Tre sfide nel deployare modelli generativi in produzione
Sfide nel deployare modelli generativi
Come deployare modelli di lingua e diffusione grandi per il tuo prodotto senza spaventare gli utenti.

OpenAI, Google, Microsoft, Midjourney, StabilityAI, CharacterAI e molti altri: tutti stanno cercando di portare la migliore soluzione per modelli di testo-a-testo, testo-immagine, immagine-immagine e immagine-testo.
La ragione è semplice: il vasto campo di opportunità che lo spazio offre; dopo tutto, non si tratta solo di intrattenimento, ma anche di utilità che era impossibile sbloccare. Dai motori di ricerca migliori a campagne pubblicitarie più impressionanti e personalizzate e a chatbot amichevoli, come MyAI di Snap.
E sebbene lo spazio sia molto fluido, con molte parti in movimento e checkpoint del modello rilasciati ogni pochi giorni, ci sono sfide che ogni azienda che lavora con AI generativa sta cercando di affrontare.
In questo articolo parlerò delle principali sfide e di come affrontarle nel deployare modelli generativi in produzione. Sebbene ci siano molti tipi diversi di modelli generativi, in questo articolo mi concentrerò sugli ultimi sviluppi nei modelli di diffusione e basati su GPT. Tuttavia, molti argomenti discussi qui si applicherebbero anche ad altri modelli.
- Costruire PCA da zero
- Rilevare le frodi nell’e-commerce con tecniche avanzate di Data Science
- Il futuro della programmazione Java 5 tendenze da monitorare nel 2023
Cos’è l’AI generativa?
L’AI generativa descrive in modo generale un insieme di modelli in grado di generare nuovo contenuto. I noti Generative Adversarial Networks lo fanno apprendendo la distribuzione dei dati reali e generando variabilità dal rumore aggiunto.
Il recente boom nell’AI generativa deriva dal fatto che i modelli raggiungono una qualità a livello umano su larga scala. La ragione per lo sblocco di questa trasformazione è semplice: ora abbiamo abbastanza potenza di calcolo (da qui il rialzo del prezzo delle azioni NVIDIA) per addestrare e mantenere modelli con una capacità sufficiente per ottenere risultati di alta qualità. L’avanzamento attuale è alimentato da due architetture di base: i modelli di trasformatori e di diffusione.
Forse la svolta più significativa dell’ultimo anno è stata ChatGPT di OpenAI, un modello generativo basato su testo, con 175 miliardi per una delle ultime versioni di ChatGPT-3.5 che ha una base di conoscenza sufficiente per mantenere conversazioni su vari argomenti. Mentre ChatGPT è un modello a singola modalità, poiché può supportare solo il testo, i modelli multimodali possono prendere in input e restituire diversi tipi di input, ad esempio testo e immagini.
Le architetture multimodali di immagine-testo e testo-immagine operano in uno spazio latente condiviso dai concetti testuali e di immagine. Lo spazio latente viene ottenuto addestrando su un compito che richiede entrambi i concetti (ad esempio, la descrizione delle immagini) penalizzando la distanza nello spazio latente tra lo stesso concetto in due modalità diverse. Una volta ottenuto questo spazio latente, può essere riutilizzato per altri compiti.
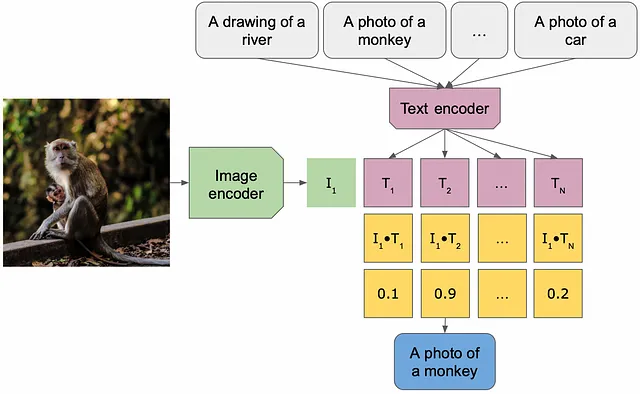
Modelli generativi notevoli rilasciati quest’anno sono DALLE/Stable-Diffusion (testo-immagine/immagine-immagine) e BLIP (implementazione immagine-testo). I modelli DALLE prendono in input un prompt o un’immagine e un prompt genera un’immagine come risposta, mentre i modelli basati su BLIP possono rispondere a domande sui contenuti dell’immagine.
Sfide e Soluzioni
Purtroppo, non esiste un pranzo gratuito quando si tratta di apprendimento automatico e i modelli generativi su larga scala si trovano di fronte a alcune sfide quando si tratta del loro deploy in produzione: dimensione e latenza, bias e equità, e la qualità dei risultati generati.
Dimensione del modello e latenza
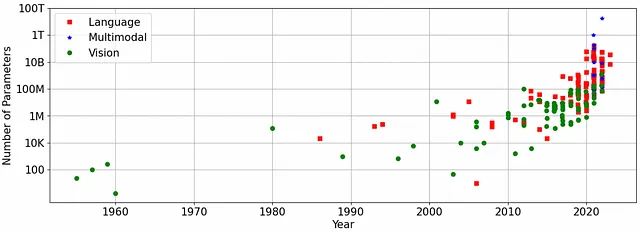
I modelli GenAI all’avanguardia sono enormi. Ad esempio, i modelli LLaMA di Meta per il testo a testo variano tra 7 e 65 miliardi di parametri, mentre ChatGPT-3.5 ha 175 miliardi di parametri. Questi numeri sono giustificati – in un mondo semplificato, la regola generale è che più grande è il modello, più dati vengono utilizzati per l’addestramento e migliore è la qualità.
I modelli testo-immagine, seppur più piccoli, sono comunque significativamente più grandi dei loro predecessori basati su reti generative avversarie – i checkpoint di Stable Diffusion 1.5 hanno meno di 1 miliardo di parametri (occupando oltre tre gigabyte di spazio), e DALLE 2.0 ha 3.5 miliardi di parametri. Pochi GPU avrebbero abbastanza memoria per mantenere questi modelli e di solito sarebbe necessaria una flotta per mantenere un singolo grande modello, il che può diventare molto costoso molto presto, senza nemmeno parlare del deploy di questi modelli su dispositivi mobili.
I modelli generativi impiegano tempo per produrre l’output. Per alcuni, la latenza è dovuta alle loro dimensioni – propagare il segnale attraverso diversi miliardi di parametri anche su una flotta di GPU richiede tempo, mentre per altri è dovuta alla natura iterativa della produzione di risultati di alta qualità. I modelli di diffusione, nella loro configurazione predefinita, impiegano 50 passaggi per generare un’immagine, ridurre il numero di passaggi deteriora la qualità dell’immagine di output.
Soluzioni: Ridurre le dimensioni del modello spesso aiuta a renderlo più veloce – distillare, comprimere e quantizzare il modello ridurrebbe anche la latenza. Qualcomm ha aperto la strada comprimendo il modello di diffusione stabile a sufficienza per poterlo utilizzare su dispositivi mobili. Di recente sono state rilasciate versioni più piccole, distillate e molto più veloci di Stable Diffusion (piccole e mini).
Un’ottimizzazione specifica del modello può anche contribuire ad accelerare l’inferenza – ad esempio, per i modelli di diffusione, potresti generare un output a bassa risoluzione e quindi ingrandirlo o utilizzare un numero inferiore di passaggi e un diverso scheduler, in quanto alcuni funzionano meglio con un numero inferiore di passaggi, mentre altri generano una qualità superiore per un numero maggiore di iterazioni. Ad esempio, Snap ha recentemente dimostrato che otto passaggi sarebbero sufficienti per creare risultati di alta qualità con Stable Diffusion 1.5, utilizzando varie ottimizzazioni durante l’addestramento.
Compilare il modello con, ad esempio, tensorrt di NVIDIA e torch.compile potrebbe ridurre sostanzialmente la latenza con un minimo sforzo di ingegneria.
Sul campo – deploy di applicazioni di deep learning su dispositivi mobili
Tecniche per trovare il giusto compromesso tra efficienza e accuratezza per le reti neurali profonde su dispositivi limitati
towardsdatascience.com
Bias, equità e sicurezza
Hai mai provato a rompere ChatGPT? Molti sono riusciti a scoprire problemi di bias e equità, e OpenAI merita i complimenti per il grande lavoro che sta facendo per affrontare questi problemi. Senza correzioni su larga scala, i chatbot possono creare problemi nel mondo reale propagando idee e comportamenti dannosi e insicuri.
Alcuni esempi in politica, ad esempio, ChatGPT ha rifiutato di creare poesie su Trump ma ne ha creata una su Biden, parità di genere e lavori in particolare – implicando che alcune professioni siano per gli uomini e altre per le donne e per la razza.
Come i modelli testo-testo, anche i modelli testo-immagine e immagine-testo contengono bias e problemi di equità. Il modello Stable Diffusion 2.1, quando viene chiesto di generare immagini di un medico e un’infermiera, produce un uomo bianco per il primo e una donna bianca per la seconda. Curiosamente, il bias dipenderebbe dal paese specificato nell’input – ad esempio, un medico giapponese o un’infermiera brasiliana.


Giocando con il modello di immagine-testo BLIP e fornendo un’immagine di una persona in sovrappeso e medici di sesso maschile e femminile, ho ottenuto descrizioni di immagini giudicanti e di parte – “un uomo grasso”, “un medico maschio”, “una donna con un camice bianco e uno stetoscopio”.


![Immagini generate dall'autore con Stable Diffusion 2.1 e didascalie generate con il modello BLIP da sinistra a destra [1] un uomo grasso che mangia un cono di gelato; [2] un medico uomo in camice bianco e cravatta; [3] una donna in camice da laboratorio bianco con uno stetoscopio al collo. Le immagini sono generate dall'autore con l'interfaccia SD 2.1 e passate attraverso BLIP.](https://miro.medium.com/v2/resize:fit:640/format:webp/1*SU00ELFCZ4fNW8wTbKcDyw.png)
Come testare il problema: È un problema abbastanza difficile da diagnosticare: in molti casi, è necessario sapere cosa cercare. Avere un dataset di benchmark separato con una grande varietà di input, in cui le cose potrebbero andare o non andare storte, con risposte di esempio e segnali di allarme per ogni risposta che rileveremmo, oltre a un dataset di persone provenienti da diverse esperienze e in diverse situazioni che conserva tutte le possibili informazioni sull’immagine della persona, sarebbe utile. Questi dataset devono avere centinaia di migliaia di voci per ottenere statistiche affidabili.
Soluzione: Quasi tutti i problemi di bias, equità e sicurezza derivano dai dati di addestramento. Mi piace l’analogia secondo cui i modelli di intelligenza artificiale sono uno specchio dell’umanità che esacerba tutti i nostri bias. L’addestramento su dati puliti e imparziali migliorerebbe drasticamente i risultati. Tuttavia, anche con questi, i modelli commettono errori.
Un’altra possibile soluzione è la post-elaborazione e il filtraggio dei risultati; ad esempio, Stable Diffusion addestrato su dati che contengono immagini di nudezze ha un rilevatore di contenuti NSFW per individuare eventuali problemi. Filtri simili possono essere applicati all’output dei modelli di testo-a-testo.
Qualità, pertinenza e correttezza dell’output
I modelli generativi possono essere molto creativi nell’interpretare le richieste degli utenti e, sebbene i modelli su larga scala recenti raggiungano una qualità paragonabile a quella umana, per ogni caso d’uso non funzionerebbero immediatamente, richiedendo ulteriori regolazioni e ottimizzazione delle richieste.
Valutare la qualità nei primi modelli limitati di immagini-testo e testo-testo era relativamente semplice: dopo tutto, un miglioramento rispetto al gibberish è evidente. I modelli generativi di alta qualità iniziano a mostrare comportamenti più difficili da rilevare; ad esempio, i modelli di testo-testo possono diventare evasivi, producendo con sicurezza informazioni errate e obsolete.
I modelli di diffusione mostrano imperfezioni di output in altri modi. I problemi tipici attribuiti ai modelli basati sull’immagine sono la geometria errata, l’anatomia mutata, una discrepanza tra l’input e il risultato dell’immagine, il mismatch di colore della pelle e genere nel caso del trasferimento di immagini. La valutazione automatizzata dell’estetica e del realismo è ancora in ritardo, con metriche tipiche, come FID, incapaci di catturare queste variazioni.


![Da sinistra a destra: [1] due persone che si abbracciano; [2] un uomo con il pollice in su; [3] un cane che corre nel parco. Un'immagine da Stable Diffusion 1.5 generata dall'autore](https://miro.medium.com/v2/resize:fit:640/format:webp/1*tyh1KGXnbEMtGszdyE6WKg.png)
Come testare il problema: Testare la qualità dei modelli generativi è sfidante; dopo tutto, non esiste una verità fondamentale per questi modelli, sono fatti per fornire output nuovi. E quindi, finora, nessuna metrica potrebbe catturare in modo affidabile gli aspetti qualitativi. E la metrica più affidabile è l’valutazione umana.
Come nella valutazione di bias e equità, il modo migliore è avere un ampio dataset di prompt e immagini per testare la qualità. Con i modelli di testo-a-testo che diventano sempre più personalizzati e adattati a ciascun utente, oltre alla coerenza dei dialoghi, correttezza e rilevanza, vorremmo anche valutare quanto bene possono ricordare informazioni sulla conversazione.
Soluzione: Molti dei problemi di qualità possono essere attribuiti ai dati di addestramento e alla dimensione dei modelli; potrebbero essere anche solo un po’ troppo piccoli per fare un altro salto di qualità (pensa a GPT-3.5 rispetto a GPT-4) — lo spazio latente attuale è un’astrazione e non è progettato per conservare informazioni precise. Molti problemi possono essere risolti con una migliore ingegnerizzazione dei prompt — sia per i modelli di testo-a-testo che di testo-a-immagine e con prompt negativi per i modelli di testo-a-immagine.
I modelli di testo-a-immagine e immagine-a-immagine possono avere strumenti aggiuntivi che potrebbero aumentare la qualità — miglioramento dell’immagine, tramite metodi di deep learning convenzionali o raffinamenti basati sulla diffusione. Moduli aggiuntivi come ControlNet e ortogonali all’architettura di diffusione possono aiutare a ottenere un controllo aggiuntivo sui risultati generati. Le tecniche Dreambooth per il raffinamento del modello per un’applicazione specifica aiuterebbero anche a ottenere quel vantaggio nei risultati. Giocare con parametri aggiuntivi, come lo scheduler, CFG e il numero di passaggi di diffusione, può influire notevolmente sulla qualità.
Sommario
I modelli generativi hanno aperto un nuovo campo di applicazioni, sia divertenti, come AI Lenses, che commerciali, come motori di ricerca migliori, co-piloti e pubblicità. Allo stesso tempo, la corsa per lanciare il prodotto da parte delle aziende e l’entusiasmo dei consumatori per le nuove funzionalità a volte fanno passare inosservati i difetti apparenti nella tecnologia.
E sebbene ci sia un’impostazione generale per rendere il benchmark dei modelli più trasparente pubblicando dataset open-source su larga scala, codice di addestramento e risultati di valutazione, c’è anche una spinta per una regolamentazione più rigorosa dei modelli AI su larga scala. In un mondo ideale, entrambe le cose non dovrebbero andare agli estremi e si dovrebbero aiutare reciprocamente per rendere l’AI più sicura e divertente da usare.
Ti è piaciuto l’autore? Resta in contatto!
Ho dimenticato qualcosa? Non esitare a lasciare una nota, un commento o a mandarmi un messaggio direttamente su LinkedIn o Twitter!
Valutazione della qualità dell’immagine profonda
Approfondimento sulla valutazione della qualità dell’immagine di riferimento completa. Dagli esperimenti di qualità dell’immagine soggettiva all’obiettivo profondo…
towardsdatascience.com
Perdite percettive per il ripristino dell’immagine profonda
Dall’errore quadratico medio ai GAN — cosa rende una buona funzione di perdita percettiva?
towardsdatascience.com





