Il Falcon è atterrato nell’ecosistema di Hugging Face
Il Falcon è arrivato su Hugging Face.
Introduzione
Falcon è una nuova famiglia di modelli linguistici all’avanguardia creati dal Technology Innovation Institute di Abu Dhabi e rilasciati con licenza Apache 2.0. In particolare, Falcon-40B è il primo modello “veramente aperto” con capacità che possono competere con molti modelli closed-source attuali. Questa è una fantastica notizia per i professionisti, gli appassionati e l’industria, poiché apre la porta a molti casi d’uso interessanti.
In questo blog, esploreremo a fondo i modelli Falcon: discuteremo innanzitutto ciò che li rende unici e poi mostreremo quanto sia facile costruire su di essi (inferenza, quantizzazione, fine-tuning e altro ancora) con gli strumenti dell’ecosistema Hugging Face.
Indice
- I modelli Falcon
- Demo
- Inferenza
- Valutazione
- Fine-tuning con PEFT
- Conclusioni
I modelli Falcon
La famiglia Falcon è composta da due modelli di base: Falcon-40B e il suo fratellino Falcon-7B. Il modello a 40B di parametri è attualmente in cima alla classifica dell’Open LLM Leaderboard, mentre il modello a 7B è il migliore nella sua categoria di peso.
Falcon-40B richiede circa 90 GB di memoria GPU, che è molto, ma comunque meno di LLaMA-65B, che Falcon supera. D’altra parte, Falcon-7B ha bisogno solo di circa 15 GB, rendendo inferenza e fine-tuning accessibili anche su hardware per consumatori. (Più avanti in questo blog, discuteremo di come possiamo sfruttare la quantizzazione per rendere Falcon-40B accessibile anche su GPU più economiche!)
- Benvenuti a fastText nell’Hugging Face Hub
- DuckDB analizza oltre 50.000 dataset archiviati nell’Hugging Face Hub
- Il Hugging Face Hub per Gallerie, Biblioteche, Archivi e Musei
TII ha reso disponibili anche versioni “instruct” dei modelli, Falcon-7B-Instruct e Falcon-40B-Instruct. Queste varianti sperimentali sono state sottoposte a fine-tuning su istruzioni e dati conversazionali; si adattano quindi meglio a compiti popolari di tipo assistente. Se stai solo cercando di giocare rapidamente con i modelli, sono la scelta migliore. È anche possibile creare la propria versione “instruct” personalizzata, basandosi sulla moltitudine di dataset creati dalla comunità: continua a leggere per un tutorial passo-passo!
Falcon-7B e Falcon-40B sono stati addestrati rispettivamente su 1,5 trilioni e 1 trilione di token, in linea con i modelli moderni ottimizzati per l’inferenza. Il fattore chiave per l’alta qualità dei modelli Falcon è il loro training data, basato prevalentemente (>80%) su RefinedWeb, un nuovo massiccio dataset web basato su CommonCrawl. Invece di raccogliere fonti curate sparse, TII si è concentrato sulla scalabilità e sul miglioramento della qualità dei dati web, sfruttando una deduplicazione su larga scala e un rigido filtraggio per raggiungere la qualità di altri corpora. I modelli Falcon includono ancora alcune fonti curate nel loro addestramento (come dati conversazionali da Reddit), ma significativamente meno rispetto a quanto è stato comune per gli LLM all’avanguardia come GPT-3 o PaLM. La parte migliore? TII ha rilasciato pubblicamente una versione estratta di 600 miliardi di token di RefinedWeb per la comunità da utilizzare nei propri LLM!
Un’altra caratteristica interessante dei modelli Falcon è l’uso dell’attenzione multiquery. Lo schema di attenzione multihead di base ha una query, una chiave e un valore per ogni head; l’attenzione multiquery invece condivide una chiave e un valore tra tutte le head.
Questo trucco non influenza significativamente il pretraining, ma migliora notevolmente la scalabilità dell’inferenza: infatti, la cache K,V mantenuta durante la decodifica autoregressiva è ora significativamente più piccola (10-100 volte a seconda dei dettagli specifici dell’architettura), riducendo i costi di memoria e consentendo nuove ottimizzazioni come la statefulness.
* punteggio dalla versione base non disponibile, riportiamo invece la versione sintonizzata.
Puoi facilmente provare il Big Falcon Model (40 miliardi di parametri!) in questo Space o nel playground incorporato qui sotto:
Sotto il cofano, questo playground utilizza Hugging Face’s Text Generation Inference, un server scalabile Rust, Python e gRPC per la generazione di testi veloce ed efficiente. È la stessa tecnologia che alimenta HuggingChat.
Abbiamo anche creato una versione Core ML del modello instruct 7B, ed è così che funziona su un MacBook Pro M1:
Video: Falcon 7B Instruct in esecuzione su un MacBook Pro M1 con Core ML.
Il video mostra un’app leggera che sfrutta una libreria Swift per il lavoro pesante: caricamento del modello, tokenizzazione, preparazione dell’input, generazione e decodifica. Stiamo lavorando per creare questa libreria per permettere agli sviluppatori di integrare potenti LLM in tutti i tipi di applicazioni senza dover reinventare la ruota. È ancora un po’ grezza, ma non vediamo l’ora di condividerla con voi. Nel frattempo, puoi scaricare i pesi Core ML dal repository ed esplorarli tu stesso!
Puoi utilizzare le familiari API dei transformers per eseguire i modelli sul tuo hardware, ma devi prestare attenzione a un paio di dettagli:
- I modelli sono stati addestrati utilizzando il tipo di dato
bfloat16, quindi ti raccomandiamo di utilizzare lo stesso. Ciò richiede una versione recente di CUDA e funziona meglio su schede moderne. Puoi anche provare a eseguire l’inferenza utilizzando il tipo di datofloat16, ma tieni presente che i modelli sono stati valutati utilizzando il tipo di datobfloat16. - È necessario consentire l’esecuzione del codice remoto. Ciò è dovuto al fatto che i modelli utilizzano un’architettura nuova che non fa ancora parte dei
transformers– invece, il codice necessario è fornito dagli autori del modello nel repository. In particolare, questi sono i file il cui codice verrà utilizzato se consenti l’esecuzione remota (utilizzandofalcon-7b-instructcome esempio): configuration_RW.py, modelling_RW.py.
Con queste considerazioni, puoi utilizzare l’API del transformers pipeline per caricare il modello di istruzioni 7B in questo modo:
from transformers import AutoTokenizer
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)E quindi, puoi eseguire la generazione di testo utilizzando un codice simile al seguente:
sequences = pipeline(
"Scrivi una poesia su Valencia.",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Risultato: {seq['generated_text']}")E potresti ottenere qualcosa del genere:
Valencia, città del sole
La città che brilla come una stella
Una città dai mille colori
Dove la notte è illuminata dalle stelle
Valencia, la città del mio cuore
Dove il passato è custodito in un baule doratoInferenza di Falcon 40B
L’esecuzione del modello 40B è impegnativa a causa delle sue dimensioni: non si adatta a una singola A100 con 80 GB di RAM. Caricando in modalità a 8 bit, è possibile eseguirlo con circa 45 GB di RAM, che si adatta a un A6000 (48 GB) ma non alla versione da 40 GB della A100. Ecco come puoi farlo:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-40b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_8bit=True,
device_map="auto",
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)Tuttavia, nota che l’inferenza a 8 bit misti utilizzerà torch.float16 invece di torch.bfloat16, quindi assicurati di testare accuratamente i risultati.
Se hai più schede e accelerate installato, puoi sfruttare device_map="auto" per distribuire automaticamente i livelli del modello su varie schede. Può anche spostare alcuni livelli sulla CPU se necessario, ma ciò influirà sulla velocità di inferenza.
C’è anche la possibilità di utilizzare il caricamento a 4 bit utilizzando l’ultima versione di bitsandbytes, transformers e accelerate. In questo caso, il modello 40B richiede ~27 GB di RAM per l’esecuzione. Purtroppo, questa quantità è leggermente superiore alla memoria disponibile in schede come 3090 o 4090, ma è sufficiente per eseguirlo su schede da 30 o 40 GB.
Inferenza di Generazione di Testo
L’inferenza di generazione di testo è un contenitore di inferenza pronto per la produzione sviluppato da Hugging Face per consentire un facile dispiegamento di modelli di linguaggio di grandi dimensioni.
Le sue principali caratteristiche sono:
- Batching continuo
- Streaming di token utilizzando Server-Sent Events (SSE)
- Parallelismo dei tensori per una velocità di inferenza più rapida su più GPU
- Code transformers ottimizzate utilizzando kernel CUDA personalizzati
- Logging, monitoraggio e tracciamento pronti per la produzione con Prometheus e Open Telemetry
Dalla versione v0.8.2, l’Inferenza di Generazione di Testo supporta nativamente i modelli Falcon 7b e 40b senza dipendere dalla funzionalità di “affidamento al codice remoto” dei Transformers, consentendo implementazioni ermetiche e audit di sicurezza. Inoltre, l’implementazione di Falcon include kernel CUDA personalizzati per ridurre significativamente la latenza end-to-end.
L’Inferenza di Generazione di Testo è ora integrata all’interno dei Punti di Inference di Hugging Face. Per distribuire un modello Falcon, vai alla pagina del modello e fai clic sul widget Deploy -> Inference Endpoints.
Per i modelli 7B, ti consigliamo di selezionare “GPU [VoAGI] – 1x Nvidia A10G”.
Per i modelli 40B, dovrai distribuirli su “GPU [xlarge] – 1x Nvidia A100” e attivare la quantizzazione: Configurazione avanzata -> Contenitore di servizio -> Quantizzazione Int-8. Nota: Potrebbe essere necessario richiedere un aumento della quota tramite email a [email protected]
Valutazione
Quindi quanto sono buoni i modelli Falcon? Una valutazione approfondita degli autori di Falcon sarà pubblicata a breve, quindi nel frattempo abbiamo eseguito entrambi i modelli base e instruct attraverso il nostro benchmark LLM aperto. Questo benchmark misura sia le capacità di ragionamento degli LLM che la loro capacità di fornire risposte veritiere nei seguenti domini:
- AI2 Reasoning Challenge (ARC): Domande scientifiche a scelta multipla per la scuola elementare.
- HellaSwag: Ragionamento di buon senso sugli eventi quotidiani.
- MMLU: Domande a scelta multipla in 57 materie (professionali e accademiche).
- TruthfulQA: Testa l’abilità del modello di separare i fatti da un insieme di affermazioni errate selezionate in modo avversario.
I risultati mostrano che i modelli base e instruct da 40B sono molto solidi e attualmente occupano il 1° e il 2° posto nella classifica LLM 🏆!
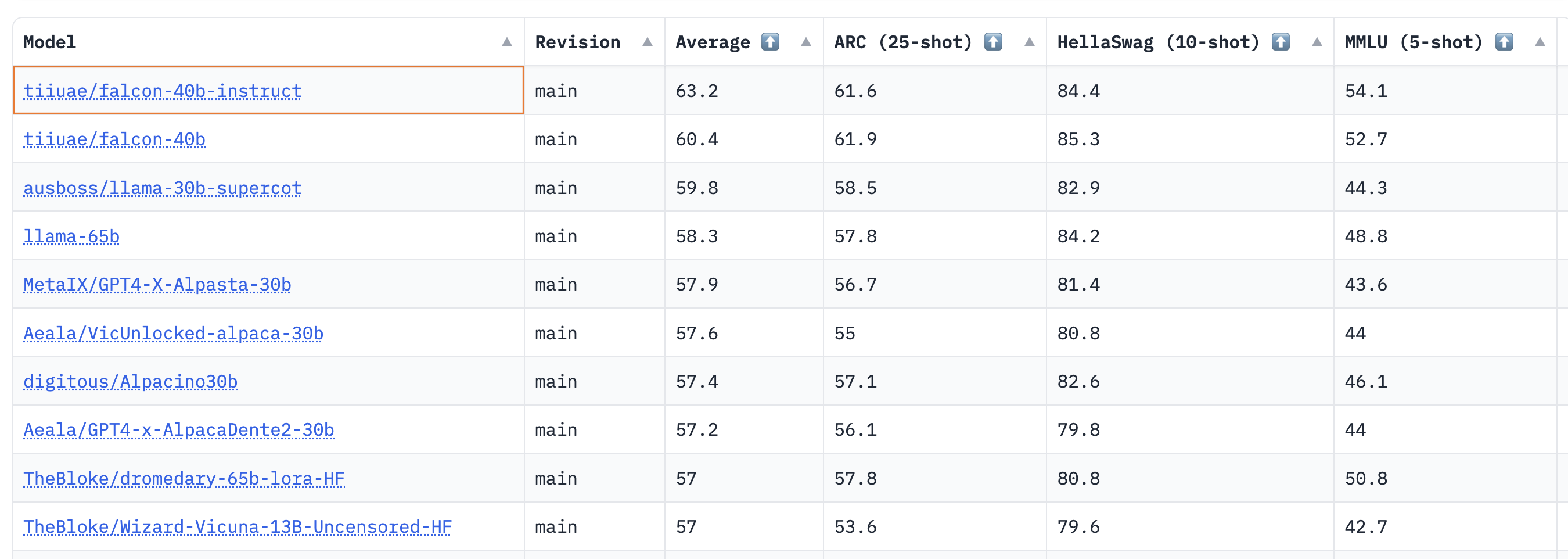
Come osservato da Thomas Wolf, una sorprendente intuizione qui è che i modelli da 40B sono stati preaddestrati utilizzando circa la metà del calcolo necessario per LLaMa 65B (2800 vs 6300 petaflop-giorni), il che suggerisce che non abbiamo ancora raggiunto i limiti di ciò che è “ottimale” per il preaddestramento degli LLM.
Per i modelli 7B, vediamo che il modello base è migliore di llama-7b e supera il modello mpt-7b di MosaicML diventando il miglior LLM preaddestrato attuale a questa scala. Di seguito è riportato un elenco ridotto dei modelli popolari dalla classifica per confronto:
Sebbene la classifica LLM aperta non misuri le capacità di chat (dove la valutazione umana è lo standard aureo), questi risultati preliminari per i modelli Falcon sono molto incoraggianti!
Ora vediamo come puoi effettuare il fine-tuning dei tuoi modelli Falcon – magari uno dei tuoi finirà in cima alla classifica 🤗.
Fine-tuning con PEFT
Addestrare modelli di dimensioni superiori a 10B può essere tecnicamente e computazionalmente impegnativo. In questa sezione esamineremo gli strumenti disponibili nell’ecosistema di Hugging Face per addestrare in modo efficiente modelli estremamente grandi su hardware semplice e mostreremo come effettuare il fine-tuning del Falcon-7b su una singola NVIDIA T4 (16GB – Google Colab).
Vediamo come possiamo addestrare Falcon sul dataset Guanaco, un sottoinsieme di alta qualità del dataset Open Assistant composto da circa 10.000 dialoghi. Con la libreria PEFT possiamo utilizzare l’approccio QLoRA recente per effettuare il fine-tuning degli adapter che vengono posizionati sopra il modello a 4 bit congelato. Puoi saperne di più sull’integrazione dei modelli quantizzati a 4 bit in questo post del blog.
Poiché solo una piccola frazione del modello è addestrabile quando si utilizzano gli Adattatori a Rango Ridotto (LoRA), sia il numero di parametri appresi che la dimensione dell’artefatto addestrato vengono drasticamente ridotti. Come mostrato nella schermata sottostante, il modello salvato ha solo 65MB per il modello con 7B di parametri (15GB in float16).
Nello specifico, dopo aver selezionato i moduli di destinazione da adattare (in pratica i livelli di query/chiave del modulo di attenzione), vengono collegati piccoli strati lineari addestrabili vicino a questi moduli come illustrato di seguito). Gli stati nascosti prodotti dagli adapter vengono quindi aggiunti agli stati originali per ottenere lo stato nascosto finale.
Una volta addestrato, non è necessario salvare l’intero modello in quanto il modello base è stato mantenuto congelato. Inoltre, è possibile mantenere il modello in qualsiasi tipo di dato arbitrario (int8, fp4, fp16, ecc.), a condizione che gli stati nascosti di output di questi moduli siano convertiti nello stesso tipo di dato degli stati dell’adapter – questo è il caso dei moduli bitsandbytes (Linear8bitLt e Linear4bit) che restituiscono stati nascosti con lo stesso tipo di dato del modulo non quantizzato originale.
Abbiamo ottimizzato i due varianti dei modelli di Falcon (7B e 40B) sul dataset di Guanaco. Abbiamo ottimizzato il modello 7B su una singola NVIDIA-T4 16GB e il modello 40B su una singola NVIDIA A100 80GB. Abbiamo utilizzato modelli di base quantizzati a 4 bit e il metodo QLoRA, così come il recente SFTTrainer dalla libreria TRL.
Lo script completo per riprodurre i nostri esperimenti utilizzando PEFT è disponibile qui , ma solo poche righe di codice sono necessarie per eseguire rapidamente il SFTTrainer (senza PEFT per semplicità):
from datasets import load_dataset
from trl import SFTTrainer
from transformers import AutoTokenizer, AutoModelForCausalLM
dataset = load_dataset("imdb", split="train")
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True)
trainer = SFTTrainer(
model,
tokenizer=tokenizer
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()Consulta il repository originale di qlora per ulteriori dettagli sulla valutazione dei modelli addestrati.
Risorse per la messa a punto
- Notebook Colab per la messa a punto di Falcon-7B sul dataset di Guanaco utilizzando 4 bit e PEFT
- Codice di addestramento
- Adattatori del modello 40B ( log )
- Adattatori del modello 7B ( log )
Conclusione
Falcon è un nuovo ed entusiasmante modello di linguaggio di grandi dimensioni che può essere utilizzato per applicazioni commerciali. In questo post del blog abbiamo mostrato le sue capacità, come eseguirlo nel proprio ambiente e quanto sia facile metterlo a punto utilizzando dati personalizzati all’interno dell’ecosistema di Hugging Face. Siamo entusiasti di vedere cosa la comunità costruirà con esso!






