Incontra Retroformer un elegante framework di intelligenza artificiale per migliorare iterativamente grandi agenti linguistici imparando un modello retrospettivo plug-in.
Incontra Retroformer, un framework di intelligenza artificiale per migliorare agenti linguistici tramite apprendimento retrospettivo.


È emersa una nuova potente tendenza in cui i grandi modelli di linguaggio (LLM) vengono potenziati per diventare agenti di linguaggio autonomi capaci di svolgere attività in modo indipendente, alla fine al servizio di un obiettivo, anziché limitarsi a rispondere alle domande degli utenti. React, Toolformer, HuggingGPT, agenti generativi, WebGPT, AutoGPT, BabyAGI e Langchain sono alcune delle ricerche ben note che hanno dimostrato efficacemente la praticità dello sviluppo di agenti di decisione autonomi utilizzando LLM. Questi metodi utilizzano LLM per produrre output basati su testo e azioni che possono poi essere utilizzati per accedere alle API e svolgere attività in un contesto specifico.
La maggior parte degli agenti di linguaggio attuali, tuttavia, non ha comportamenti ottimizzati o in linea con le funzioni di ricompensa ambientale a causa dell’enorme portata dei LLM con un numero elevato di parametri. Reflexion, un’architettura di agente di linguaggio piuttosto recente, e molti altri lavori simili, tra cui Self-Refine e Generative Agent, sono un’anomalia perché utilizzano un feedback verbale, specificamente l’autoriflessione, per aiutare gli agenti a imparare dai fallimenti passati. Questi agenti riflessivi convertono le ricompense binarie o scalari dell’ambiente in input vocale come riassunto testuale, fornendo ulteriore contesto alla richiesta dell’agente di linguaggio.
Il feedback di autoriflessione funge da segnale semantico per l’agente, fornendogli un’area specifica su cui concentrarsi per migliorare. Ciò consente all’agente di imparare dai fallimenti passati e evitare di ripetere gli stessi errori più volte per poter fare meglio nel prossimo tentativo. Sebbene il perfezionamento iterativo sia reso possibile dall’operazione di autoriflessione, può essere difficile generare un feedback riflessivo utile da un LLM preaddestrato e congelato, come mostrato nella Figura 1. Ciò perché il LLM deve essere in grado di identificare le aree in cui l’agente ha commesso errori in un determinato ambiente, come il problema dell’assegnazione del credito, e produrre un riassunto con suggerimenti su come migliorare.
- Ricercatori di Airbnb sviluppano Chronon un framework per lo sviluppo di funzionalità adatte alla produzione per modelli di apprendimento automatico.
- Transizione di carriera da Ingegnere di Sistema a Analista dei Dati
- Le migliori applicazioni di BERT che dovresti conoscere
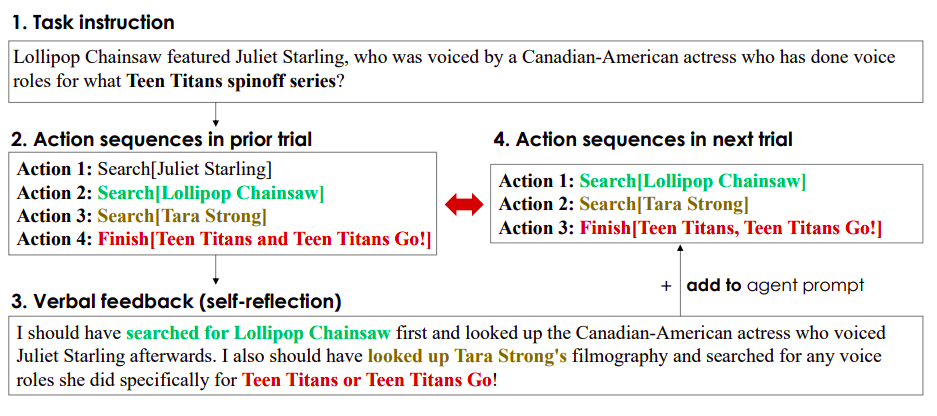
Il modello di linguaggio congelato deve essere adeguatamente modificato per specializzarsi nei problemi di assegnazione del credito per compiti in circostanze particolari al fine di ottimizzare il rinforzo verbale. Inoltre, gli agenti di linguaggio attuali non ragionano o pianificano in modo coerente con l’apprendimento differenziabile basato sul gradiente utilizzando le numerose approcci di apprendimento per rinforzo attualmente in uso. I ricercatori di Salesforce Research introducono Retroformer, un quadro morale per rinforzare gli agenti di linguaggio apprendendo un modello retrospettivo plug-in per risolvere i vincoli. Retroformer migliora automaticamente le richieste dell’agente di linguaggio in base all’input dell’ambiente attraverso l’ottimizzazione delle politiche.
In particolare, l’architettura dell’agente proposto può perfezionare in modo iterativo un modello di linguaggio preaddestrato riflettendo su tentativi falliti e assegnando crediti per le azioni intraprese dall’agente sulle ricompense future. Ciò viene fatto imparando dalle informazioni di ricompensa arbitrarie in diversi ambienti e compiti. Effettuano esperimenti su simulazioni open-source e contesti del mondo reale, come HotPotQA, per valutare le competenze nell’uso degli strumenti di un agente web che deve contattare ripetutamente le API di Wikipedia per rispondere alle domande. HotPotQA comprende compiti di risposta alle domande basate sulla ricerca. Gli agenti Retroformer, a differenza della riflessione, che non utilizza il gradiente per pensare e pianificare, sono apprendisti più rapidi e decision-maker migliori. Più specificamente, gli agenti Retroformer aumentano il tasso di successo di HotPotQA dei compiti di risposta alle domande basate sulla ricerca del 18% in soli quattro tentativi, dimostrando il valore della pianificazione e del ragionamento basati sul gradiente per l’uso degli strumenti in ambienti con uno spazio di stato-azione molto ampio.
In conclusione, quanto segue è ciò che hanno contribuito:
• La ricerca sviluppa Retroformer, che migliora la velocità di apprendimento e il completamento delle attività mediante il continuo perfezionamento delle indicazioni fornite agli agenti linguistici di grandi dimensioni basandosi su input contestuali. Il metodo proposto si concentra sul miglioramento del modello retrospettivo nell’architettura dell’agente linguistico senza accedere ai parametri di Actor LLM o senza la necessità di propagare i gradienti.
• Il metodo proposto consente di apprendere da segnali di ricompensa diversi per compiti ed ambienti vari. Retroformer è un modulo plug-in adattabile per molti tipi di LLM (Large Language Models) basati su cloud, come GPT o Bard, grazie alla sua natura agnostica.






