Come costruire una pipeline di rilevamento automatico completo della deriva dei dati
Come creare una pipeline per il rilevamento automatico della deriva dei dati
Una guida automatizzata per rilevare e gestire la deriva dei dati

Motivazione
La deriva dei dati si verifica quando la distribuzione delle caratteristiche di input nell’ambiente di produzione differisce dai dati di addestramento, portando a potenziali imprecisioni e diminuzione delle prestazioni del modello.
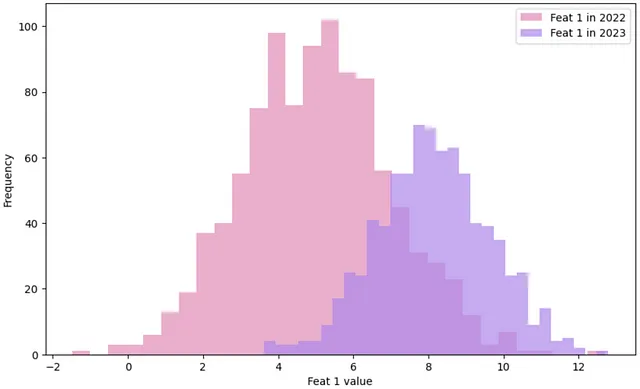
Per mitigare l’impatto della deriva dei dati sulle prestazioni del modello, possiamo progettare un flusso di lavoro che rileva la deriva, avvisa il team dei dati e attiva il ritraining del modello.
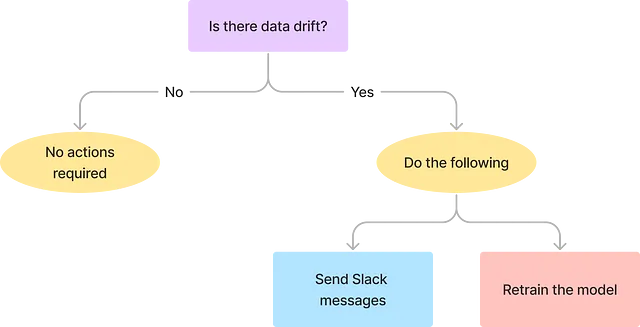
Flussi di lavoro
Il flusso di lavoro comprende i seguenti compiti:
- Recupera i dati di riferimento dal database Postgres.
- Ottieni i dati di produzione correnti dal web.
- Rileva la deriva dei dati confrontando i dati di riferimento e i dati correnti.
- Aggiungi i dati correnti al database Postgres esistente.
- Quando si verifica una deriva dei dati, vengono eseguite le seguenti azioni:
- Invia un messaggio Slack per avvisare il team dei dati.
- Ritraina il modello per aggiornarne le prestazioni.
- Carica il modello aggiornato su S3 per lo storage.
Questo flusso di lavoro è pianificato per essere eseguito in determinati momenti, come ad esempio ogni lunedì alle 11:00.
- Risolvere l’esercizio di Reinforcement Learning sulle piste da corsa con il controllo Monte Carlo fuori politica
- Incontra PEARL – Il nuovo strumento di intelligenza artificiale che può eseguire chiamate di assistenza clienti e vendite
- Tre sfide nel deployare modelli generativi in produzione
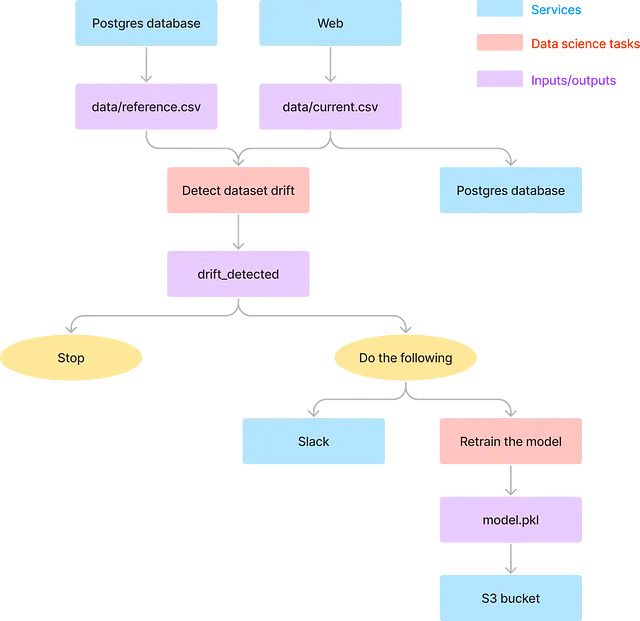
In generale, il flusso di lavoro comprende due tipi di compiti: compiti di data science e compiti di data engineering.
I compiti di data science, rappresentati da riquadri rosa, sono eseguiti dai data scientist e riguardano la deriva dei dati…





