Regolamentare l’IA Generativa
Regolamentare l'IA Generativa
In che misura i LLM rispettano l’EU AI Act?

Poiché l’intelligenza artificiale generativa (AI) rimane al centro dell’attenzione, cresce la richiesta di regolamentare questa tecnologia poiché può avere un impatto negativo su una vasta popolazione in breve tempo. Gli impatti potrebbero assumere la forma di discriminazione, perpetuazione di stereotipi, violazioni della privacy, pregiudizi negativi e minare i valori umani fondamentali.
Nel giugno 2023, il governo degli Stati Uniti ha annunciato un insieme di linee guida volontarie sull’IA a cui hanno aderito diverse aziende di spicco, tra cui Anthropic, Meta (Facebook), Google, Amazon, OpenAI e Microsoft, solo per citarne alcune.[1] Questo è un grande passo avanti per gli Stati Uniti, ma sfortunatamente è sempre stato in ritardo rispetto all’Unione europea nelle regolamentazioni sull’IA. Nel mio precedente articolo Generative AI Ethics: Key Considerations in the Age of Autonomous Content, ho esplorato il quadro etico dell’IA dell’UE e ho fornito una serie di considerazioni per l’implementazione del quadro quando vengono utilizzati grandi modelli di linguaggio (LLM). Questo blog si concentra sul progetto di legge dell’UE sull’IA e su quanto bene i LLM si conformano alla legislazione in bozza.
Legge dell’UE sull’IA
Nel giugno 2023, l’UE ha approvato la prima bozza di regolamentazione sull’IA al mondo. Sulla base del quadro etico sull’IA ratificato nel 2019, la priorità dell’UE è garantire che i sistemi di intelligenza artificiale utilizzati nell’UE siano “sicuri, trasparenti, rintracciabili, non discriminatori e rispettosi dell’ambiente”.[2] Per evitare conseguenze dannose, il quadro dell’UE insiste sul coinvolgimento umano nei sistemi di intelligenza artificiale. In altre parole, le aziende non possono semplicemente lasciare che l’IA e l’automazione si gestiscano da sole.
La legge proposta suddivide l’IA in tre diverse categorie a seconda del rischio che possono rappresentare per le persone: ogni livello di rischio richiede un diverso grado di regolamentazione. Se questo piano viene accettato, sarebbe il primo insieme di regolamentazioni sull’IA al mondo. I tre livelli di rischio identificati dall’UE sono: rischio inaccettabile, rischio elevato e rischio limitato.
- Riallineamento delle conferenze di calcio universitario – node2vec
- Osservabilità dei dati all’avanguardia dati, codice, infrastruttura e intelligenza artificiale
- Implementazione universale degli algoritmi BFS, DFS, Dijkstra e A-Star
- Rischio inaccettabile: sarà vietato l’uso di tecnologie dannose e che rappresentano una minaccia per gli esseri umani. Esempi di ciò potrebbero includere l’influenza cognitiva delle persone o di determinate classi vulnerabili; classificazione delle persone in base al loro status sociale e utilizzo del riconoscimento facciale per la sorveglianza in tempo reale e l’identificazione delle identità a distanza di massa. Ora, tutti sappiamo che le forze armate di tutto il mondo si stanno concentrando sulle armi autonome, ma divago.
- Rischio elevato: i sistemi di intelligenza artificiale che potrebbero avere un effetto negativo sulla sicurezza o sui diritti e le libertà fondamentali vengono classificati in due diverse categorie dall’UE. La prima categoria riguarda l’IA incorporata nei prodotti di vendita al dettaglio che attualmente rientrano nelle normative dell’UE sulla sicurezza dei prodotti. Ciò include giocattoli, aeroplani, automobili, apparecchiature mediche, ascensori e così via. La seconda categoria dovrà essere registrata in un database dell’UE. Ciò include tecnologie come la biometria, le operazioni relative all’infrastruttura critica, la formazione e l’istruzione, le attività legate all’impiego, la polizia, il controllo delle frontiere e l’analisi giuridica della legge.
- Rischio limitato: almeno i sistemi a basso rischio devono rispettare gli standard di trasparenza e apertura che consentirebbero alle persone di prendere decisioni informate. L’UE stabilisce che gli utenti dovrebbero essere informati ogni volta che interagiscono con l’IA. Inoltre, richiedono che i modelli siano creati in modo tale da non creare materiale illecito. Inoltre, richiedono che i creatori dei modelli divulghino quali (se presenti) materiali protetti da copyright sono stati utilizzati nella loro formazione.
Il prossimo passo per l’EU AI Act sarà quello di essere negoziato tra i paesi membri in modo che possano votare sulla forma finale della legge. L’UE sta puntando alla fine dell’anno (2023) per la ratifica.
Ora, passiamo a vedere in che misura i LLM attuali si attengono all’atto in bozza.
Conformità dei LLM con l’atto in bozza dell’UE sull’IA
Ricercatori presso il Center for Research on Foundation Models (CRFM) e l’Institute for Human-Centered Artifical Intelligence (HAI) dell’Università di Stanford hanno recentemente pubblicato un articolo dal titolo I Foundation Models rispettano l’atto in bozza dell’UE sull’IA? Hanno estratto ventidue requisiti dall’atto, li hanno categorizzati e quindi hanno creato una rubrica a 5 punti per dodici dei ventidue requisiti. Tutta la ricerca, inclusi i criteri, le rubriche e i punteggi, sono disponibili su GitHub con licenza MIT.
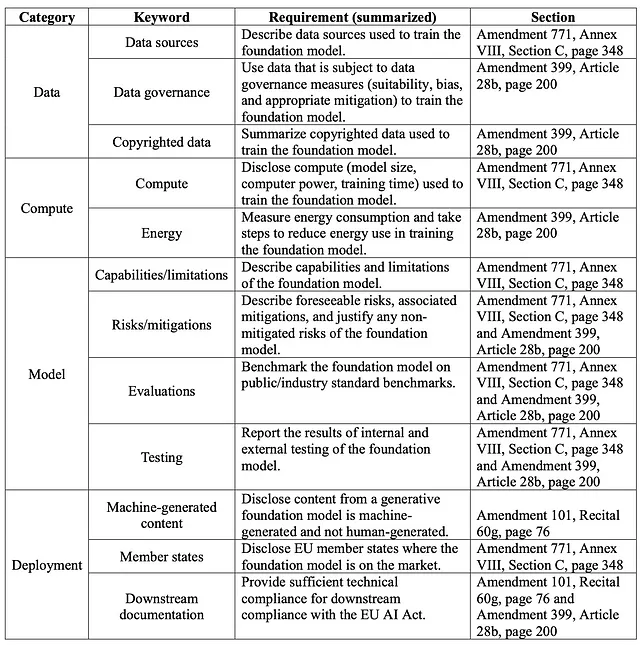
Il team di ricerca ha mappato i requisiti legislativi nelle categorie indicate nella Tabella 1.1. Va notato che il team ha valutato solo dodici dei ventidue requisiti totali identificati. Alla fine, il team ha selezionato i dodici requisiti che erano più facilmente valutabili in base ai dati disponibili pubblicamente e alla documentazione fornita dai produttori di modelli.
Tabella 1.1: Riassunto della tabella di conformità LLM
Per coloro che potrebbero non essere a conoscenza, il team di Stanford ha catalogato meticolosamente oltre cento set di dati, modelli e applicazioni LLM che possono essere trovati nei loro grafici di ecosistema. Per rendere le cose gestibili, i ricercatori hanno analizzato “10 fornitori di modelli di base e i loro modelli di base principali con 12 dei requisiti dell’Atto per i modelli di base in base alle nostre rubriche”.[3]
I ricercatori hanno esaminato modelli di OpenAI, Anthropic, Google, Meta, Stability.ai e altri. Sulla base della loro analisi, la loro ricerca ha prodotto la seguente scheda di valutazione.
Figura 1.2: Valutazione della conformità dei fornitori di modelli di base con la bozza dell’AI Act dell’UE

In generale, i ricercatori hanno osservato che c’era una notevole variabilità nella conformità dei modelli tra i fornitori (e questi erano solo dodici dei ventidue requisiti) con “alcuni fornitori con un punteggio inferiore al 25% (AI21 Labs, Aleph Alpha, Anthropic) e solo un fornitore con un punteggio di almeno il 75% (Hugging Face/BigScience) al momento attuale”.[4]
Ti incoraggio a leggere lo studio completo, ma i ricercatori hanno affermato che c’è ampia margine di miglioramento per tutti i fornitori. Hanno anche identificato diverse “sfide persistenti” chiave che includono:
● Problemi di copyright ambigui: La maggior parte dei modelli di base è stata addestrata su dati provenienti da fonti su Internet, con una parte significativa probabilmente protetta da copyright. Tuttavia, la maggior parte dei fornitori non specifica lo status di copyright dei dati di addestramento. Le implicazioni legali dell’utilizzo e della riproduzione di dati protetti da copyright, in particolare quando si considerano i termini di licenza, non sono ben definite e sono attualmente oggetto di contenzioso attivo negli Stati Uniti (vedi Washington Post – AI ha imparato dal loro lavoro. Ora vogliono compensazione. Reuters – Il giudice statunitense riscontra difetti nella causa degli artisti contro le aziende di intelligenza artificiale). Dovremo vedere come si sviluppa nel tempo.
● Mancanza di divulgazione sulla mitigazione del rischio: Come menzionato nell’introduzione, l’IA ha il potenziale per avere un impatto negativo su molte persone rapidamente, quindi capire i rischi di LLM è fondamentale. Tuttavia, quasi tutti i fornitori di modelli di base ignorano le informazioni sul rischio individuate nella legislazione in bozza. Sebbene molti fornitori elenchino i rischi, pochi dettagliano le misure adottate per mitigare i rischi identificati. Anche se non si tratta di un caso di IA generativa, c’è una recente causa legale contro l’assicuratore sanitario statunitense Cigna Healthcare, che afferma che hanno utilizzato l’IA per negare i pagamenti (Axios – Le cause legali sull’IA si estendono alla sanità). Bill Gates ha scritto un ottimo articolo dal titolo “I rischi dell’IA sono reali ma gestibili”, che ti incoraggio a leggere.
● Deficit di valutazione e audit: C’è una carenza di benchmark coerenti per valutare le prestazioni dei modelli di base, specialmente in aree come l’uso potenziale improprio o la robustezza del modello. L’Atto CHIPS e Science degli Stati Uniti ha presentato un mandato per l’Istituto Nazionale di Standard e Tecnologia (NIST) per creare valutazioni standardizzate per i modelli di intelligenza artificiale. La capacità di valutare e monitorare i modelli è stata il focus del mio framework GenAIOps di cui ho parlato di recente. Alla fine, vedremo GenAIOps, DataOps e DevOps convergere in un framework comune, ma ci vorrà del tempo.
● Rapporti di consumo energetico non coerenti: Penso che molti di noi abbiano sperimentato le recenti ondate di calore in tutto il mondo. Per i LLM, i fornitori di modelli di base sono piuttosto variati quando si tratta di segnalare l’uso dell’energia e le relative emissioni. Infatti, i ricercatori citano altre ricerche che suggeriscono che non sappiamo ancora come misurare e contabilizzare l’uso dell’energia. Nnlabs.org ha riportato quanto segue: “Secondo OpenAI, GPT-2, che ha 1,5 miliardi di parametri, ha richiesto 355 anni di tempo di calcolo su un singolo processore e ha consumato 28.000 kWh di energia per l’addestramento. In confronto, GPT-3, che ha 175 miliardi di parametri, ha richiesto 355 anni di tempo di calcolo su un singolo processore e ha consumato 284.000 kWh di energia per l’addestramento, che è 10 volte più energia rispetto a GPT-2. BERT, che ha 340 milioni di parametri, ha richiesto 4 giorni di addestramento su 64 TPUs e ha consumato 1.536 kWh di energia”.[5]
Oltre a quanto sopra, ci sono molte altre questioni da affrontare quando si implementa l’IA generativa all’interno della propria organizzazione.
Sommario
Sulla base della ricerca, c’è ancora una lunga strada da percorrere per i fornitori e gli adottanti delle tecnologie di intelligenza artificiale generativa. Legislatori, progettisti di sistemi, governi e organizzazioni devono lavorare insieme per affrontare queste importanti questioni. Come punto di partenza, possiamo assicurarci di essere trasparenti nel nostro design, nell’implementazione e nell’uso dei sistemi di intelligenza artificiale. Per settori regolamentati, potrebbe essere una sfida in quanto i linguaggi di modellazione linguistica spesso hanno miliardi di parametri. Miliardi! Come può qualcosa essere interpretabile e trasparente con così tanti fattori? Questi sistemi devono avere una documentazione chiara e inequivocabile e dobbiamo rispettare i diritti di proprietà intellettuale. Per sostenere l’ambiente, la responsabilità sociale e la governance aziendale (ESG), sarà anche necessario progettare un quadro standardizzato per misurare e segnalare il consumo di energia. Inoltre, i sistemi di intelligenza artificiale devono essere sicuri, rispettare la privacy e difendere i valori umani. Dobbiamo adottare un approccio centrato sull’uomo all’intelligenza artificiale.
Se desideri saperne di più sull’intelligenza artificiale, dai un’occhiata al mio libro “Intelligenza Artificiale: una guida esecutiva per far funzionare l’IA per la tua azienda” su Amazon o all’audiolibro narrato sull’IA su Google Play.
[1] Shear, Michael D., Cecilia Kang e David E. Sanger. 2023. “Sotto pressione da parte di Biden, le aziende di intelligenza artificiale accettano di definire le regole per nuovi strumenti.” The New York Times, 21 luglio 2023, sec. U.S. https://www.nytimes.com/2023/07/21/us/politics/ai-regulation-biden.html.
[2] Parlamento europeo. 2023. “EU AI Act: la prima regolamentazione sull’intelligenza artificiale | Notizie | Parlamento europeo.” www.europarl.europa.eu. 6 agosto 2023. https://www.europarl.europa.eu/news/en/headlines/society/20230601STO93804/eu-ai-act-first-regulation-on-artificial-intelligence.
[3] Bommasani, Rishi, Kevin Klyman, Daniel Zhang e Percy Liang. 2023. “Stanford CRFM.” Crfm.stanford.edu. 15 giugno 2023. https://crfm.stanford.edu/2023/06/15/eu-ai-act.html.
[4] Bommasani, Rishi, Kevin Klyman, Daniel Zhang e Percy Liang. 2023. “Stanford CRFM.” Crfm.stanford.edu. 15 giugno 2023. https://crfm.stanford.edu/2023/06/15/eu-ai-act.html.
[5] ai. 2023. “Requisiti di potenza per addestrare i moderni LLM.” Nnlabs.org. 5 marzo 2023. https://www.nnlabs.org/power-requirements-of-large-language-models/.