I ricercatori di UC Berkeley e Meta AI propongono un modello di riconoscimento delle azioni lagrangiane unendo la posa 3D e l’aspetto contestualizzato dei tracklet.
UC Berkeley and Meta AI researchers propose a model for recognizing Lagrangian actions by combining 3D pose and contextualized tracklet appearance.


Nella meccanica dei fluidi è consueto distinguere tra le formulazioni del campo di flusso di Lagrange ed Euler. Secondo Wikipedia, “la specificazione lagrangiana del campo di flusso è un approccio allo studio del movimento dei fluidi in cui l’osservatore segue un pacchetto di fluido discreto mentre fluisce nello spazio e nel tempo. La linea di traiettoria di un pacchetto può essere determinata graficando la sua posizione nel tempo. Questo può essere rappresentato come il galleggiare lungo un fiume mentre si è seduti in una barca. La specificazione euleriana del campo di flusso è un metodo di analisi del movimento dei fluidi che pone particolare enfasi sui luoghi nello spazio attraverso i quali il fluido fluisce nel tempo. Seduti su una sponda del fiume e osservando l’acqua passare da un punto fisso vi aiuterà a visualizzarlo.”
Queste idee sono cruciali per capire come vengono esaminati i registri delle azioni umane. Secondo la prospettiva euleriana, si concentrerebbero su vettori di caratteristiche in determinati luoghi, come (x, y) o (x, y, z), e considererebbero l’evoluzione storica rimanendo fermi nello spazio in quel punto. Secondo la prospettiva lagrangiana, invece, seguirebbero, diciamo, un essere umano attraverso lo spazio-tempo e il vettore di caratteristiche correlato. Ad esempio, le ricerche precedenti per il riconoscimento dell’attività impiegavano spesso il punto di vista lagrangiano. Tuttavia, con lo sviluppo di reti neurali basate sulla convoluzione spaziotemporale 3D, la prospettiva euleriana è diventata la norma in metodi all’avanguardia come SlowFast Networks. La prospettiva euleriana è stata mantenuta anche dopo il passaggio ai sistemi di trasformazione.
Ciò è significativo perché ci offre l’opportunità di riesaminare la domanda “Quali dovrebbero essere i corrispettivi delle parole nell’analisi dei video?” durante il processo di tokenizzazione per i trasformatori. Dosovitskiy et al. hanno suggerito che le patch di immagine siano una buona opzione, e l’estensione di tale concetto ai video implica che i cuboidi spaziotemporali potrebbero essere adatti anche per i video. Invece, adottano la prospettiva lagrangiana per esaminare il comportamento umano nel loro lavoro. Ciò rende chiaro che pensano al percorso di un’entità nel tempo. In questo caso, l’entità potrebbe essere di alto livello, come un essere umano, o di basso livello, come un pixel o una patch. Optano per agire a livello di “esseri umani come entità” perché sono interessati a comprendere il comportamento umano.
- Affrontare il divario di generalizzazione dell’AI i ricercatori dell’University College di Londra propongono Spawrious – una suite di benchmark per la classificazione delle immagini contenente correlazioni spurie tra le classi e gli sfondi.
- Rivoluzionare la sintesi testo-immagine i ricercatori dell’UC Berkeley utilizzano grandi modelli di linguaggio in un processo di generazione a due fasi per un miglioramento del ragionamento spaziale e del senso comune.
- I ricercatori di Meta AI e Samsung presentano due nuovi metodi di intelligenza artificiale, Prodigy e Resetting, per l’adattamento del tasso di apprendimento che migliorano il tasso di adattamento del metodo D-Adaptation all’avanguardia.
Per fare questo, utilizzano una tecnica che analizza il movimento di una persona in un video e lo utilizza per identificare la sua attività. Possono recuperare queste traiettorie utilizzando le tecniche di tracciamento 3D PHALP e HMR 2.0, recentemente rilasciate. La figura 1 illustra come PHALP recupera le tracce delle persone dal video elevando gli individui a 3D, consentendo loro di collegare le persone attraverso diversi fotogrammi e accedere alla loro rappresentazione 3D. Utilizzano queste rappresentazioni 3D delle persone, le loro pose e posizioni 3D, come elementi fondamentali di ogni token. Ciò ci consente di costruire un sistema flessibile in cui il modello, in questo caso un trasformatore, accetta token appartenenti a vari individui con accesso alla loro identità, postura 3D e posizione 3D come input. Possiamo apprendere le interazioni interpersonali utilizzando le posizioni 3D delle persone nello scenario.
Il loro modello basato sulla tokenizzazione supera le precedenti basi che avevano solo accesso ai dati sulla postura e può utilizzare il tracciamento 3D. Sebbene l’evoluzione della posizione di una persona nel tempo sia un segnale potente, alcune attività richiedono conoscenze di sfondo aggiuntive sulle circostanze e sull’aspetto della persona. Pertanto, è fondamentale combinare la postura con i dati sull’aspetto della persona e dell’ambiente che derivano direttamente dai pixel. Per fare ciò, utilizzano inoltre modelli di riconoscimento delle azioni all’avanguardia per fornire dati supplementari basati sull’aspetto contestualizzato delle persone e dell’ambiente in un quadro lagrangiano. Registrono specificamente gli attributi di aspetto contestualizzati localizzati intorno a ciascuna traccia eseguendo intensivamente tali modelli lungo il percorso di ogni traccia.
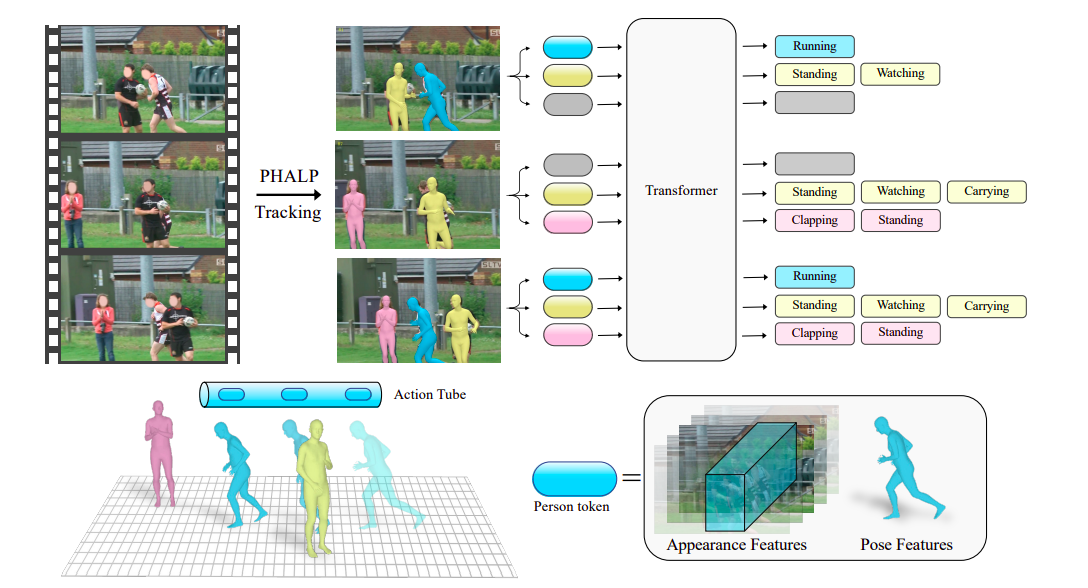
I loro token, che vengono elaborati dalle spine riconoscimento azioni, contengono informazioni esplicite sulla posizione 3D degli individui e dati di aspetto altamente campionati dai pixel. Sull’arduo dataset AVA v2.2, l’intero sistema supera il precedente stato dell’arte di un margine significativo di 2,8 mAP. Nel complesso, il loro contributo chiave è l’introduzione di una metodologia che enfatizza i benefici del tracciamento e delle pose 3D per comprendere il movimento umano. I ricercatori dell’UC Berkeley e di Meta AI suggeriscono un metodo di Riconoscimento Azione Lagrangiano con Tracciamento (LART) che utilizza le traiettorie delle persone per prevedere le loro azioni. La loro versione di base supera le precedenti versioni di base che utilizzavano informazioni sulla postura utilizzando traiettorie prive di traccia e rappresentazioni di pose 3D delle persone nel video. Inoltre, mostrano che le basi standard che considerano solo l’aspetto e il contesto del video possono essere facilmente integrate con il suggerimento del punto di vista Lagrangiano per la rilevazione delle azioni, ottenendo notevoli miglioramenti rispetto al paradigma predominante.





