenta e metterò alla prova il nostro modello addestrato.

Preparati per assistere al processo affascinante di ridimensionamento, previsione e svelamento delle etichette nascoste all’interno dei pixel!
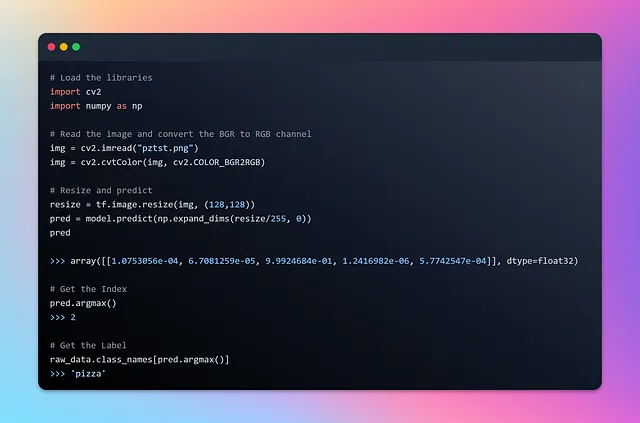
Voilà! Il nostro modello ha sventolato la sua bacchetta e ha rivelato la vera identità dell’immagine con una precisione impeccabile 💯
Ci siamo riusciti! Abbiamo compiuto l’incredibile impresa di creare un modello personalizzato da zero per la classificazione multiclasse delle immagini 🎉
Ecco il link per il codice completo 📜
Il nostro viaggio insieme in questo blog giunge ora a una deliziosa conclusione, ma non temere, perché ci riuniremo nella nostra prossima avventura, dove sveleremo i misteri di altri affascinanti problemi di visione artificiale. Fino ad allora, continua ad esplorare e ad addestrare i tuoi modelli di classificazione delle immagini. Addio 👋 fino al prossimo incontro!
Spero che tu abbia apprezzato questo articolo! Puoi seguirmi Afaque Umer per altri articoli simili.
Cercherò di presentare ulteriori concetti di Machine learning/Scienza dei dati e cercherò di semplificare termini e concetti che suonano complessi.





