Crea un avatar personalizzato con l’uso dell’IA generativa utilizzando Amazon SageMaker
Crea un avatar personalizzato con IA generativa e Amazon SageMaker
L’Intelligenza Artificiale generativa è diventata uno strumento comune per migliorare e accelerare il processo creativo in diverse industrie, tra cui l’intrattenimento, la pubblicità e il design grafico. Consente esperienze più personalizzate per il pubblico e migliora la qualità complessiva dei prodotti finali.
Uno dei principali vantaggi dell’Intelligenza Artificiale generativa è la creazione di esperienze uniche e personalizzate per gli utenti. Ad esempio, l’Intelligenza Artificiale generativa viene utilizzata dai servizi di streaming per generare titoli e immagini personalizzate per i film al fine di aumentare l’interesse degli spettatori e creare immagini per i titoli basate sulla cronologia di visione e le preferenze dell’utente. Il sistema genera quindi migliaia di varianti dell’artwork di un titolo e le testa per determinare quale versione attira maggiormente l’attenzione dell’utente. In alcuni casi, l’artwork personalizzato per le serie TV ha aumentato significativamente i tassi di clic e di visualizzazione rispetto ai programmi senza artwork personalizzato.
In questo post, dimostriamo come è possibile utilizzare modelli di Intelligenza Artificiale generativa come Stable Diffusion per creare una soluzione di avatar personalizzata su Amazon SageMaker e risparmiare costi di inferenza con endpoint multi-modello (MME) contemporaneamente. La soluzione dimostra come, caricando 10-12 immagini di te stesso, puoi ottimizzare un modello personalizzato che può generare avatar basati su qualsiasi prompt di testo, come mostrato negli screenshot seguenti. Sebbene questo esempio generi avatar personalizzati, è possibile applicare la stessa tecnica a qualsiasi generazione di arte creativa ottimizzando per oggetti o stili specifici.
 |
Panoramica della soluzione
Il diagramma di architettura seguente illustra la soluzione end-to-end per il nostro generatore di avatar.
- Il Machine Learning e la tecnologia Blockchain potrebbero aiutare a contrastare la diffusione delle fake news
- Hack della Procrastinazione Trasforma i Progetti in Giochi Video (con ChatGPT)
- Antropomorfizzare l’AI gli esseri umani cercano empatia nei posti sbagliati
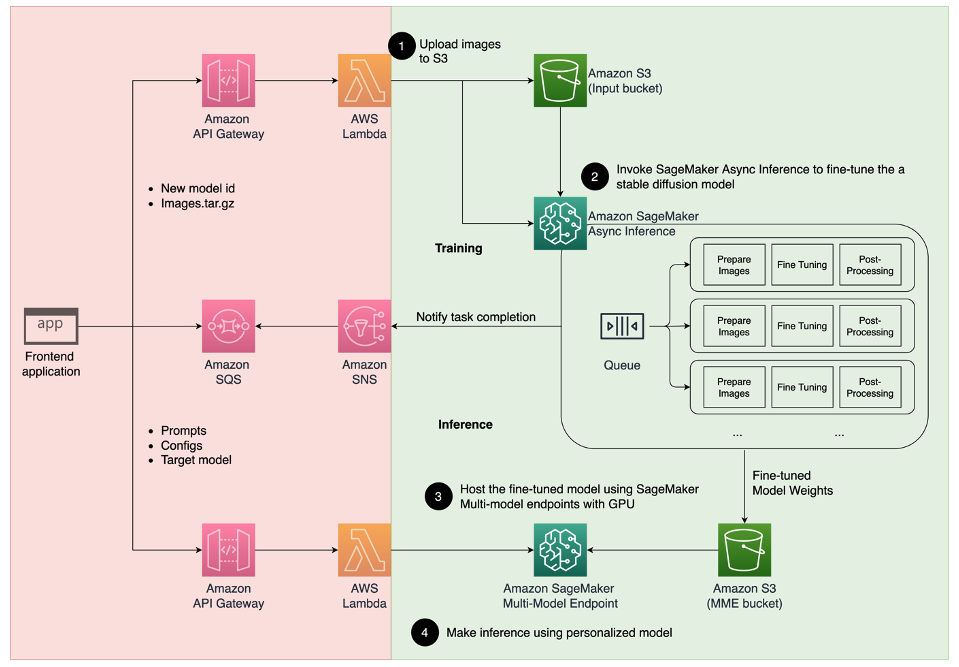
Lo scopo di questo post e del codice di esempio fornito su GitHub si concentrano solo sulla formazione del modello e sull’orchestrazione dell’inferenza (la sezione verde nel diagramma precedente). Puoi fare riferimento all’architettura completa della soluzione e sviluppare ulteriormente sulla base dell’esempio fornito.
La formazione del modello e l’inferenza possono essere suddivise in quattro fasi:
- Carica le immagini su Amazon Simple Storage Service (Amazon S3). In questa fase, ti chiediamo di fornire almeno 10 immagini ad alta risoluzione di te stesso. Più immagini fornisci, migliori saranno i risultati, ma ci vorrà più tempo per l’addestramento.
- Ottimizza un modello base Stable Diffusion 2.1 utilizzando l’inferenza asincrona di SageMaker. Spieghiamo la ragione per cui utilizziamo un endpoint di inferenza per la formazione più avanti in questo post. Il processo di ottimizzazione inizia con la preparazione delle immagini, inclusi il ritaglio del volto, la variazione dello sfondo e il ridimensionamento per il modello. Successivamente utilizziamo Low-Rank Adaptation (LoRA), una tecnica di ottimizzazione efficiente dei parametri per i modelli di linguaggio di grandi dimensioni (LLM), per ottimizzare ulteriormente il modello. Infine, nella post-elaborazione, confezioniamo i pesi LoRA ottimizzati con lo script di inferenza e i file di configurazione (tar.gz) e li carichiamo in una posizione del bucket S3 per gli MME di SageMaker.
- Ospita i modelli ottimizzati utilizzando gli MME di SageMaker con GPU. SageMaker caricherà e memorizzerà in cache dinamicamente il modello dalla posizione Amazon S3 in base al traffico di inferenza per ciascun modello.
- Utilizza il modello ottimizzato per l’inferenza. Dopo aver ricevuto la notifica del servizio di notifica Amazon Simple Notification Service (Amazon SNS) che indica l’avvenuta ottimizzazione, puoi utilizzare immediatamente quel modello fornendo un parametro
target_modelquando invochi l’MME per creare il tuo avatar.
Spieghiamo ogni fase in maggior dettaglio nelle sezioni seguenti e forniamo alcuni esempi di codice di esempio.
Prepara le immagini
Per ottenere i migliori risultati dalla messa a punto di Stable Diffusion per generare immagini di te stesso, di solito è necessario fornire una grande quantità e varietà di foto di te stesso da diverse angolazioni, con diverse espressioni e in sfondi diversi. Tuttavia, con la nostra implementazione, ora puoi ottenere un risultato di alta qualità anche con soli 10 immagini di input. Abbiamo anche aggiunto una fase di preprocessing automatizzata per estrarre il tuo volto da ogni foto. Tutto ciò di cui hai bisogno è catturare chiaramente l’essenza di come ti appari da diverse prospettive. Includi una foto frontale, uno scatto laterale da ciascun lato e foto da angolazioni intermedie. Dovresti includere anche foto con diverse espressioni facciali come sorrisi, sguardi tristi e un’espressione neutra. Avere una varietà di espressioni consentirà al modello di riprodurre meglio le tue caratteristiche facciali uniche. Le immagini di input determinano la qualità dell’avatar che puoi generare. Per assicurarti che tutto sia fatto correttamente, consigliamo un’esperienza intuitiva dell’interfaccia utente per guidare l’utente attraverso il processo di acquisizione e caricamento delle immagini.
Di seguito sono presenti esempi di immagini selfie da diverse angolazioni con diverse espressioni facciali.

Ottimizza un modello di diffusione stabile
Dopo che le immagini sono caricate su Amazon S3, possiamo invocare il punto di accesso di inferenza asincrono di SageMaker per avviare il nostro processo di addestramento. I punti di accesso asincroni sono destinati a casi d’uso di inferenza con payload (fino a 1 GB) e tempi di elaborazione lunghi (fino a 1 ora). Fornisce anche un meccanismo di accodamento incorporato per accodare le richieste e un meccanismo di notifica di completamento del task tramite Amazon SNS, oltre ad altre funzionalità native di SageMaker hosting come il ridimensionamento automatico.
Anche se il fine-tuning non è un caso d’uso di inferenza, abbiamo scelto di utilizzarlo qui al posto dei job di addestramento di SageMaker a causa dei suoi meccanismi di accodamento e notifica incorporati e della gestione del ridimensionamento automatico, inclusa la possibilità di ridurre a 0 le istanze quando il servizio non è in uso. Ciò ci consente di scalare facilmente il servizio di fine-tuning per un gran numero di utenti simultanei ed elimina la necessità di implementare e gestire componenti aggiuntive. Tuttavia, presenta il limite di 1 GB per il payload e di 1 ora per il tempo massimo di elaborazione. Nei nostri test, abbiamo riscontrato che 20 minuti sono sufficienti per ottenere risultati ragionevolmente buoni con circa 10 immagini di input su un’istanza ml.g5.2xlarge. Tuttavia, per i job di fine-tuning su larga scala, sarebbe consigliabile utilizzare l’approccio di addestramento di SageMaker.
Per ospitare il punto di accesso asincrono, dobbiamo completare diverse fasi. La prima è definire il nostro server di modelli. Per questo post, utilizziamo il Large Model Inference Container (LMI). LMI è alimentato da DJL Serving, che è una soluzione di hosting di modelli ad alte prestazioni e indipendente dal linguaggio di programmazione. Abbiamo scelto questa opzione perché il contenitore di inferenza gestito da SageMaker ha già molte delle librerie di addestramento di cui abbiamo bisogno, come Hugging Face Diffusers e Accelerate. Ciò riduce notevolmente la quantità di lavoro necessaria per personalizzare il contenitore per il nostro job di fine-tuning.
Il seguente snippet di codice mostra la versione del contenitore LMI utilizzata nel nostro esempio:
inference_image_uri = (
f"763104351884.dkr.ecr.{region}.amazonaws.com/djl-inference:0.21.0-deepspeed0.8.3-cu117"
)
print(f"Image going to be used is ---- > {inference_image_uri}")Inoltre, abbiamo bisogno di un file serving.properties che configuri le proprietà di hosting, inclusa l’engine di inferenza da utilizzare, la posizione dell’artefatto del modello e il batching dinamico. Infine, dobbiamo avere un file model.py che carichi il modello nell’engine di inferenza e prepari l’input e l’output dei dati dal modello. Nel nostro esempio, utilizziamo il file model.py per avviare il job di fine-tuning, che spieghiamo in maggior dettaglio in una sezione successiva. Entrambi i file serving.properties e model.py sono forniti nella cartella training_service.
Il passaggio successivo dopo aver definito il nostro server di modelli è creare una configurazione del punto di accesso che definisce come verrà fornita la nostra inferenza asincrona. Per il nostro esempio, stiamo semplicemente definendo il limite massimo di invocazioni simultanee e la posizione di output su S3. Con l’istanza ml.g5.2xlarge, abbiamo riscontrato che possiamo eseguire il fine-tuning contemporaneo di due modelli senza incontrare un’eccezione di memoria esaurita (OOM), pertanto impostiamo max_concurrent_invocations_per_instance su 2. Questo numero potrebbe dover essere regolato se stiamo utilizzando un diverso set di parametri di sintonizzazione o un tipo di istanza più piccolo. Consigliamo di impostare inizialmente questo valore su 1 e monitorare l’utilizzo della memoria GPU in Amazon CloudWatch.
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=f"s3://{bucket}/{s3_prefix}/async_inference/output" , # Dove saranno memorizzati i risultati
max_concurrent_invocations_per_instance=2,
notification_config={
"SuccessTopic": "...",
"ErrorTopic": "...",
}, # Configurazione delle notifiche
)Infine, creiamo un modello SageMaker che raggruppa le informazioni sul contenitore, i file del modello e il ruolo di Identity and Access Management (IAM) di AWS in un singolo oggetto. Il modello viene distribuito utilizzando la configurazione del punto di accesso da noi definita in precedenza:
modello = Model(
image_uri=image_uri,
model_data=model_data,
role=role,
env=env
)
modello.deploy(
initial_instance_count=1,
instance_type=instance_type,
endpoint_name=endpoint_name,
async_inference_config=async_inference_config
)
predittore = sagemaker.Predictor(
endpoint_name=endpoint_name,
sagemaker_session=sagemaker_session
)Quando il punto di arrivo è pronto, utilizziamo il seguente codice di esempio per invocare il punto di arrivo asincrono e avviare il processo di ottimizzazione fine:
sm_runtime = boto3.client("sagemaker-runtime")
input_s3_loc = sess.upload_data("data/jw.tar.gz", bucket, s3_prefix)
response = sm_runtime.invoke_endpoint_async(
EndpointName=sd_tuning.endpoint_name,
InputLocation=input_s3_loc)Per ulteriori dettagli su LMI su SageMaker, fare riferimento a Deploy di modelli di grandi dimensioni su Amazon SageMaker utilizzando DJLServing e l’infereza di modello parallela DeepSpeed.
Dopo l’invocazione, il punto di arrivo asincrono inizia a mettere in coda il nostro lavoro di ottimizzazione fine. Ogni lavoro passa attraverso i seguenti passaggi: prepara le immagini, esegue l’ottimizzazione fine di Dreambooth e LoRA e prepara gli artefatti del modello. Approfondiamo ulteriormente il processo di ottimizzazione fine.
Prepara le immagini
Come abbiamo menzionato in precedenza, la qualità delle immagini di input influenza direttamente la qualità del modello ottimizzato in modo fine. Per il caso d’uso dell’avatar, vogliamo che il modello si concentri sulle caratteristiche del viso. Invece di richiedere agli utenti di fornire immagini curate con cura di dimensioni e contenuti esatti, implementiamo una fase di preelaborazione utilizzando tecniche di visione artificiale per alleviare questo onere. Nella fase di preelaborazione, utilizziamo prima un modello di rilevamento del volto per isolare il volto più grande in ogni immagine. Quindi ritagliamo e riempiamo l’immagine alla dimensione richiesta di 512 x 512 pixel per il nostro modello. Infine, segmentiamo il volto dallo sfondo e aggiungiamo variazioni casuali dello sfondo. Ciò aiuta a evidenziare le caratteristiche del viso, consentendo al nostro modello di imparare dal viso stesso anziché dallo sfondo. Le seguenti immagini illustrano i tre passaggi di questo processo.
 |
 |
 |
| Passaggio 1: Rilevamento del volto utilizzando la visione artificiale | Passaggio 2: Ritaglia e riempi l’immagine a 512 x 512 pixel | Passaggio 3 (Opzionale): Segmenta e aggiungi variazioni dello sfondo |
Ottimizzazione fine di Dreambooth e LoRA
Per l’ottimizzazione fine, abbiamo combinato le tecniche di Dreambooth e LoRA. Dreambooth consente di personalizzare il modello Stable Diffusion, incorporando un soggetto nel dominio di output del modello utilizzando un identificatore univoco ed espandendo il dizionario di visione linguistica del modello. Utilizza un metodo chiamato preservazione precedente per preservare la conoscenza semantica del modello della classe del soggetto, in questo caso una persona, e utilizza altri oggetti della classe per migliorare l’output finale dell’immagine. Questo è come Dreambooth può ottenere risultati di alta qualità con solo poche immagini di input del soggetto.
Il seguente frammento di codice mostra gli input della nostra classe trainer.py per la nostra soluzione avatar. Notare che abbiamo scelto <<TOK>> come identificatore univoco. Questo è fatto appositamente per evitare di scegliere un nome che potrebbe già essere nel dizionario del modello. Se il nome esiste già, il modello deve dimenticare e quindi riconoscere il soggetto, il che potrebbe portare a risultati di ottimizzazione fine scadenti. La classe del soggetto è impostata su “una foto di persona”, il che consente la preservazione precedente generando prima foto di persone da alimentare come input aggiuntivi durante il processo di ottimizzazione fine. Questo aiuterà a ridurre l’overfitting poiché il modello cerca di preservare la conoscenza precedente di una persona utilizzando il metodo di preservazione precedente.
status = trn.run(base_model="stabilityai/stable-diffusion-2-1-base",
resolution=512,
n_steps=1000,
concept_prompt="foto di <<TOK>>", # << identificatore unico del soggetto
learning_rate=1e-4,
gradient_accumulation=1,
fp16=True,
use_8bit_adam=True,
gradient_checkpointing=True,
train_text_encoder=True,
with_prior_preservation=True,
prior_loss_weight=1.0,
class_prompt="una foto di persona", # << classe del soggetto
num_class_images=50,
class_data_dir=class_data_dir,
lora_r=128,
lora_alpha=1,
lora_bias="none",
lora_dropout=0.05,
lora_text_encoder_r=64,
lora_text_encoder_alpha=1,
lora_text_encoder_bias="none",
lora_text_encoder_dropout=0.05
)Sono state abilitate diverse opzioni di risparmio di memoria nella configurazione, tra cui fp16, use_8bit_adam e l’accumulo del gradiente. Ciò riduce l’impronta di memoria a meno di 12 GB, consentendo il fine-tuning di fino a due modelli contemporaneamente su un’istanza ml.g5.2xlarge.
LoRA è una tecnica efficiente di fine-tuning per i LLM (Linguaggio naturale a linguaggio naturale) che congela la maggior parte dei pesi e collega una piccola rete di adattatori a specifici strati del LLM pre-addestrato, consentendo una formazione più rapida e una conservazione ottimizzata. Per Stable Diffusion, l’adattatore è collegato all’encoder di testo e ai componenti U-Net del pipeline di inferenza. L’encoder di testo converte l’input in un’area latente compresa dal modello U-Net, e il modello U-Net utilizza il significato latente per generare l’immagine nel successivo processo di diffusione. L’output del fine-tuning sono solo i pesi dell’encoder di testo e dell’adattatore U-Net. Durante il tempo di inferenza, questi pesi possono essere riattaccati al modello Stable Diffusion di base per riprodurre i risultati del fine-tuning.
Le figure seguenti sono diagrammi dettagliati del fine-tuning LoRA forniti dall’autore originale: Cheng-Han Chiang, Yung-Sung Chuang, Hung-yi Lee, “AACL_2022_tutorial_PLMs,” 2022
 |
 |
Combina entrambi i metodi, siamo riusciti a generare un modello personalizzato riducendo di un ordine di grandezza i parametri. Ciò ha comportato un tempo di addestramento molto più veloce e una riduzione dell’utilizzo della GPU. Inoltre, l’archiviazione è stata ottimizzata con un peso di adattatore di soli 70 MB, rispetto a 6 GB per un modello Stable Diffusion completo, rappresentando una riduzione del 99% della dimensione.
Prepara gli artefatti del modello
Dopo il completamento del fine-tuning, il passaggio di post-elaborazione creerà un file TAR con i pesi LoRA insieme agli altri file di servizio del modello per NVIDIA Triton. Utilizziamo un backend Python, il che significa che è necessario avere il file di configurazione Triton e lo script Python utilizzato per l’inferenza. Nota che lo script Python deve essere chiamato model.py. Il file TAR del modello finale dovrebbe avere la seguente struttura di file:
|--sd_lora
|--config.pbtxt
|--1\
|--model.py
|--output #Pesi LoRA
|--text_encoder\
|--unet\
|--train.shOspita i modelli sintonizzati in modo fine utilizzando SageMaker MME con GPU
Dopo che i modelli sono stati sintonizzati in modo fine, ospitiamo i modelli personalizzati Stable Diffusion utilizzando SageMaker MME. SageMaker MME è una potente funzionalità di distribuzione che consente di ospitare più modelli in un singolo contenitore dietro un unico punto di ingresso. Gestisce automaticamente il traffico e il routing verso i modelli per ottimizzare l’utilizzo delle risorse, risparmiare costi e ridurre al minimo il carico operativo derivante dalla gestione di migliaia di punti di ingresso. Nel nostro esempio, eseguiamo l’hosting su istanze GPU e SageMaker MME supporta le GPU utilizzando Triton Server. Ciò consente di eseguire più modelli su un singolo dispositivo GPU e di sfruttare il calcolo accelerato. Per ulteriori dettagli su come ospitare Stable Diffusion su SageMaker MME, consulta “Create immagini di alta qualità con modelli Stable Diffusion e distribuiscili in modo efficiente in Amazon SageMaker”.
Per il nostro esempio, abbiamo effettuato ottimizzazioni aggiuntive per caricare i modelli pre-ottimizzati più velocemente durante le situazioni di avvio a freddo. Questo è possibile grazie al design dell’adattatore di LoRA. Poiché i pesi del modello di base e gli ambienti Conda sono gli stessi per tutti i modelli pre-ottimizzati, possiamo condividere queste risorse comuni pre-caricandole sul contenitore di hosting. Ciò lascia solo il file di configurazione di Triton, il backend Python (model.py) e i pesi dell’adattatore di LoRA da caricare dinamicamente da Amazon S3 dopo la prima invocazione. Il seguente diagramma fornisce un confronto lato a lato.

Ciò riduce significativamente il file TAR del modello da circa 6 GB a 70 MB, rendendo quindi molto più veloce il caricamento e la decompressione. Per fare il pre-caricamento nel nostro esempio, abbiamo creato un modello di backend Python di utilità in models/model_setup. Lo script copia semplicemente il modello di diffusione Stable di base e l’ambiente Conda da Amazon S3 in una posizione comune da condividere tra tutti i modelli pre-ottimizzati. Di seguito è riportato il frammento di codice che esegue il compito:
def initialize(self, args):
# setup dell'ambiente conda
self.conda_pack_path = Path(args['model_repository']) / "sd_env.tar.gz"
self.conda_target_path = Path("/tmp/conda")
self.conda_env_path = self.conda_target_path / "sd_env.tar.gz"
if not self.conda_env_path.exists():
self.conda_env_path.parent.mkdir(parents=True, exist_ok=True)
shutil.copy(self.conda_pack_path, self.conda_env_path)
# setup del modello di diffusione di base
self.base_model_path = Path(args['model_repository']) / "stable_diff.tar.gz"
try:
with tarfile.open(self.base_model_path) as tar:
tar.extractall('/tmp')
self.response_message = "Setup dell'ambiente del modello riuscito."
except Exception as e:
# stampa il messaggio di eccezione
print(f"Rilevata un'eccezione: {e}")
self.response_message = f"Rilevata un'eccezione: {e}"Quindi ogni modello pre-ottimizzato punterà alla posizione condivisa sul contenitore. L’ambiente Conda viene referenziato in config.pbtxt.
name: "pipeline_0"
backend: "python"
max_batch_size: 1
...
parameters: {
key: "EXECUTION_ENV_PATH",
value: {string_value: "/tmp/conda/sd_env.tar.gz"}
}Il modello di base di Diffusione Stabile viene caricato dalla funzione initialize() di ciascun file model.py. Applichiamo poi i pesi personalizzati di LoRA al modello unet e text_encoder per riprodurre ciascun modello pre-ottimizzato:
...
class TritonPythonModel:
def initialize(self, args):
self.output_dtype = pb_utils.triton_string_to_numpy(
pb_utils.get_output_config_by_name(json.loads(args["model_config"]),
"generated_image")["data_type"])
self.model_dir = args['model_repository']
device='cuda'
self.pipe = StableDiffusionPipeline.from_pretrained('/tmp/stable_diff',
torch_dtype=torch.float16,
revision="fp16").to(device)
# Carica i pesi di LoRA
self.pipe.unet = PeftModel.from_pretrained(self.pipe.unet, unet_sub_dir)
if os.path.exists(text_encoder_sub_dir):
self.pipe.text_encoder = PeftModel.from_pretrained(self.pipe.text_encoder, text_encoder_sub_dir)Utilizzare il modello pre-ottimizzato per l’infereza
Ora possiamo provare il nostro modello pre-ottimizzato invocando il punto di accesso di MME. I parametri di input che abbiamo esposto nel nostro esempio includono prompt, negative_prompt e gen_args, come mostrato nel seguente frammento di codice. Impostiamo il tipo di dati e la forma di ciascun elemento di input nel dizionario e li convertiamo in una stringa JSON. Infine, il payload stringa e il TargetModel vengono passati alla richiesta per generare la tua immagine di avatar.
import random
prompt = """<<TOK>> epic portrait, zoomed out, blurred background cityscape, bokeh,
perfect symmetry, by artgem, artstation ,concept art,cinematic lighting, highly
detailed, octane, concept art, sharp focus, rockstar games, post processing,
picture of the day, ambient lighting, epic composition"""
negative_prompt = """
beard, goatee, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred,
watermark, grainy, signature, cut off, draft, amateur, multiple, gross, weird, uneven, furnishing, decorating, decoration, furniture, text, poor, low, basic, worst, juvenile,
unprofessional, failure, crayon, oil, label, thousand hands
"""
seed = random.randint(1, 1000000000)
gen_args = json.dumps(dict(num_inference_steps=50, guidance_scale=7, seed=seed))
inputs = dict(prompt = prompt,
negative_prompt = negative_prompt,
gen_args = gen_args)
payload = {
"inputs":
[{"name": name, "shape": [1,1], "datatype": "BYTES", "data": [data]} for name, data in inputs.items()]
}
response = sm_runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/octet-stream",
Body=json.dumps(payload),
TargetModel="sd_lora.tar.gz",
)
output = json.loads(response["Body"].read().decode("utf8"))["outputs"]
original_image = decode_image(output[0]["data"][0])
original_imagePulizia
Segui le istruzioni nella sezione di pulizia del notebook per eliminare le risorse allocate come parte di questo post al fine di evitare addebiti non necessari. Consulta la pagina dei prezzi di Amazon SageMaker per i dettagli relativi al costo delle istanze di inferenza.
Conclusioni
In questo post abbiamo dimostrato come creare una soluzione di avatar personalizzata utilizzando Stable Diffusion su SageMaker. Sintonizzando un modello pre-addestrato con poche immagini, possiamo generare avatar che riflettono l’individualità e la personalità di ogni utente. Questo è solo uno dei molti esempi di come possiamo utilizzare l’IA generativa per creare esperienze personalizzate e uniche per gli utenti. Le possibilità sono infinite e ti incoraggiamo a sperimentare con questa tecnologia ed esplorarne il potenziale per migliorare il processo creativo. Speriamo che questo post sia stato informativo e ispiratore. Ti invitiamo a provare l’esempio e condividere le tue creazioni con noi utilizzando gli hashtag #sagemaker #mme #genai sui social media. Ci piacerebbe vedere cosa crei.
Oltre a Stable Diffusion, sono disponibili molti altri modelli di IA generativa su Amazon SageMaker JumpStart. Consulta la guida introduttiva a Amazon SageMaker JumpStart per esplorare le loro capacità.





