L’Arrivo di SDXL 1.0
Arrivo SDXL 1.0
Presentazione di SDXL 1.0: Comprensione dei Modelli di Diffusione

Nel mondo in rapida evoluzione dell’apprendimento automatico, in cui nuovi modelli e tecnologie invadono i nostri feed quasi quotidianamente, rimanere aggiornati e prendere decisioni informate diventa un compito arduo. Oggi, concentriamo la nostra attenzione su SDXL 1.0, un modello generativo di testo per immagini che ha indubbiamente suscitato considerevole interesse nel campo.
SDXL 1.0, abbreviazione di “Stable Diffusion XL”, è presentato come un modello di diffusione latente di testo in immagine che supera i suoi predecessori con una serie di promettenti miglioramenti. Nei capitoli successivi, esamineremo attentamente queste affermazioni e daremo un’occhiata più da vicino ai nuovi miglioramenti.
In particolare, SDXL è un modello open-source che affronta una preoccupazione principale nel campo dei modelli generativi. Mentre i modelli black-box hanno guadagnato riconoscimento come state-of-the-art, l’opacità della loro architettura ostacola una valutazione completa e una validazione delle loro prestazioni, limitando il coinvolgimento della comunità più ampia.
In questo articolo, ci imbarcheremo in una dettagliata esplorazione di questo modello promettente, ispezionando le sue capacità, i blocchi di costruzione e tracciando interessanti confronti con i modelli di diffusione stabile precedenti. Il mio obiettivo è fornire una chiara comprensione senza addentrarsi troppo nelle complessità tecniche, rendendo questa lettura coinvolgente e accessibile per tutti. Iniziamo!
- Governo giapponese adatta la tecnologia ChatGPT per compiti amministrativi
- La Scienza delle Decisioni sta silenziosamente diventando la nuova Scienza dei Dati?
- Come le città stanno implementando tecnologie all’avanguardia sfruttando algoritmi di IA imparziali
Comprensione della Diffusione Stabile: Svelando la Magia della Generazione di Testo in Immagini
Se ti senti sicuro di come funziona la Diffusione Stabile, o non ti interessa la parte tecnica, sentiti libero di saltare questo capitolo.
La Diffusione Stabile, il rivoluzionario modello di apprendimento profondo di testo in immagine, ha scosso il mondo dell’IA al momento del suo rilascio nel 2022, sfruttando il potere delle avanzate tecniche di diffusione.
Questo sviluppo significativo rappresenta un notevole avanzamento nella generazione di immagini di intelligenza artificiale, potenzialmente ampliando l’accesso a modelli ad alte prestazioni per un pubblico più ampio. La sorprendente capacità di trasformare descrizioni di testo semplice in complessi risultati visivi ha catturato l’attenzione di coloro che l’hanno sperimentato. La Diffusione Stabile dimostra competenza nella produzione di immagini di alta qualità, dimostrando anche una notevole velocità ed efficienza, aumentando così l’accessibilità alla creazione di arte generata da intelligenza artificiale.
La formazione della Diffusione Stabile ha coinvolto ampi set di dati pubblici come LAION-5B, sfruttando una vasta gamma di immagini con didascalie per perfezionare le sue abilità artistiche. Tuttavia, un aspetto chiave che contribuisce al suo progresso risiede nella partecipazione attiva della comunità, offrendo preziosi feedback che guidano lo sviluppo in corso del modello e migliorano le sue capacità nel tempo.
Come funziona?
Iniziamo con i principali blocchi di costruzione di un modello di Diffusione Stabile e come si possono addestrare e fare previsioni con questi modelli individualmente.
U-Net e l’Essenza del Processo di Diffusione:
Per generare immagini utilizzando modelli di visione artificiale, ci spingiamo oltre l’approccio convenzionale basato su dati etichettati, come classificazione, rilevamento o segmentazione. Nel campo della Diffusione Stabile, l’obiettivo è consentire ai modelli di imparare i dettagli complessi delle immagini stesse, catturando contesti complessi con un approccio innovativo noto come “Diffusione”.
Il processo di diffusione si sviluppa in due fasi distinte:
- Nella prima parte, prendiamo un’immagine e introduciamo una quantità controllata di rumore casuale. Questo passaggio è chiamato diffusione in avanti.
- Nella seconda parte, miriamo a denoise l’immagine e ricostruire il contenuto originale. Questo processo è noto come diffusione inversa.

La prima parte, che prevede l’aggiunta di rumore gaussiano all’immagine di input ad ogni passaggio temporale t, è relativamente semplice. Tuttavia, la seconda fase rappresenta una sfida, poiché calcolare direttamente l’immagine originale non è fattibile. Per superare questo ostacolo, utilizziamo una rete neurale, ed è qui che entra in gioco l’ingegnoso U-Net.
Sfruttando U-Net, addestriamo il nostro modello per predire il rumore da un’immagine con rumore casuale data all’istante t e calcoliamo la perdita tra il rumore predetto e il rumore effettivo. Con un dataset sufficientemente grande e più passaggi di rumore, il modello acquisisce la capacità di fare previsioni informate sui modelli di rumore. Questo modello U-Net addestrato si rivela anche prezioso per generare approssimazioni di ricostruzioni di immagini a partire da rumore dato.

Se hai familiarità con modelli di probabilità di base e visione artificiale, questo processo è relativamente semplice. Tuttavia, c’è un altro problema da notare. Addestrare milioni di immagini con rumore aggiunto e ricostruirle sarebbe estremamente dispendioso in termini di tempo e utilizzo di risorse di calcolo. Per affrontare questa sfida, i ricercatori hanno ripreso in considerazione un’architettura ben nota: Autoencoder. Poiché abbiamo già utilizzato un approccio simile con U-Net, incorporando convoluzioni trasposte e blocchi residui, questi elementi si rivelano anche vitali per gestire input di testo condizionali.
Con gli autoencoder, è possibile “codificare” i dati in uno spazio “latente” molto più piccolo e “decodificarli” tornando allo spazio originale. Infatti, è per questo che il paper originale sulla diffusione stabile è chiamato Diffusione latente. Ciò ci consente di comprimere efficacemente grandi immagini in dimensioni inferiori.
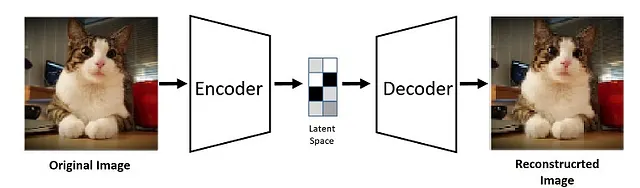
Le operazioni di diffusione in avanti e inversa avverranno ora all’interno di spazi latenti significativamente più piccoli, con conseguente riduzione dei requisiti di memoria e elaborazione molto più veloce.
Siamo quasi alla fine dell’architettura “Diffusione stabile” rinomata; l’unico elemento rimanente è la condizionatura. Tipicamente, questo aspetto viene realizzato utilizzando Text Encoder, anche se esistono altri metodi che utilizzano immagini come condizionamento, come ControlNet, ma che esulano dallo scopo di questo articolo. La condizionatura del testo svolge un ruolo fondamentale nella generazione di immagini basate su input di testo, dove risiede la vera magia del modello di diffusione stabile.
Per raggiungere questo obiettivo, possiamo addestrare un modello di embedding di testo come BERT o CLIP utilizzando immagini con didascalie e aggiungere vettori di embedding dei token come input di condizionamento. Utilizzando un meccanismo di cross-attenzione (query, chiavi e valori), possiamo mappare gli embedding di testo condizionati nei blocchi residui di U-Net. Di conseguenza, possiamo incorporare didascalie delle immagini insieme alle immagini stesse durante il processo di addestramento e condizionare efficacemente le generazioni di immagini in base al testo fornito.
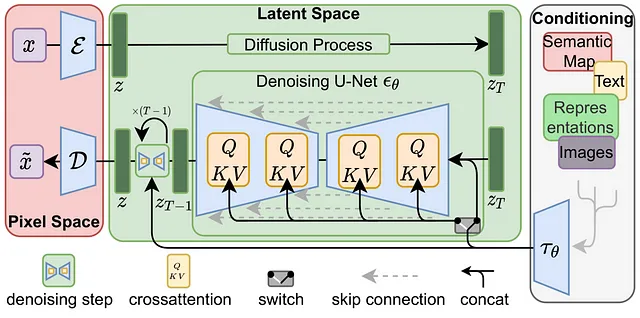
Ora che conosci tutti i mattoni di base di un modello di diffusione stabile, armato di questa conoscenza, possiamo confrontare facilmente i modelli di diffusione stabile precedenti e fare una valutazione più informata dei loro punti di forza e limitazioni.
Cosa c’è di nuovo in SDXL?
Ora che abbiamo compreso i fondamenti dei modelli SD, approfondiamo il paper SDXL per scoprire i cambiamenti trasformativi introdotti in questo nuovo modello. In sintesi, SDXL presenta i seguenti miglioramenti:
- Aumento del numero di parametri U-Net: SDXL potenzia la capacità del modello incorporando un maggior numero di parametri U-Net, consentendo una generazione di immagini più sofisticata.
- Distribuzione eterogenea dei blocchi Transformer: Abbandonando la distribuzione uniforme dei blocchi Transformer nei modelli precedenti ([1,1,1,1]), SDXL adotta una distribuzione eterogenea ([0,2,4]), introducendo capacità di apprendimento ottimizzate e migliorate.
- Miglioramento dell’encoder di condizionamento del testo: SDXL sfrutta un encoder di condizionamento del testo più grande, OpenCLIP ViT-bigG, per incorporare efficacemente informazioni testuali nel processo di generazione di immagini.
- Encoder di testo aggiuntivo: Il modello utilizza un encoder di testo aggiuntivo, CLIP ViT-L, che concatena il suo output, arricchendo il processo di condizionamento con caratteristiche testuali complementari.
- Introduzione di “Condizionamento delle dimensioni”: Un nuovo condizionatore chiamato “Condizionamento delle dimensioni” prende in input la larghezza e l’altezza dell’immagine di addestramento originale come input condizionale, consentendo al modello di adattare la generazione di immagini in base a indizi legati alle dimensioni.
- Parametro “Condizionamento del ritaglio”: SDXL introduce il parametro “Condizionamento del ritaglio”, incorporando le coordinate di ritaglio dell’immagine come input condizionale.
- Parametro “Condizionamento multi-aspetto”: Incorporando la dimensione del bucket per il condizionamento, il parametro “Condizionamento multi-aspetto” consente a SDXL di adattarsi a vari rapporti di aspetto.
- Modello raffinatore specializzato: SDXL introduce un secondo modello SD, specializzato nella gestione di dati ad alta qualità e ad alta risoluzione, catturando efficacemente dettagli locali complessi.
Ora, diamo un’occhiata più da vicino a come alcune di queste aggiunte si confrontano con i modelli di diffusione stabili precedenti.
Confronto ufficiale di Stability.ai:
Iniziamo esaminando il confronto ufficiale di Stability.ai, come presentato dagli autori. Questo confronto offre preziose informazioni sulle preferenze degli utenti tra SDXL e Stable Diffusion. Tuttavia, dobbiamo approcciare i risultati con cautela…
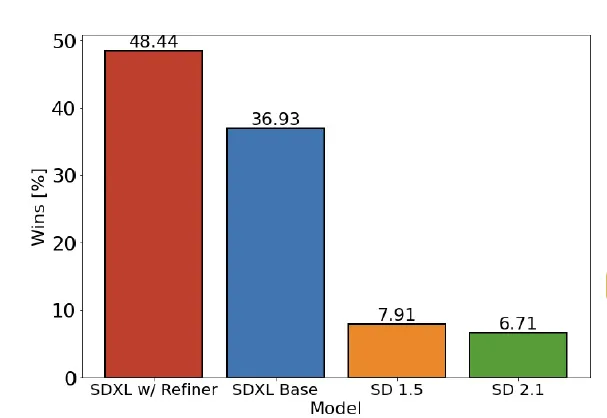
Questo studio dimostra che i partecipanti hanno scelto i modelli SDXL rispetto ai modelli SD 1.5 e 2.1 precedenti. In particolare, il modello SDXL con l’aggiunta del Refiner ha raggiunto un tasso di vincita del 48,44%. È importante notare che, sebbene questo risultato sia statisticamente significativo, dobbiamo anche tenere conto dei pregiudizi introdotti dall’elemento umano e della casualità intrinseca dei modelli generativi.
Prestazioni rispetto ai modelli Black-Box di ultima generazione:
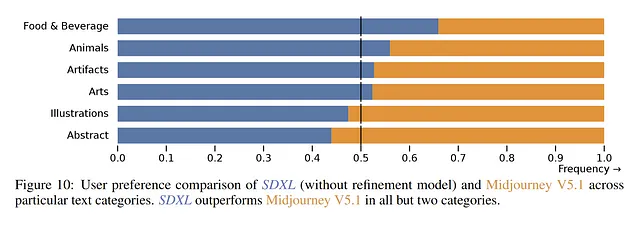
Attualmente, Midjourney è molto popolare tra gli utenti, alcuni lo considerano attualmente una soluzione all’avanguardia. Secondo il sondaggio ufficiale, SDXL presenta un tasso di preferenza più elevato in categorie come “Cibo e Bevande” e “Animali”. Tuttavia, in altre categorie come “Illustrazioni” e “Astratto”, gli utenti preferiscono ancora Midjourney V5.1.
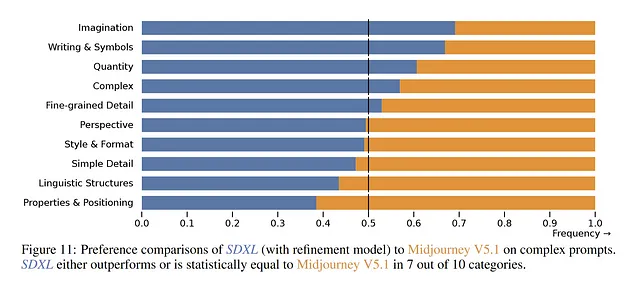
Ancora una volta, osserviamo un modello simile nel caso di prompt complessi. Il paper afferma che sono preferiti in 7 su 10 argomenti complessi. Tuttavia, senza conoscere i prompt specifici utilizzati, diventa difficile trarre una conclusione. Inoltre, la mancanza di informazioni riguardo all’encoder di prompt in Midjourney complica ulteriormente le cose e solo il tempo rivelerà le vere preferenze.
Numero dei parametri di U-Net
Come accennato in precedenza, i modelli U-Net svolgono un ruolo vitale nella Diffusione Stabile, facilitando la ricostruzione delle immagini dalla rumore dato. In SDXL, gli autori hanno apportato un miglioramento significativo incorporando un modello U-Net considerevolmente più grande rispetto alle versioni precedenti di SD, con un totale di 2,6 miliardi di parametri di U-Net rispetto a ~860 milioni per i suoi predecessori.
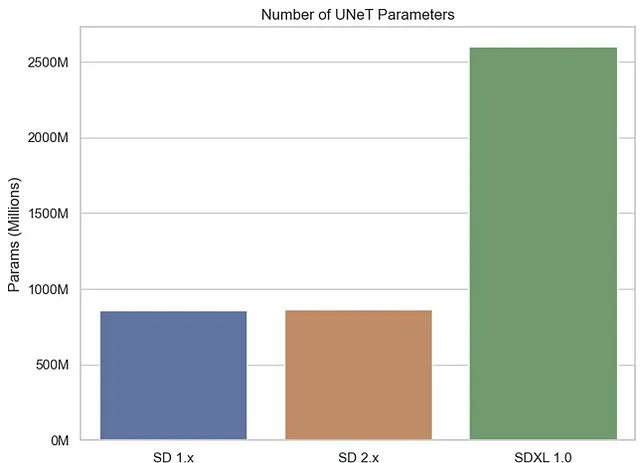
Anche se avere più parametri può sembrare promettente inizialmente, è essenziale considerare il compromesso tra complessità e qualità. Con l’aumentare del numero di parametri, aumentano anche i requisiti di sistema sia per l’addestramento che per la generazione. Sebbene sia ancora prematuro arrivare a conclusioni definitive sulla qualità del prodotto, il compromesso tra complessità e qualità è già evidente.
Numero dei parametri di Text Encoder
Effettivamente, osservando il numero totale di parametri dell’encoder di testo, osserviamo un aumento significativo in SDXL 1.0 rispetto ai suoi predecessori. L’introduzione di due conditioner di testo in SDXL, invece di uno singolo nelle versioni precedenti, contribuisce a questa crescita significativa nel conteggio dei parametri dell’encoder di testo. Questa espansione permette a SDXL di sfruttare un maggior volume di informazioni testuali.
SDXL utilizza l’encoder di testo OpenCLIP G/14 con 694,7 milioni di parametri, rispetto a CLIP L/14 con 123,65 milioni di parametri, per un totale di oltre 800 milioni di parametri. Questo rappresenta un salto sostanziale rispetto ai suoi predecessori.
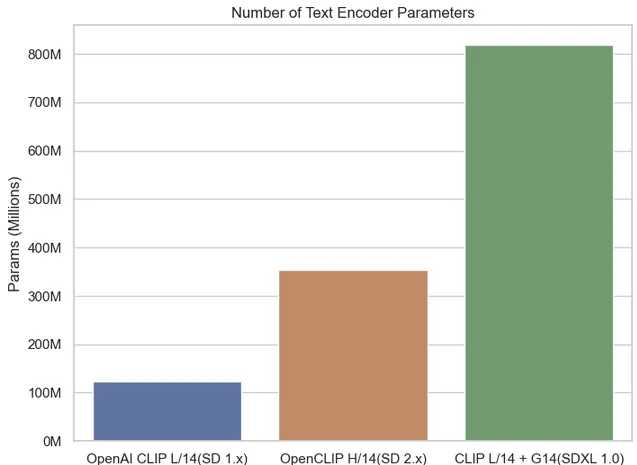
Una volta di più, impiegare codificatori di testo più grandi e multipli può sembrare allettante inizialmente, ma introduce una complessità aggiuntiva che potrebbe rivelarsi dannosa. Considera uno scenario in cui stai addestrando un modello SDXL con i tuoi dati. In tali casi, determinare i parametri ottimali diventa più sfidante rispetto ai modelli SD precedenti perché trovare il “punto dolce” degli iperparametri per entrambi i codificatori diventa più difficile da raggiungere.
Il flusso di lavoro
In effetti, il termine “XL” in SDXL indica la sua scala espansa e la maggiore complessità rispetto ai modelli SD precedenti. SDXL supera i suoi predecessori in vari aspetti, vantando un maggior numero di parametri, inclusi due codificatori di testo e due modelli U-Net – il modello base e il refiner, che funziona essenzialmente come un modello immagine-immagine. Naturalmente, questa maggiore complessità delle pipeline SDXL:
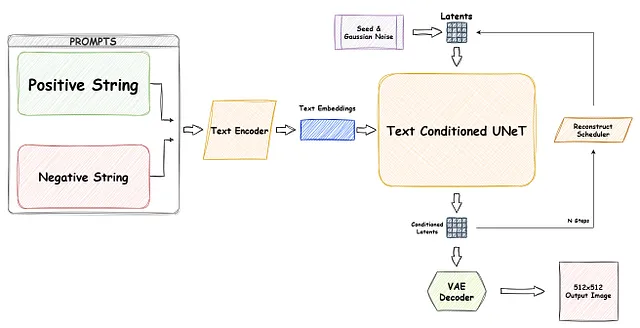
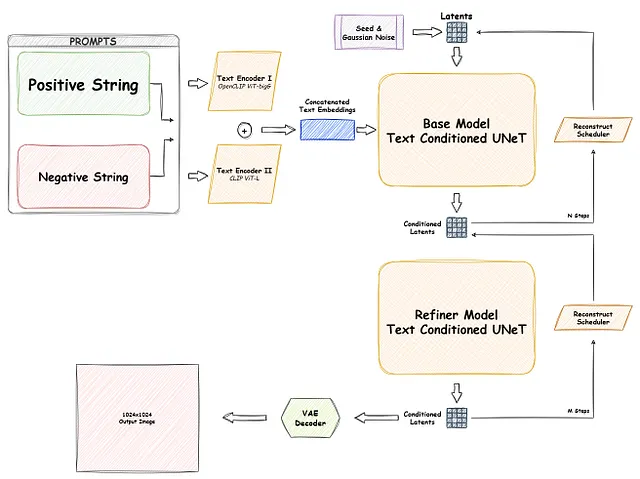
SDXL in pratica
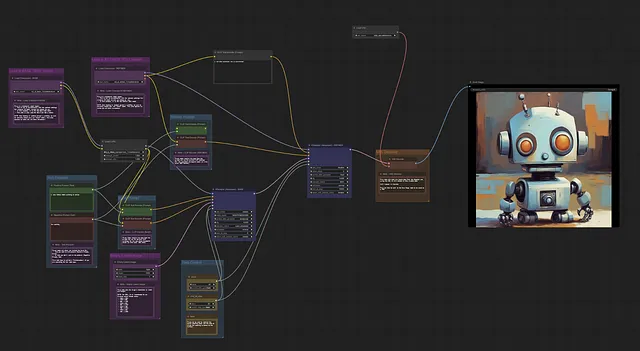
I pesi del modello di SDXL sono stati rilasciati ufficialmente e sono liberamente accessibili per l’uso come script Python, grazie alla libreria diffusers di Hugging Face. Inoltre, è disponibile una opzione GUI user-friendly chiamata ComfyUI. Questa GUI fornisce un’interfaccia basata su nodi altamente personalizzabile, che consente agli utenti di posizionare intuitivamente i blocchi di costruzione del modello di diffusione testo-immagine stabile e di connetterli visivamente.
Con questa implementazione pronta all’uso, gli utenti possono integrare senza soluzione di continuità SDXL nei loro progetti, consentendo loro di sfruttare la potenza di questo innovativo modello di diffusione testo-immagine latente.
Esempio di base dell’utilizzo di diffusers
Stato attuale di SDXL ed esperienze personali
Sebbene le nuove funzionalità e aggiunte in SDXL sembrino promettenti, alcuni modelli SD 1.5 sintonizzati offrono ancora risultati migliori. Questo risultato è attribuito principalmente al grande supporto della comunità in crescita – un vantaggio che deriva dall’approccio open-source.
Nella sua fase iniziale, SDXL mostra miglioramenti rispetto a 1.5 e sono fiducioso che, con il continuo supporto della comunità, le sue prestazioni diventeranno sempre più forti in futuro. Tuttavia, è essenziale riconoscere che all’aumentare della complessità dei modelli, l’utilizzo e l’addestramento richiedono risorse maggiori dal punto di vista computazionale. Ma non c’è ancora motivo di preoccupazione…
LoRAs (Decomposizioni adattive localmente rankevoli) ha guadagnato popolarità per il fine-tuning di Large Language Models. Questo approccio prevede l’aggiunta di coppie di matrici di pesi di decomposizione di rango ai pesi esistenti e l’addestramento solo di questi pesi appena aggiunti. Di conseguenza, l’addestramento diventa più rapido ed efficiente dal punto di vista computazionale. L’incorporazione di LoRA è destinata a spianare la strada alla comunità per creare versioni personalizzate ancora migliori in futuro. È importante sottolineare che SDXL supporta già pienamente LoRA.
Nonostante gli sviluppi positivi, è importante notare che SDXL continua ad avere alcune delle usuali limitazioni della Stable Diffusion, come ufficialmente riconosciuto dagli autori:
- Il modello non raggiunge la fotorealismo perfetto
- Il modello non può renderizzare testo leggibile
- Il modello fatica con compiti più difficili che implicano la composizione, come la creazione di un’immagine corrispondente a “Un cubo rosso sopra una sfera blu”
- Volte e persone in generale potrebbero non essere generate correttamente.
- La parte di autoencoding del modello è lossy.
Osservazioni personali
Personalmente, mentre sperimento con il modello SDXL, trovo ancora preferibili alcuni checkpoint della comunità del modello SD 1.5 in alcuni casi. Con mesi di supporto della comunità, è relativamente facile trovare il modello sintonizzato corretto che si adatta alle esigenze specifiche, come il fotorealismo o stili più cartoonish. Tuttavia, al momento è difficile trovare modelli sintonizzati specifici per SDXL a causa dei requisiti elevati di potenza di calcolo. Tuttavia, il modello di base di SDXL sembra performare meglio rispetto ai modelli di base di SD 1.5 o 2.1 in termini di qualità e risoluzione delle immagini e con ulteriori ottimizzazioni e tempo, questo potrebbe cambiare nel prossimo futuro.
Vale la pena notare che con l’aumento delle dimensioni del modello, alcuni utenti hanno segnalato difficoltà nell’eseguire il modello sui loro laptop o PC quotidiani, il che è spiacevole. Sono fiducioso che le tecniche di quantizzazione comunemente utilizzate nei Large Language Models possano trovare il loro posto anche in questo campo.
Inoltre, con il cambiamento degli encoder di testo, le mie solite indicazioni non producono più risultati soddisfacenti su SDXL. Sebbene gli sviluppatori di SDXL sostengano che l’uso di indicazioni sia più facile con SDXL, devo ancora trovare l’approccio corretto. Potrebbe richiedere del tempo adattarsi al nuovo stile di indicazione, specialmente per coloro che provengono dalle versioni precedenti.
Conclusioni
Nel nostro articolo, abbiamo scoperto le capacità di Stable Diffusion XL, un modello con la capacità di trasformare descrizioni di testo semplice in rappresentazioni visive intricate. Abbiamo scoperto che la natura open-source di SDXL e il suo approccio per affrontare le preoccupazioni legate ai modelli black-box hanno contribuito al suo ampio appeal, consentendogli di raggiungere un pubblico più ampio.
Con il suo aumento del numero di parametri e delle funzionalità extra, SDXL si è dimostrato un modello “XL”, vantando una complessità maggiore rispetto ai suoi predecessori.
L’implementazione di SDXL nella pratica è stata resa più semplice con il rilascio ufficiale dei suoi pesi del modello, liberamente disponibili come script Python da huggingface, insieme all’opzione user-friendly ComfyUI GUI.
Sebbene SDXL mostri grandi promesse, il percorso verso la perfezione è ancora in corso. Alcuni modelli SD 1.5 finemente tarati continuano a superare SDXL in determinati scenari, grazie al supporto della vivace comunità. Tuttavia, con un impegno e un supporto attivi, posso vedere che SDXL continuerà a evolversi e migliorarsi nel tempo.
Tuttavia, è importante riconoscere che, come i suoi predecessori, SDXL ha alcune limitazioni. Raggiungere la fotorealismo perfetta, la resa di testo leggibile, l’affrontare sfide di composizione e generare volti e persone accuratamente sono tra le aree in cui il modello deve essere migliorato.
In conclusione, SDXL 1.0 rappresenta un significativo passo avanti nella generazione di testo in immagini, liberando il potenziale creativo dell’IA e spingendo i confini di ciò che è possibile. Mentre la comunità dell’IA continua a collaborare e innovare, possiamo aspettarci sviluppi ancora più sorprendenti nel affascinante mondo dei modelli SD e oltre.
Riferimenti:
- Denoising Diffusion Probabilistic Models — Jonathan Ho, Ajay Jain, Pieter Abbeel, 2020
- High-Resolution Image Synthesis with Latent Diffusion Models — Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer, 2021
- SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis — Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, Robin Rombach, 2023






