Distribuisci migliaia di insiemi di modelli con i punti finali multi-modello di Amazon SageMaker su GPU per ridurre al minimo i costi di hosting
Distribuisci insiemi di modelli con punti finali multi-modello di Amazon SageMaker su GPU per ridurre i costi di hosting
L’adozione dell’intelligenza artificiale (AI) sta accelerando in tutti i settori e ambiti di utilizzo. Recenti progressi scientifici nel deep learning (DL), nei grandi modelli di linguaggio (LLMs) e nell’AI generativa consentono ai clienti di utilizzare soluzioni avanzate all’avanguardia con prestazioni quasi simili a quelle umane. Questi modelli complessi spesso richiedono l’accelerazione hardware perché consente non solo una formazione più veloce, ma anche un’elaborazione più rapida quando si utilizzano reti neurali profonde in applicazioni in tempo reale. Il grande numero di core di elaborazione parallela delle GPU le rende particolarmente adatte per queste attività di DL.
Tuttavia, oltre all’invocazione del modello, queste applicazioni DL spesso richiedono anche la pre-elaborazione o la post-elaborazione in un flusso di lavoro di inferenza. Ad esempio, le immagini di input per un caso di utilizzo di rilevamento degli oggetti potrebbero dover essere ridimensionate o ritagliate prima di essere inviate a un modello di visione artificiale, o la tokenizzazione degli input di testo prima di essere utilizzata in un LLM. NVIDIA Triton è un server di inferenza open-source che consente agli utenti di definire tali flussi di lavoro di inferenza come un insieme di modelli sotto forma di un grafo aciclico orientato (DAG). È progettato per eseguire modelli su larga scala sia su CPU che su GPU. Amazon SageMaker supporta il deployment di Triton in modo trasparente, consentendoti di utilizzare le funzioni di Triton beneficiando anche delle capacità di SageMaker: un ambiente gestito e sicuro con integrazione di strumenti MLOps, ridimensionamento automatico dei modelli ospitati e altro ancora.
AWS, nel suo impegno ad aiutare i clienti a ottenere il massimo risparmio, ha continuamente innovato non solo nelle opzioni di prezzo e nei servizi proattivi di ottimizzazione dei costi, ma anche nel lancio di funzionalità di risparmio dei costi come gli endpoint multi-modello (MMEs). Gli MMEs sono una soluzione conveniente per il deployment di un gran numero di modelli utilizzando la stessa flotta di risorse e un contenitore di servizio condiviso per ospitare tutti i modelli. Invece di utilizzare più endpoint per singoli modelli, è possibile ridurre i costi di hosting deployando più modelli pagando solo per un singolo ambiente di inferenza. Inoltre, gli MMEs riducono i costi di deployment perché SageMaker si occupa del caricamento dei modelli in memoria e della loro scalabilità in base ai pattern di traffico verso l’endpoint.
In questo post, mostriamo come eseguire più modelli di deep learning in ensemble su un’istanza GPU con un MME di SageMaker. Per seguire questo esempio, puoi trovare il codice nel repository pubblico di esempi di SageMaker.
- Ospita l’interfaccia utente di Spark su Amazon SageMaker Studio
- Rilascio di Swift Transformers Esegui LLM on-device sui dispositivi Apple
- Perfeziona Llama 2 con DPO
Come funzionano i MME di SageMaker con GPU
Con i MME, un singolo contenitore ospita più modelli. SageMaker controlla il ciclo di vita dei modelli ospitati sul MME caricandoli e scaricandoli nella memoria del contenitore. Invece di scaricare tutti i modelli nell’istanza dell’endpoint, SageMaker carica e memorizza dinamicamente i modelli man mano che vengono invocati.
Quando viene effettuata una richiesta di invocazione per un particolare modello, SageMaker esegue le seguenti operazioni:
- Innanzitutto, instrada la richiesta all’istanza dell’endpoint.
- Se il modello non è stato caricato, scarica l’artefatto del modello da Amazon Simple Storage Service (Amazon S3) nel volume Amazon Elastic Block Storage (Amazon EBS) di quell’istanza.
- Carica il modello nella memoria del contenitore sull’istanza di calcolo con accelerazione GPU. Se il modello è già caricato nella memoria del contenitore, l’invocazione sarà più veloce perché non saranno necessari ulteriori passaggi.
Quando è necessario caricare un modello aggiuntivo e l’utilizzo della memoria dell’istanza è elevato, SageMaker scaricherà i modelli non utilizzati dal contenitore dell’istanza per garantire che ci sia sufficiente memoria. Questi modelli scaricati rimarranno nel volume EBS dell’istanza in modo che possano essere caricati nella memoria del contenitore in seguito, evitando così la necessità di scaricarli nuovamente dal bucket S3. Tuttavia, se il volume di archiviazione dell’istanza raggiunge la sua capacità massima, SageMaker cancellerà i modelli non utilizzati dal volume di archiviazione. Nei casi in cui il MME riceva molte richieste di invocazione e siano presenti istanze aggiuntive (o una politica di auto-scaling), SageMaker instrada alcune richieste verso altre istanze nel cluster di inferenza per gestire il traffico intenso.
Questo non solo fornisce un meccanismo di risparmio dei costi, ma consente anche di distribuire dinamicamente nuovi modelli e deprecare quelli vecchi. Per aggiungere un nuovo modello, è sufficiente caricarlo nel bucket S3 configurato per il MME e invocarlo. Per eliminare un modello, basta smettere di inviare richieste e cancellarlo dal bucket S3. L’aggiunta o l’eliminazione di modelli da un MME non richiede l’aggiornamento dell’endpoint stesso!
Ensemble di Triton
L’ensemble di modelli di Triton rappresenta un flusso di lavoro che consiste in un modello, una logica di pre-elaborazione e post-elaborazione e la connessione dei tensori di input e output tra di essi. Una singola richiesta di inferenza a un ensemble attiva l’esecuzione dell’intero flusso di lavoro come una serie di passaggi utilizzando lo scheduler dell’ensemble. Lo scheduler raccoglie i tensori di output in ogni passaggio e li fornisce come tensori di input per altri passaggi secondo le specifiche. Per chiarire: il modello di ensemble è ancora visto come un singolo modello da un punto di vista esterno.
L’architettura del server Triton include un repository di modelli: un repository basato su un sistema di file dei modelli che Triton renderà disponibili per l’inferenza. Triton può accedere ai modelli da uno o più percorsi di file accessibili localmente o da posizioni remote come Amazon S3.
Ogni modello in un repository di modelli deve includere una configurazione del modello che fornisce informazioni obbligatorie e facoltative sul modello. Tipicamente, questa configurazione viene fornita in un file config.pbtxt specificato come ModelConfig protobuf. Una configurazione minima del modello deve specificare la piattaforma o il backend (come PyTorch o TensorFlow), la proprietà max_batch_size, e i tensori di input e output del modello.
Triton su SageMaker
SageMaker consente il deployment del modello utilizzando il server Triton con del codice personalizzato. Questa funzionalità è disponibile tramite i container del server di inferenza Triton gestiti da SageMaker. Questi container supportano i comuni framework di machine learning (ML) (come TensorFlow, ONNX e PyTorch, oltre a formati di modello personalizzati) e variabili d’ambiente utili che consentono di ottimizzare le prestazioni su SageMaker. È consigliato utilizzare le immagini dei container di Deep Learning di SageMaker (DLC) poiché vengono mantenute e regolarmente aggiornate con patch di sicurezza.
Guida alla soluzione
In questo post, effettuiamo il deployment di due diversi tipi di ensemble su una istanza GPU, utilizzando Triton e un singolo endpoint SageMaker.
Il primo ensemble è composto da due modelli: un modello DALI per il preprocessing delle immagini e un modello TensorFlow Inception v3 per l’inferenza effettiva. L’ensemble di pipeline prende immagini codificate come input, che dovranno essere decodificate, ridimensionate a una risoluzione di 299×299 e normalizzate. Questo preprocessing sarà gestito dal modello DALI. DALI è una libreria open-source per le comuni attività di preprocessing di immagini e speech, come decodifica e data augmentation. Inception v3 è un modello di riconoscimento delle immagini che è composto da convoluzioni simmetriche e asimmetriche, e livelli fully connected di pooling medio e massimo (ed è quindi perfetto per l’uso su GPU).
Il secondo ensemble trasforma frasi di testo in embedding e consiste di tre modelli. Innanzitutto, viene applicato un modello di preprocessing alla tokenizzazione del testo di input (implementata in Python). Poi utilizziamo un modello BERT pre-trained (non case-sensitive) dal Model Hub di Hugging Face per estrarre gli embedding dei token. BERT è un modello di lingua inglese che è stato addestrato utilizzando un obiettivo di masked language modeling (MLM). Infine, applichiamo un modello di postprocessing in cui gli embedding di token grezzi dal passaggio precedente vengono combinati in embedding di frasi.
Dopo aver configurato Triton per utilizzare questi ensemble, mostriamo come configurare e eseguire il SageMaker MME.
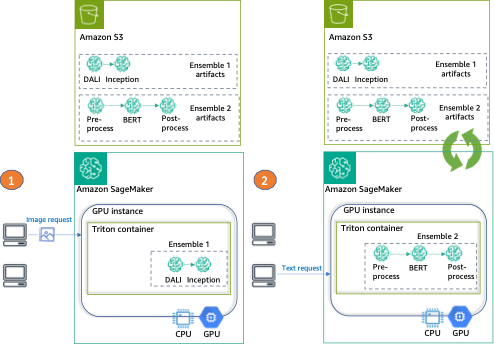
Infine, forniamo un esempio di invocazione per ciascun ensemble, come si può vedere nel seguente diagramma:
- Ensemble 1 – Invocare l’endpoint con un’immagine, specificando DALI-Inception come ensemble di destinazione
- Ensemble 2 – Invocare lo stesso endpoint, questa volta con input di testo e richiedendo l’ensemble di preprocess-BERT-postprocess
Configurare l’ambiente
Prima di tutto, configuriamo l’ambiente necessario. Ciò include l’aggiornamento delle librerie AWS (come Boto3 e l’SDK di SageMaker) e l’installazione delle dipendenze necessarie per impacchettare i nostri ensemble ed eseguire inferenze utilizzando Triton. Utilizziamo anche il ruolo di esecuzione predefinito di SageMaker SDK. Utilizziamo questo ruolo per consentire a SageMaker di accedere ad Amazon S3 (dove sono archiviati i nostri artefatti del modello) e al registro dei container (da cui verrà utilizzata l’immagine NVIDIA Triton). Vedere il codice seguente:
import boto3, json, sagemaker, time
from sagemaker import get_execution_role
import nvidia.dali as dali
import nvidia.dali.types as types
# Variabili di SageMaker
sm_client = boto3.client(service_name="sagemaker")
runtime_sm_client = boto3.client("sagemaker-runtime")
sagemaker_session = sagemaker.Session(boto_session=boto3.Session())
role = get_execution_role()
# Altre variabili
instance_type = "ml.g4dn.4xlarge"
sm_model_name = "triton-tf-dali-ensemble-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
endpoint_config_name = "triton-tf-dali-ensemble-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
endpoint_name = "triton-tf-dali-ensemble-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())Preparare gli ensemble
In questo prossimo passaggio, prepariamo i due ensemble: il TensorFlow (TF) Inception con preprocessing DALI e il BERT con preprocessing e postprocessing in Python.
Ciò comporta il download dei modelli preaddestrati, la fornitura dei file di configurazione Triton e l’impacchettamento degli artefatti da archiviare in Amazon S3 prima del deploy.
Preparare l’ensemble TF e DALI
Prima di tutto, prepariamo le directory per archiviare i nostri modelli e le configurazioni: per il TF Inception (inception_graphdef), per il preprocessing DALI (dali) e per l’ensemble (ensemble_dali_inception). Poiché Triton supporta la versione dei modelli, aggiungiamo anche la versione del modello al percorso della directory (indicata come 1 perché abbiamo solo una versione). Per saperne di più sulla politica di versione di Triton, fare riferimento alla Politica di Versione. Successivamente, scarichiamo il modello Inception v3, lo estraiamo e lo copiamo nella directory del modello inception_graphdef. Ecco il codice seguente:
!mkdir -p model_repository/inception_graphdef/1
!mkdir -p model_repository/dali/1
!mkdir -p model_repository/ensemble_dali_inception/1
!wget -O /tmp/inception_v3_2016_08_28_frozen.pb.tar.gz \
https://storage.googleapis.com/download.tensorflow.org/models/inception_v3_2016_08_28_frozen.pb.tar.gz
!(cd /tmp && tar xzf inception_v3_2016_08_28_frozen.pb.tar.gz)
!mv /tmp/inception_v3_2016_08_28_frozen.pb model_repository/inception_graphdef/1/model.graphdefOra, configuriamo Triton per utilizzare il nostro pipeline di ensemble. In un file config.pbtxt, specifichiamo le forme e i tipi dei tensori di input e output e i passaggi che il scheduler Triton deve eseguire (preprocessing DALI e il modello Inception per la classificazione delle immagini):
%%writefile model_repository/ensemble_dali_inception/config.pbtxt
name: "ensemble_dali_inception"
platform: "ensemble"
max_batch_size: 256
input [
{
name: "INPUT"
data_type: TYPE_UINT8
dims: [ -1 ]
}
]
output [
{
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 1001 ]
}
]
ensemble_scheduling {
step [
{
model_name: "dali"
model_version: -1
input_map {
key: "DALI_INPUT_0"
value: "INPUT"
}
output_map {
key: "DALI_OUTPUT_0"
value: "preprocessed_image"
}
},
{
model_name: "inception_graphdef"
model_version: -1
input_map {
key: "input"
value: "preprocessed_image"
}
output_map {
key: "InceptionV3/Predictions/Softmax"
value: "OUTPUT"
}
}
]
}Successivamente, configuriamo ciascuno dei modelli. Prima di tutto, la configurazione del modello per il backend DALI:
%%writefile model_repository/dali/config.pbtxt
name: "dali"
backend: "dali"
max_batch_size: 256
input [
{
name: "DALI_INPUT_0"
data_type: TYPE_UINT8
dims: [ -1 ]
}
]
output [
{
name: "DALI_OUTPUT_0"
data_type: TYPE_FP32
dims: [ 299, 299, 3 ]
}
]
parameters: [
{
key: "num_threads"
value: { string_value: "12" }
}
]Successivamente, la configurazione del modello per TensorFlow Inception v3 scaricato in precedenza:
%%writefile model_repository/inception_graphdef/config.pbtxt
name: "inception_graphdef"
platform: "tensorflow_graphdef"
max_batch_size: 256
input [
{
name: "input"
data_type: TYPE_FP32
format: FORMAT_NHWC
dims: [ 299, 299, 3 ]
}
]
output [
{
name: "InceptionV3/Predictions/Softmax"
data_type: TYPE_FP32
dims: [ 1001 ]
label_filename: "inception_labels.txt"
}
]
instance_group [
{
kind: KIND_GPU
}
]Perché questo è un modello di classificazione, dobbiamo anche copiare le etichette del modello Inception nella directory inception_graphdef nel repository del modello. Queste etichette includono 1.000 etichette di classe dal dataset ImageNet.
!aws s3 cp s3://sagemaker-sample-files/datasets/labels/inception_labels.txt model_repository/inception_graphdef/inception_labels.txtIn seguito, configuriamo e serializziamo la pipeline DALI che gestirà la nostra preelaborazione su file. La preelaborazione include la lettura dell’immagine (usando la CPU), la decodifica (accelerata usando la GPU) e il ridimensionamento e la normalizzazione dell’immagine.
@dali.pipeline_def(batch_size=3, num_threads=1, device_id=0)
def pipe():
"""Crea una pipeline che legge immagini e maschere, decodifica le immagini e le restituisce."""
images = dali.fn.external_source(device="cpu", name="DALI_INPUT_0")
images = dali.fn.decoders.image(images, device="mixed", output_type=types.RGB)
images = dali.fn.resize(images, resize_x=299, resize_y=299) #ridimensiona l'immagine alle dimensioni predefinite di 299x299
images = dali.fn.crop_mirror_normalize(
images,
dtype=types.FLOAT,
output_layout="HWC",
crop=(299, 299), #ritaglia l'immagine alle dimensioni predefinite di 299x299
mean=[0.485 * 255, 0.456 * 255, 0.406 * 255], #ritaglia una regione centrale dell'immagine
std=[0.229 * 255, 0.224 * 255, 0.225 * 255], #ritaglia una regione centrale dell'immagine
)
return images
pipe().serialize(filename="model_repository/dali/1/model.dali")Infine, raggruppiamo insieme gli artefatti e li carichiamo come un singolo oggetto su Amazon S3:
!tar -cvzf model_tf_dali.tar.gz -C model_repository .
model_uri = sagemaker_session.upload_data(
path="model_tf_dali.tar.gz", key_prefix="triton-mme-gpu-ensemble"
)
print("URI del modello S3: {}".format(model_uri))Prepara l’ensemble di TensorRT e Python
In questo esempio, utilizziamo un modello preaddestrato dalla libreria transformers.
Puoi trovare tutti i modelli (preelaborazione e postelaborazione, insieme ai file config.pbtxt) nella cartella ensemble_hf. La nostra struttura del file system includerà quattro directory (tre per i passaggi del modello individuale e una per l’ensemble) e le rispettive versioni:
ensemble_hf
├── bert-trt
| |── model.pt
| |──config.pbtxt
├── ensemble
│ └── 1
| └── config.pbtxt
├── postprocess
│ └── 1
| └── model.py
| └── config.pbtxt
├── preprocess
│ └── 1
| └── model.py
| └── config.pbtxtNella cartella workspace, forniamo due script: il primo per convertire il modello nel formato ONNX (onnx_exporter.py) e lo script di compilazione TensorRT (generate_model_trt.sh).
Triton supporta nativamente l’esecuzione di TensorRT, che consente di distribuire facilmente un motore TensorRT, ottimizzando così per un’architettura GPU selezionata.
Per assicurarci di utilizzare la versione di TensorRT e le dipendenze compatibili con quelle nel nostro contenitore Triton, compiliamo il modello utilizzando la versione corrispondente dell’immagine del contenitore PyTorch di NVIDIA:
model_id = "sentence-transformers/all-MiniLM-L6-v2"
! docker run --gpus=all --rm -it -v `pwd`/workspace:/workspace nvcr.io/nvidia/pytorch:22.10-py3 /bin/bash generate_model_trt.sh $model_idQuindi copiamo gli artefatti del modello nella directory che abbiamo creato in precedenza e aggiungiamo una versione al percorso:
! mkdir -p ensemble_hf/bert-trt/1 && mv workspace/model.plan ensemble_hf/bert-trt/1/model.plan && rm -rf workspace/model.onnx workspace/core*Utilizziamo un Conda pack per generare un ambiente Conda che verrà utilizzato dal backend Python di Triton nella preelaborazione e nella postelaborazione:
!bash conda_dependencies.sh
!cp processing_env.tar.gz ensemble_hf/postprocess/ && cp processing_env.tar.gz ensemble_hf/preprocess/
!rm processing_env.tar.gzInfine, carichiamo gli artefatti del modello su Amazon S3:
!tar -C ensemble_hf/ -czf model_trt_python.tar.gz .
model_uri = sagemaker_session.upload_data(
path="model_trt_python.tar.gz", key_prefix="triton-mme-gpu-ensemble"
)
print("S3 model uri: {}".format(model_uri))Esegui ensemble su un’istanza SageMaker MME con GPU
Ora che i nostri artefatti di ensemble sono memorizzati su Amazon S3, possiamo configurare e avviare il SageMaker MME.
Iniziamo recuperando l’URI dell’immagine del contenitore per l’immagine Triton DLC che corrisponde a quella nel registro dei contenitori della nostra regione (e viene utilizzata per la compilazione del modello TensorRT):
account_id_map = {
"us-east-1": "785573368785",
"us-east-2": "007439368137",
"us-west-1": "710691900526",
"us-west-2": "301217895009",
"eu-west-1": "802834080501",
"eu-west-2": "205493899709",
"eu-west-3": "254080097072",
"eu-north-1": "601324751636",
"eu-south-1": "966458181534",
"eu-central-1": "746233611703",
"ap-east-1": "110948597952",
"ap-south-1": "763008648453",
"ap-northeast-1": "941853720454",
"ap-northeast-2": "151534178276",
"ap-southeast-1": "324986816169",
"ap-southeast-2": "355873309152",
"cn-northwest-1": "474822919863",
"cn-north-1": "472730292857",
"sa-east-1": "756306329178",
"ca-central-1": "464438896020",
"me-south-1": "836785723513",
"af-south-1": "774647643957",
}
region = boto3.Session().region_name
if region not in account_id_map.keys():
raise ("REGIONE NON SUPPORTATA")
base = "amazonaws.com.cn" if region.startswith("cn-") else "amazonaws.com"
triton_image_uri = "{account_id}.dkr.ecr.{region}.{base}/sagemaker-tritonserver:23.03-py3".format(
account_id=account_id_map[region], region=region, base=base
)Successivamente, creiamo il modello in SageMaker. Nella richiesta create_model, descriviamo il contenitore da utilizzare e la posizione degli artefatti del modello, e specificare utilizzando il parametro Mode che si tratta di un multi-modello.
container = {
"Image": triton_image_uri,
"ModelDataUrl": models_s3_location,
"Mode": "MultiModel",
}
create_model_response = sm_client.create_model(
ModelName=sm_model_name, ExecutionRoleArn=role, PrimaryContainer=container
)Per ospitare i nostri ensemble, creiamo una configurazione del punto di accesso con la chiamata API create_endpoint_config, e quindi creiamo un punto di accesso con la chiamata API create_endpoint. SageMaker quindi distribuisce tutti i contenitori che hai definito per il modello nell’ambiente di hosting.
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"InstanceType": instance_type,
"InitialVariantWeight": 1,
"InitialInstanceCount": 1,
"ModelName": sm_model_name,
"VariantName": "AllTraffic",
}
],
)
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name
)Anche se in questo esempio stiamo impostando un’istanza singola per ospitare il nostro modello, i MME di SageMaker supportano completamente l’impostazione di una politica di scaling automatico. Per ulteriori informazioni su questa funzionalità, consulta Esegui più modelli di deep learning su GPU con endpoint multi-modello di Amazon SageMaker.
Creare i payload delle richieste e invocare il MME per ogni modello
Dopo aver distribuito il nostro MME in tempo reale, è il momento di invocare il nostro endpoint con ciascuno dei modelli di ensemble utilizzati.
Prima di tutto, creiamo un payload per l’ensemble DALI-Inception. Utilizziamo l’immagine shiba_inu_dog.jpg dal dataset pubblico di immagini di animali domestici di SageMaker. Carichiamo l’immagine come un array di byte codificato da utilizzare nel backend DALI (per saperne di più, vedere gli esempi di decodifica delle immagini).
sample_img_fname = "shiba_inu_dog.jpg"
import numpy as np
s3_client = boto3.client("s3")
s3_client.download_file(
"sagemaker-sample-files", "datasets/image/pets/shiba_inu_dog.jpg", sample_img_fname
)
def load_image(img_path):
"""
Carica l'immagine come un array di byte codificato.
Questo è un approccio tipico da utilizzare nel backend DALI
"""
with open(img_path, "rb") as f:
img = f.read()
return np.array(list(img)).astype(np.uint8)
rv = load_image(sample_img_fname)
print(f"Forma dell'immagine {rv.shape}")
rv2 = np.expand_dims(rv, 0)
print(f"Forma dell'array di immagini espanso {rv2.shape}")
payload = {
"inputs": [
{
"name": "INPUT",
"shape": rv2.shape,
"datatype": "UINT8",
"data": rv2.tolist(),
}
]
}Con la nostra immagine codificata e il payload pronto, invochiamo l’endpoint.
Si noti che specifichiamo il nostro ensemble di destinazione come artefatto model_tf_dali.tar.gz. Il parametro TargetModel è ciò che differenzia gli MME dagli endpoint di singolo modello e ci consente di indirizzare la richiesta al modello corretto.
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name, ContentType="application/octet-stream", Body=json.dumps(payload), TargetModel="model_tf_dali.tar.gz"
)La risposta include i metadati sull’invocazione (come il nome del modello e la versione) e la risposta effettiva dell’inferenza nella parte dei dati dell’oggetto di output. In questo esempio, otteniamo un array di 1.001 valori, dove ogni valore è la probabilità della classe a cui appartiene l’immagine (1.000 classi e 1 in più per gli altri). Successivamente, invochiamo nuovamente il nostro MME, ma questa volta puntiamo al secondo ensemble. Qui i dati sono solo due semplici frasi di testo:
text_inputs = ["Frase 1", "Frase 2"]Per semplificare la comunicazione con Triton, il progetto Triton fornisce diverse librerie client. Utilizziamo quella libreria per preparare il payload nella nostra richiesta:
import tritonclient.http as http_client
text_inputs = ["Frase 1", "Frase 2"]
inputs = []
inputs.append(http_client.InferInput("INPUT0", [len(text_inputs), 1], "BYTES"))
batch_request = [[text_inputs[i]] for i in range(len(text_inputs))]
input0_real = np.array(batch_request, dtype=np.object_)
inputs[0].set_data_from_numpy(input0_real, binary_data=True)
outputs = []
outputs.append(http_client.InferRequestedOutput("finaloutput"))
request_body, header_length = http_client.InferenceServerClient.generate_request_body(
inputs, outputs=outputs
)Adesso siamo pronti per invocare l’endpoint: questa volta il modello di destinazione è l’ensemble model_trt_python.tar.gz:
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/vnd.sagemaker-triton.binary+json;json-header-size={}".format(
header_length
),
Body=request_body,
TargetModel="model_trt_python.tar.gz"
)La risposta sono le rappresentazioni delle frasi che possono essere utilizzate in una varietà di applicazioni di elaborazione del linguaggio naturale (NLP).
Pulizia
Infine, puliamo ed eliminiamo l’endpoint, la configurazione dell’endpoint e il modello:
sm_client.delete_endpoint(EndpointName=endpoint_name)
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
sm_client.delete_model(ModelName=sm_model_name)Conclusione
In questo post, abbiamo mostrato come configurare, distribuire e invocare un SageMaker MME con ensemble Triton su un’istanza accelerata da GPU. Abbiamo ospitato due ensemble su un singolo ambiente di inferenza in tempo reale, riducendo così il nostro costo del 50% (per un’istanza g4dn.4xlarge, che rappresenta oltre $13.000 di risparmio annuo). Sebbene questo esempio abbia utilizzato solo due pipeline, gli MME di SageMaker possono supportare migliaia di ensemble di modelli, rendendolo un meccanismo straordinario di risparmio dei costi. Inoltre, è possibile utilizzare la capacità dinamica degli MME di SageMaker per caricare (e scaricare) modelli al fine di ridurre al minimo l’onere operativo della gestione delle distribuzioni di modelli in produzione.