Presentando RWKV – Una RNN con i vantaggi di un transformer
Introducing RWKV - A hybrid RNN with transformer benefits.
ChatGPT e le applicazioni basate su chatbot hanno attirato notevole attenzione nel campo dell’Elaborazione del Linguaggio Naturale (NLP). La comunità è costantemente alla ricerca di modelli forti, affidabili e open-source per le proprie applicazioni e casi d’uso. La crescita di questi potenti modelli deriva dalla democratizzazione e dall’ampia adozione dei modelli basati su trasformatori, introdotti per la prima volta da Vaswani et al. nel 2017. Questi modelli hanno superato significativamente i modelli NLP SoTA precedenti basati su Reti Neurali Ricorrenti (RNN), che sono stati considerati obsoleti dopo quel paper. Attraverso questo post sul blog, presenteremo l’integrazione di una nuova architettura, RWKV, che combina i vantaggi sia delle RNN che dei trasformatori, e che è stata recentemente integrata nella libreria transformers di Hugging Face.
Panoramica del progetto RWKV
Il progetto RWKV è stato avviato e viene guidato da Bo Peng, che contribuisce attivamente e mantiene il progetto. La comunità, organizzata nel canale ufficiale di Discord, sta costantemente migliorando gli artefatti del progetto su vari argomenti come prestazioni (RWKV.cpp, quantizzazione, ecc.), scalabilità (elaborazione e acquisizione di dati) e ricerca (ottimizzazione della chat, ottimizzazione multi-modale, ecc.). Le GPU per l’addestramento dei modelli RWKV sono donate da Stability AI.
Puoi partecipare unendoti al canale ufficiale di Discord e saperne di più sulle idee generali dietro RWKV in questi due post sul blog: https://johanwind.github.io/2023/03/23/rwkv_overview.html / https://johanwind.github.io/2023/03/23/rwkv_details.html
Architettura dei trasformatori vs RNN
L’architettura delle RNN è una delle prime architetture di reti neurali ampiamente utilizzate per l’elaborazione di una sequenza di dati, contrariamente alle architetture classiche che prendono in input una dimensione fissa. Prende in input il “token” corrente (cioè il punto dati corrente del flusso di dati), lo “stato” precedente e calcola il token successivo previsto e lo stato successivo previsto. Lo stato nuovo viene quindi utilizzato per calcolare la predizione del token successivo e così via. Le RNN possono essere utilizzate anche in diverse “modalità”, consentendo quindi la possibilità di applicare le RNN in diversi scenari, come indicato nel post sul blog di Andrej Karpathy, come ad esempio one-to-one (classificazione di immagini), one-to-many (didascalia delle immagini), many-to-one (classificazione di sequenze), many-to-many (generazione di sequenze), ecc.
- Esegui un Chatbot simile a Chatgpt su una singola GPU con ROCm
- Più piccolo è meglio Q8-Chat, un’efficace esperienza di intelligenza artificiale generativa su Xeon
- Grande riduzione della duplicazione su larga scala dietro BigCode
Poiché le RNN utilizzano gli stessi pesi per calcolare le previsioni ad ogni passo, faticano a memorizzare informazioni per sequenze a lungo termine a causa del problema del gradiente che svanisce. Sono stati fatti sforzi per affrontare questa limitazione introducendo nuove architetture come LSTMs o GRUs. Tuttavia, l’architettura del trasformatore si è dimostrata finora la più efficace nel risolvere questo problema.
Nell’architettura del trasformatore, i token di input vengono elaborati contemporaneamente nel modulo di auto-attenzione. I token vengono prima proiettati linearmente in spazi diversi utilizzando i pesi di query, chiave e valore. Le matrici risultanti vengono utilizzate direttamente per calcolare i punteggi di attenzione (attraverso softmax, come mostrato di seguito), quindi moltiplicati per gli stati nascosti dei valori per ottenere gli stati nascosti finali. Questo design consente all’architettura di mitigare efficacemente il problema della sequenza a lungo termine e di eseguire anche inferenze e addestramenti più veloci rispetto ai modelli RNN.
Durante l’addestramento, l’architettura del trasformatore ha diversi vantaggi rispetto alle tradizionali RNN e CNN. Uno dei vantaggi più significativi è la sua capacità di apprendere rappresentazioni contestuali. A differenza delle RNN e delle CNN, che elaborano sequenze di input parola per parola, l’architettura del trasformatore elabora le sequenze di input nel loro insieme. Ciò consente di catturare dipendenze a lungo raggio tra le parole nella sequenza, il che è particolarmente utile per compiti come la traduzione del linguaggio e la risposta alle domande.
Durante l’elaborazione, le RNN hanno alcuni vantaggi in termini di velocità ed efficienza della memoria. Questi vantaggi includono la semplicità, dovuta alla necessità di operazioni matrice-vettore, e l’efficienza della memoria, poiché i requisiti di memoria non crescono durante l’elaborazione. Inoltre, la velocità di calcolo rimane la stessa con la lunghezza della finestra di contesto grazie al fatto che i calcoli agiscono solo sul token corrente e sullo stato.
L’architettura RWKV
RWKV è ispirato all’Attention Free Transformer di Apple. L’architettura è stata attentamente semplificata e ottimizzata in modo da poter essere trasformata in una RNN. Inoltre, sono stati aggiunti una serie di trucchi come TokenShift e SmallInitEmb (l’elenco dei trucchi è elencato nel README del repository ufficiale di GitHub) per aumentarne le prestazioni fino a raggiungere GPT. Senza questi, il modello non sarebbe altrettanto performante. Per l’addestramento, è presente un’infrastruttura per scalare l’addestramento fino a 14B di parametri fino ad oggi, e alcuni problemi sono stati risolti iterativamente in RWKV-4 (ultima versione ad oggi), come l’instabilità numerica.
RWKV come combinazione di RNN e transformers
Come combinare il meglio dei transformers e delle RNN? Lo svantaggio principale dei modelli basati su transformer è che può diventare difficile eseguire un modello con una finestra di contesto più grande di un certo valore, in quanto i punteggi di attenzione vengono calcolati contemporaneamente per l’intera sequenza.
Le RNN supportano nativamente lunghezze di contesto molto lunghe – limitate solo dalla lunghezza di contesto vista durante l’addestramento, ma questo può essere esteso a milioni di token con una codifica attenta. Attualmente, ci sono modelli RWKV addestrati su una lunghezza di contesto di 8192 (ctx8192) e sono veloci quanto i modelli ctx1024 e richiedono la stessa quantità di RAM.
Gli svantaggi principali dei modelli RNN tradizionali e come RWKV è diverso:
- I modelli RNN tradizionali non sono in grado di utilizzare contesti molto lunghi (LSTM può gestire solo ~100 token quando usato come LM). Tuttavia, RWKV può utilizzare migliaia di token e oltre, come mostrato di seguito:
- I modelli RNN tradizionali non possono essere parallelizzati durante l’addestramento. RWKV è simile a un “GPT linearizzato” e si addestra più velocemente di GPT.
Combinando entrambi i vantaggi in un’unica architettura, si spera che RWKV possa diventare più della somma delle sue parti.
Formulazione dell’attenzione di RWKV
L’architettura del modello è molto simile ai modelli basati su transformer classici (ossia un livello di embedding, più livelli identici, normalizzazione di livello e una testa di Causal Language Modeling per prevedere il token successivo). L’unica differenza è nel livello di attenzione, che è completamente diverso rispetto ai modelli tradizionali basati su transformer.
Per avere una comprensione più completa del livello di attenzione, si consiglia di approfondire la spiegazione dettagliata fornita in un post sul blog di Johan Sokrates Wind.
Checkpoint esistenti
Modelli di sola lingua: modelli RWKV-4
I modelli RWKV più adottati vanno da ~170M a 14B di parametri. Secondo il post di panoramica di RWKV, questi modelli sono stati addestrati sul dataset Pile e valutati rispetto ad altri modelli SoTA su diversi benchmark, e sembrano performare abbastanza bene, con risultati molto comparabili.
Versione addestrata/Chat: modello RWKV-4 Raven
Bo ha anche addestrato una versione “chat” dell’architettura RWKV, il modello RWKV-4 Raven. È un modello RWKV-4 Pile (modello RWKV preaddestrato sul dataset Pile) addestrato su ALPACA, CodeAlpaca, Guanaco, GPT4All, ShareGPT e altro. Il modello è disponibile in diverse versioni, con modelli addestrati in diverse lingue (solo inglese, inglese + cinese + giapponese, inglese + giapponese, ecc.) e dimensioni diverse (1.5B di parametri, 7B di parametri, 14B di parametri).
Tutti i modelli convertiti in HF sono disponibili su Hugging Face Hub, nell’organizzazione RWKV.
Integrazione con 🤗 Transformers
L’architettura è stata aggiunta alla libreria transformers grazie a questa Pull Request. Al momento della scrittura, è possibile utilizzarla installando transformers dalla sorgente o utilizzando il branch main della libreria. L’architettura è strettamente integrata con la libreria e può essere utilizzata come qualsiasi altra architettura.
Esaminiamo alcuni esempi di seguito.
Esempio di generazione di testo
Per generare testo dato un prompt di input, è possibile utilizzare pipeline per generare testo:
from transformers import pipeline
model_id = "RWKV/rwkv-4-169m-pile"
prompt = "\nIn un risultato scioccante, gli scienziati hanno scoperto un branco di draghi che vivono in una valle remota, precedentemente inesplorata, in Tibet. Ancora più sorprendente per i ricercatori è stato il fatto che i draghi parlavano perfettamente il cinese."
pipe = pipeline("text-generation", model=model_id)
print(pipe(prompt, max_new_tokens=20))
>>> [{'generated_text': '\nIn un risultato scioccante, gli scienziati hanno scoperto un branco di draghi che vivono in una valle remota, precedentemente inesplorata, in Tibet. Ancora più sorprendente per i ricercatori è stato il fatto che i draghi parlavano perfettamente il cinese.\n\nI ricercatori hanno scoperto che i draghi erano in grado di comunicare tra loro e che'}]O puoi eseguire e iniziare dal frammento di codice qui sotto:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile")
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
prompt = "\nIn una scoperta scioccante, gli scienziati hanno scoperto un branco di draghi che vivono in una valle remota, precedentemente inesplorata, in Tibet. Ancora più sorprendente per i ricercatori è il fatto che i draghi parlavano perfetto cinese."
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(inputs["input_ids"], max_new_tokens=20)
print(tokenizer.decode(output[0].tolist()))
>>> In una scoperta scioccante, gli scienziati hanno scoperto un branco di draghi che vivono in una valle remota, precedentemente inesplorata, in Tibet. Ancora più sorprendente per i ricercatori è il fatto che i draghi parlavano perfetto cinese.\n\nI ricercatori hanno scoperto che i draghi erano in grado di comunicare tra loro e che eranoUtilizza i modelli Raven (modelli di chat)
Puoi sollecitare il modello di chat in stile alpaca, ecco un esempio qui sotto:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "RWKV/rwkv-raven-1b5"
model = AutoModelForCausalLM.from_pretrained(model_id).to(0)
tokenizer = AutoTokenizer.from_pretrained(model_id)
question = "Dimmi qualcosa sui corvi"
prompt = f"### Istruzione: {question}\n### Risposta:"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(inputs["input_ids"], max_new_tokens=100)
print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True))
>>> ### Istruzione: Dimmi qualcosa sui corvi
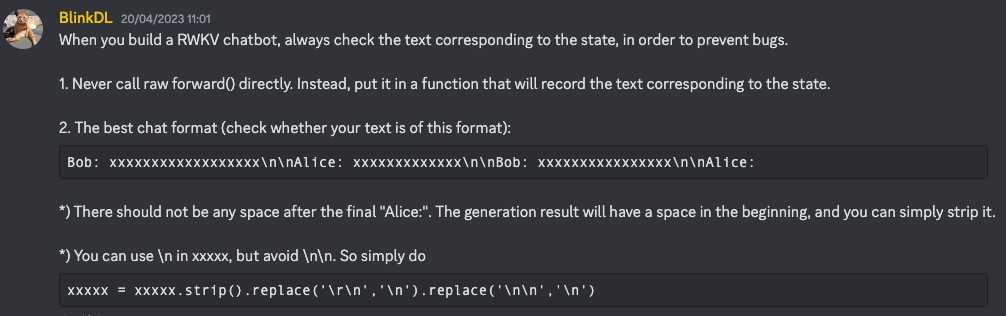
### Risposta: I CORVI sono un tipo di uccello nativo del Medio Oriente e dell'Africa del Nord. Sono noti per la loro intelligenza, adattabilità e capacità di vivere in una varietà di ambienti. I CORVI sono noti per la loro intelligenza, adattabilità e capacità di vivere in una varietà di ambienti. Sono noti per la loro intelligenza, adattabilità e capacità di vivere in una varietà di ambienti.Secondo Bo, le migliori tecniche di istruzione sono descritte in questo messaggio su Discord (assicurati di unirti al canale prima di fare clic)
|  |
|
Conversione dei pesi
Qualsiasi utente può facilmente convertire i pesi originali RWKV nel formato HF semplicemente eseguendo lo script di conversione fornito nella libreria transformers. Prima, carica i pesi “raw” su Hugging Face Hub (indichiamo tale repository come RAW_HUB_REPO e il file raw RAW_FILE), quindi esegui lo script di conversione:
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIRSe desideri caricare il modello convertito su Hub (ad esempio, sotto dummy_user/converted-rwkv), prima ricorda di effettuare il login con huggingface-cli login prima di caricare il modello, quindi esegui:
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR --push_to_hub --model_name dummy_user/converted-rwkvFuture work
Multi-lingual RWKV
Bo sta attualmente lavorando su un corpus multilingue per addestrare modelli RWKV. Di recente è stato rilasciato un nuovo tokenizer multilingue.
Progetti orientati alla comunità e alla ricerca
La comunità RWKV è molto attiva e sta lavorando su diverse direzioni di sviluppo, un elenco di progetti interessanti può essere trovato in un canale dedicato su Discord (assicurati di unirti al canale prima di fare clic sul link). Esiste anche un canale dedicato alla ricerca su questa architettura, sentiti libero di unirti e contribuire!
Compressione e accelerazione del modello
A causa della necessità solo di operazioni matrice-vettore, RWKV è un candidato ideale per hardware di calcolo non standard e sperimentale, come processori/acceleratori fototonici.
Pertanto, l’architettura può anche trarre vantaggio in modo naturale dalle tecniche classiche di accelerazione e compressione (come ONNX, quantizzazione a 4-bit/8-bit, ecc.), e speriamo che ciò venga democratizzato per sviluppatori e professionisti insieme all’integrazione dei transformers nell’architettura.
RWKV può anche beneficiare delle tecniche di accelerazione proposte dalla libreria optimum in futuro. Alcune di queste tecniche sono evidenziate nel repository rwkv.cpp o nel repository rwkv-cpp-cuda.
Ringraziamenti
Il team di Hugging Face desidera ringraziare Bo e la comunità di RWKV per il loro tempo e per aver risposto alle nostre domande sull’architettura. Vorremmo anche ringraziarli per il loro aiuto e supporto e guardiamo avanti per vedere una maggiore adozione dei modelli RWKV nell’ecosistema di HF. Desideriamo inoltre riconoscere il lavoro di Johan Wind per il suo blogpost su RWKV, che ci ha aiutato molto a comprendere l’architettura e il suo potenziale. E infine, vorremmo sottolineare e riconoscere il lavoro di ArEnSc per aver ripreso la PR iniziale di transformers. Un grande plauso anche a Merve Noyan, Maria Khalusova e Pedro Cuenca per aver gentilmente revisionato questo blogpost per renderlo molto migliore!
Citazione
Se utilizzi RWKV per il tuo lavoro, utilizza la seguente citazione cff.





