Automatizza la creazione di didascalie e la ricerca di immagini su larga scala aziendale utilizzando l’IA generativa e Amazon Kendra
'Automate caption creation and large-scale image search for businesses using generative AI and Amazon Kendra.
Amazon Kendra è un servizio di ricerca intelligente alimentato dall’apprendimento automatico (ML). Amazon Kendra reinventa la ricerca per i tuoi siti web e le tue applicazioni in modo che i tuoi dipendenti e clienti possano trovare facilmente i contenuti che stanno cercando, anche quando sono dispersi in diverse posizioni e repository di contenuti all’interno della tua organizzazione.
Amazon Kendra supporta una varietà di formati di documento, come Microsoft Word, PDF e testo da diverse fonti di dati. In questo post, ci concentriamo sull’estensione del supporto dei documenti in Amazon Kendra per rendere le immagini ricercabili in base al loro contenuto visualizzato. Le immagini possono spesso essere cercate utilizzando metadati supplementari come parole chiave. Tuttavia, è necessario un grande sforzo manuale per aggiungere metadati dettagliati a potenzialmente migliaia di immagini. L’intelligenza artificiale generativa (GenAI) può essere utile per generare automaticamente i metadati. Generando didascalie testuali, le previsioni delle didascalie GenAI offrono metadati descrittivi per le immagini. L’indice Amazon Kendra può quindi essere arricchito con i metadati generati durante l’ingestione del documento per consentire la ricerca delle immagini senza alcuno sforzo manuale.
Ad esempio, un modello GenAI può essere utilizzato per generare una descrizione testuale per l’immagine seguente come “un cane sdraiato per terra sotto un ombrello” durante l’ingestione del documento dell’immagine.

- La distribuzione di SageMaker è ora disponibile su Amazon SageMaker Studio
- Crea un avatar personalizzato con l’uso dell’IA generativa utilizzando Amazon SageMaker
- Il Machine Learning e la tecnologia Blockchain potrebbero aiutare a contrastare la diffusione delle fake news
Un modello di riconoscimento degli oggetti può comunque rilevare parole chiave come “cane” e “ombrello”, ma un modello GenAI offre una comprensione più approfondita di ciò che è rappresentato nell’immagine identificando che il cane si trova sotto l’ombrello. Questo ci aiuta a costruire ricerche più raffinate nel processo di ricerca delle immagini. La descrizione testuale viene aggiunta come metadati a un indice di ricerca Amazon Kendra tramite un arricchimento automatico personalizzato del documento (CDE). Gli utenti che cercano termini come “cane” o “ombrello” saranno quindi in grado di trovare l’immagine, come mostrato nella seguente schermata.
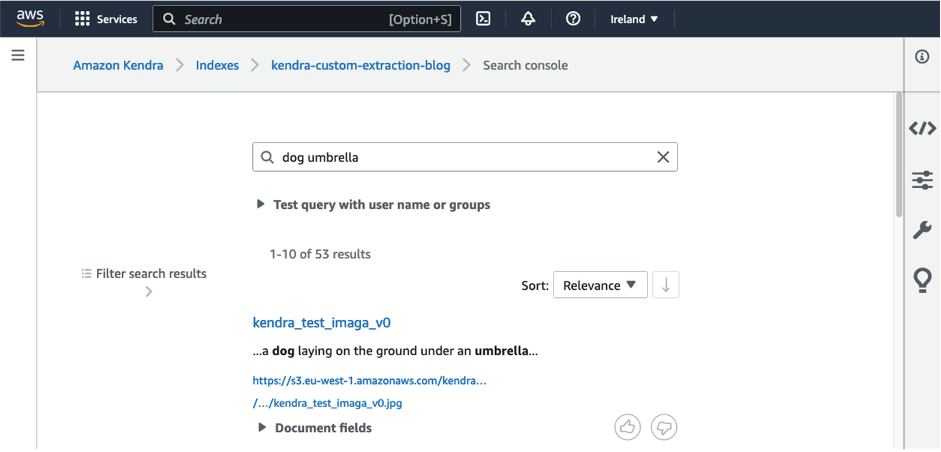
In questo post, mostriamo come utilizzare CDE in Amazon Kendra utilizzando un modello GenAI implementato su Amazon SageMaker. Dimostriamo CDE utilizzando esempi semplici e forniamo una guida passo passo per consentirti di sperimentare CDE in un indice Amazon Kendra nel tuo account AWS. Consente agli utenti di trovare rapidamente e facilmente le immagini di cui hanno bisogno senza doverle contrassegnare o categorizzare manualmente. Questa soluzione può anche essere personalizzata e scalata per soddisfare le esigenze di diverse applicazioni e settori.
Descrizione dell’immagine con GenAI
La descrizione dell’immagine con GenAI prevede l’utilizzo di algoritmi di apprendimento automatico per generare descrizioni testuali delle immagini. Il processo è anche noto come didascalia delle immagini e opera all’incrocio tra la visione artificiale e l’elaborazione del linguaggio naturale (NLP). Ha applicazioni in aree in cui i dati sono multimodali, come il commercio elettronico, in cui i dati contengono testo sotto forma di metadati e immagini, o nel settore sanitario, in cui i dati potrebbero contenere risonanze magnetiche o scansioni TC insieme alle note e alle diagnosi del medico, per citarne alcuni casi d’uso.
I modelli GenAI imparano a riconoscere oggetti e caratteristiche all’interno delle immagini, per poi generare descrizioni di quegli oggetti e caratteristiche in linguaggio naturale. I modelli all’avanguardia utilizzano un’architettura codificatore-decodificatore, in cui le informazioni sull’immagine vengono codificate nei livelli intermedi della rete neurale e decodificate in descrizioni testuali. Questi possono essere considerati come due fasi distinte: l’estrazione delle caratteristiche dalle immagini e la generazione delle didascalie testuali. Nella fase di estrazione delle caratteristiche (codificatore), il modello GenAI elabora l’immagine per estrarre caratteristiche visive rilevanti, come forme degli oggetti, colori e texture. Nella fase di generazione delle didascalie (decodificatore), il modello genera una descrizione in linguaggio naturale dell’immagine in base alle caratteristiche visive estratte.
I modelli GenAI vengono tipicamente addestrati su grandi quantità di dati, il che li rende adatti a varie attività senza ulteriore addestramento. L’adattamento a set di dati personalizzati e nuovi domini è anche facilmente realizzabile attraverso il learning few-shot. I metodi di pre-addestramento consentono di addestrare facilmente applicazioni multimodali utilizzando modelli di linguaggio e immagini all’avanguardia. Questi metodi di pre-addestramento consentono anche di combinare il modello di visione e il modello di linguaggio che si adattano meglio ai tuoi dati.
La qualità delle descrizioni delle immagini generate dipende dalla qualità e dimensione dei dati di addestramento, dall’architettura del modello GenAI e dalla qualità delle caratteristiche estratte e degli algoritmi di generazione delle didascalie. Sebbene la descrizione delle immagini con GenAI sia un campo di ricerca attivo, mostra risultati molto buoni in una vasta gamma di applicazioni, come la ricerca di immagini, la narrazione visiva e l’accessibilità per le persone con disabilità visive.
Casi d’uso
La descrizione delle immagini GenAI è utile nei seguenti casi d’uso:
- Ecommerce – Un caso d’uso comune nel settore in cui le immagini e il testo si trovano insieme è il commercio al dettaglio. In particolare, l’e-commerce memorizza grandi quantità di dati come immagini di prodotti insieme a descrizioni testuali. La descrizione testuale o i metadati sono importanti per assicurare che all’utente vengano mostrati i migliori prodotti in base alle ricerche. Inoltre, con la tendenza dei siti di e-commerce a ottenere dati da fornitori esterni, le descrizioni dei prodotti spesso sono incomplete, il che comporta molte ore di lavoro manuale e un’enorme quantità di lavoro per etichettare le informazioni corrette nelle colonne dei metadati. La descrizione delle immagini basata su GenAI è particolarmente utile per automatizzare questo processo laborioso. L’affinamento del modello su dati personalizzati di moda, come immagini di moda insieme a testi che descrivono le caratteristiche dei prodotti di moda, può essere utilizzato per generare metadati che migliorano l’esperienza di ricerca dell’utente.
- Marketing – Un altro caso d’uso della ricerca di immagini è la gestione delle risorse digitali. Le aziende di marketing memorizzano grandi quantità di dati digitali che devono essere centralizzati, facilmente ricercabili e scalabili grazie ai cataloghi dei dati. Un lago di dati centralizzato con cataloghi di dati informativi ridurrebbe gli sforzi di duplicazione e consentirebbe una condivisione più ampia di contenuti creativi e una maggiore coerenza tra i team. Per le piattaforme di progettazione grafica comunemente utilizzate per consentire la generazione di contenuti sui social media o presentazioni in ambienti aziendali, una ricerca più rapida potrebbe migliorare l’esperienza dell’utente rendendo disponibili i risultati di ricerca corretti per le immagini che gli utenti desiderano cercare e consentendo agli utenti di cercare utilizzando query di linguaggio naturale.
- Manifatturiero – Il settore manifatturiero memorizza molte immagini di dati come progetti architettonici di componenti, edifici, hardware e attrezzature. La possibilità di cercare attraverso tali dati consente ai team di prodotto di ricreare facilmente progetti da un punto di partenza già esistente ed elimina molte complicazioni di progettazione, accelerando così il processo di generazione del progetto.
- Assistenza sanitaria – I medici e i ricercatori medici possono catalogare e cercare attraverso risonanze magnetiche e tomografie computerizzate, campioni di campioni, immagini di malattie come eruzioni cutanee e deformità, insieme alle note dei medici, alle diagnosi e ai dettagli degli studi clinici.
- Metaverso o realtà aumentata – Pubblicizzare un prodotto significa creare una storia che gli utenti possono immaginare e a cui possono identificarsi. Con gli strumenti e le analisi alimentati dall’IA, è diventato più facile che mai costruire non solo una storia, ma storie personalizzate che soddisfino i gusti e le sensibilità uniche degli utenti finali. Qui entrano in gioco i modelli di traduzione immagine-testo. La narrazione visiva può aiutare a creare personaggi, adattarli a diversi stili e sottotitolarli. Può anche essere utilizzato per alimentare esperienze stimolanti nel metaverso o nella realtà aumentata e contenuti immersivi, compresi i videogiochi. La ricerca di immagini consente agli sviluppatori, ai progettisti e ai team di cercare i loro contenuti utilizzando query di linguaggio naturale, il che può mantenere la coerenza del contenuto tra i vari team.
- Accessibilità dei contenuti digitali per non vedenti e ipovedenti – Questo è principalmente reso possibile dalle tecnologie di supporto come i lettori di schermo, i sistemi Braille che consentono la lettura e la scrittura tattile e le tastiere speciali per la navigazione dei siti web e delle applicazioni su Internet. Tuttavia, le immagini devono essere presentate come contenuto testuale che può quindi essere comunicato come voce. La descrizione delle immagini utilizzando gli algoritmi GenAI è un elemento cruciale per la ridisegnazione di Internet e rendendolo più inclusivo, offrendo a tutti la possibilità di accedere, comprendere e interagire con i contenuti online.
Dettagli del modello e affinamento del modello per set di dati personalizzati
In questa soluzione, sfruttiamo il modello di descrizione delle immagini vit-gpt2 disponibile da Hugging Face, che è distribuito con licenza Apache 2.0 senza ulteriori affinamenti. Vit è un modello fondamentale per i dati delle immagini e GPT-2 è un modello fondamentale per il linguaggio. La combinazione multimodale dei due offre la capacità di descrivere le immagini. Hugging Face ospita modelli di descrizione delle immagini all’avanguardia, che possono essere implementati su AWS con pochi clic e offrono endpoint di inferenza facili da implementare. Sebbene possiamo utilizzare direttamente questo modello pre-addestrato, possiamo anche personalizzare il modello per adattarlo a set di dati specifici del dominio, a tipi di dati aggiuntivi come video o dati spaziali e a casi d’uso unici. Ci sono diversi modelli GenAI in cui alcuni modelli si comportano meglio con determinati set di dati, o il tuo team potrebbe già utilizzare modelli di visione e linguaggio. Questa soluzione offre la flessibilità di scegliere il miglior modello di visione e linguaggio come modello di descrizione delle immagini attraverso una semplice sostituzione del modello utilizzato.
Per la personalizzazione dei modelli per applicazioni industriali uniche, i modelli open source disponibili su AWS attraverso Hugging Face offrono diverse possibilità. Un modello pre-addestrato può essere testato per il set di dati unico o addestrato su campioni dei dati etichettati per affinarlo. Metodi di ricerca innovativi consentono anche di combinare efficientemente qualsiasi combinazione di modelli di visione e linguaggio e addestrarli sul tuo set di dati. Questo modello appena addestrato può quindi essere implementato in SageMaker per la descrizione delle immagini descritta in questa soluzione.
Un esempio di ricerca di immagini personalizzata è l’Enterprise Resource Planning (ERP). Nell’ERP, i dati delle immagini raccolti dalle diverse fasi della logistica o della gestione della catena di approvvigionamento potrebbero includere ricevute fiscali, ordini fornitori, buste paga e altro, che devono essere automaticamente categorizzati per l’uso da diverse squadre all’interno dell’organizzazione. Un altro esempio è utilizzare scansioni mediche e diagnosi mediche per prevedere nuove immagini mediche per la classificazione automatica. Il modello di visione estrae le caratteristiche dalle immagini MRI, CT o a raggi X e il modello di testo le descrive con le diagnosi mediche.
Panoramica della soluzione
Il diagramma seguente mostra l’architettura per la ricerca di immagini con GenAI e Amazon Kendra.
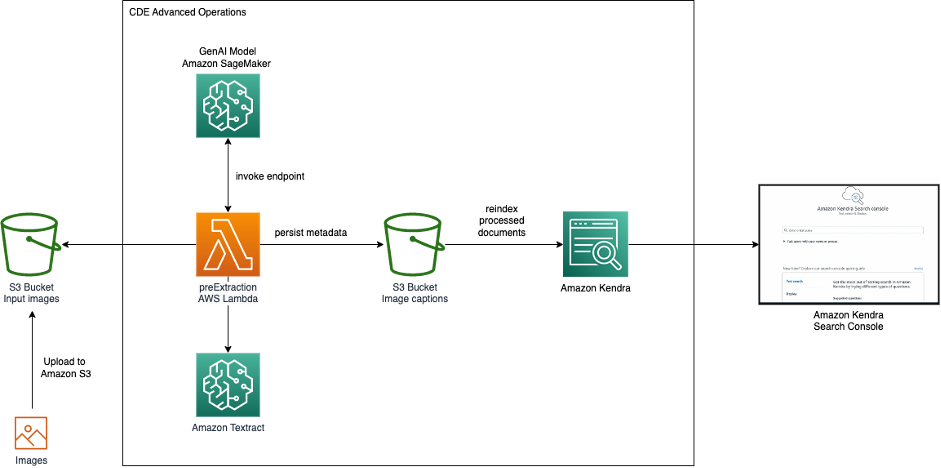
Inseriamo le immagini da Amazon Simple Storage Service (Amazon S3) in Amazon Kendra. Durante l’inserimento in Amazon Kendra, viene invocato il modello GenAI ospitato su SageMaker per generare una descrizione dell’immagine. Inoltre, il testo visibile in un’immagine viene estratto da Amazon Textract. La descrizione dell’immagine e il testo estratto vengono memorizzati come metadati e resi disponibili all’indice di ricerca di Amazon Kendra. Dopo l’inserimento, le immagini possono essere cercate tramite la console di ricerca di Amazon Kendra, l’API o l’SDK.
Utilizziamo le operazioni avanzate di CDE in Amazon Kendra per chiamare il modello GenAI e Amazon Textract durante la fase di inserimento delle immagini. Tuttavia, possiamo utilizzare CDE per una gamma più ampia di casi d’uso. Con CDE, è possibile creare, modificare o eliminare attributi e contenuti dei documenti durante l’inserimento dei documenti in Amazon Kendra. Ciò significa che è possibile manipolare e inserire i dati come richiesto. Ciò può essere realizzato invocando le funzioni AWS Lambda di pre- e post-estrazione durante l’inserimento, consentendo l’arricchimento o la modifica dei dati. Ad esempio, possiamo utilizzare Amazon Medical Comprehend durante l’inserimento dei dati testuali medici per aggiungere informazioni generate da ML ai metadati di ricerca.
Puoi utilizzare la nostra soluzione per cercare immagini tramite Amazon Kendra seguendo questi passaggi:
- Carica le immagini in un repository di immagini come un bucket S3.
- Il repository di immagini viene quindi indicizzato da Amazon Kendra, che è un motore di ricerca utilizzato per la ricerca di dati strutturati e non strutturati. Durante l’indicizzazione, vengono invocati il modello GenAI e Amazon Textract per generare i metadati dell’immagine. Puoi avviare l’indicizzazione manualmente o su un programma predefinito.
- Puoi quindi cercare immagini utilizzando query in linguaggio naturale, come “Trova immagini di rose rosse” o “Mostrami foto di cani che giocano nel parco”, tramite la console, l’SDK o l’API di Amazon Kendra. Queste query vengono elaborate da Amazon Kendra, che utilizza algoritmi di ML per comprendere il significato delle query e recuperare immagini rilevanti dal repository indicizzato.
- I risultati della ricerca ti vengono presentati, insieme alle rispettive descrizioni testuali, consentendoti di trovare rapidamente e facilmente le immagini che stai cercando.
Prerequisiti
Devi avere i seguenti prerequisiti:
- Un account AWS
- Permessi per fornire ed eseguire le seguenti servizi tramite AWS CloudFormation: Amazon S3, Amazon Kendra, Lambda e Amazon Textract.
Stima dei costi
Il costo di distribuzione di questa soluzione come prova di concetto è proiettato nella seguente tabella. Questo è il motivo per cui utilizziamo Amazon Kendra con l’edizione sviluppatore, che non è raccomandata per carichi di lavoro di produzione, ma fornisce un’opzione a basso costo per gli sviluppatori. Supponiamo che la funzionalità di ricerca di Amazon Kendra venga utilizzata per 20 giorni lavorativi per 3 ore al giorno e calcoliamo quindi i costi associati per 60 ore attive mensili.
| Servizio | Tempo Consumato | Stima dei Costi al Mese |
| Amazon S3 | Archiviazione di 10 GB con trasferimento dati | 2,30 USD |
| Amazon Kendra | Edizione sviluppatore con 60 ore/mese | 67,90 USD |
| Amazon Textract | Rilevamento del testo del documento al 100% su 10.000 immagini | 15,00 USD |
| Amazon SageMaker | Inferenza in tempo reale con ml.g4dn.xlarge per un modello distribuito su un endpoint per 3 ore ogni giorno per 20 giorni | 44,00 USD |
| . | . | 129,2 USD |
Deploya risorse con AWS CloudFormation
Lo stack di CloudFormation deploya le seguenti risorse:
- Una funzione Lambda che scarica il modello di sottotitoli delle immagini dall’Hugging Face hub e successivamente costruisce gli asset del modello
- Una funzione Lambda che popola il codice di inferenza e gli artefatti del modello zippati in un bucket S3 di destinazione
- Un bucket S3 per memorizzare gli artefatti del modello zippati e il codice di inferenza
- Un bucket S3 per memorizzare le immagini caricate e i documenti di Amazon Kendra
- Un indice di Amazon Kendra per cercare tra i sottotitoli delle immagini generate
- Un endpoint di inferenza in tempo reale di SageMaker per deployare il modello di sottotitoli delle immagini di Hugging Face
- Una funzione Lambda che viene attivata durante l’arricchimento dell’indice di Amazon Kendra su richiesta. Invoca Amazon Textract e un endpoint di inferenza in tempo reale di SageMaker.
Inoltre, AWS CloudFormation deploya tutti i ruoli e le politiche di Gestione dell’Identità e Accesso (IAM) necessari, una VPC insieme a subnet, un gruppo di sicurezza e un gateway internet in cui viene eseguita la funzione Lambda delle risorse personalizzate.
Completa i seguenti passaggi per fornire le tue risorse:
- Scegli Avvia stack per avviare il modello CloudFormation nella Regione
us-east-1: - Scegli Avanti.
- Nella pagina Specifica i dettagli dello stack, lascia l’URL del modello e l’URI S3 del file dei parametri ai valori predefiniti, quindi scegli Avanti.
- Continua a scegliere Avanti nelle pagine successive.
- Scegli Crea stack per deployare lo stack.
Monitora lo stato dello stack. Quando lo stato viene mostrato come CREATE_COMPLETE, il deploy è completo.
Inserisci e cerca immagini di esempio
Completa i seguenti passaggi per inserire e cercare le tue immagini:
- Sulla console di Amazon S3, crea una cartella chiamata
imagesnel bucket S3kendra-image-search-stack-imagecaptionsnella Regioneus-east-1. - Carica le seguenti immagini nella cartella
images.




- Vai alla console di Amazon Kendra nella Regione
us-east-1. - Nel riquadro di navigazione, scegli Indici, quindi scegli il tuo indice (
kendra-index). - Scegli Data sources, quindi scegli
generated_image_captions. - Scegli Sincronizza ora.
Attendi che la sincronizzazione sia completata prima di proseguire con i passaggi successivi.
- Nel riquadro di navigazione, scegli Indici, quindi scegli
kendra-index. - Vai alla console di ricerca.
- Prova le seguenti query individualmente o combinate: “cane”, “ombrello” e “newsletter”, e scopri quali immagini sono posizionate in alto da Amazon Kendra.
Sentiti libero di testare le tue query che si adattano alle immagini caricate.
Pulizia
Per deprovisionare tutte le risorse, completa i seguenti passaggi:
- Nella console di AWS CloudFormation, seleziona Stack nel riquadro di navigazione.
- Seleziona lo stack
kendra-genai-image-searche scegli Elimina.
Attendi che lo stato dello stack cambi in DELETE_COMPLETE.
Conclusione
In questo post abbiamo visto come Amazon Kendra e GenAI possono essere combinati per automatizzare la creazione di metadati significativi per le immagini. I modelli GenAI all’avanguardia sono estremamente utili per generare didascalie di testo che descrivono il contenuto di un’immagine. Ciò ha diverse applicazioni nell’industria, che vanno dal settore sanitario e delle scienze della vita, al settore del commercio al dettaglio e dell’e-commerce, alle piattaforme di asset digitali e ai media. La didascalia dell’immagine è anche fondamentale per costruire un mondo digitale più inclusivo e ridisegnare Internet, il metaverso e le tecnologie immersive per soddisfare le esigenze delle sezioni sociali con problemi di vista.
La ricerca delle immagini abilitata tramite didascalie consente di cercare facilmente i contenuti digitali senza sforzo manuale per queste applicazioni e rimuove gli sforzi duplicati. Il modello CloudFormation che abbiamo fornito semplifica la distribuzione di questa soluzione per abilitare la ricerca delle immagini utilizzando Amazon Kendra. Un’architettura semplice di immagini archiviate in Amazon S3 e GenAI per creare descrizioni testuali delle immagini può essere utilizzata con CDE in Amazon Kendra per alimentare questa soluzione.
Questa è solo una delle applicazioni di GenAI con Amazon Kendra. Per approfondire come costruire applicazioni GenAI con Amazon Kendra, consulta il documento “Costruisci rapidamente applicazioni Generative AI ad alta precisione sui dati aziendali utilizzando Amazon Kendra, LangChain e grandi modelli di linguaggio”. Per la costruzione e l’espansione delle applicazioni GenAI, ti consigliamo di dare un’occhiata ad Amazon Bedrock.





