Riconoscimento della lingua parlata su Mozilla Common Voice – Parte I.
Riconoscimento lingua parlata Mozilla Common Voice - Parte I.
Uno dei compiti più impegnativi dell’IA è identificare la lingua dell’interlocutore per scopi successivi di conversione del discorso in testo. Questo problema potrebbe sorgere, ad esempio, quando persone che vivono nella stessa casa e parlano lingue diverse utilizzano lo stesso dispositivo di controllo vocale come una serratura del garage o un sistema domotico intelligente.
In questa serie di articoli, cercheremo di massimizzare l’accuratezza del riconoscimento della lingua parlata utilizzando il set di dati Mozilla Common Voice (MCV). In particolare, confronteremo diversi modelli di reti neurali addestrati a distinguere tra tedesco, inglese, spagnolo, francese e russo.
In questa prima parte discuteremo la selezione dei dati, la pre-elaborazione e l’embedding.
Selezione dei dati
MCV è di gran lunga il più grande set di dati vocali disponibile pubblicamente, comprendente brevi registrazioni (durata media = 5,3s) in ben 112 lingue.
- Riconoscimento delle emozioni sul bordo migliorare l’interazione uomo-macchina attraverso l’analisi in tempo reale del linguaggio parlato
- Sfruttare i pannelli di controllo gestionali per la narrazione un percorso praticabile?
- Padronare il Monte Carlo Come simulare il tuo percorso verso modelli di apprendimento automatico migliori
Per il nostro compito di riconoscimento della lingua, scegliamo 5 lingue: tedesco, inglese, spagnolo, francese e russo. Per tedesco, inglese, spagnolo e francese, consideriamo solo gli accenti etichettati in MCV come Deutschland Deutsch, United States English, España e Français de France rispettivamente. Per ogni lingua, selezioniamo un sottoinsieme di registrazioni di adulti tra i campioni convalidati.
Abbiamo utilizzato una divisione train/val/test con 40K/5K/5K clip audio per lingua. Per ottenere una valutazione oggettiva, ci siamo assicurati che gli speaker (client_id) non si sovrapponessero tra i tre set. Quando suddividiamo i dati, riempiamo prima i set di test e di validazione con registrazioni di speaker poco rappresentati, quindi assegnamo i dati rimanenti al set di addestramento. Questo ha migliorato la diversità degli speaker nei set di valutazione/test e ha portato a una stima più oggettiva dell’errore di generalizzazione. Per evitare che un singolo speaker domini nel set di addestramento, abbiamo limitato il numero massimo di registrazioni per client_id a 2000. In media, abbiamo ottenuto 26 registrazioni per speaker. Ci siamo anche assicurati che il numero di registrazioni femminili corrispondesse al numero di registrazioni maschili. Infine, abbiamo aumentato il set di addestramento se il numero risultante di registrazioni fosse stato inferiore a 40K. La distribuzione finale dei conteggi è rappresentata nella figura qui sotto.
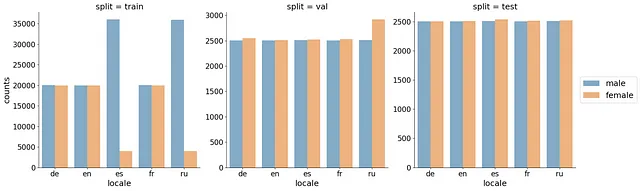
Il dataframe risultante con la divisione indicata è disponibile qui.
Pre-elaborazione dei dati
Tutti i file audio di MCV sono forniti nel formato .mp3. Anche se .mp3 è ottimo per lo stoccaggio compatto della musica, non è ampiamente supportato dalle librerie di elaborazione audio, come librosa in Python. Quindi, prima di tutto, dobbiamo convertire tutti i file in formato .wav. Inoltre, il tasso di campionamento originale di MCV è di 44kHz. Questo implica una frequenza massima di 22kHz (secondo il teorema di Nyquist). Questo sarebbe eccessivo per un compito di riconoscimento della lingua parlata: ad esempio, in inglese, la maggior parte dei fonemi non supera i 3kHz nel discorso conversazionale. Quindi, possiamo anche ridurre il tasso di campionamento a 16kHz. Questo ridurrà non solo la dimensione del file, ma accelererà anche la generazione degli embedding.
Entrambe le operazioni possono essere eseguite in un unico comando utilizzando ffmpeg:
ffmpeg -y -nostdin -hide_banner -loglevel error -i $input_file.mp3 -ar 16000 $output_file.wavIngegneria delle caratteristiche
Le informazioni rilevanti vengono di solito estratte dalle clip audio calcolando degli embedding. Considereremo quattro embedding più o meno comuni per il riconoscimento del discorso / riconoscimento della lingua parlata: mel spectrogram, MFCC, RASTA-PLP e GFCC.
Mel Spectrogram
I principi dei mel spectrogrammi sono stati ampiamente discussi su VoAGI. Un tutorial dettagliato passo-passo su mel spectrogrammi e MFCC può essere trovato anche qui.
Per ottenere il mel spectrogram, il segnale di input è sottoposto prima a un filtro di pre-emphasis. Quindi, viene eseguita la trasformata di Fourier su finestre scorrevoli applicate consecutivamente alla forma d’onda ottenuta. Dopo di ciò, la scala delle frequenze viene trasformata nella scala mel, che è lineare rispetto alla percezione umana degli intervalli. Infine, viene applicato un banco di filtri triangolari sovrapposti allo spettro di potenza sulla scala mel per simulare come l’orecchio umano percepisce il suono.
MFCC
I coefficienti di Mel sono altamente correlati, il che potrebbe essere indesiderabile per alcuni algoritmi di apprendimento automatico (ad esempio, è più conveniente avere una matrice di covarianza diagonale per i modelli di miscela gaussiana). Per decorrelare le banche di filtri di Mel, si ottengono i coefficienti cepstrali di Mel-frequency (MFCC) calcolando la Trasformata Cosinica Discreta (DCT) delle energie del filtro di log. Di solito vengono utilizzati solo alcuni MFCC primi. I passaggi esatti sono indicati qui.
RASTA-PLP
La Perceptual Linear Prediction (PLP) (Hermansky e Hynek, 1990) è un altro modo per calcolare le incapsulazioni per i clip musicali.
Le differenze tra PLP e MFCC riguardano le banche di filtri, la pre-emfasi di uguale intensità, la conversione di intensità in volume e l’applicazione della previsione lineare (Hönig et al., 2005).
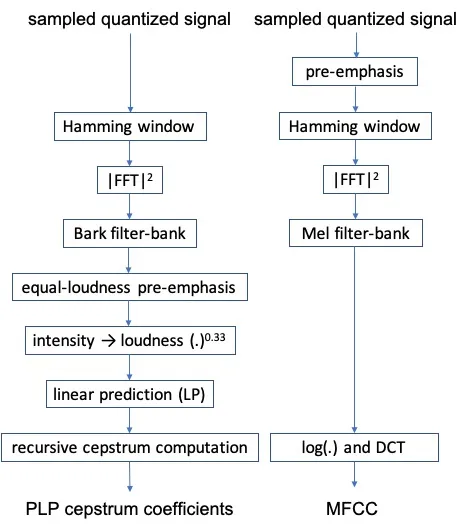
Si è riscontrato che il PLP è più robusto rispetto al MFCC quando c’è una discrepanza acustica tra i dati di addestramento e di test (Woodland et al., 1996).
Rispetto al PLP, il RASTA-PLP (Hermansky et al., 1991) esegue un filtraggio aggiuntivo nel dominio spettrale logaritmico, il che rende il metodo più robusto alle distorsioni spettrali lineari introdotte dai canali di comunicazione.
GFCC
I coefficienti cepstrali di frequenza Gammatone (GFCC) sono risultati meno sensibili al rumore rispetto al MFCC (Zhao, 2012; Shao, 2007). Rispetto al MFCC, i filtri Gammatone vengono calcolati sulla scala di larghezza di banda rettangolare equivalente (anziché sulla scala di Mel) e viene applicata l’operazione di radice cubica (anziché il logaritmo) prima del calcolo della DCT.
La figura seguente mostra un esempio di segnale insieme alle sue diverse incapsulazioni:
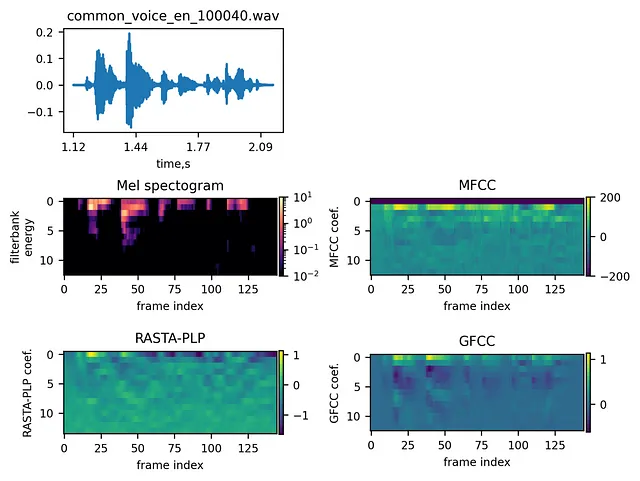
Confronto delle incapsulazioni
Per scegliere l’incapsulazione più efficiente, abbiamo addestrato la rete LSTM di attenzione di De Andrade et al., 2018. Per motivi di tempo, abbiamo addestrato la rete neurale solo su 5.000 clip.
La figura seguente confronta l’accuratezza di convalida per tutte le incapsulazioni.
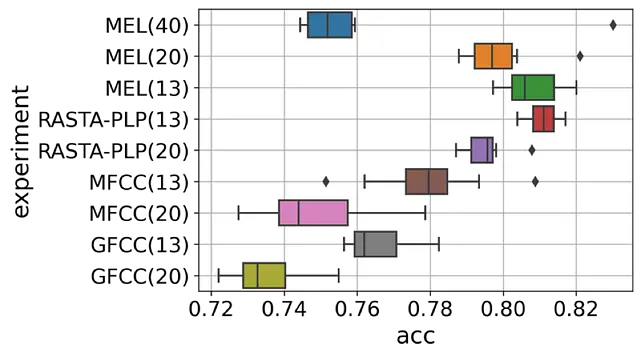
Quindi, gli spettrogrammi Mel con le prime 13 banche di filtri si avvicinano alle prestazioni di RASTA-PLP con model_order=13.
È interessante notare che gli spettrogrammi Mel hanno prestazioni migliori del MFCC. Questo supporta le precedenti affermazioni (vedi qui e qui) secondo cui gli spettrogrammi Mel sono una scelta migliore per i classificatori di reti neurali.
Un’altra osservazione è che le prestazioni di solito diminuiscono per un numero maggiore di coefficienti. Ciò può essere dovuto all’overfitting poiché i coefficienti di ordine elevato rappresentano spesso caratteristiche legate al parlante che non sono generalizzabili all’insieme di test in cui vengono scelti diversi parlanti.
A causa dei limiti di tempo, non abbiamo testato alcuna combinazione di incapsulazioni, anche se è stato osservato in precedenza che potrebbero fornire un’accuratezza superiore.
Dato che gli spettrogrammi Mel sono molto più veloci da calcolare rispetto al RASTA-PLP, useremo queste incapsulazioni in ulteriori esperimenti.
Nella Parte II eseguiremo diversi modelli di reti neurali e sceglieremo quello che classifica meglio le lingue.
Riferimenti
- De Andrade, Douglas Coimbra, et al. “A neural attention model for speech command recognition.” arXiv preprint arXiv:1808.08929 (2018).
- Hermansky, Hynek. “Perceptual linear predictive (PLP) analysis of speech.” the Journal of the Acoustical Society of America 87.4 (1990): 1738–1752.
- Hönig, Florian, et al. “Revising perceptual linear prediction (PLP).” Ninth European Conference on Speech Communication and Technology. 2005.
- Hermansky, Hynek, et al. “RASTA-PLP speech analysis.” Proc. IEEE Int’l Conf. Acoustics, speech and signal processing. Vol. 1. 1991.
- Shao, Yang, Soundararajan Srinivasan e DeLiang Wang. “Incorporating auditory feature uncertainties in robust speaker identification.” 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07. Vol. 4. IEEE, 2007.
- Woodland, Philip C., Mark John Francis Gales e David Pye. “Improving environmental robustness in large vocabulary speech recognition.” 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings. Vol. 1. IEEE, 1996.
- Zhao, Xiaojia, Yang Shao e DeLiang Wang. “CASA-based robust speaker identification.” IEEE Transactions on Audio, Speech, and Language Processing 20.5 (2012): 1608–1616.





