Sì, i Transformers sono efficaci per la previsione delle serie temporali (+ Autoformer)
I Transformers sono efficaci per le serie temporali (+ Autoformer).
![]()
Introduzione
Alcuni mesi fa, abbiamo presentato il modello Informer (Zhou, Haoyi, et al., 2021), che è un Time Series Transformer che ha vinto il premio come migliore articolo alla AAAI 2021. Abbiamo anche fornito un esempio di previsione probabilistica multivariata con Informer. In questo post, discuteremo la domanda: I Transformers sono efficaci per la previsione delle serie temporali? (AAAI 2023). Come vedremo, lo sono.
In primo luogo, forniremo prove empiriche che i Transformers sono effettivamente efficaci per la previsione delle serie temporali. Il nostro confronto mostra che il semplice modello lineare, noto come DLinear, non è migliore dei Transformers come dichiarato. Quando confrontati con modelli di dimensioni equivalenti nello stesso contesto dei modelli lineari, i modelli basati su Transformer si comportano meglio sulle metriche dell’insieme di test che consideriamo. Successivamente, presenteremo il modello Autoformer (Wu, Haixu, et al., 2021), che è stato pubblicato in NeurIPS 2021 dopo il modello Informer. Il modello Autoformer è ora disponibile in 🤗 Transformers. Infine, discuteremo il modello DLinear, che è una semplice rete feedforward che utilizza il layer di decomposizione di Autoformer. Il modello DLinear è stato introdotto per la prima volta in Are Transformers Effective for Time Series Forecasting? e sosteneva di superare i modelli basati su Transformer nella previsione delle serie temporali.
Andiamo!
- Politica di AI @🤗 Risposta alla richiesta di commenti sulla responsabilità dell’AI dell’NTIA degli Stati Uniti.
- Ottimizza i modelli di adattatore MMS per ASR a bassa risorsa
- Pannello su Hugging Face
Benchmarking – Transformers vs. DLinear
Nell’articolo Are Transformers Effective for Time Series Forecasting?, pubblicato di recente alla AAAI 2023, gli autori sostengono che i Transformers non siano efficaci per la previsione delle serie temporali. Confrontano i modelli basati su Transformer con un semplice modello lineare, che chiamano DLinear. Il modello DLinear utilizza il layer di decomposizione del modello Autoformer, che presenteremo più avanti in questo post. Gli autori sostengono che il modello DLinear superi i modelli basati su Transformer nella previsione delle serie temporali. È vero? Scopriamolo.
La tabella sopra mostra i risultati del confronto tra i modelli Autoformer e DLinear sui tre dataset utilizzati nell’articolo. I risultati mostrano che il modello Autoformer supera il modello DLinear su tutti e tre i dataset.
Successivamente, presenteremo il nuovo modello Autoformer insieme al modello DLinear. Mostreremo come confrontarli sul dataset Traffic della tabella sopra e forniremo spiegazioni per i risultati ottenuti.
TL;DR: Un semplice modello lineare, sebbene vantaggioso in alcuni casi, non ha la capacità di incorporare covariate rispetto a modelli più complessi come i transformers nell’ambito univariato.
Autoformer – Sotto il cofano
Autoformer si basa sul metodo tradizionale di scomposizione delle serie temporali in componenti di stagionalità e ciclo di tendenza. Questo viene realizzato tramite l’incorporazione di un layer di decomposizione, che migliora la capacità del modello di catturare accuratamente queste componenti. Inoltre, Autoformer introduce un innovativo meccanismo di autocorrelazione che sostituisce l’attenzione standard self-attention utilizzata nel transformer classico. Questo meccanismo consente al modello di utilizzare dipendenze basate sul periodo nell’attenzione, migliorando così le prestazioni complessive.
Nelle sezioni successive, approfondiremo i due contributi chiave di Autoformer: il layer di decomposizione e il meccanismo di attenzione (autocorrelazione). Forniremo anche esempi di codice per illustrare come queste componenti funzionano all’interno dell’architettura di Autoformer.
Layer di Decomposizione
La decomposizione è da tempo un metodo popolare nell’analisi delle serie temporali, ma non era stata ampiamente incorporata nei modelli di deep learning fino all’introduzione dell’articolo su Autoformer. Dopo una breve spiegazione del concetto, mostreremo come l’idea viene applicata in Autoformer utilizzando il codice PyTorch.
Scomposizione delle Serie Temporali
Nell’analisi delle serie temporali, la decomposizione è un metodo di suddivisione di una serie temporale in tre componenti sistematiche: ciclo di tendenza, variazione stagionale e fluttuazioni casuali. La componente di tendenza rappresenta la direzione a lungo termine della serie temporale, che può essere crescente, decrescente o stabile nel tempo. La componente stagionale rappresenta i pattern ricorrenti che si verificano all’interno della serie temporale, come cicli annuali o trimestrali. Infine, la componente casuale (talvolta chiamata “irregolare”) rappresenta il rumore casuale nei dati che non può essere spiegato dalle componenti di tendenza o stagionali.
I due principali tipi di decomposizione sono la decomposizione additiva e la decomposizione moltiplicativa, che sono implementate nella libreria statsmodels. Scomponendo una serie temporale in queste componenti, possiamo comprendere e modellare meglio i pattern sottostanti nei dati.
Ma come possiamo incorporare la decomposizione nell’architettura Transformer? Vediamo come lo fa Autoformer.
Decomposizione in Autoformer
Autoformer incorpora un blocco di decomposizione come operazione interna del modello, come presentato nell’architettura di Autoformer sopra. Come si può vedere, l’encoder e il decoder utilizzano un blocco di decomposizione per aggregare la parte tendenziale-ciclica ed estrarre progressivamente la parte stagionale dalla serie. Il concetto di decomposizione interna ha dimostrato la sua utilità fin dalla pubblicazione di Autoformer. Successivamente, è stato adottato in diversi altri articoli sulle serie temporali, come FEDformer (Zhou, Tian, et al., ICML 2022) e DLinear (Zeng, Ailing, et al., AAAI 2023), evidenziando la sua importanza nella modellazione delle serie temporali.
Ora definiamo formalmente il livello di decomposizione:
Per una serie di input X ∈ R L × d \mathcal{X} \in \mathbb{R}^{L \times d} X ∈ R L × d con lunghezza L L L, il livello di decomposizione restituisce X trend , X seasonal \mathcal{X}_\textrm{trend}, \mathcal{X}_\textrm{seasonal} X trend , X seasonal definiti come segue:
X trend = AvgPool(Padding( X )) X seasonal = X − X trend \mathcal{X}_\textrm{trend} = \textrm{AvgPool(Padding(} \mathcal{X} \textrm{))} \\ \mathcal{X}_\textrm{seasonal} = \mathcal{X} – \mathcal{X}_\textrm{trend} X trend = AvgPool(Padding( X )) X seasonal = X − X trend
E l’implementazione in PyTorch:
import torch
from torch import nn
class DecompositionLayer(nn.Module):
"""
Restituisce le parti trend e seasonal della serie temporale.
"""
def __init__(self, kernel_size):
super().__init__()
self.kernel_size = kernel_size
self.avg = nn.AvgPool1d(kernel_size=kernel_size, stride=1, padding=0) # moving average
def forward(self, x):
"""Input shape: Batch x Time x EMBED_DIM"""
# padding su entrambe le estremità della serie temporale
num_of_pads = (self.kernel_size - 1) // 2
front = x[:, 0:1, :].repeat(1, num_of_pads, 1)
end = x[:, -1:, :].repeat(1, num_of_pads, 1)
x_padded = torch.cat([front, x, end], dim=1)
# calcola la parte trend e la parte stagionale della serie
x_trend = self.avg(x_padded.permute(0, 2, 1)).permute(0, 2, 1)
x_seasonal = x - x_trend
return x_seasonal, x_trendCome si può vedere, l’implementazione è piuttosto semplice e può essere utilizzata in altri modelli, come vedremo con DLinear. Ora spieghiamo il secondo contributo – il meccanismo di attenzione (autocorrelazione).
Meccanismo di attenzione (autocorrelazione)
Oltre al livello di decomposizione, Autoformer utilizza un nuovo meccanismo di auto-correlazione che sostituisce l’auto-attenzione in modo trasparente. Nel Transformer di base per le serie temporali, i pesi di attenzione sono calcolati nel dominio temporale e aggregati punto per punto. D’altra parte, come si può vedere nella figura sopra, Autoformer li calcola nel dominio delle frequenze (utilizzando la trasformata di Fourier veloce) e li aggrega per ritardi temporali.
Nelle sezioni seguenti, approfondiremo questi argomenti nel dettaglio e li spiegheremo con esempi di codice.
Attenzione nel dominio delle frequenze
In teoria, dato un ritardo temporale τ \tau τ, l’autocorrelazione per una singola variabile discreta y y y viene utilizzata per misurare la “relazione” (correlazione di Pearson) tra il valore corrente della variabile al tempo t t t e il suo valore passato al tempo t − τ t-\tau t − τ:
Autocorrelazione ( τ ) = Corr ( y t , y t − τ ) \textrm{Autocorrelazione}(\tau) = \textrm{Corr}(y_t, y_{t-\tau}) Autocorrelazione ( τ ) = Corr ( y t , y t − τ )
Utilizzando l’autocorrelazione, Autoformer estrae le dipendenze basate sulla frequenza dalle query e dalle chiavi, invece del prodotto scalare standard tra di esse. Puoi pensarlo come una sostituzione del termine Q K T QK^T Q K T nella self-attention.
Nella pratica, l’autocorrelazione delle query e delle chiavi per tutti i ritardi viene calcolata contemporaneamente tramite FFT. In questo modo, il meccanismo dell’autocorrelazione raggiunge una complessità temporale di O ( L log L ) O(L \log L) O ( L lo g L ) (dove L L L è la lunghezza temporale di input), simile all’attenzione ProbSparse di Informer. Nota che la teoria dietro al calcolo dell’autocorrelazione tramite FFT si basa sul teorema di Wiener-Khinchin, che esula dallo scopo di questo post sul blog.
Ora, siamo pronti per vedere il codice in PyTorch:
import torch
def autocorrelation(query_states, key_states):
"""
Calcola l'autocorrelazione(Q,K) usando `torch.fft`.
Puoi pensarla come una sostituzione del QK^T nella self-attention.
Assunzione: gli stati sono ridimensionati alla stessa forma di [batch_size, time_length, embedding_dim].
"""
query_states_fft = torch.fft.rfft(query_states, dim=1)
key_states_fft = torch.fft.rfft(key_states, dim=1)
attn_weights = query_states_fft * torch.conj(key_states_fft)
attn_weights = torch.fft.irfft(attn_weights, dim=1)
return attn_weightsAbbastanza semplice! 😎 Ti ricordo che questa è solo un’implementazione parziale di autocorrelation(Q,K), e l’implementazione completa si può trovare in 🤗 Transformers.
Successivamente, vedremo come aggregare i nostri attn_weights con i valori in base al ritardo temporale, processo che viene chiamato Time Delay Aggregation.
Time Delay Aggregation
Consideriamo le autocorrelazioni (indicate come attn_weights) come R Q , K \mathcal{R_{Q,K}} R Q , K . Sorge la domanda: come aggregiamo queste R Q , K ( τ 1 ) , R Q , K ( τ 2 ) , . . . , R Q , K ( τ k ) \mathcal{R_{Q,K}}(\tau_1), \mathcal{R_{Q,K}}(\tau_2), …, \mathcal{R_{Q,K}}(\tau_k) R Q , K ( τ 1 ) , R Q , K ( τ 2 ) , . . . , R Q , K ( τ k ) con V \mathcal{V} V ? Nella self-attention standard, questa aggregazione viene realizzata tramite il prodotto scalare. Tuttavia, in Autoformer, adottiamo un approccio diverso. Prima di tutto, allineiamo V \mathcal{V} V calcolando il suo valore per ogni ritardo temporale τ 1 , τ 2 , . . . τ k \tau_1, \tau_2, … \tau_k τ 1 , τ 2 , . . . τ k , che è anche noto come Rolling. Successivamente, effettuiamo una moltiplicazione elemento per elemento tra il V \mathcal{V} V allineato e le autocorrelazioni. Nella figura fornita, puoi osservare il lato sinistro che mostra il rolling di V \mathcal{V} V in base al ritardo temporale, mentre il lato destro illustra la moltiplicazione elemento per elemento con le autocorrelazioni.
Si può riassumere con le seguenti equazioni:
τ 1 , τ 2 , . . . τ k = arg Top-k ( R Q , K ( τ ) ) R ^ Q , K ( τ 1 ) , R ^ Q , K ( τ 2 ) , . . . , R ^ Q , K ( τ k ) = Softmax ( R Q , K ( τ 1 ) , R Q , K ( τ 2 ) , . . . , R Q , K ( τ k ) ) Autocorrelation-Attention = ∑ i = 1 k Roll ( V , τ i ) ⋅ R ^ Q , K ( τ i ) \tau_1, \tau_2, … \tau_k = \textrm{arg Top-k}(\mathcal{R_{Q,K}}(\tau)) \\ \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _1), \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _2), …, \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _k) = \textrm{Softmax}(\mathcal{R_{Q,K}}(\tau _1), \mathcal{R_{Q,K}}(\tau_2), …, \mathcal{R_{Q,K}}(\tau_k)) \\ \textrm{Autocorrelation-Attention} = \sum_{i=1}^k \textrm{Roll}(\mathcal{V}, \tau_i) \cdot \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _i) τ 1 , τ 2 , . . . τ k = arg Top-k ( R Q , K ( τ ) ) R ^ Q , K ( τ 1 ) , R ^ Q , K ( τ 2 ) , . . . , R ^ Q , K ( τ k ) = Softmax ( R Q , K ( τ 1 ) , R Q , K ( τ 2 ) , . . . , R Q , K ( τ k ) ) Autocorrelation-Attention = i = 1 ∑ k Roll ( V , τ i ) ⋅ R ^ Q , K ( τ i )
Ecco fatto! Nota che k k k è controllato da un iperparametro chiamato autocorrelation_factor (simile a sampling_factor in Informer), e softmax viene applicato alle autocorrelazioni prima della moltiplicazione.
Ora siamo pronti per vedere il codice finale:
import torch
import math
def time_delay_aggregation(attn_weights, value_states, autocorrelation_factor=2):
"""
Calcola l'aggregazione come value_states.roll(delay) * top_k_autocorrelations(delay).
Il risultato finale è l'output autocorrelazione-attenzione.
Pensateci come una sostituzione del prodotto scalare tra attn_weights e value states.
L'autocorrelation_factor viene utilizzato per trovare i ritardi delle autocorrelazioni migliori.
Presupposto: le forme di value_states e attn_weights sono: [dimensione_batch, lunghezza_temporale, dimensione_incorporamento]
"""
dimensione_batch, num_heads, lunghezza_tgt, canale = ...
lunghezza_temporale = value_states.size(1)
autocorrelazioni = attn_weights.view(dimensione_batch, num_heads, lunghezza_tgt, canale)
# trova i ritardi delle autocorrelazioni migliori
top_k = int(autocorrelation_factor * math.log(lunghezza_temporale))
autocorrelazioni_media = torch.mean(autocorrelazioni, dim=(1, -1)) # dimensione_batch x lunghezza_tgt
top_k_autocorrelazioni, top_k_ritardi = torch.topk(autocorrelazioni_media, top_k, dim=1)
# applica softmax sulla dimensione del canale
top_k_autocorrelazioni = torch.softmax(top_k_autocorrelazioni, dim=-1) # dimensione_batch x top_k
# calcola l'aggregazione: value_states.roll(delay) * top_k_autocorrelazioni(delay)
ritardi_agg = torch.zeros_like(value_states).float() # dimensione_batch x lunghezza_temporale x canale
for i in range(top_k):
value_states_roll_delay = value_states.roll(shifts=-int(top_k_ritardi[i]), dims=1)
top_k_al_ritardo = top_k_autocorrelazioni[:, i]
# aggregazione
top_k_ridimensionato = top_k_al_ritardo.view(-1, 1, 1).repeat(num_heads, lunghezza_tgt, canale)
ritardi_agg += value_states_roll_delay * top_k_ridimensionato
output_attn = ritardi_agg.contiguous()
return output_attnCi siamo riusciti! Il modello Autoformer è ora disponibile nella libreria Transformers di 🤗 e viene semplicemente chiamato AutoformerModel.
La nostra strategia con questo modello è mostrare le prestazioni dei modelli Transformer univariati in confronto al modello DLinear che è intrinsecamente univariato come verrà mostrato successivamente. Presenteremo anche i risultati di due modelli Transformer multivariati addestrati sugli stessi dati.
DLinear – Sotto Il Cappuccio
In realtà, DLinear è concettualmente semplice: è solo un fully connected con il DecompositionLayer di Autoformer . Utilizza il DecompositionLayer sopra per decomporre la serie temporale di input nella parte residua (la stagionalità) e nella tendenza. Nel passaggio in avanti, ogni parte viene passata attraverso il proprio livello lineare, che proietta il segnale in un’uscita di dimensione appropriata prediction_length. L’output finale è la somma delle due uscite corrispondenti nel modello di previsione dei punti:
def forward(self, context):
stagionale, tendenza = self.decomposition(context)
output_stagionale = self.linear_stagionale(stagionale)
output_tendenza = self.linear_tendenza(tendenza)
return output_stagionale + output_tendenzaNell’ambito probabilistico, è possibile proiettare gli array di lunghezza del contesto in dimensioni prediction-length * hidden tramite i livelli linear_stagionale e linear_tendenza. Le uscite risultanti vengono sommate e ridimensionate in (prediction_length, hidden). Infine, una testa probabilistica mappa le rappresentazioni latenti di dimensione hidden ai parametri di una distribuzione.
Nel nostro benchmark, utilizziamo l’implementazione di DLinear da GluonTS .
Esempio: Dataset Traffico
Vogliamo mostrare empiricamente le prestazioni dei modelli basati su Transformer nella libreria, confrontandoli sul dataset traffic, un dataset con 862 serie temporali. Addestreremo un modello condiviso su ciascuna delle singole serie temporali (cioè in modalità univariata). Ciascuna serie temporale rappresenta il valore di occupazione di un sensore ed è nell’intervallo [0, 1]. Manteniamo i seguenti iperparametri fissi per tutti i modelli:
# La lunghezza di previsione del traffico è 24. Riferimento:
# https://github.com/awslabs/gluonts/blob/6605ab1278b6bf92d5e47343efcf0d22bc50b2ec/src/gluonts/dataset/repository/_lstnet.py#L105
prediction_length = 24
context_length = prediction_length*2
batch_size = 128
num_batches_per_epoch = 100
epochs = 50
scaling = "std"I modelli di transformer sono tutti relativamente piccoli con:
encoder_layers=2
decoder_layers=2
d_model=16Invece di mostrare come addestrare un modello usando Autoformer, si può semplicemente sostituire il modello nei due post precedenti ( TimeSeriesTransformer e Informer ) con il nuovo modello Autoformer e addestrarlo sul dataset traffico. Per evitare di ripeterci, abbiamo già addestrato i modelli e li abbiamo spinti su HuggingFace Hub. Utilizzeremo quei modelli per la valutazione.
Carica dataset
Prima di tutto, installiamo le librerie necessarie:
!pip install -q transformers datasets evaluate accelerate "gluonts[torch]" ujson tqdmIl dataset traffico, utilizzato da Lai et al. (2017), contiene il traffico di San Francisco. Contiene 862 serie temporali orarie che mostrano i tassi di occupazione delle strade nell’intervallo [ 0 , 1 ] [0, 1] [ 0 , 1 ] nelle autostrade dell’area della baia di San Francisco dal 2015 al 2016.
from gluonts.dataset.repository.datasets import get_dataset
dataset = get_dataset("traffic")
freq = dataset.metadata.freq
prediction_length = dataset.metadata.prediction_lengthVisualizziamo una serie temporale nel dataset e tracciamo la divisione tra train e test:
import matplotlib.pyplot as plt
train_example = next(iter(dataset.train))
test_example = next(iter(dataset.test))
num_of_samples = 4*prediction_length
figure, axes = plt.subplots()
axes.plot(train_example["target"][-num_of_samples:], color="blue")
axes.plot(
test_example["target"][-num_of_samples - prediction_length :],
color="red",
alpha=0.5,
)
plt.show()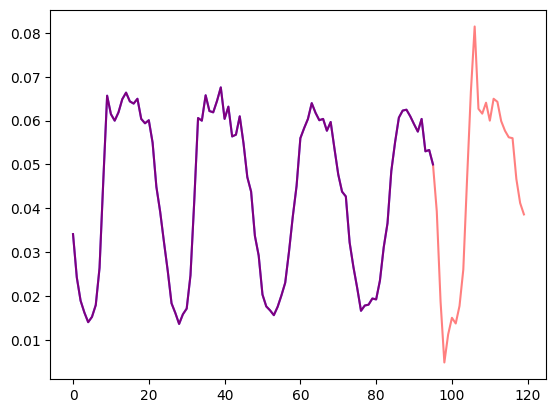
Definiamo le divisioni tra train e test:
train_dataset = dataset.train
test_dataset = dataset.testDefinire le trasformazioni
Successivamente, definiamo le trasformazioni per i dati, in particolare per la creazione delle caratteristiche temporali (basate sul dataset o universali).
Definiamo una Chain di trasformazioni da GluonTS (che è un po’ simile a torchvision.transforms.Compose per le immagini). Ci permette di combinare più trasformazioni in un singolo flusso di lavoro.
Le trasformazioni seguenti sono annotate con commenti per spiegare cosa fanno. A un livello elevato, itereremo sulle singole serie temporali del nostro dataset e aggiungeremo/rimuoveremo campi o caratteristiche:
from transformers import PretrainedConfig
from gluonts.time_feature import time_features_from_frequency_str
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
# creare una lista di campi da rimuovere successivamente
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
return Chain(
# passo 1: rimuovere campi statici/dinamici se non specificato
[RemoveFields(field_names=remove_field_names)]
# passo 2: convertire i dati in NumPy (potenzialmente non necessario)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# ci aspettiamo una dimensione extra per il caso multivariato:
expected_ndim=1 if config.input_size == 1 else 2,
),
# passo 3: gestire i NaN's riempiendo l'obiettivo con zero
# e restituiamo la maschera (che è nei valori osservati)
# vero per i valori osservati, falso per i NaN's
# il decoder usa questa maschera (non viene sostenuta alcuna perdita per i valori non osservati)
# vedere loss_weights all'interno del modello xxxForPrediction
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# passo 4: aggiungere le caratteristiche temporali in base alla frequenza del dataset
# queste servono come codifiche posizionali
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# passo 5: aggiungere un'altra caratteristica temporale (solo un numero singolo)
# indica al modello dove si trova nella vita il valore della serie temporale
# sorta di contatore in esecuzione
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# passo 6: impilare verticalmente tutte le caratteristiche temporali nella chiave FEAT_TIME
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# passo 7: rinominare per corrispondere ai nomi di HuggingFace
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)Definire InstanceSplitter
Per addestramento/validazione/test successivo creiamo un InstanceSplitter che viene utilizzato per campionare finestre dal dataset (poiché, ricorda, non possiamo passare all’intero storico dei valori al modello a causa di vincoli di tempo e memoria).
L’instance splitter campiona finestre di dimensione context_length e dimensione successiva prediction_length dai dati e aggiunge una chiave past_ o future_ a tutte le chiavi temporali per le rispettive finestre. Ciò assicura che i values saranno suddivisi in chiavi past_values e future_values, che serviranno rispettivamente come input dell’encoder e dell’decoder. Lo stesso accade per qualsiasi chiave nell’argomento time_series_fields:
from gluonts.transform import InstanceSplitter
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)Creare i DataLoaders di PyTorch
Successivamente, è il momento di creare i DataLoaders di PyTorch, che ci consentono di avere batch di coppie (input, output) – o in altre parole ( past_values , future_values ).
from typing import Iterable
import torch
from gluonts.itertools import Cyclic, Cached
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# inizializziamo un'istanza di addestramento
instance_splitter = create_instance_splitter(config, "train")
# l'instance splitter campionerà una finestra di
# lunghezza del contesto + lags + lunghezza della previsione (dai 366 possibili time series trasformati)
# casualmente all'interno della time series target e restituirà un iteratore.
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(stream, is_train=True)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# creiamo uno splitter di istanze di test che campionerà l'ultima finestra
# di contesto vista solo durante l'addestramento per l'encoder.
instance_sampler = create_instance_splitter(config, "test")
# applichiamo le trasformazioni in modalità di test
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)Valutazione su Autoformer
Abbiamo già preallenato un modello Autoformer su questo dataset, quindi possiamo semplicemente recuperare il modello e valutarlo sul set di test:
from transformers import AutoformerConfig, AutoformerForPrediction
config = AutoformerConfig.from_pretrained("kashif/autoformer-traffic-hourly")
model = AutoformerForPrediction.from_pretrained("kashif/autoformer-traffic-hourly")
test_dataloader = create_test_dataloader(
config=config,
freq=freq,
data=test_dataset,
batch_size=64,
)All’atto dell’inferring, useremo il metodo generate() del modello per predire prediction_length passi nel futuro dall’ultima finestra di contesto di ciascuna serie temporale nel set di addestramento.
from accelerate import Accelerator
accelerator = Accelerator()
device = accelerator.device
model.to(device)
model.eval()
forecasts_ = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts_.append(outputs.sequences.cpu().numpy())Il modello restituisce un tensore di forma (batch_size, numero di campioni, lunghezza previsione, input_size).
In questo caso, otteniamo 100 valori possibili per le prossime 24 ore per ciascuna delle serie temporali nel batch del dataloader di test che, se ricordi, è 64:
forecasts_[0].shape
>>> (64, 100, 24)Li impileremo verticalmente, per ottenere previsioni per tutte le serie temporali nel dataset di test: abbiamo 7 finestre scorrevoli nel set di test, motivo per cui otteniamo un totale di 7 * 862 = 6034 previsioni:
import numpy as np
forecasts = np.vstack(forecasts_)
print(forecasts.shape)
>>> (6034, 100, 24)Possiamo valutare la previsione risultante rispetto ai valori reali fuori campione presenti nel set di test. Per fare ciò, useremo la libreria 🤗 Evaluate, che include le metriche MASE.
Calcoliamo la metrica per ciascuna serie temporale nel dataset e restituiamo la media:
from tqdm.autonotebook import tqdm
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
forecast_median = np.median(forecasts, 1)
mase_metrics = []
for item_id, ts in enumerate(tqdm(test_dataset)):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq))
mase_metrics.append(mase["mase"])Quindi il risultato per il modello Autoformer è:
print(f"MASE univariato Autoformer: {np.mean(mase_metrics):.3f}")
>>> MASE univariato Autoformer: 0.910Per tracciare la previsione per qualsiasi serie temporale rispetto ai dati di test effettivi, definiamo il seguente aiutante:
import matplotlib.dates as mdates
import pandas as pd
test_ds = list(test_dataset)
def plot(ts_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=test_ds[ts_index][FieldName.START],
periods=len(test_ds[ts_index][FieldName.TARGET]),
freq=test_ds[ts_index][FieldName.START].freq,
).to_timestamp()
ax.plot(
index[-5*prediction_length:],
test_ds[ts_index]["target"][-5*prediction_length:],
label="effettivo",
)
plt.plot(
index[-prediction_length:],
np.median(forecasts[ts_index], axis=0),
label="mediana",
)
plt.gcf().autofmt_xdate()
plt.legend(loc="best")
plt.show()Ad esempio, per le serie temporali nel set di test con indice 4 :
plot(4)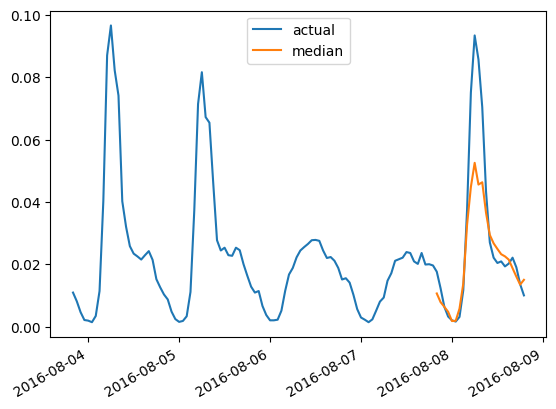
Valutazione su DLinear
Un DLinear probabilistico è implementato in gluonts e quindi possiamo addestrarlo e valutarlo relativamente rapidamente qui:
from gluonts.torch.model.d_linear.estimator import DLinearEstimator
# Definisci il modello DLinear con gli stessi parametri del modello Autoformer
estimator = DLinearEstimator(
prediction_length=dataset.metadata.prediction_length,
context_length=dataset.metadata.prediction_length*2,
scaling=scaling,
hidden_dimension=2,
batch_size=batch_size,
num_batches_per_epoch=num_batches_per_epoch,
trainer_kwargs=dict(max_epochs=epochs)
)Addestra il modello:
predictor = estimator.train(
training_data=train_dataset,
cache_data=True,
shuffle_buffer_length=1024
)
>>> INFO:pytorch_lightning.callbacks.model_summary:
| Nome | Tipo | Parametri
---------------------------------------
0 | modello | DLinearModel | 4.7 K
---------------------------------------
4.7 K Parametri addestrabili
0 Parametri non addestrabili
4.7 K Parametri totali
0.019 Dimensione totale stimata dei parametri del modello (MB)
Addestramento: 0it [00:00, ?it/s]
...
INFO:pytorch_lightning.utilities.rank_zero:Epoca 49, passo globale 5000: 'train_loss' non era in top 1
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` fermato: `max_epochs=50` raggiunto.E valutalo sul set di test:
from gluonts.evaluation import make_evaluation_predictions, Evaluator
forecast_it, ts_it = make_evaluation_predictions(
dataset=dataset.test,
predictor=predictor,
)
d_linear_forecasts = list(forecast_it)
d_linear_tss = list(ts_it)
evaluator = Evaluator()
agg_metrics, _ = evaluator(iter(d_linear_tss), iter(d_linear_forecasts))Quindi il risultato per il modello DLinear è:
dlinear_mase = agg_metrics["MASE"]
print(f"MASE DLinear: {dlinear_mase:.3f}")
>>> MASE DLinear: 0.965Come prima, tracciamo le previsioni del nostro modello DLinear addestrato tramite questo aiuto:
def plot_gluonts(index):
plt.plot(d_linear_tss[index][-4 * dataset.metadata.prediction_length:].to_timestamp(), label="target")
d_linear_forecasts[index].plot(show_label=True, color='g')
plt.legend()
plt.gcf().autofmt_xdate()
plt.show()
plot_gluonts(4)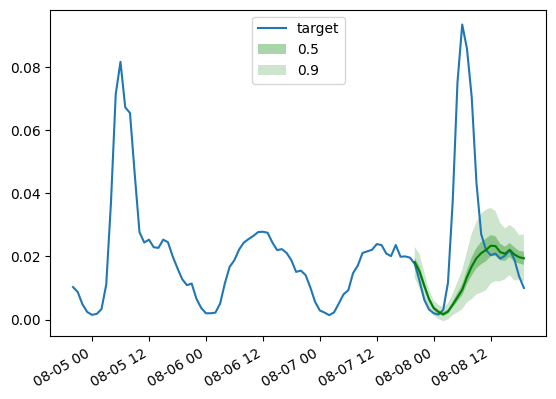
Il dataset traffic presenta una variazione distribuzionale nei modelli dei sensori tra i giorni feriali e i weekend. Quindi cosa sta succedendo qui? Dato che il modello DLinear non ha la capacità di incorporare covariate, in particolare alcun attributo data-ora, la finestra di contesto che gli forniamo non ha sufficienti informazioni per capire se la previsione è per il weekend o per i giorni feriali. Di conseguenza, il modello prevederà il pattern più comune, ovvero quello dei giorni feriali, portando a una performance peggiore nei weekend. Naturalmente, fornendo una finestra di contesto più ampia, un modello lineare sarà in grado di individuare il pattern settimanale, ma forse ci sono pattern mensili o trimestrali nei dati che richiederebbero contesti sempre più grandi.
Conclusioni
Come si confrontano i modelli basati su Transformer rispetto al precedente modello lineare? Di seguito sono riportate le metriche MASE del set di test ottenute dai diversi modelli che abbiamo:
Come si può osservare, il Transformer vanilla che abbiamo introdotto l’anno scorso ottiene i migliori risultati qui. In secondo luogo, i modelli multivariati sono tipicamente peggiori rispetto a quelli univariati, a causa della difficoltà nel stimare le correlazioni/relazioni tra le serie. La varianza aggiuntiva introdotta dalle stime spesso danneggia le previsioni risultanti o il modello apprende correlazioni spurie. Recenti paper come CrossFormer (ICLR 23) e CARD cercano di affrontare questo problema nei modelli Transformer. I modelli multivariati di solito hanno buone prestazioni quando addestrati su grandi quantità di dati. Tuttavia, confrontati con i modelli univariati, specialmente su dataset aperti più piccoli, i modelli univariati tendono a fornire metriche migliori. Confrontando il modello lineare con trasformatori univariati delle stesse dimensioni o in realtà qualsiasi altro modello neurale univariato, si ottengono tipicamente prestazioni migliori.
Per riassumere, i Transformers sono decisamente lontani dall’essere obsoleti quando si tratta di previsioni di serie temporali! Tuttavia, la disponibilità di set di dati su larga scala è fondamentale per massimizzarne il potenziale. A differenza di CV e NLP, il campo delle serie temporali manca di set di dati su larga scala accessibili al pubblico. La maggior parte dei modelli pre-addestrati esistenti per le serie temporali sono addestrati su campioni di piccole dimensioni provenienti da archivi come UCR e UEA, che contengono solo alcuni migliaia o addirittura centinaia di campioni. Sebbene questi set di dati di riferimento abbiano contribuito al progresso della comunità delle serie temporali, le loro dimensioni limitate e la mancanza di generalità rappresentano sfide per il pre-addestramento dei modelli di deep learning.
Pertanto, lo sviluppo di set di dati su larga scala e generici per le serie temporali (come ImageNet in CV) è di fondamentale importanza. La creazione di tali set di dati faciliterà notevolmente ulteriori ricerche sui modelli pre-addestrati appositamente progettati per l’analisi delle serie temporali e migliorerà l’applicabilità dei modelli pre-addestrati nella previsione delle serie temporali.
Riconoscimenti
Esprimiamo la nostra gratitudine a Lysandre Debut e Pedro Cuenca per i loro commenti illuminanti e l’aiuto durante questo progetto ❤️.