Più piccolo è meglio Q8-Chat, un’efficace esperienza di intelligenza artificiale generativa su Xeon
Il miglior Q8-Chat, un'esperienza di intelligenza artificiale generativa su Xeon.
I modelli di linguaggio di grandi dimensioni (LLM) stanno conquistando il mondo dell’apprendimento automatico. Grazie alla loro architettura Transformer, i LLM hanno la straordinaria capacità di imparare da grandi quantità di dati non strutturati, come testo, immagini, video o audio. Si comportano molto bene in molti tipi di compiti, sia estrattivi come la classificazione del testo, che generativi come il riassunto del testo e la generazione di testo-immagine.
Come suggerisce il loro nome, i LLM sono modelli di grandi dimensioni che spesso superano i 10 miliardi di parametri. Alcuni ne hanno più di 100 miliardi, come il modello BLOOM. I LLM richiedono molta potenza di calcolo, tipicamente presente nelle GPU di alta gamma, per prevedere abbastanza velocemente per casi d’uso a bassa latenza come la ricerca o le applicazioni di conversazione. Purtroppo, per molte organizzazioni, i costi associati possono essere proibitivi e rendere difficile l’utilizzo dei LLM all’avanguardia nelle loro applicazioni.
In questo articolo, discuteremo delle tecniche di ottimizzazione che aiutano a ridurre le dimensioni dei LLM e la latenza dell’inferenza, consentendo loro di funzionare in modo efficiente sui processori Intel.
Un’introduzione alla quantizzazione
I LLM vengono di solito addestrati con parametri in virgola mobile a 16 bit (detto anche FP16/BF16). Pertanto, memorizzare il valore di un singolo peso o valore di attivazione richiede 2 byte di memoria. Inoltre, l’aritmetica in virgola mobile è più complessa e più lenta dell’aritmetica intera e richiede ulteriori risorse di calcolo.
- Grande riduzione della duplicazione su larga scala dietro BigCode
- 🐶Safetensors è stato sottoposto ad una revisione di sicurezza ed è diventato il valore predefinito.
- Hugging Face e IBM si sono uniti su watsonx.ai, lo studio aziendale di prossima generazione per i creatori di intelligenza artificiale.
La quantizzazione è una tecnica di compressione del modello che mira a risolvere entrambi i problemi riducendo l’intervallo di valori unici che i parametri del modello possono assumere. Ad esempio, è possibile quantizzare i modelli a una precisione inferiore come interi a 8 bit (INT8) per ridurli e sostituire le complesse operazioni in virgola mobile con operazioni intere più semplici e veloci.
In poche parole, la quantizzazione ridimensiona i parametri del modello a intervalli di valori più piccoli. Quando ha successo, riduce le dimensioni del modello almeno del 2x, senza alcun impatto sull’accuratezza del modello.
È possibile applicare la quantizzazione durante l’addestramento, chiamata addestramento “quantization-aware” (QAT), che generalmente produce i migliori risultati. Se si preferisce quantizzare un modello esistente, è possibile applicare la quantizzazione post-addestramento (PTQ), una tecnica molto più veloce che richiede pochissime risorse di calcolo.
Sono disponibili diversi strumenti di quantizzazione. Ad esempio, PyTorch ha un supporto integrato per la quantizzazione. È anche possibile utilizzare la libreria Optimum Intel di Hugging Face, che include API facili da usare per QAT e PTQ.
Quantizzazione dei LLM
Studi recenti [1] [2] mostrano che le tecniche di quantizzazione attuali non funzionano bene con i LLM. In particolare, i LLM presentano outliers di grande magnitudine in specifici canali di attivazione in tutti i livelli e token. Ecco un esempio con il modello OPT-13B. Si può notare che uno dei canali di attivazione ha valori molto più grandi di tutti gli altri su tutti i token. Questo fenomeno è visibile in tutti i livelli del modello Transformer.
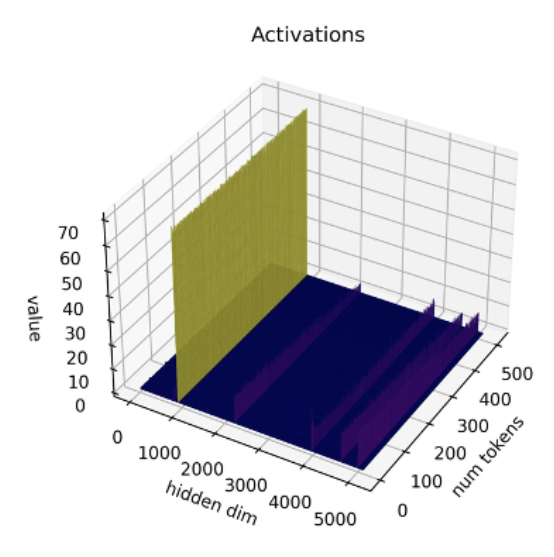 *Fonte: SmoothQuant*
*Fonte: SmoothQuant*
Le migliori tecniche di quantizzazione finora quantizzano le attivazioni token-wise, causando outliers troncati o attivazioni a bassa magnitudine che vanno in overflow. Entrambe le soluzioni danneggiano significativamente la qualità del modello. Inoltre, l’addestramento “quantization-aware” richiede un addestramento del modello aggiuntivo, il che non è pratico nella maggior parte dei casi a causa della mancanza di risorse di calcolo e dati.
SmoothQuant [3] [4] è una nuova tecnica di quantizzazione che risolve questo problema. Applica una trasformazione matematica congiunta a pesi e attivazioni, che riduce il rapporto tra valori outlier e valori non-outlier per le attivazioni a discapito di aumentare il rapporto per i pesi. Questa trasformazione rende i livelli del Transformer “quantization-friendly” e consente una quantizzazione a 8 bit senza compromettere la qualità del modello. Di conseguenza, SmoothQuant produce modelli più piccoli e più veloci che funzionano bene sulle piattaforme dei processori Intel.
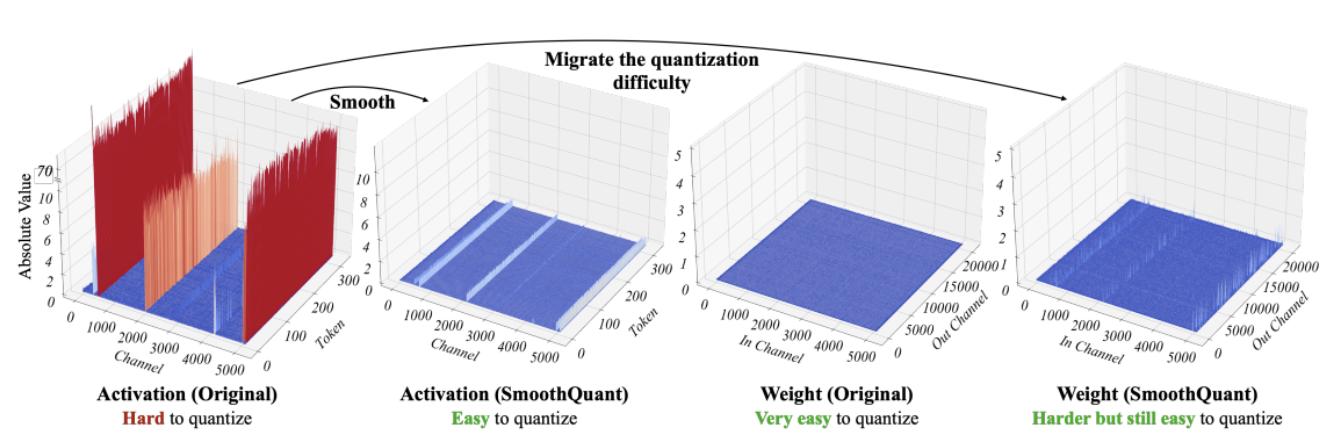 *Fonte: SmoothQuant*
*Fonte: SmoothQuant*
Ora vediamo come SmoothQuant funziona quando viene applicato ai LLM popolari.
Quantizzazione dei LLM con SmoothQuant
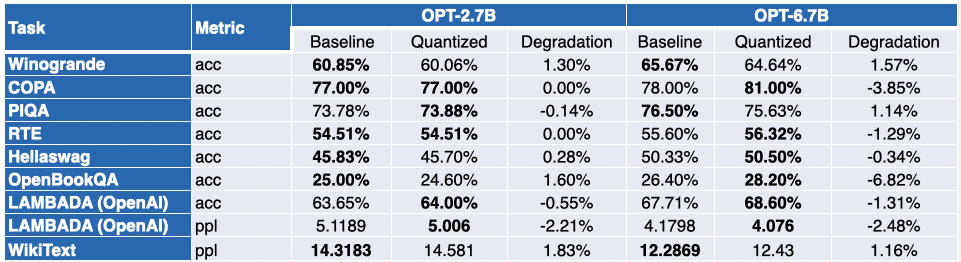
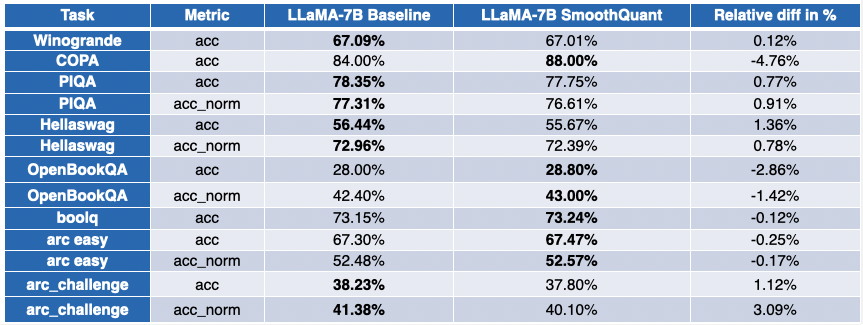
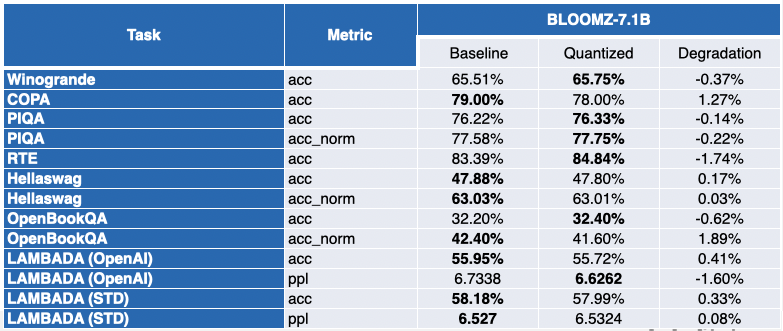
I nostri amici di Intel hanno quantizzato diversi LLM con SmoothQuant-O3: OPT 2.7B e 6.7B [5], LLaMA 7B [6], Alpaca 7B [7], Vicuna 7B [8], BloomZ 7.1B [9], MPT-7B-chat [10]. Hanno anche valutato l’accuratezza dei modelli quantizzati utilizzando il Language Model Evaluation Harness.
La tabella qui sotto presenta un riassunto delle loro scoperte. La seconda colonna mostra il rapporto di benchmark che sono migliorati dopo la quantizzazione. La terza colonna contiene la media del degrado medio ( * un valore negativo indica che il benchmark è migliorato ). Puoi trovare i risultati dettagliati alla fine di questo post.
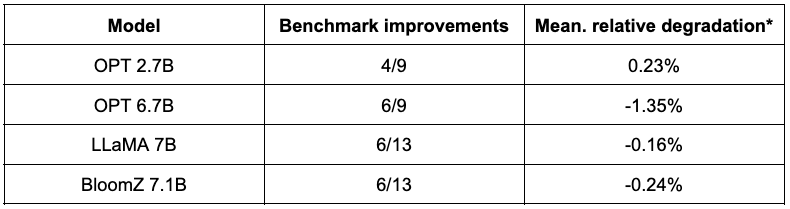
Come puoi vedere, i modelli OPT sono ottimi candidati per la quantizzazione SmoothQuant. I modelli sono ~2 volte più piccoli rispetto ai modelli a 16 bit preaddestrati. La maggior parte delle metriche migliora, e quelli che non migliorano sono solo penalizzati in modo marginale.
La situazione è un po’ più contrastata per LLaMA 7B e BloomZ 7.1B. I modelli sono compressi di un fattore di ~2 volte, con circa la metà dei task che ottengono miglioramenti delle metriche. Di nuovo, l’altra metà viene colpita solo marginalmente, con un singolo task che registra un degrado relativo superiore al 3%.
Il vantaggio ovvio di lavorare con modelli più piccoli è una significativa riduzione della latenza di inferenza. Ecco un video che mostra la generazione di testo in tempo reale con il modello MPT-7B-chat su una CPU Intel Sapphire Rapids con 32 core e una dimensione del batch di 1.
In questo esempio, chiediamo al modello: “*Qual è il ruolo di Hugging Face nella democratizzazione dell’NLP?*”. Questo invia al modello il seguente prompt: ” Una chat tra un utente curioso e un assistente di intelligenza artificiale. L’assistente fornisce risposte utili, dettagliate e cortesi alle domande dell’utente. UTENTE: Qual è il ruolo di Hugging Face nella democratizzazione dell’NLP? ASSISTENTE: “
L’esempio mostra i vantaggi aggiuntivi che si possono ottenere dalla quantizzazione a 8 bit abbinata alla 4a generazione di Xeon, che comporta un tempo di generazione molto basso per ogni token. Questo livello di performance rende sicuramente possibile eseguire LLM su piattaforme CPU, offrendo ai clienti maggiore flessibilità IT e un rapporto costo-prestazioni migliore che mai.
Esperienza di chat su Xeon
Recentemente, Clement, il CEO di HuggingFace, ha detto: “*Più aziende sarebbero meglio servite concentrando l’attenzione su modelli più piccoli e specifici che sono più economici da addestrare ed eseguire.*” L’emergere di modelli relativamente più piccoli come Alpaca, BloomZ e Vicuna apre una nuova opportunità per le aziende di ridurre i costi del fine-tuning e dell’inferenza in produzione. Come dimostrato sopra, la quantizzazione di alta qualità porta esperienze di chat di alta qualità alle piattaforme CPU Intel, senza la necessità di eseguire LLM mastodontiche e acceleratori di intelligenza artificiale complessi.
Insieme ad Intel, stiamo ospitando una nuova demo entusiasmante in Spaces chiamata Q8-Chat (pronunciato “Cute chat”). Q8-Chat offre un’esperienza di chat simile a ChatGPT, ma viene eseguito solo su una CPU Intel Sapphire Rapids con 32 core e una dimensione del batch di 1.
Prossimi passi
Stiamo lavorando attualmente all’integrazione di queste nuove tecniche di quantizzazione nella libreria Hugging Face Optimum Intel attraverso Intel Neural Compressor . Una volta terminato, sarete in grado di replicare queste demo con poche righe di codice.
Restate sintonizzati. Il futuro è a 8 bit!
Questo post è garantito al 100% privo di ChatGPT.
Riconoscimenti
Questo blog è stato realizzato in collaborazione con Ofir Zafrir, Igor Margulis, Guy Boudoukh e Moshe Wasserblat di Intel Labs. Un ringraziamento speciale a loro per i loro ottimi commenti e la collaborazione.
Appendice: risultati dettagliati
Un valore negativo indica che il benchmark è migliorato.