Nuovi modelli ViT e ALIGN da Kakao Brain
Kakao Brain presenta nuovi modelli ViT e ALIGN.
Kakao Brain e Hugging Face sono entusiasti di rilasciare un nuovo dataset immagine-testo open source COYO di 700 milioni di coppie e due nuovi modelli di linguaggio visivo addestrati su di esso, ViT e ALIGN . Questa è la prima volta che il modello ALIGN viene reso pubblico gratuitamente e open source e il primo rilascio dei modelli ViT e ALIGN che sono forniti con il dataset di addestramento.
I modelli ViT e ALIGN di Kakao Brain seguono la stessa architettura e gli stessi iperparametri forniti nei rispettivi modelli originali di Google, ma vengono addestrati sul dataset COYO open source. I modelli ViT e ALIGN di Google, sebbene addestrati su enormi dataset (ViT addestrato su 300 milioni di immagini e ALIGN addestrato su 1,8 miliardi di coppie immagine-testo rispettivamente), non possono essere replicati perché i dataset non sono pubblici. Questo contributo è particolarmente prezioso per i ricercatori che desiderano riprodurre il modellamento del linguaggio visivo con accesso anche ai dati. Maggiori informazioni dettagliate sui modelli Kakao ViT e ALIGN possono essere trovate qui .
Questo blog presenterà il nuovo dataset COYO, i modelli ViT e ALIGN di Kakao Brain e come utilizzarli! Ecco i punti principali:
- Primo modello ALIGN open source di sempre!
- Primi modelli ViT e ALIGN open source addestrati su un dataset open source COYO
- I modelli ViT e ALIGN di Kakao Brain si comportano allo stesso livello delle versioni di Google
- Le demo di ViT e ALIGN sono disponibili su HF! Puoi interagire con le demo di ViT e ALIGN online con campioni di immagini a tua scelta!
Confronto delle prestazioni
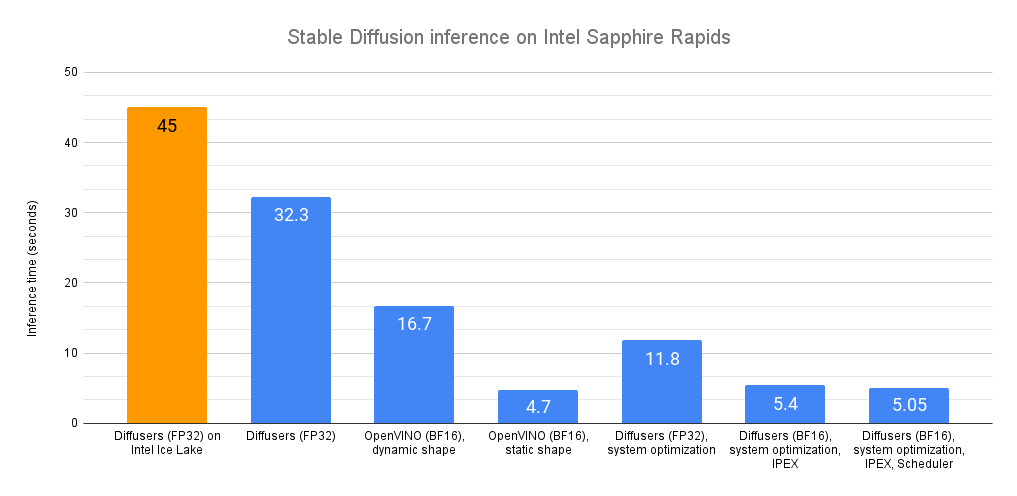
I modelli ViT e ALIGN rilasciati da Kakao Brain si comportano allo stesso livello e talvolta meglio di quanto Google abbia riportato sulla loro implementazione. Il modello ALIGN-B7-Base di Kakao Brain, sebbene addestrato su un numero molto inferiore di coppie (700 milioni di coppie rispetto a 1,8 miliardi), si comporta allo stesso livello del ALIGN-B7-Base di Google nel compito di classificazione KNN dell’immagine e meglio nei compiti di recupero immagine-testo e testo-immagine di MS-COCO. Il modello ViT-L/16 di Kakao Brain si comporta in modo simile al ViT-L/16 di Google quando valutato su ImageNet e ImageNet-ReaL alle risoluzioni del modello 384 e 512. Ciò significa che la comunità può utilizzare i modelli ViT e ALIGN di Kakao Brain per replicare i rilasci di ViT e ALIGN di Google, specialmente quando gli utenti richiedono accesso ai dati di addestramento. Siamo entusiasti di vedere rilasci open source e trasparenti di questi modelli che si comportano allo stesso livello dello stato dell’arte!
- Ottimizzazione avanzata di 20B LLM con RLHF su una GPU da 24GB per consumatori
- Jupyter X Hugging Face
- Addestra il tuo ControlNet con diffusori
DATASET COYO

Cosa c’è di speciale in questi rilasci di modelli è che i modelli sono addestrati sul dataset COYO gratuito e accessibile. COYO è un dataset immagine-testo di 700 milioni di coppie simile al dataset immagine-testo di ALIGN 1.8B di Google, che è una collezione di coppie “rumorose” di testo alternativo e immagine da pagine web, ma open source. COYO-700M e ALIGN 1.8B sono “rumorose” perché è stata applicata una filtrazione minima. COYO è simile all’altro dataset immagine-testo open source, LAION, ma con le seguenti differenze. Mentre LAION 2B è un dataset molto più grande di 2 miliardi di coppie in inglese, rispetto alle 700 milioni di coppie di COYO, le coppie di COYO includono più metadati che danno agli utenti maggiore flessibilità e controllo più dettagliato sull’uso. La seguente tabella mostra le differenze: COYO è dotato di punteggi estetici per tutte le coppie, punteggi di watermark più robusti e dati sul conteggio dei volti.
Come funzionano ViT e ALIGN
Allora, cosa fanno questi modelli? Discutiamo brevemente come funzionano i modelli ViT e ALIGN.
ViT — Vision Transformer — è un modello di visione proposto da Google nel 2020 che assomiglia all’architettura del Transformer per il testo. È un nuovo approccio alla visione, diverso dalle reti neurali convoluzionali (CNN) che hanno dominato i compiti di visione dal 2012 con AlexNet. È fino a quattro volte più efficiente dal punto di vista computazionale rispetto alle CNN che si comportano allo stesso modo e agnostico al dominio. ViT prende in input un’immagine che viene suddivisa in una sequenza di patch di immagini – proprio come il Transformer per il testo prende in input una sequenza di testo – e viene assegnata una posizione a ciascuna patch per apprendere la struttura dell’immagine. Le prestazioni di ViT sono particolarmente notevoli per avere un ottimo rapporto prestazioni-calcolo. Sebbene alcuni modelli ViT di Google siano open source, il dataset JFT-300 milioni di coppie immagine-etichetta su cui sono stati addestrati non è stato pubblicato pubblicamente. Mentre quello di Kakao Brain è stato addestrato su COYO-Labeled-300M , che è stato rilasciato pubblicamente, e il modello ViT rilasciato si comporta in modo simile in vari compiti, il suo codice, modello e dati di addestramento (COYO-Labeled-300M) sono completamente pubblici per la riproducibilità e la scienza aperta.
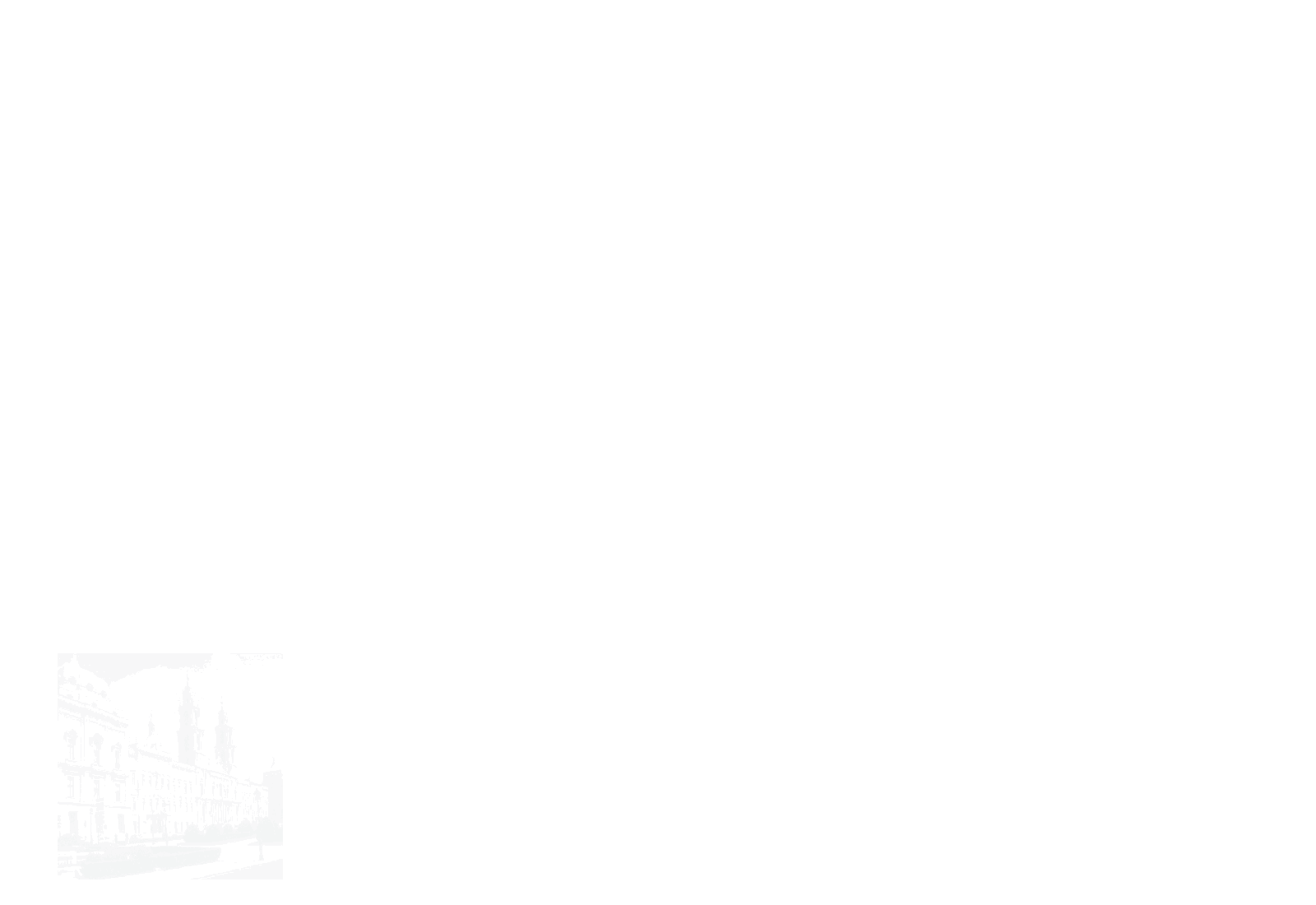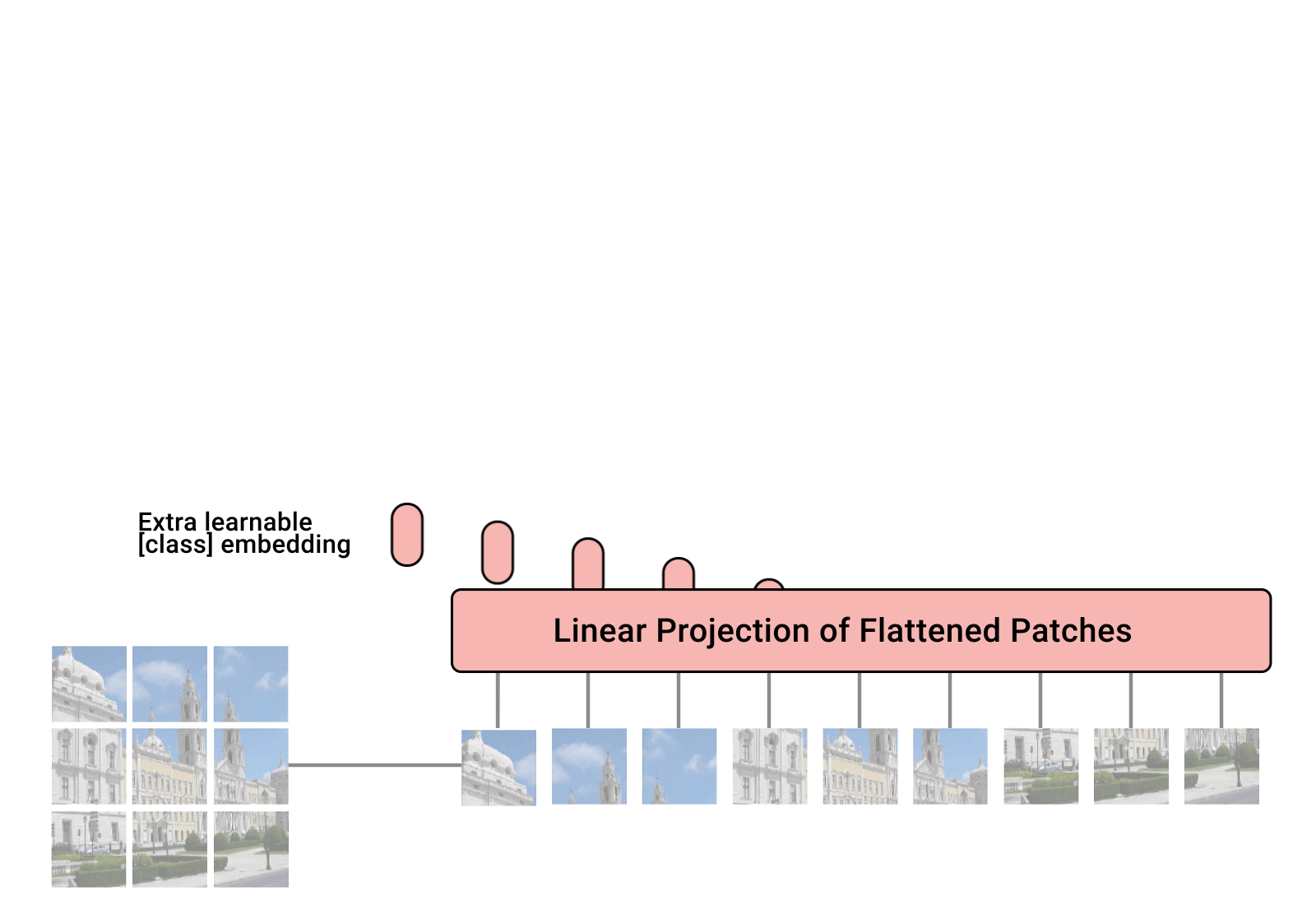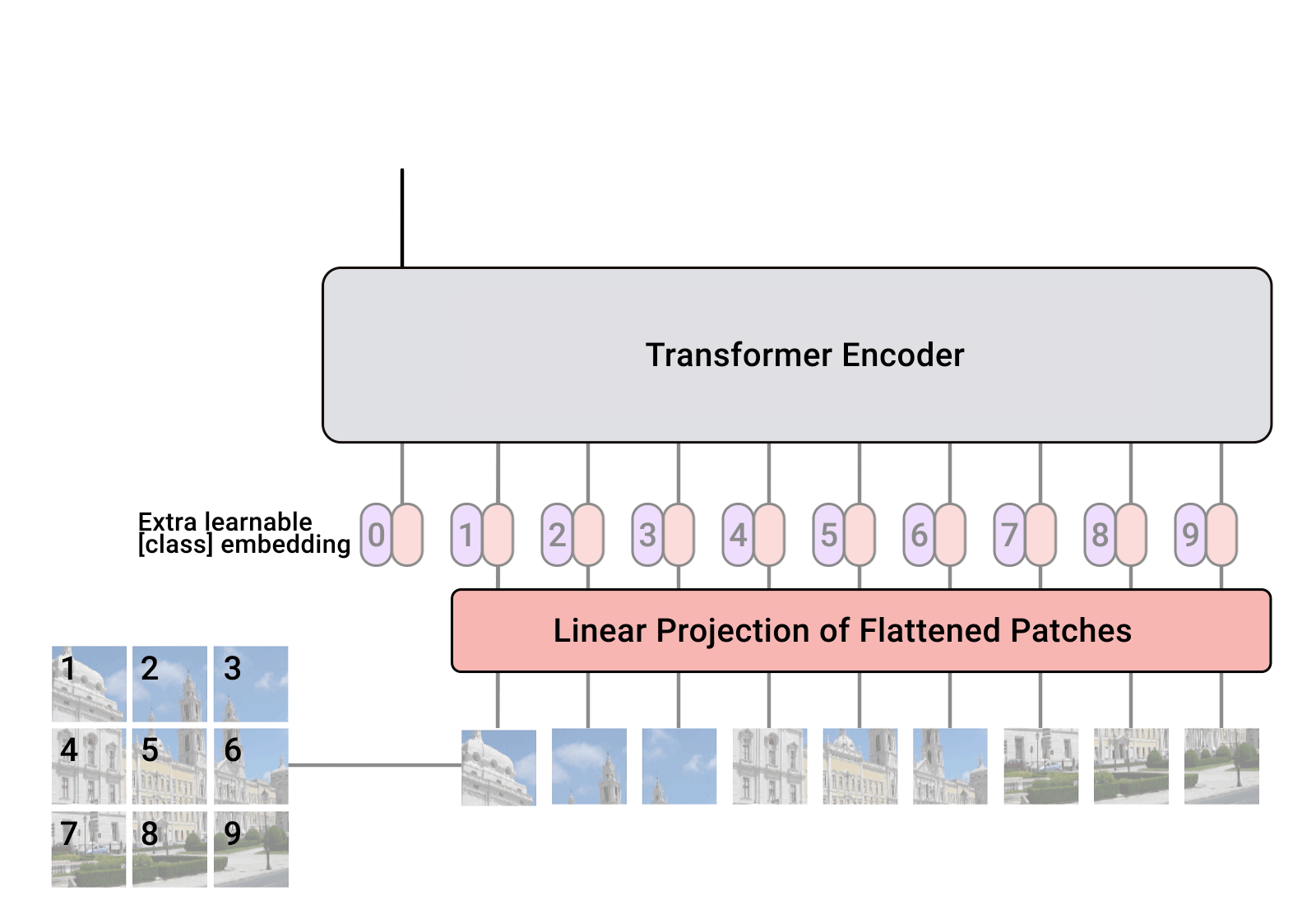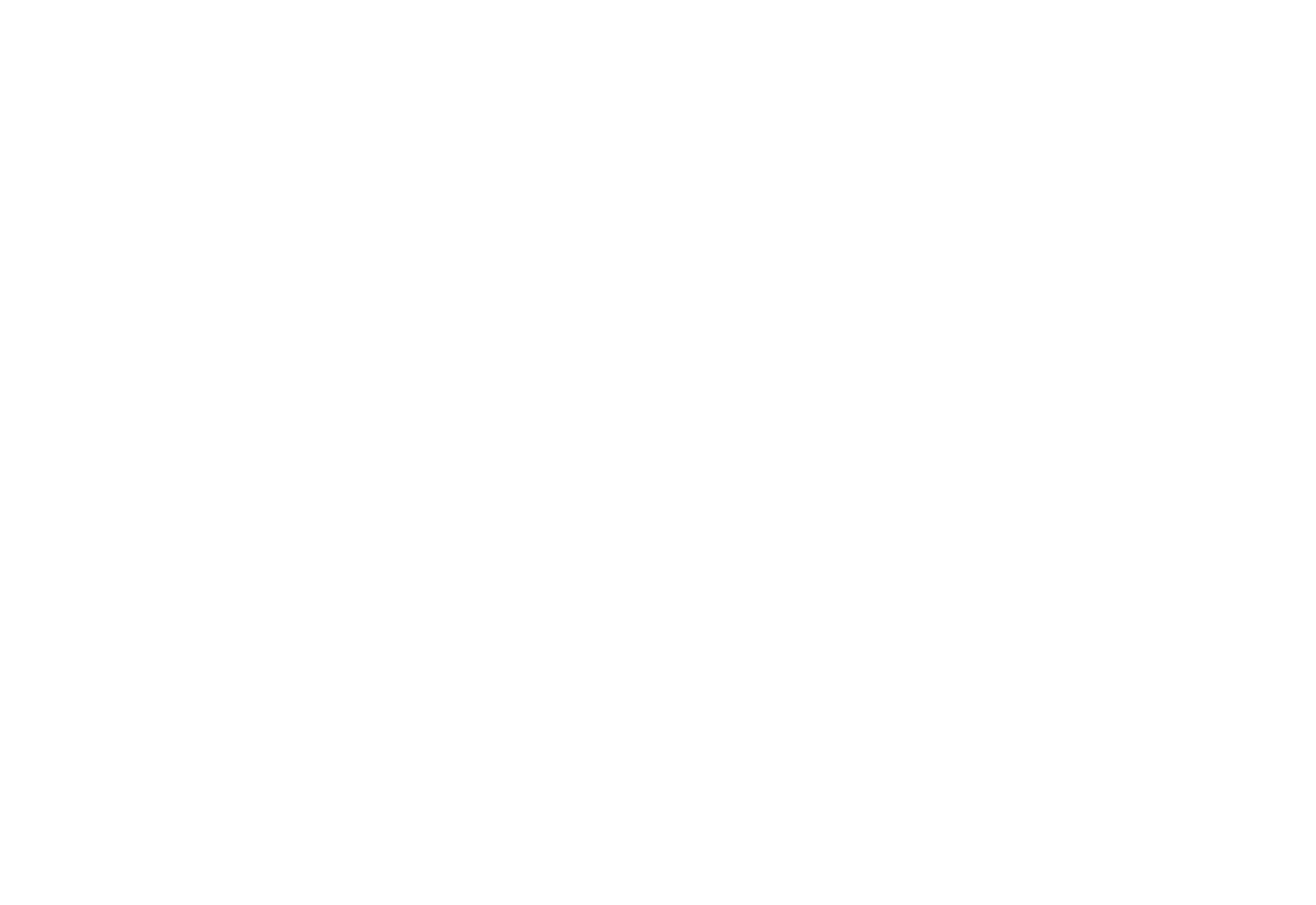
Una visualizzazione di come funziona ViT dal blog di Google
Successivamente, Google ha introdotto ALIGN, un modello di embedding su larga scala di immagini e testo rumoroso nel 2021. ALIGN è un modello di lingua visiva addestrato su dati di testo-immagine “rumorosi” per diverse attività di visione e cross-modalità come il recupero di testo-immagine. ALIGN ha un’architettura a doppio codificatore semplice addestrato su coppie di immagini e testi, appreso tramite una funzione di perdita contrastiva. Il corpus di addestramento “rumoroso” di ALIGN è noto per bilanciare la scala e la robustezza. In precedenza, l’apprendimento della rappresentazione del linguaggio visivo era stato addestrato su set di dati su larga scala con etichette manuali, che richiedono un’ampia elaborazione preliminare. Il corpus di ALIGN utilizza i dati di testo alternativo dell’immagine, il testo che appare quando l’immagine non viene caricata, come didascalia dell’immagine – risultando inevitabilmente rumoroso, ma molto più grande (1,8 miliardi di coppie) dataset che consente ad ALIGN di avere prestazioni di livello SoTA su varie attività. ALIGN di Kakao Brain è la prima versione open-source di questo modello, addestrato sul dataset COYO e ottiene risultati migliori rispetto a quelli riportati da Google.

Modello ALIGN dal blog di Google
Come utilizzare il dataset COYO
Possiamo scaricare comodamente il dataset COYO con una singola riga di codice utilizzando la libreria 🤗 Datasets. Per visualizzare l’anteprima del dataset COYO e saperne di più sul processo di curatela dei dati e sugli attributi meta inclusi, visita la pagina del dataset sullo hub o il repository Git originale. Per iniziare, installiamo la libreria 🤗 Datasets: pip install datasets e scarichiamola.
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m')
>>> datasetAnche se è significativamente più piccolo del dataset LAION, il dataset COYO è comunque enorme con 747M di coppie immagine-testo e potrebbe essere impossibile scaricare l’intero dataset sul tuo computer locale. Per scaricare solo un sottoinsieme del dataset, possiamo semplicemente passare l’argomento streaming=True al metodo load_dataset() per creare un dataset iterabile e scaricare le istanze di dati man mano che procediamo.
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m', streaming=True)
>>> print(next(iter(dataset['train'])))
{'id': 2680060225205, 'url': 'https://cdn.shopify.com/s/files/1/0286/3900/2698/products/TVN_Huile-olive-infuse-et-s-227x300_e9a90ffd-b6d2-4118-95a1-29a5c7a05a49_800x.jpg?v=1616684087', 'text': 'Olio di oliva aromatizzato alle erbe toscane', 'width': 227, 'height': 300, 'image_phash': '9f91e133b1924e4e', 'text_length': 36, 'word_count': 6, 'num_tokens_bert': 6, 'num_tokens_gpt': 9, 'num_faces': 0, 'clip_similarity_vitb32': 0.19921875, 'clip_similarity_vitl14': 0.147216796875, 'nsfw_score_opennsfw2': 0.0058441162109375, 'nsfw_score_gantman': 0.018961310386657715, 'watermark_score': 0.11015450954437256, 'aesthetic_score_laion_v2': 4.871710777282715}Come utilizzare ViT e ALIGN dall’hub
Andiamo avanti e sperimentiamo con i nuovi modelli ViT e ALIGN. Poiché ALIGN è stato appena aggiunto a 🤗 Transformers, installeremo l’ultima versione della libreria: pip install -q git+https://github.com/huggingface/transformers.git e inizieremo con ViT per la classificazione delle immagini importando i moduli e le librerie che utilizzeremo. Nota che il modello ALIGN appena aggiunto farà parte del pacchetto PyPI nella prossima versione della libreria.
import requests
from PIL import Image
import torch
from transformers import ViTImageProcessor, ViTForImageClassificationSuccessivamente, scaricheremo un’immagine casuale di due gatti e telecomandi su un divano dal dataset COCO e pre-elaboreremo l’immagine per trasformarla nel formato di input previsto dal modello. Per fare ciò, possiamo utilizzare comodamente la corrispondente classe di preelaborazione ( ViTProcessor ). Per inizializzare il modello e il preelaboratore, utilizzeremo uno dei repos di Kakao Brain ViT sul hub. Si noti che l’inizializzazione del preelaboratore da un repository garantisce che l’immagine pre-elaborata sia nel formato previsto da quel modello preaddestrato specifico.
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('kakaobrain/vit-large-patch16-384')
model = ViTForImageClassification.from_pretrained('kakaobrain/vit-large-patch16-384')Il resto è semplice, pre-elaboreremo l’immagine in input al modello per ottenere i logit di classe. I modelli di classificazione delle immagini di Kakao Brain ViT sono addestrati sulle etichette di ImageNet e restituiscono logit di forma (batch_size, 1000).
# pre-elabora l'immagine o l'elenco delle immagini
inputs = processor(images=image, return_tensors="pt")
# inferenza
with torch.no_grad():
outputs = model(**inputs)
# applica SoftMax ai logit per calcolare la probabilità di ogni classe
preds = torch.nn.functional.softmax(outputs.logits, dim=-1)
# stampa le prime 5 previsioni di classe e le loro probabilità
top_class_preds = torch.argsort(preds, descending=True)[0, :5]
for c in top_class_preds:
print(f"{model.config.id2label[c.item()]} con probabilità {round(preds[0, c.item()].item(), 4)}")E abbiamo finito! Per rendere le cose ancora più facili e più brevi, possiamo anche utilizzare la comoda pipeline di classificazione delle immagini e passare il nome del repository di Kakao Brain ViT come nostro modello target per inizializzare la pipeline. Possiamo quindi passare un URL o un percorso locale a un’immagine o un’immagine Pillow e utilizzare facoltativamente l’argomento top_k per restituire le prime k previsioni. Procediamo quindi ottenendo le prime 5 previsioni per la nostra immagine di gatti e telecomandi.
>>> from transformers import pipeline
>>> classifier = pipeline(task='image-classification', model='kakaobrain/vit-large-patch16-384')
>>> classifier('http://images.cocodataset.org/val2017/000000039769.jpg', top_k=5)
[{'score': 0.8223727941513062, 'label': 'telecomando, telecomando'}, {'score': 0.06580372154712677, 'label': 'tabby, gatto tabby'}, {'score': 0.0655883178114891, 'label': 'gatto tigre'}, {'score': 0.0388941615819931, 'label': 'gatto egiziano'}, {'score': 0.0011215205304324627, 'label': 'lince, puma'}]Se vuoi sperimentare di più con il modello Kakao Brain ViT, vai al suo spazio su Hub 🤗.
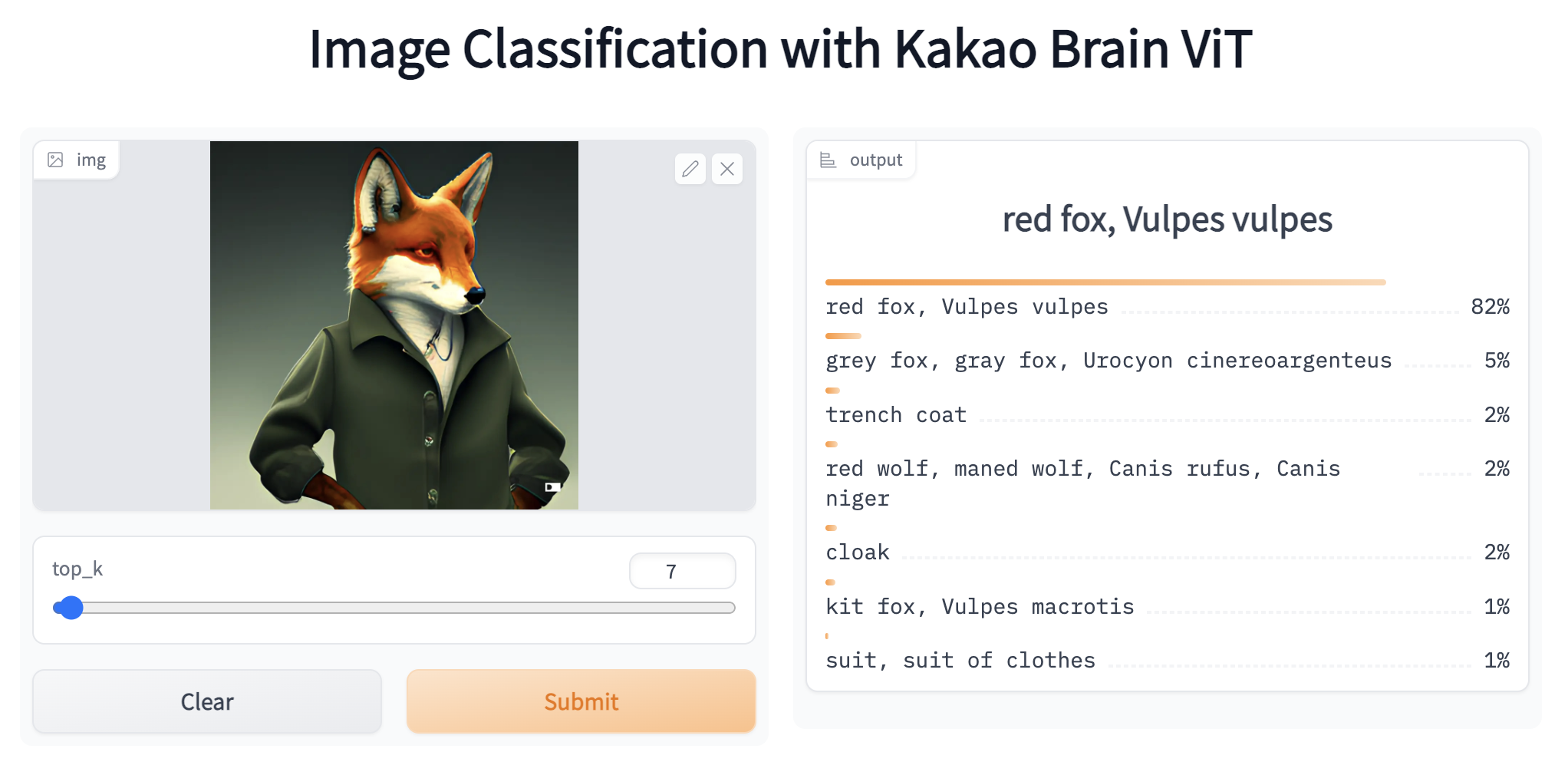
Passiamo ora a sperimentare con ALIGN, che può essere utilizzato per recuperare embedding multi-modali di testi o immagini o per eseguire la classificazione di immagini zero-shot. L’implementazione di ALIGN e il suo utilizzo sono simili a CLIP. Per iniziare, scarichiamo prima il modello preaddestrato e il suo preelaboratore, che può preelaborare sia le immagini che i testi in modo che siano nel formato previsto per essere alimentati negli encoder di visione e di testo di ALIGN. Ancora una volta, importiamo i moduli che useremo e inizializziamo il preelaboratore e il modello.
import requests
from PIL import Image
import torch
from transformers import AlignProcessor, AlignModel
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignModel.from_pretrained('kakaobrain/align-base')Cominceremo prima con la classificazione di immagini a zero-shot. Per farlo, forniremo etichette candidate (testo libero) e utilizzeremo AlignModel per scoprire quale descrizione descrive meglio l’immagine. Prima elaboreremo sia le immagini che gli input di testo e forniremo l’input preelaborato ad AlignModel.
candidate_labels = ['un'immagine di un gatto', 'un'immagine di un cane']
inputs = processor(images=immagine, text=candidate_labels, return_tensors='pt')
con torch.no_grad():
outputs = model(**inputs)
# questo è il punteggio di similarità tra immagine e testo
logits_per_image = outputs.logits_per_image
# possiamo applicare la softmax per ottenere le probabilità delle etichette
probs = logits_per_image.softmax(dim=1)
print(probs)Fatto, facile come bere un bicchier d’acqua. Per sperimentare di più con il modello ALIGN di Kakao Brain per la classificazione di immagini a zero-shot, basta andare alla sua demo su 🤗 Hub. Si noti che l’output di AlignModel include text_embeds e image_embeds (vedi la documentazione di ALIGN). Se non abbiamo bisogno di calcolare i logit per immagine e testo per la classificazione a zero-shot, possiamo ottenere gli embedding visivi e di testo utilizzando i comodi metodi get_image_features() e get_text_features() della classe AlignModel.
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)In alternativa, possiamo utilizzare gli encoder di testo e visione stand-alone di ALIGN per ottenere embedding multimodali. Questi embedding possono poi essere utilizzati per addestrare modelli per vari compiti successivi come la rilevazione oggetti, la segmentazione dell’immagine e la descrizione dell’immagine. Vediamo come possiamo ottenere questi embedding utilizzando AlignTextModel e AlignVisionModel. Si noti che possiamo utilizzare la comoda classe AlignProcessor per elaborare separatamente testi e immagini.
from transformers import AlignTextModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignTextModel.from_pretrained('kakaobrain/align-base')
# ottieni gli embedding di due query di testo
inputs = processor(['un'immagine di un gatto', 'un'immagine di un cane'], return_tensors='pt')
con torch.no_grad():
outputs = model(**inputs)
# ottieni l'ultimo hidden state e l'output pooler finale
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_outputPossiamo anche scegliere di restituire tutti gli hidden state e i valori di attenzione impostando gli argomenti output_hidden_states e output_attentions su True durante l’inferenza.
con torch.no_grad():
outputs = model(**inputs, output_hidden_states=True, output_attentions=True)
# stampa quali informazioni vengono restituite
for key, value in outputs.items():
print(key)Facciamo lo stesso con AlignVisionModel e otteniamo l’embedding multimodale di un’immagine.
from transformers import AlignVisionModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignVisionModel.from_pretrained('kakaobrain/align-base')
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
immagine = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=immagine, return_tensors='pt')
con torch.no_grad():
outputs = model(**inputs)
# stampa l'ultimo hidden state e l'output pooler finale
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_outputCome ViT, possiamo utilizzare il pipeline di classificazione di immagini a zero-shot per rendere ancora più semplice il nostro lavoro. Vediamo come possiamo utilizzare questa pipeline per eseguire la classificazione di immagini “in the wild” utilizzando etichette candidate in forma di testo libero.
>>> from transformers import pipeline
>>> classifier = pipeline(task='zero-shot-image-classification', model='kakaobrain/align-base')
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['animali', 'esseri umani', 'paesaggi'],
... )
[{'score': 0.9263709783554077, 'label': 'animali'}, {'score': 0.07163811475038528, 'label': 'esseri umani'}, {'score': 0.0019908479880541563, 'label': 'paesaggi'}]
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['bianco e nero', 'fotorealista', 'pittura'],
... )
[{'score': 0.9735308885574341, 'label': 'bianco e nero'}, {'score': 0.025493400171399117, 'label': 'fotorealista'}, {'score': 0.0009757201769389212, 'label': 'pittura'}]Conclusione
Negli ultimi anni ci sono stati incredibili progressi nei modelli multimodali, con modelli come CLIP e ALIGN che sbloccano varie attività derivate come la didascalia delle immagini, la classificazione delle immagini a zero-shot e la rilevazione di oggetti a vocabolario aperto. In questo blog, abbiamo parlato degli ultimi modelli open source ViT e ALIGN contribuiti all’Hub da Kakao Brain, così come del nuovo dataset di testo-immagine COYO. Abbiamo anche mostrato come è possibile utilizzare questi modelli per eseguire varie attività con poche righe di codice sia da soli che come parte dei pipeline di 🤗 Transformers.
Ecco tutto! Continuiamo ad integrare i modelli di visione artificiale e multimodali più impattanti e ci piacerebbe avere un tuo riscontro. Per rimanere aggiornato sulle ultime novità nella ricerca sulla visione artificiale e multimodale, puoi seguirci su Twitter: @adirik , @a_e_roberts , @NielsRogge , @RisingSayak , e @huggingface .