Verso modelli di linguaggio criptati su larga scala con FHE
FHE for large-scale encrypted language models
I grandi modelli di linguaggio (LLM) sono stati recentemente dimostrati come strumenti affidabili per migliorare la produttività in molte aree come la programmazione, la creazione di contenuti, l’analisi del testo, la ricerca web e l’apprendimento a distanza.
L’impatto dei grandi modelli di linguaggio sulla privacy degli utenti
Nonostante l’attrattiva dei LLM, persistono preoccupazioni sulla privacy riguardo alle query degli utenti che vengono elaborate da questi modelli. Da un lato, sfruttare la potenza dei LLM è desiderabile, ma dall’altro c’è il rischio di divulgare informazioni sensibili al fornitore del servizio LLM. In alcune aree, come la sanità, le finanze o il diritto, questo rischio di privacy è un fattore che blocca.
Una possibile soluzione a questo problema è la distribuzione in loco, in cui il proprietario del LLM distribuirebbe il suo modello sulla macchina del cliente. Tuttavia, questa non è una soluzione ottimale, poiché la costruzione di un LLM può costare milioni di dollari (4,6M$ per GPT3) e la distribuzione in loco comporta il rischio di divulgare la proprietà intellettuale del modello (IP).
Zama crede che sia possibile ottenere il meglio dei due mondi: la nostra ambizione è proteggere sia la privacy dell’utente che la proprietà intellettuale del modello. In questo blog, vedrai come sfruttare la libreria transformers di Hugging Face e far eseguire parti di questi modelli su dati crittografati. Il codice completo può essere trovato in questo esempio di caso d’uso.
- Huggy Lingo Utilizzare l’Apprendimento Automatico per Migliorare i Metadati del Linguaggio sul Hugging Face Hub
- Utilizzo dei valori SHAP per l’interpretabilità dei modelli nel Machine Learning
- 50 suggerimenti di ChatGPT per far crescere la tua azienda
La crittografia completamente omomorfica (FHE) può risolvere le sfide di privacy dei LLM
La soluzione di Zama alle sfide della distribuzione dei LLM consiste nell’utilizzare la crittografia completamente omomorfica (FHE), che consente l’esecuzione di funzioni su dati crittografati. È possibile raggiungere l’obiettivo di proteggere la proprietà intellettuale del proprietario del modello pur mantenendo la privacy dei dati dell’utente. Questa dimostrazione mostra che un modello LLM implementato in FHE mantiene la qualità delle previsioni del modello originale. Per fare ciò, è necessario adattare l’implementazione di GPT2 della libreria transformers di Hugging Face, rielaborando sezioni dell’inferenza usando Concrete-Python, che consente la conversione di funzioni Python in equivalenti FHE.
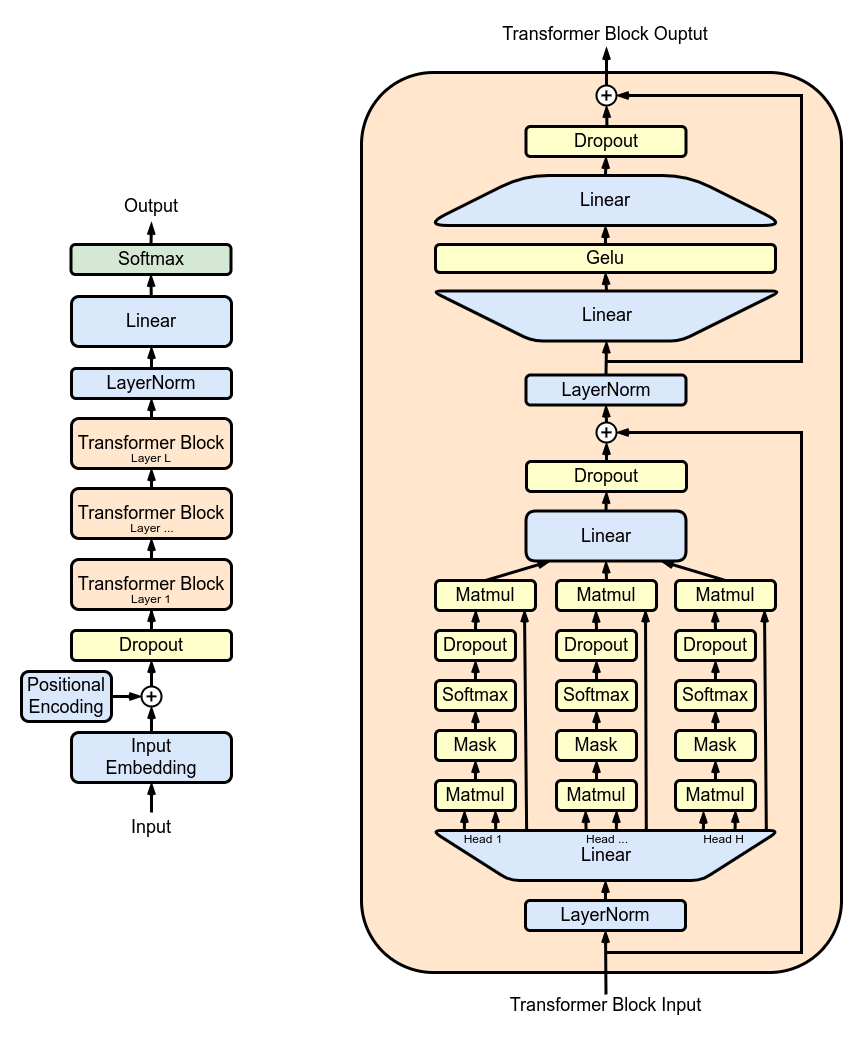
La figura 1 mostra l’architettura di GPT2 che ha una struttura ripetitiva: una serie di strati di attenzione a più teste (MHA) applicati successivamente. Ogni strato MHA proietta gli input utilizzando i pesi del modello, calcola il meccanismo di attenzione e riproietta l’output dell’attenzione in un nuovo tensore.
In TFHE, i pesi del modello e le attivazioni sono rappresentati con numeri interi. Le funzioni non lineari devono essere implementate con un’operazione di bootstrapping programmabile (PBS). PBS implementa un’operazione di ricerca nella tabella (TLU) su dati crittografati, consentendo anche il rinfresco dei testi crittografati per consentire calcoli arbitrari. Tuttavia, il tempo di calcolo di PBS domina quello delle operazioni lineari. Sfruttando questi due tipi di operazioni, è possibile esprimere ogni sottoparte o addirittura l’intero calcolo LLM in FHE.
Implementazione di uno strato LLM con FHE
Successivamente, vedrai come crittografare una singola testa di attenzione del blocco di attenzione a più teste (MHA). Puoi trovare un esempio anche per l’intero blocco MHA in questo esempio di caso d’uso.

La figura 2 mostra una panoramica semplificata dell’implementazione sottostante. Un client avvia l’inferenza in locale fino al primo strato che è stato rimosso dal modello condiviso. L’utente crittografa le operazioni intermedie e le invia al server. Il server applica parte del meccanismo di attenzione e i risultati vengono quindi restituiti al client che può decifrarli e continuare l’inferenza locale.
Quantizzazione
Prima di eseguire l’inferenza del modello su valori crittografati, i pesi e le attivazioni del modello devono essere quantizzati e convertiti in numeri interi. L’ideale è utilizzare la quantizzazione post-training che non richiede il riaddestramento del modello. Il processo consiste nell’implementare un meccanismo di attenzione compatibile con FHE, utilizzare numeri interi e PBS, e quindi valutare l’impatto sull’accuratezza del LLM.
Per valutare l’impatto della quantizzazione, esegui il modello completo di GPT2 con una singola testa LLM che opera su dati crittografati. Quindi, valuta l’accuratezza ottenuta variando il numero di bit di quantizzazione sia per i pesi che per le attivazioni.
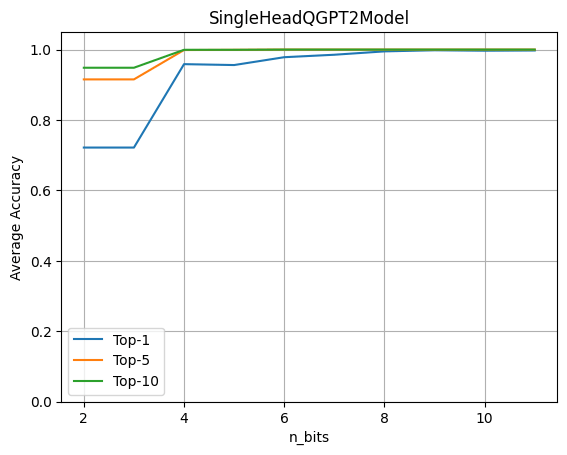
Questo grafico mostra che la quantizzazione a 4 bit mantiene il 96% dell’accuratezza originale. L’esperimento è stato effettuato utilizzando un set di dati di circa 80 frasi. Le metriche sono calcolate confrontando le previsioni dei logit del modello originale con il modello con la testa quantizzata.
Applicazione di FHE al modello Hugging Face GPT2
Sfruttando la libreria transformers di Hugging Face, riscrivere il passaggio in avanti dei moduli che si desidera criptare, al fine di includere gli operatori quantizzati. Creare un’istanza di SingleHeadQGPT2Model caricando prima un GPT2LMHeadModel e quindi sostituire manualmente il primo modulo di attenzione multi-head come segue utilizzando un modulo QGPT2SingleHeadAttention. L’implementazione completa può essere trovata qui.
self.transformer.h[0].attn = QGPT2SingleHeadAttention(config, n_bits=n_bits)Il passaggio in avanti viene quindi sovrascritto in modo che la prima testa del meccanismo di attenzione multi-head, inclusa la proiezione effettuata per la creazione delle matrici di query, chiavi e valori, venga eseguita con operatori compatibili con FHE. Il seguente modulo QGPT2 può essere trovato qui.
class SingleHeadAttention(QGPT2):
"""Classe che rappresenta una singola attenzione implementata con metodi di quantizzazione."""
def run_numpy(self, q_hidden_states: np.ndarray):
# Converti l'input in un'istanza di DualArray
q_x = DualArray(
float_array=self.x_calib,
int_array=q_hidden_states,
quantizer=self.quantizer
)
# Estrarre il nome del modulo di base di attenzione
mha_weights_name = f"transformer.h.{self.layer}.attn."
# Estrarre i pesi e i bias di query, chiavi e valori utilizzando gli indici corretti
head_0_indices = [
list(range(i * self.n_embd, i * self.n_embd + self.head_dim))
for i in range(3)
]
q_qkv_weights = ...
q_qkv_bias = ...
# Applica la prima proiezione per estrarre Q, K e V come un singolo array
q_qkv = q_x.linear(
weight=q_qkv_weights,
bias=q_qkv_bias,
key=f"attention_qkv_proj_layer_{self.layer}",
)
# Estrarre le query, chiavi e valori
q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}")
q_q, q_k, q_v = q_qkv.enc_split(
3,
axis=-1,
key=f"qkv_split_layer_{self.layer}"
)
# Calcola il meccanismo di attenzione
q_y = self.attention(q_q, q_k, q_v)
return self.finalize(q_y)Altre computazioni nel modello rimangono in virgola mobile, non criptate e ci si aspetta che vengano eseguite dal client in locale.
Caricando i pesi pre-addestrati nel modello GPT2 modificato in questo modo, è possibile chiamare il metodo generate:
qgpt2_model = SingleHeadQGPT2Model.from_pretrained(
"gpt2_model", n_bits=4, use_cache=False
)
output_ids = qgpt2_model.generate(input_ids)Come esempio, è possibile chiedere al modello quantizzato di completare la frase “La crittografia è un”. Con una precisione di quantizzazione sufficiente durante l’esecuzione del modello in FHE, l’output della generazione è:
“La crittografia è una parte molto importante della sicurezza del tuo computer”
Quando la precisione di quantizzazione è troppo bassa, otterrai:
“La crittografia è un ottimo modo per imparare sul mondo che ti circonda”
Compilazione in FHE
Ora è possibile compilare la testa di attenzione utilizzando il seguente codice Concrete-ML:
circuit_head = qgpt2_model.compile(input_ids)Eseguendo questo, vedrai il seguente output: “Circuito compilato con larghezza di 8 bit”. Questa configurazione, compatibile con FHE, mostra la larghezza di bit massima necessaria per eseguire operazioni in FHE.
Complessità
Nelle modelli di trasformatori, l’operazione più intensiva dal punto di vista computazionale è il meccanismo di attenzione che moltiplica le query, le chiavi e i valori. In FHE, il costo è aggravato dalla specificità delle moltiplicazioni nel dominio criptato. Inoltre, all’aumentare della lunghezza della sequenza, il numero di queste moltiplicazioni complesse aumenta in modo quadratico.
Per la testa criptata, una sequenza di lunghezza 6 richiede 11.622 operazioni PBS. Questo è un primo esperimento che non è stato ottimizzato per le prestazioni. Sebbene possa essere eseguito in pochi secondi, richiederebbe molta potenza di calcolo. Fortunatamente, l’hardware migliorerà la latenza di 1000x a 10000x, facendo passare le cose da diversi minuti su CPU a < 100ms su ASIC una volta che saranno disponibili tra qualche anno. Per ulteriori informazioni su queste proiezioni, consulta questo post del blog.
Conclusioni
I grandi modelli di linguaggio sono ottimi strumenti di assistenza in una vasta gamma di casi d’uso, ma la loro implementazione solleva importanti questioni sulla privacy dell’utente. In questo blog, hai visto un primo passo verso il lavoro dell’intero LLM su dati criptati, dove il modello funzionerebbe interamente nel cloud, mentre la privacy degli utenti sarebbe completamente rispettata.
Questo passaggio include la conversione di una parte specifica di un modello come GPT2 nel realm FHE. Questa implementazione sfrutta la libreria transformers e ti permette di valutare l’impatto sull’accuratezza quando una parte del modello viene eseguita su dati criptati. Oltre a preservare la privacy dell’utente, questo approccio consente anche al proprietario del modello di mantenere una parte significativa del proprio modello privata. Il codice completo può essere trovato in questo esempio di caso d’uso.
Le librerie Zama Concrete e Concrete-ML (Non dimenticare di mettere una stella ai repository su GitHub ⭐️💛) consentono la creazione semplice di modelli di ML e la conversione all’equivalente FHE per essere in grado di calcolare e prevedere su dati criptati.
Spero che tu abbia apprezzato questo post; sentiti libero di condividere i tuoi pensieri/feedback!






