Miglioramento delle pipeline RAG in Haystack Introduzione di DiversityRanker e LostInTheMiddleRanker
Miglioramento delle pipeline RAG in Haystack con DiversityRanker e LostInTheMiddleRanker.
Come gli ultimi rankers ottimizzano l’utilizzo della finestra di contesto LLM nelle pipeline di generazione con augmentazione del recupero (RAG)
Le recenti migliorie nel Natural Language Processing (NLP) e nell’Answering di Domande a Lunga Forma (LFQA) avrebbero, solo pochi anni fa, suonato come qualcosa proveniente dal campo della fantascienza. Chi avrebbe potuto pensare che oggi avremmo sistemi capaci di rispondere a domande complesse con la precisione di un esperto, sintetizzando queste risposte al volo da un vasto insieme di fonti? L’LFQA è un tipo di generazione con augmentazione del recupero (RAG) che recentemente ha fatto significativi progressi, sfruttando le migliori capacità di recupero e generazione dei Large Language Models (LLM).
Ma cosa succederebbe se potessimo raffinare ulteriormente questa configurazione? Cosa succederebbe se potessimo ottimizzare come RAG seleziona e utilizza le informazioni per migliorare le sue prestazioni? Questo articolo introduce due componenti innovative che mirano a migliorare RAG con esempi concreti tratti dall’LFQA, basandosi sulle ultime ricerche e sulla nostra esperienza: il DiversityRanker e il LostInTheMiddleRanker.
Consideriamo la finestra di contesto del LLM come un pasto gourmet, dove ogni paragrafo è un ingrediente unico e saporito. Proprio come un capolavoro culinario richiede ingredienti diversi e di alta qualità, l’LFQA richiede una finestra di contesto riempita da paragrafi di alta qualità, variati, rilevanti e non ripetitivi.
Nel complesso mondo dell’LFQA e del RAG, sfruttare al massimo la finestra di contesto del LLM è fondamentale. Qualsiasi spazio sprecato o contenuto ripetitivo limita la profondità e l’ampiezza delle risposte che possiamo estrarre e generare. È un delicato equilibrio organizzare in modo appropriato il contenuto della finestra di contesto. Questo articolo presenta nuovi approcci per padroneggiare questo equilibrio, che miglioreranno la capacità di RAG di fornire risposte precise e complete.
- Questa newsletter sull’IA è tutto ciò di cui hai bisogno #59
- Come l’IA sta aiutando le compagnie aeree a mitigare l’impatto climatico dei contrails
- Distribuisci migliaia di insiemi di modelli con i punti finali multi-modello di Amazon SageMaker su GPU per ridurre al minimo i costi di hosting
Esploriamo questi entusiasmanti progressi e come migliorano LFQA e RAG.
Background
Haystack è un framework open-source che fornisce soluzioni complete per i costruttori di NLP pratico. Supporta una vasta gamma di casi d’uso, dall’answer di domande e dalla ricerca semantica dei documenti fino agli agenti LLM. Il suo design modulare consente l’integrazione dei modelli NLP all’avanguardia, dei repository di documenti e di vari altri componenti necessari nell’attuale toolbox NLP.
Uno dei concetti chiave in Haystack è l’idea di una pipeline. Una pipeline rappresenta una sequenza di passaggi di elaborazione che un componente specifico esegue. Questi componenti possono eseguire vari tipi di elaborazione del testo, consentendo agli utenti di creare facilmente sistemi potenti e personalizzabili definendo come i dati fluiscano attraverso la pipeline e l’ordine dei nodi che eseguono i loro passaggi di elaborazione.
La pipeline svolge un ruolo cruciale nell’answer di domande a lunga forma basata sul web. Inizia con un componente WebRetriever, che cerca e recupera documenti rilevanti per la query dal web, rimuovendo automaticamente il contenuto HTML in testo grezzo. Ma una volta che otteniamo documenti rilevanti per la query, come ne facciamo il miglior uso? Come riempiamo la finestra di contesto del LLM per massimizzare la qualità delle risposte? E se questi documenti, sebbene altamente rilevanti, fossero ripetitivi e numerosi, talvolta superando la finestra di contesto del LLM?
È qui che entrano in gioco i componenti che presenteremo oggi: il DiversityRanker e il LostInTheMiddleRanker. Il loro obiettivo è quello di affrontare queste sfide e migliorare le risposte generate dalle pipeline LFQA/RAG.
Il DiversityRanker migliora la diversità dei paragrafi selezionati per la finestra di contesto. Il LostInTheMiddleRanker, posizionato di solito dopo il DiversityRanker nella pipeline, aiuta a mitigare il degrado delle prestazioni del LLM osservato quando i modelli devono accedere a informazioni rilevanti nel bel mezzo di una lunga finestra di contesto. Le sezioni seguenti approfondiranno queste due componenti e ne dimostreranno l’efficacia in un caso d’uso pratico.
DiversityRanker
Il DiversityRanker è una nuova componente progettata per migliorare la diversità dei paragrafi selezionati per la finestra di contesto nella pipeline RAG. Si basa sul principio che un insieme variegato di documenti può aumentare la capacità del LLM di generare risposte con maggiore ampiezza e profondità.
Il DiversityRanker utilizza sentence transformers per calcolare la similarità tra documenti. La libreria sentence transformers offre modelli di embedding potenti per creare rappresentazioni significative di frasi, paragrafi e persino interi documenti. Queste rappresentazioni, o embedding, catturano il contenuto semantico del testo, consentendoci di misurare quanto due pezzi di testo siano simili.
DiversityRanker elabora i documenti utilizzando l’algoritmo seguente:
1. Inizia calcolando gli embedding per ciascun documento e la query utilizzando un modello di sentence-transformer.
2. Seleziona quindi il documento semanticamente più vicino alla query come primo documento selezionato.
3. Per ciascun documento rimanente, calcola la similarità media con i documenti già selezionati.
4. Seleziona quindi il documento che è, in media, meno simile ai documenti già selezionati.
5. Questo processo di selezione continua finché tutti i documenti vengono selezionati, ottenendo così una lista di documenti ordinati dal documento che contribuisce di più alla diversità complessiva al documento che contribuisce di meno.
Una nota tecnica da tenere presente: il DiversityRanker utilizza un approccio locale avido per selezionare il documento successivo in ordine, il che potrebbe non trovare l’ordine complessivo più ottimale per i documenti. DiversityRanker si concentra sulla diversità più che sulla rilevanza, quindi dovrebbe essere posizionato nel flusso di lavoro dopo un altro componente come TopPSampler o un altro ranker di similarità che si concentra maggiormente sulla rilevanza. Utilizzandolo dopo un componente che seleziona i documenti più rilevanti, ci assicuriamo di selezionare documenti diversi da un insieme di documenti già rilevanti.
LostInTheMiddleRanker
Il LostInTheMiddleRanker ottimizza la disposizione dei documenti selezionati nella finestra di contesto dell’LLM. Questo componente è un modo per ovviare a un problema identificato in recenti ricerche [1] che suggerisce che gli LLM faticano a concentrarsi su passaggi rilevanti nel mezzo di un contesto lungo. Il LostInTheMiddleRanker alterna il posizionamento dei migliori documenti all’inizio e alla fine della finestra di contesto, facilitando al meccanismo di attenzione dell’LLM l’accesso e l’utilizzo di essi. Per capire come LostInTheMiddleRanker ordina i documenti dati, immagina un esempio semplice in cui i documenti consistono in una singola cifra da 1 a 10 in ordine crescente. LostInTheMiddleRanker ordinerà questi dieci documenti nell’ordine seguente: [1 3 5 7 9 10 8 6 4 2].
Anche se gli autori di questa ricerca si sono concentrati su un compito di risposta a domande, cioè estrarre dagli testi i passaggi rilevanti per la risposta, speculiamo che il meccanismo di attenzione dell’LLM avrà anche più facilità a concentrarsi sui paragrafi all’inizio e alla fine della finestra di contesto durante la generazione delle risposte.
LostInTheMiddleRanker è meglio posizionato come l’ultimo ranker nel flusso di lavoro RAG poiché i documenti dati sono già selezionati in base alla similarità (rilevanza) e ordinati per diversità.
Utilizzo dei nuovi ranker in flussi di lavoro
In questa sezione, esamineremo il caso d’uso pratico del flusso di lavoro LFQA/RAG, concentrandoci su come integrare il DiversityRanker e il LostInTheMiddleRanker. Discuteremo anche come questi componenti interagiscono tra loro e con gli altri componenti nel flusso di lavoro.
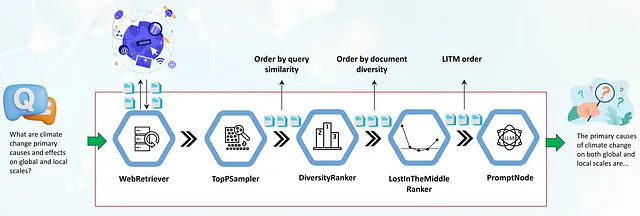
Il primo componente nel flusso di lavoro è un WebRetriever che recupera documenti rilevanti alla query dal web utilizzando un’API di motore di ricerca programmabile (SerperDev, Google, Bing, ecc.). I documenti recuperati vengono prima privati dei tag HTML, convertiti in testo grezzo e, facoltativamente, preelaborati in paragrafi più brevi. Vengono quindi passati a un componente TopPSampler, che seleziona i paragrafi più rilevanti in base alla loro similarità alla query.
Dopo che TopPSampler seleziona l’insieme di paragrafi rilevanti, vengono passati al DiversityRanker. Il DiversityRanker, a sua volta, ordina i paragrafi in base alla loro diversità, riducendo la ripetitività dei documenti ordinati da TopPSampler.
I documenti selezionati vengono quindi passati al LostInTheMiddleRanker. Come abbiamo già menzionato, LostInTheMiddleRanker posiziona i paragrafi più rilevanti all’inizio e alla fine della finestra di contesto, spingendo i documenti con il punteggio peggiore al centro.
Infine, i paragrafi uniti vengono passati a un PromptNode, che condiziona un LLM a rispondere alla domanda basandosi su questi paragrafi selezionati.
I nuovi ranker sono già stati uniti al ramo principale di Haystack e saranno disponibili nella prossima versione 1.20 prevista per la fine di agosto 2023. Abbiamo incluso una nuova demo del pipeline LFQA/RAG nella cartella degli esempi del progetto.
La demo mostra come il DiversityRanker e il LostInTheMiddleRanker possano essere facilmente integrati in un pipeline RAG per migliorare la qualità delle risposte generate.
Studio di caso
Per dimostrare l’efficacia dei pipeline LFQA/RAG che includono i due nuovi ranker, useremo un piccolo campione di una mezza dozzina di domande che richiedono risposte dettagliate. Le domande includono: “Quali sono le principali cause delle animosità di lunga data tra Russia e Polonia?”, “Quali sono le cause principali dei cambiamenti climatici sia a livello globale che locale?”, e altro ancora. Per rispondere bene a queste domande, i LLM richiedono una vasta gamma di fonti storiche, politiche, scientifiche e culturali, rendendoli ideali per il nostro caso d’uso.
Confrontare le risposte generate dal pipeline RAG con i due nuovi ranker (pipeline ottimizzata) e un pipeline senza di essi (non ottimizzata) richiederebbe una valutazione complessa che coinvolge il giudizio di esperti umani. Per semplificare la valutazione e valutare principalmente l’effetto del DiversityRanker, abbiamo calcolato la distanza coseno media a coppie dei documenti di contesto iniettati nel contesto del LLM. Abbiamo limitato la dimensione della finestra di contesto in entrambi i pipeline a 1024 parole. Eseguendo questi script Python di esempio [2], abbiamo scoperto che il pipeline ottimizzato ha un aumento medio del 20-30% della distanza coseno a coppie [3] per i documenti iniettati nel contesto del LLM. Questo aumento nella distanza coseno a coppie significa essenzialmente che i documenti utilizzati sono più diversi (e meno ripetitivi), dando così al LLM una gamma più ampia e ricca di paragrafi su cui attingere per le sue risposte. Lasciamo la valutazione del LostInTheMiddleRanker e il suo effetto sulle risposte generate per uno dei nostri prossimi articoli.
Conclusioni
Abbiamo esplorato come gli utenti di Haystack possano migliorare i loro pipeline RAG utilizzando due ranker innovativi: DiversityRanker e LostInTheMiddleRanker.
DiversityRanker garantisce che la finestra di contesto del LLM sia riempita con documenti diversi e non ripetitivi, fornendo una gamma più ampia di paragrafi per il LLM per sintetizzare la risposta. Allo stesso tempo, LostInTheMiddleRanker ottimizza il posizionamento dei paragrafi più rilevanti nella finestra di contesto, rendendo più facile per il modello accedere e utilizzare i documenti di supporto migliori.
Il nostro piccolo studio di caso ha confermato l’efficacia del DiversityRanker calcolando la distanza coseno media a coppie dei documenti iniettati nella finestra di contesto del LLM nel pipeline RAG ottimizzato (con due nuovi ranker) e nel pipeline non ottimizzato (senza ranker utilizzati). I risultati hanno mostrato che un pipeline RAG ottimizzato ha aumentato la distanza coseno media a coppie di circa il 20-30%.
Abbiamo dimostrato come questi nuovi ranker possano potenzialmente migliorare la Question-Answering a lungo termine e altri pipeline RAG. Continuando a investire ed espandere su queste e idee simili, possiamo migliorare ulteriormente le capacità dei pipeline RAG di Haystack, avvicinandoci alla creazione di soluzioni di NLP che sembrano più magia che realtà.
Riferimenti:
[1] “Lost in the Middle: How Language Models Use Long Contexts” su https://arxiv.org/abs/2307.03172
[2] Script: https://gist.github.com/vblagoje/430def6cda347c0b65f5f244bc0f2ede
[3] Output dello script (risposte): https://gist.github.com/vblagoje/738253f87b7590b1c014e3d598c8300b