Grande riduzione della duplicazione su larga scala dietro BigCode
Enorme riduzione duplicazione in BigCode.
Pubblico destinatario
Le persone interessate alla deduplicazione a livello di documento su larga scala e che hanno una certa comprensione dell’hashing, del grafico e dell’elaborazione del testo.
Motivazioni
È importante prendersi cura dei nostri dati prima di alimentare il modello, almeno nel caso del Large Language Model, come dice il vecchio detto, spazzatura dentro, spazzatura fuori. Anche se è sempre più difficile farlo con modelli che attirano l’attenzione (o dovremmo dire API) creando l’illusione che la qualità dei dati conti meno.
Uno dei problemi che affrontiamo sia in BigScience che in BigCode per la qualità dei dati è la duplicazione, inclusa la possibile contaminazione del benchmark. È stato dimostrato che i modelli tendono a restituire i dati di addestramento testuali in modo letterale quando ci sono molti duplicati [1] (anche se è meno chiaro in altri domini [2]), e ciò rende il modello vulnerabile agli attacchi alla privacy [1]. Inoltre, alcuni vantaggi tipici della deduplicazione includono anche:
- Addestramento efficiente: è possibile ottenere le stesse, e talvolta migliori, prestazioni con meno passaggi di addestramento [3] [4].
- Prevenire possibili falle di dati e contaminazione del benchmark: i duplicati diversi da zero discreditano le valutazioni e possono rendere una presunta miglioramento una falsa affermazione.
- Accessibilità. La maggior parte di noi non può permettersi di scaricare o trasferire migliaia di gigabyte di testo ripetutamente, per non parlare di addestrare un modello con esso. La deduplicazione, per un dataset di dimensioni fisse, rende più facile studiare, trasferire e collaborare.
Da BigScience a BigCode
Permettetemi di condividere prima una storia su come mi sono imbarcato in questa ricerca di deduplicazione, come sono progrediti i risultati e quali lezioni ho imparato lungo il percorso.
- 🐶Safetensors è stato sottoposto ad una revisione di sicurezza ed è diventato il valore predefinito.
- Hugging Face e IBM si sono uniti su watsonx.ai, lo studio aziendale di prossima generazione per i creatori di intelligenza artificiale.
- Hugging Face collabora con Microsoft per lanciare il Catalogo dei Modelli di Hugging Face su Azure.
Tutto è cominciato con una conversazione su LinkedIn quando BigScience era già iniziato da un paio di mesi. Huu Nguyen mi ha contattato quando ha notato il mio progetto personale su GitHub e mi ha chiesto se ero interessato a lavorare sulla deduplicazione per BigScience. Naturalmente, la mia risposta è stata sì, completamente ignaro di quanto sforzo sarebbe stato richiesto solo a causa della grande quantità di dati.
È stato divertente e stimolante allo stesso tempo. È stimolante nel senso che non avevo molta esperienza di ricerca con quella scala di dati e tutti mi stavano ancora accogliendo e fidando di me con migliaia di dollari di budget di calcolo cloud. Sì, dovevo svegliarmi dal sonno per controllare più volte se avevo spento quelle macchine. Di conseguenza, ho dovuto imparare sul campo attraverso tutti i tentativi ed errori, che alla fine mi hanno aperto a una nuova prospettiva che non credo avrei mai avuto se non fosse stato per BigScience.
Andando avanti, un anno dopo, sto mettendo ciò che ho imparato in BigCode, lavorando su dataset ancora più grandi. Oltre ai LLM addestrati per l’inglese [3], abbiamo confermato che la deduplicazione migliora anche i modelli di codice [4], utilizzando un dataset molto più piccolo. E ora, sto condividendo ciò che ho imparato con te, caro lettore, e spero che tu possa anche avere un’idea di ciò che sta accadendo dietro le quinte di BigCode attraverso la lente della deduplicazione.
Nel caso tu sia interessato, ecco una versione aggiornata del confronto di deduplicazione che abbiamo iniziato in BigScience:
Questa è quella per i dataset di codice che abbiamo creato anche per BigCode. I nomi dei modelli vengono utilizzati quando il nome del dataset non è disponibile.
Parametri di MinHash + LSH ( P , T , K , B , R ) (P, T, K, B, R) ( P , T , K , B , R ) :
- P P P numero di permutazioni/hash
- T T T soglia di similarità di Jaccard
- K K K dimensione degli n-grammi/shingle
- B B B numero di bande
- R R R numero di righe
Per farsi un’idea di come quei parametri possano influire sui risultati, ecco una semplice demo per illustrare il calcolo in modo matematico: Dimostrazione matematica di MinHash.
Guida passo-passo di MinHash
In questa sezione, copriremo ogni passo di MinHash, quello utilizzato in BigCode, e i potenziali problemi di scalabilità e soluzioni. Dimostreremo il flusso di lavoro attraverso un esempio di tre documenti in inglese:
Il flusso di lavoro tipico di MinHash è il seguente:
- Shingling (tokenizzazione) e fingerprinting (MinHashing), dove mappiamo ogni documento in un insieme di hash.
- Locality-sensitive hashing (LSH). Questo passaggio serve a ridurre il numero di confronti raggruppando insieme i documenti con bande simili.
- Rimozione dei duplicati. Questo passaggio è dove decidiamo quali documenti duplicati conservare o rimuovere.
Shingles
Come nella maggior parte delle applicazioni che coinvolgono il testo, dobbiamo iniziare con la tokenizzazione. Gli N-grammi, chiamati anche shingles, vengono spesso utilizzati. Nel nostro esempio, utilizzeremo trigrammi a livello di parola, senza punteggiatura. Torniamo su come la dimensione degli n-grammi influisce sulle prestazioni in una sezione successiva.
Questa operazione ha una complessità temporale di O ( N M ) \mathcal{O}(NM) O ( N M ) dove N N N è il numero di documenti e M M M è la lunghezza del documento. In altre parole, dipende linearmente dalle dimensioni dell’insieme di dati. Questo passaggio può essere facilmente scalato mediante parallelizzazione tramite multiprocessing o calcolo distribuito.
Calcolo delle Fingerprint
In MinHash, ogni shingle di solito viene 1) hashato più volte con diverse funzioni di hash, oppure 2) permuto più volte utilizzando una sola funzione di hash. Qui, scegliamo di permutare ogni hash 5 volte. Altre varianti di MinHash possono essere trovate in MinHash – Wikipedia.
Prendendo il valore minimo di ogni colonna all’interno di ogni documento – la parte “Min” del “MinHash”, otteniamo la MinHash finale per questo documento:
Tecnicamente, non è necessario utilizzare il valore minimo di ogni colonna, ma il valore minimo è la scelta più comune. Altre statistiche di ordinamento come il massimo, il k-esimo più piccolo o il k-esimo più grande possono essere utilizzate anche [21].
Nell’implementazione, è possibile vettorizzare facilmente questi passaggi con numpy e ci si può aspettare una complessità temporale di O ( N M K ) \mathcal{O}(NMK) O ( N M K ) dove K K K è il numero di permutazioni. Codice modificato sulla base di Datasketch.
def embed_func(
content: str,
idx: int,
*,
num_perm: int,
ngram_size: int,
hashranges: List[Tuple[int, int]],
permutations: np.ndarray,
) -> Dict[str, Any]:
a, b = permutations
masks: np.ndarray = np.full(shape=num_perm, dtype=np.uint64, fill_value=MAX_HASH)
tokens: Set[str] = {" ".join(t) for t in ngrams(NON_ALPHA.split(content), ngram_size)}
hashvalues: np.ndarray = np.array([sha1_hash(token.encode("utf-8")) for token in tokens], dtype=np.uint64)
permuted_hashvalues = np.bitwise_and(
((hashvalues * np.tile(a, (len(hashvalues), 1)).T).T + b) % MERSENNE_PRIME, MAX_HASH
)
hashvalues = np.vstack([permuted_hashvalues, masks]).min(axis=0)
Hs = [bytes(hashvalues[start:end].byteswap().data) for start, end in hashranges]
return {"__signatures__": Hs, "__id__": idx}Se sei familiare con Datasketch, potresti chiederti perché ci preoccupiamo di rimuovere tutte le belle funzioni di alto livello fornite dalla libreria. Non è perché vogliamo evitare di aggiungere dipendenze, ma perché intendiamo sfruttare al massimo la capacità di calcolo della CPU durante la parallelizzazione. Fondere alcuni passaggi in una sola chiamata di funzione ci consente di utilizzare meglio le risorse di calcolo.
Dato che il calcolo di un documento non dipende da nulla altro. Una buona scelta di parallelizzazione sarebbe utilizzare la funzione map della libreria datasets:
embedded = ds.map(
function=embed_func,
fn_kwargs={
"num_perm": args.num_perm,
"hashranges": HASH_RANGES,
"ngram_size": args.ngram,
"permutations": PERMUTATIONS,
},
input_columns=[args.column],
remove_columns=ds.column_names,
num_proc=os.cpu_count(),
with_indices=True,
desc="Fingerprinting...",
)Dopo il calcolo delle fingerprint, un particolare documento viene mappato su un array di valori interi. Per capire quali documenti sono simili tra loro, dobbiamo raggrupparli in base a tali fingerprint. Entriamo nella fase di Località Sensibile all’Hashing (LSH).
Località Sensibile all’Hashing
LSH suddivide l’array di fingerprint in bande, ogni banda contenente lo stesso numero di righe. Se rimangono dei valori hash, verranno ignorati. Utilizziamo b = 2 bande e r = 2 righe per raggruppare quei documenti:
Se due documenti condividono gli stessi hash in una banda in una posizione specifica (indice della banda), saranno raggruppati nello stesso bucket e saranno considerati come candidati.
Per ogni riga nella colonna doc_ids, possiamo generare coppie di candidati accoppiando ogni coppia di essi. Dalla tabella sopra possiamo generare una coppia di candidati: (0, 1).
Oltre alle coppie duplicate
Qui molte descrizioni di deduplicazione in articoli o tutorial si fermano. Rimane ancora la domanda su cosa farne. In generale, possiamo procedere con due opzioni:
- Ricontrollare le loro effettive similarità di Jaccard calcolando la sovrapposizione tra gli shingle, a causa della natura di stima di MinHash. La similarità di Jaccard di due insiemi è definita come la dimensione dell’intersezione diviso la dimensione dell’unione. E ora diventa molto più fattibile rispetto al calcolo di tutte le similarità tra coppie, perché possiamo concentrarci solo sui documenti all’interno di un cluster. Questo è anche ciò che abbiamo fatto inizialmente per BigCode, che ha funzionato abbastanza bene.
- Considerarli come veri positivi. Probabilmente hai già notato il problema qui: la similarità di Jaccard non è transitiva, il che significa che A A A è simile a B B B e B B B è simile a C C C, ma A A A e C C C non condividono necessariamente la similarità. Tuttavia, i nostri esperimenti da The Stack mostrano che considerarli tutti duplicati migliora le prestazioni del modello successivo al meglio. E ora ci stiamo gradualmente spostando verso questo metodo, che risparmia anche tempo. Ma per applicarlo al tuo dataset, raccomandiamo comunque di esaminare il dataset e osservare i duplicati, e poi prendere una decisione basata sui dati.
Dalle coppie così ottenute, che siano state validate o meno, possiamo ora costruire un grafo con quelle coppie come archi, e i duplicati saranno raggruppati in comunità o componenti connesse. Riguardo all’implementazione, sfortunatamente, qui datasets non è stato molto utile perché ora abbiamo bisogno di qualcosa come un groupby dove possiamo raggruppare i documenti in base al loro offset della banda e ai valori della banda. Ecco alcune opzioni che abbiamo provato:
Opzione 1: Iterare i dataset nel modo classico e raccogliere gli archi. Poi utilizzare una libreria di grafi per fare la rilevazione delle comunità o delle componenti connesse.
Questo non ha funzionato bene nei nostri test, e le ragioni sono molteplici. Prima di tutto, iterare l’intero dataset è lento e consuma molta memoria su larga scala. In secondo luogo, le librerie di grafi popolari come graphtool o networkx hanno molti costi aggiuntivi per la creazione del grafo.
Opzione 2: Utilizzare framework Python popolari come dask per consentire operazioni di groupby più efficienti.
Ma avrai ancora problemi di iterazione lenta e creazione lenta del grafo.
Opzione 3: Iterare il dataset, ma utilizzare una struttura dati di union-find per raggruppare i documenti.
Questo aggiunge un sovraccarico trascurabile all’iterazione e funziona relativamente bene per i dataset di VoAGI.
for table in tqdm(HASH_TABLES, dynamic_ncols=True, desc="Raggruppamento..."):
for cluster in table.values():
if len(cluster) <= 1:
continue
idx = min(cluster)
for x in cluster:
uf.union(x, idx)Opzione 4: Per dataset di grandi dimensioni, utilizzare Spark.
Sappiamo già che le fasi fino alla parte LSH possono essere parallelizzate, il che è anche possibile in Spark. Inoltre, Spark supporta groupBy distribuito di serie ed è anche semplice implementare algoritmi come [18] per la rilevazione delle componenti connesse. Se ti stai chiedendo perché non abbiamo utilizzato l’implementazione di MinHash di Spark, la risposta è che finora tutti i nostri esperimenti derivano da Datasketch, che utilizza un’implementazione completamente diversa rispetto a Spark, e vogliamo assicurarci di continuare a trarre vantaggio dalle lezioni e dagli approfondimenti appresi da esso senza entrare in un altro labirinto di esperimenti di ablation.
edges = (
records.flatMap(
lambda x: generate_hash_values(
content=x[1],
idx=x[0],
num_perm=args.num_perm,
ngram_size=args.ngram_size,
hashranges=HASH_RANGES,
permutations=PERMUTATIONS,
)
)
.groupBy(lambda x: (x[0], x[1]))
.flatMap(lambda x: generate_edges([i[2] for i in x[1]]))
.distinct()
.cache()
)Un semplice algoritmo di componente connessa basato su [18] implementato in Spark.
a = edges
while True:
b = a.flatMap(large_star_map).groupByKey().flatMap(large_star_reduce).distinct().cache()
a = b.map(small_star_map).groupByKey().flatMap(small_star_reduce).distinct().cache()
changes = a.subtract(b).union(b.subtract(a)).collect()
if len(changes) == 0:
break
results = a.collect()Inoltre, grazie ai provider di cloud, possiamo configurare facilmente cluster Spark come una brezza con servizi come GCP DataProc. Alla fine, possiamo eseguire il programma per eliminare la duplicazione di 1.4 TB di dati in meno di 4 ore con un budget di $15 all’ora.
La qualità conta
Salire su una scala non ci porta sulla luna. Ecco perché dobbiamo assicurarci che questa sia la direzione giusta e che la stiamo utilizzando nel modo corretto.
All’inizio, i nostri parametri sono stati in gran parte ereditati dagli esperimenti di CodeParrot, e il nostro esperimento di ablazione ha indicato che queste impostazioni hanno migliorato le prestazioni del modello a valle [16]. Abbiamo quindi iniziato ad esplorare ulteriormente questa strada e possiamo confermare che [4]:
- La deduplicazione parziale migliora le prestazioni del modello con un dataset molto più piccolo (6 TB VS. 3 TB)
- Non abbiamo ancora individuato il limite, ma una deduplicazione più aggressiva (6 TB VS. 2.4 TB) può migliorare ulteriormente le prestazioni:
- Riduci la soglia di similarità
- Aumenta la dimensione dello shingle (unigramma → 5-grammi)
- Elimina il controllo dei falsi positivi perché possiamo permetterci di perdere una piccola percentuale di falsi positivi
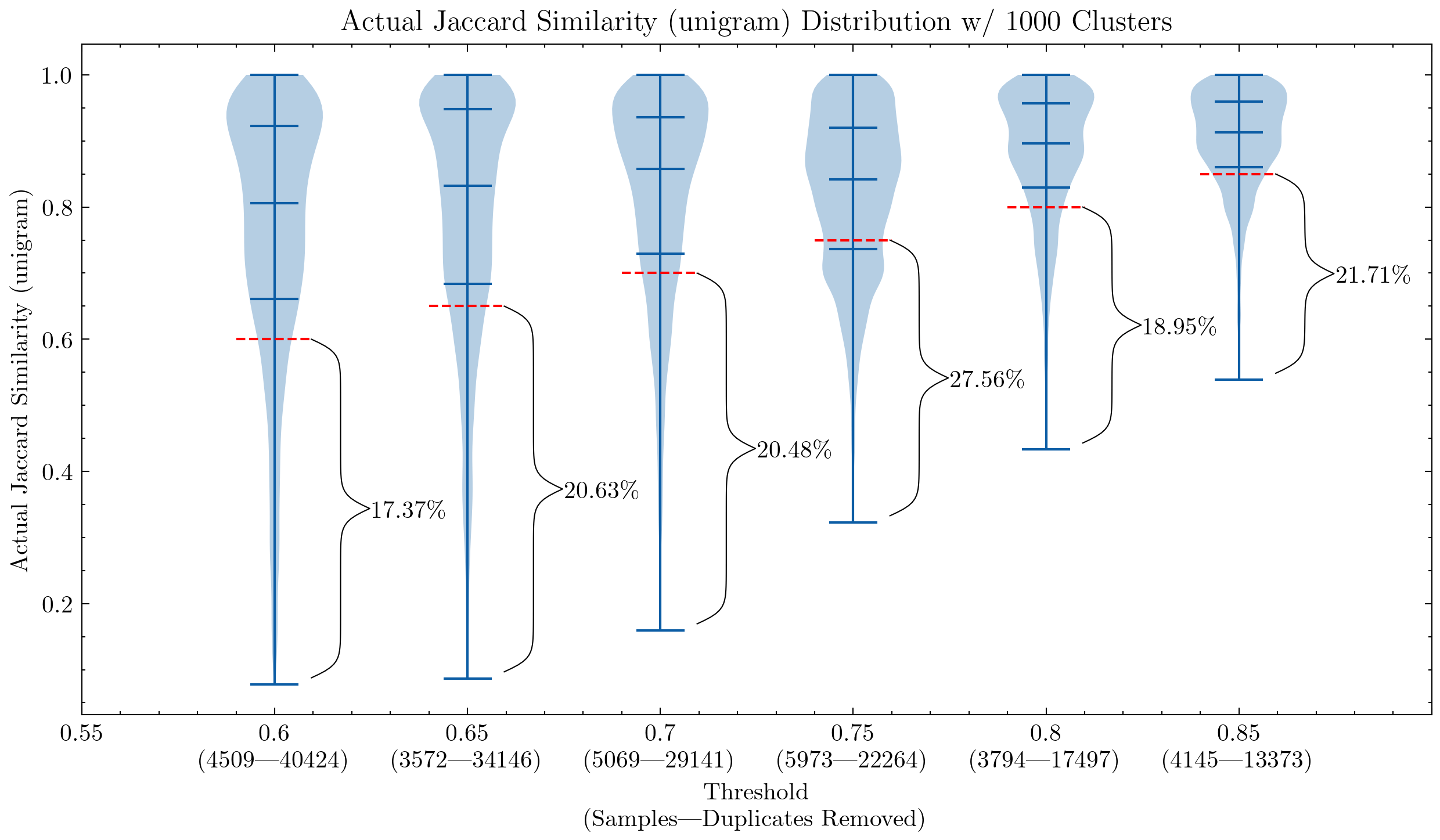
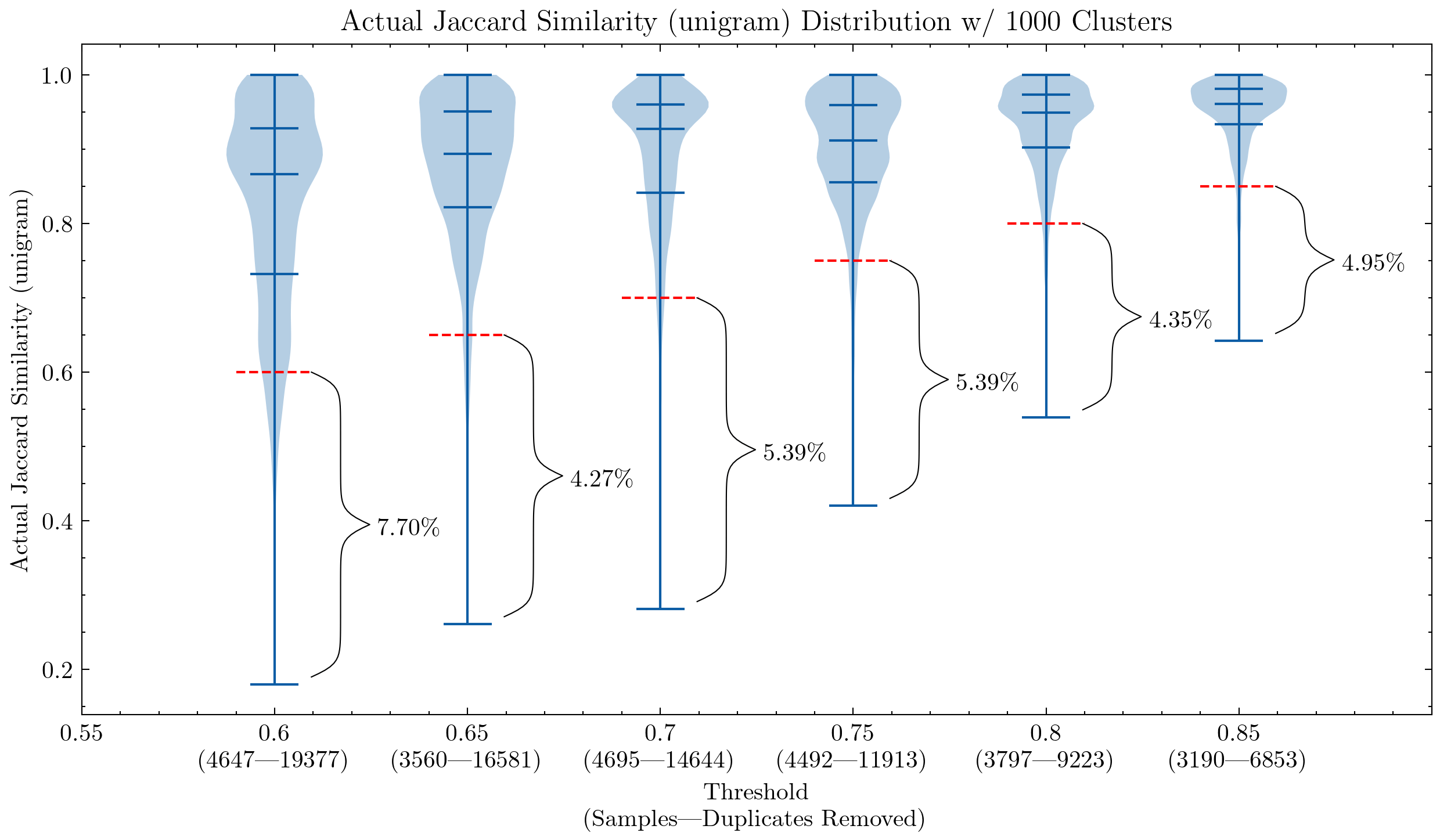
Immagine: Due grafici che mostrano l’impatto della soglia di similarità e della dimensione dello shingle, il primo utilizza unigrammi e il secondo 5-grammi. La linea tratteggiata rossa rappresenta la soglia di similarità: i documenti al di sotto di essa vengono considerati falsi positivi, le loro similarità con altri documenti all’interno di un cluster sono inferiori alla soglia.
Questi grafici ci aiutano a capire perché era necessario controllare nuovamente i falsi positivi per CodeParrot e la versione precedente di Stack: l’utilizzo di unigrammi crea molti falsi positivi; dimostrano anche che aumentando la dimensione dello shingle a 5-grammi, la percentuale di falsi positivi diminuisce significativamente. Una soglia più piccola è desiderabile se vogliamo mantenere l’aggressività della deduplicazione.
Ulteriori esperimenti hanno anche dimostrato che riducendo la soglia si rimuovono più documenti che hanno coppie ad alta similarità, aumentando quindi il richiamo nel segmento che vogliamo effettivamente rimuovere di più.
Scaling
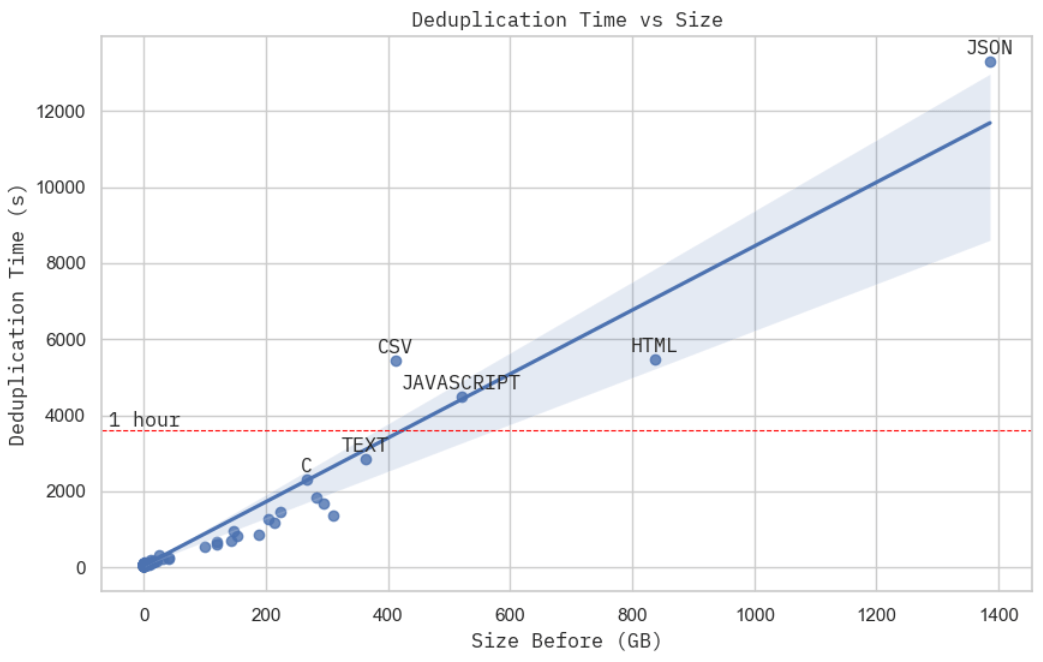
Immagine: Tempo di deduplicazione rispetto alla dimensione del dataset grezzo. Questo è stato ottenuto con 15 macchine c2d-standard-16 su GCP, e ognuna ha avuto un costo di circa $0.7 all’ora.

Immagine: Schermata dell’utilizzo della CPU per il cluster durante l’elaborazione del dataset JSON.
Questo non è la prova di scaling più rigorosa che si possa trovare, ma il tempo di deduplicazione, dato un budget di calcolo fisso, sembra praticamente lineare rispetto alla dimensione fisica del dataset. Quando si osserva più da vicino l’utilizzo delle risorse del cluster durante l’elaborazione del dataset JSON, il subset più grande in Stack, si può notare che MinHash + LSH (stadio 2) ha dominato il tempo totale di calcolo reale (stadio 2 + 3), che secondo la nostra analisi precedente è O(NM) – lineare rispetto al volume fisico del dataset.
Procedi con cautela
La deduplicazione non ti esenta dall’esplorazione e dall’analisi approfondite dei dati. Inoltre, queste scoperte sulla deduplicazione sono valide per Stack, ma ciò non significa che siano applicabili facilmente ad altri dataset o altre lingue. È un buon primo passo verso la creazione di un dataset migliore, e ulteriori indagini come il filtraggio della qualità dei dati (ad esempio, vulnerabilità, tossicità, pregiudizi, modelli generati, informazioni personali identificabili) sono ancora molto necessarie.
Continuiamo a incoraggiarti a eseguire analisi simili sui tuoi set di dati prima dell’addestramento. Ad esempio, potrebbe non essere molto utile fare la deduplicazione se hai un budget di tempo e calcolo limitato: @geiping_2022 afferma che la deduplicazione delle sottostringhe non ha migliorato le prestazioni del loro modello. Anche i set di dati esistenti potrebbero richiedere una minuziosa esaminazione prima dell’uso, ad esempio, @gao_2020 afferma che si sono solo assicurati che il Pile stesso, insieme alle sue divisioni, siano stati deduplicati, e che non deduplicano proattivamente per eventuali benchmark successivi, lasciando quella decisione ai lettori.
Riguardo alla fuga di dati e alla contaminazione dei benchmark, c’è ancora molto da esplorare. Abbiamo dovuto riaddestrare i nostri modelli di codice perché HumanEval è stato pubblicato in uno dei repository GitHub in Python. I primi risultati della quasi deduplicazione suggeriscono anche che MBPP [19], uno dei benchmark più popolari per la programmazione, condivide molte somiglianze con molti problemi Leetcode (ad esempio, il task 601 in MBPP è praticamente Leetcode 646, il task 604 ≃ Leetcode 151). E sappiamo tutti che GitHub non è privo di tali sfide di programmazione e soluzioni. Sarà ancora più difficile se qualcuno con cattive intenzioni carica tutti i benchmark sotto forma di script Python, o in altri modi meno ovvi, e inquina tutti i tuoi dati di addestramento.
Prospettive future
- Deduplicazione delle sottostringhe. Anche se ha mostrato alcuni benefici per l’inglese [3], non è ancora chiaro se questo dovrebbe essere applicato anche ai dati di codice;
- Ripetizione: paragrafi ripetuti più volte in un documento. @rae_2021 ha condiviso alcuni euristici interessanti su come rilevarli e rimuoverli.
- Utilizzo di embedding del modello per la deduplicazione semantica. Si tratta di un’altra intera questione di ricerca con scaling, costi, esperimenti di ablazione e trade-off con la quasi deduplicazione. Ci sono alcune prese affascinanti su questo [20], ma abbiamo ancora bisogno di prove più situate per trarre una conclusione (ad esempio, l’unico riferimento di deduplicazione del testo di @abbas_2023 è @lee_2022a, la cui principale affermazione è che la deduplicazione aiuta invece di cercare di essere SOTA).
- Ottimizzazione. C’è sempre spazio per l’ottimizzazione: migliore valutazione della qualità, scaling, analisi dell’impatto sulle prestazioni successive, ecc.
- Poi c’è un’altra direzione per guardare le cose: fino a che punto la quasi deduplicazione inizia a danneggiare le prestazioni? In che misura la similarità è necessaria per la diversità anziché considerarla come ridondanza?
Crediti
L’immagine del banner contiene emoji (faccina che abbraccia, Babbo Natale, documento, mago e bacchetta) da Noto Emoji (Apache 2.0). Questo post sul blog è stato scritto con orgoglio senza l’utilizzo di API generative.
Grazie enormi a Huu Nguyen @Huu e Hugo Laurençon @HugoLaurencon per la collaborazione in BigScience e a tutti in BigCode per l’aiuto lungo il percorso! Se trovi qualche errore, sentiti libero di contattarmi: mouchenghao at gmail dot com.
Risorse di supporto
- Datasketch (MIT)
- simhash-py e simhash-cpp (MIT)
- Deduplicating Training Data Makes Language Models Better (Apache 2.0)
- Gaoya (MIT)
- BigScience (Apache 2.0)
- BigCode (Apache 2.0)
Riferimenti
- [1]: Nikhil Kandpal, Eric Wallace, Colin Raffel, Deduplicating Training Data Mitigates Privacy Risks in Language Models, 2022
- [2]: Gowthami Somepalli, et al., Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models, 2022
- [3]: Katherine Lee, Daphne Ippolito, et al., Deduplicating Training Data Makes Language Models Better, 2022
- [4]: Loubna Ben Allal, Raymond Li, et al., SantaCoder: Non puntare alle stelle!, 2023
- [5]: Leo Gao, Stella Biderman, et al., The Pile: Un dataset di 800 GB di testi diversi per il language modeling, 2020
- [6]: Asier Gutiérrez-Fandiño, Jordi Armengol-Estapé, et al., MarIA: Modelli di lingua spagnoli, 2022
- [7]: Jack W. Rae, Sebastian Borgeaud, et al., Scaling Language Models: Metodi, Analisi e Approfondimenti da Training Gopher, 2021
- [8]: Xi Victoria Lin, Todor Mihaylov, et al., Apprendimento a poche istanze con modelli di linguaggio multilingue, 2021
- [9]: Hugo Laurençon, Lucile Saulnier, et al., The BigScience ROOTS Corpus: Un dataset composito multilingue di 1,6 TB, 2022
- [10]: Daniel Fried, Armen Aghajanyan, et al., InCoder: Un modello generativo per l’infilling e la sintesi del codice, 2022
- [11]: Erik Nijkamp, Bo Pang, et al., CodeGen: Un grande modello di linguaggio aperto per il codice con sintesi di programmi multi-turno, 2023
- [12]: Yujia Li, David Choi, et al., Generazione di codice di livello di competizione con AlphaCode, 2022
- [13]: Frank F. Xu, Uri Alon, et al., Una valutazione sistematica dei grandi modelli di linguaggio del codice, 2022
- [14]: Aakanksha Chowdhery, Sharan Narang, et al., PaLM: Scaling Language Modeling con Pathways, 2022
- [15]: Lewis Tunstall, Leandro von Werra, Thomas Wolf, Elaborazione del linguaggio naturale con Transformers, Edizione rivista, 2022
- [16]: Denis Kocetkov, Raymond Li, et al., The Stack: 3 TB di codice sorgente con licenza permissiva, 2022
- [17]: Rocky | Project Hail Mary Wiki | Fandom
- [18]: Raimondas Kiveris, Silvio Lattanzi, et al., Componenti connesse in MapReduce e oltre, 2014
- [19]: Jacob Austin, Augustus Odena, et al., Program Synthesis with Large Language Models, 2021
- [20]: Amro Abbas, Kushal Tirumala, et al., SemDeDup: Apprendimento efficiente dei dati su larga scala attraverso la deduplicazione semantica, 2023
- [21]: Edith Cohen, MinHash Sketches: Una breve panoramica, 2016




