Esegui un Chatbot simile a Chatgpt su una singola GPU con ROCm
Esegui un Chatbot simile a Chatgpt su una GPU ROCm.
Introduzione
ChatGPT, il modello linguistico rivoluzionario di OpenAI, è diventato una forza influente nel campo dell’intelligenza artificiale, aprendo la strada a una moltitudine di applicazioni di intelligenza artificiale in settori diversi. Con la sua straordinaria capacità di comprendere e generare testo simile a quello umano, ChatGPT ha trasformato industrie, dal supporto clienti alla scrittura creativa, ed è stato persino uno strumento di ricerca prezioso.
Sono stati fatti vari sforzi per fornire modelli linguistici open-source di grandi dimensioni che dimostrano grandi capacità ma in dimensioni più ridotte, come OPT , LLAMA , Alpaca e Vicuna .
In questo blog, approfondiremo il mondo di Vicuna e spiegheremo come eseguire il modello Vicuna 13B su una singola GPU AMD con ROCm.
Cosa è Vicuna?
- Più piccolo è meglio Q8-Chat, un’efficace esperienza di intelligenza artificiale generativa su Xeon
- Grande riduzione della duplicazione su larga scala dietro BigCode
- 🐶Safetensors è stato sottoposto ad una revisione di sicurezza ed è diventato il valore predefinito.
Vicuna è un chatbot open-source con 13 miliardi di parametri, sviluppato da un team composto da UC Berkeley, CMU, Stanford e UC San Diego. Per creare Vicuna, è stato effettuato il fine-tuning di un modello di base LLAMA utilizzando circa 70.000 conversazioni condivise dagli utenti raccolte da ShareGPT.com tramite API pubbliche. Secondo valutazioni iniziali in cui GPT-4 viene utilizzato come riferimento, Vicuna-13B ha raggiunto oltre il 90%* di qualità rispetto a OpenAI ChatGPT.
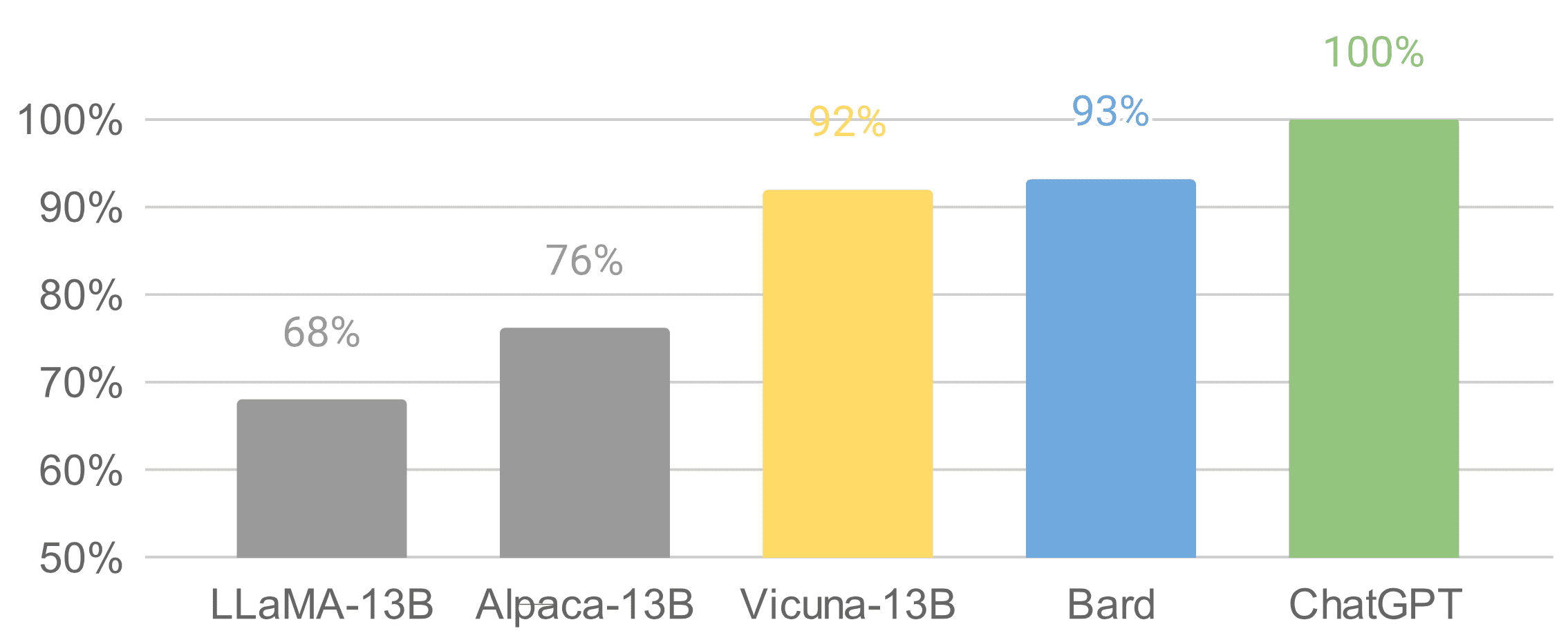
È stato rilasciato su Github l’11 aprile, solo poche settimane fa. È utile menzionare che il set di dati, il codice di addestramento, le metriche di valutazione e il costo di addestramento sono noti per Vicuna. Il costo totale di addestramento era di circa $300, rendendolo una soluzione conveniente per il pubblico generale.
Per ulteriori dettagli su Vicuna, visita https://vicuna.lmsys.org .
Perché abbiamo bisogno di un modello GPT quantizzato?
Eseguire il modello Vicuna-13B in fp16 richiede circa 28GB di RAM GPU. Per ridurre ulteriormente l’occupazione di memoria, sono necessarie tecniche di ottimizzazione. Di recente è stato pubblicato un articolo di ricerca denominato GPTQ, che propone una quantizzazione accurata post-addestramento per i modelli GPT con una precisione di bit inferiore. Come illustrato di seguito, per modelli con parametri superiori a 10 miliardi, il GPTQ a 4 bit o 3 bit può ottenere una precisione comparabile con fp16.
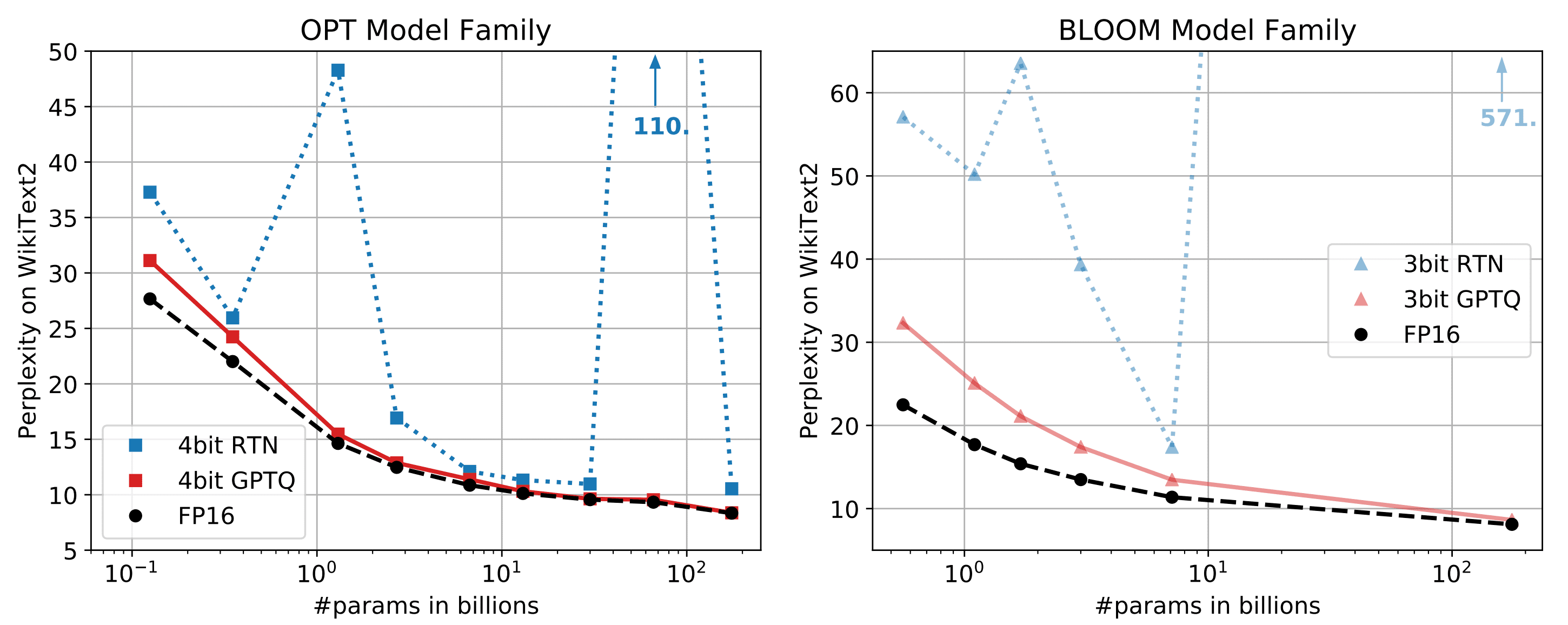
Inoltre, i grandi parametri di questi modelli hanno anche un effetto negativo gravoso sulla latenza di generazione dei token GPT perché la generazione di token GPT è più limitata dalla larghezza di banda della memoria (GB/s) che dalla computazione (TFLOP o TOP) stessa. Per questo motivo, un modello quantizzato non degrada la latenza di generazione dei token quando la GPU è in una situazione in cui la memoria è limitante. Si fa riferimento ai documenti di quantizzazione GPTQ e al repository Github .
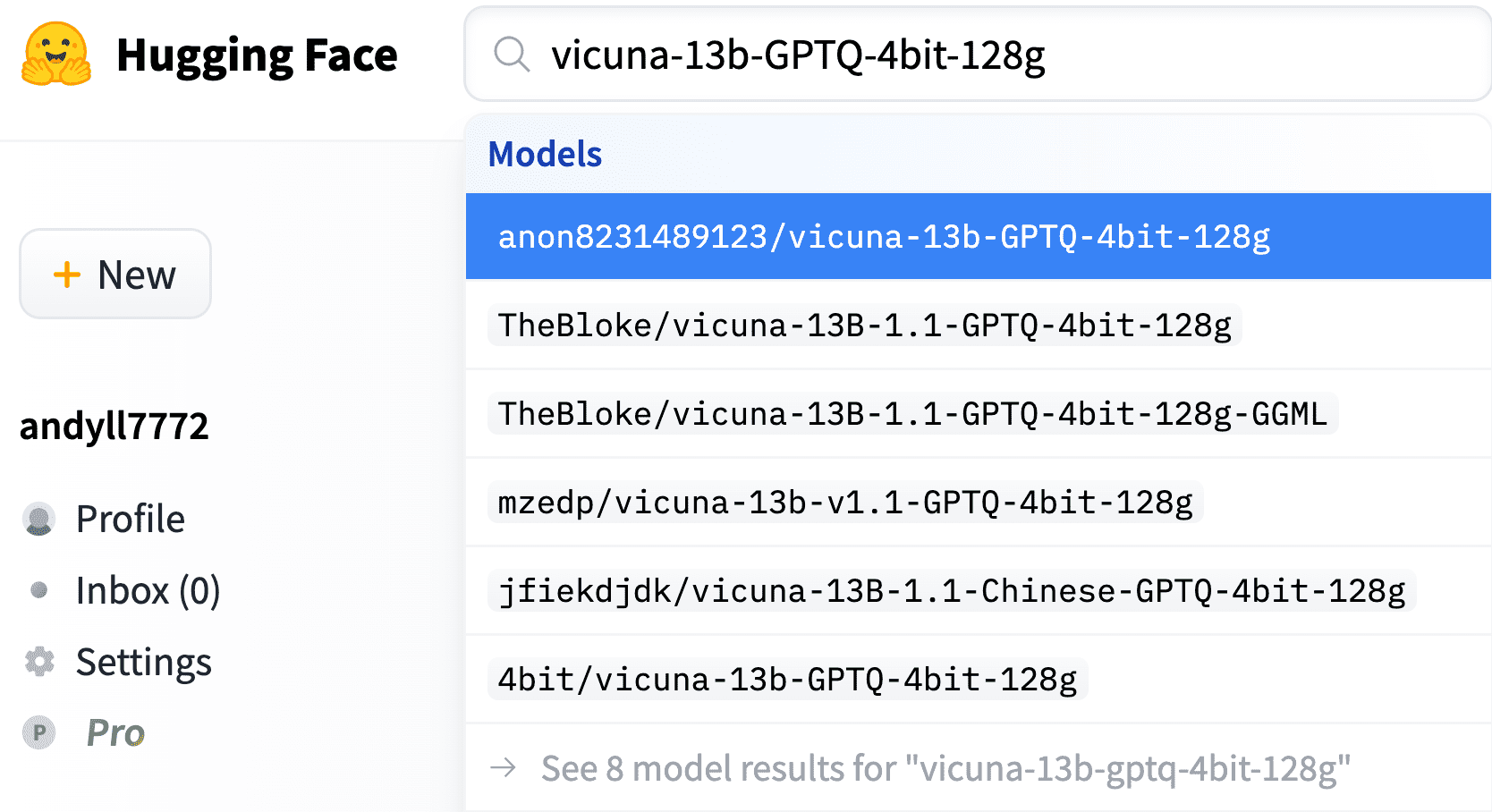
Sfruttando questa tecnica, sono disponibili diversi modelli Vicuna quantizzati a 4 bit su Hugging Face, come segue,
Esecuzione del modello Vicuna 13B su GPU AMD con ROCm
Per eseguire il modello Vicuna 13B su una GPU AMD, è necessario sfruttare la potenza di ROCm (Radeon Open Compute), una piattaforma software open-source che fornisce accelerazione GPU AMD per applicazioni di deep learning e di calcolo ad alte prestazioni.
Ecco una guida passo-passo su come configurare ed eseguire il modello Vicuna 13B su una GPU AMD con ROCm:
Requisiti di sistema
Prima di iniziare il processo di installazione, assicurarsi che il sistema soddisfi i seguenti requisiti:
-
Una GPU AMD che supporta ROCm (verificare l’elenco di compatibilità sulla pagina docs.amd.com)
-
Un sistema operativo basato su Linux, preferibilmente Ubuntu 18.04 o 20.04
-
Ambiente Conda o Docker
-
Python 3.6 o versioni successive
Per ulteriori informazioni, visita https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.4.3/page/Prerequisites.html .
Questo esempio è stato testato su GPU Instinct MI210 e Radeon RX6900XT con ROCm5.4.3 e Pytorch2.0.
Guida rapida
1 Installazione di ROCm e configurazione del container Docker (macchina host)
1.1 Installazione di ROCm
Di seguito è riportato il procedimento per ROCm5.4.3 e Ubuntu 22.04. Si prega di modificare in base alla versione ROCm e Ubuntu di destinazione da: https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.4.3/page/How_to_Install_ROCm.html
sudo apt update && sudo apt upgrade -y
wget https://repo.radeon.com/amdgpu-install/5.4.3/ubuntu/jammy/amdgpu-install_5.4.50403-1_all.deb
sudo apt-get install ./amdgpu-install_5.4.50403-1_all.deb
sudo amdgpu-install --usecase=hiplibsdk,rocm,dkms
sudo amdgpu-install --list-usecase
sudo reboot1.2 Verifica dell’installazione di ROCm
rocm-smi
sudo rocminfo1.3 Download dell’immagine Docker e avvio di un container Docker
Di seguito viene utilizzato Pytorch2.0 su ROCm5.4.2. Si prega di utilizzare l’immagine docker appropriata in base alla versione ROCm e Pytorch di destinazione: https://hub.docker.com/r/rocm/pytorch/tags
docker pull rocm/pytorch:rocm5.4.2_ubuntu20.04_py3.8_pytorch_2.0.0_preview
sudo docker run --device=/dev/kfd --device=/dev/dri --group-add video \
--shm-size=8g --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
--ipc=host -it --name vicuna_test -v ${PWD}:/workspace -e USER=${USER} \
rocm/pytorch:rocm5.4.2_ubuntu20.04_py3.8_pytorch_2.0.0_preview2 Quantizzazione del modello e inferenza del modello (all’interno del container Docker)
È possibile scaricare il modello Vicuna-13b quantizzato da Huggingface o quantizzare il modello a virgola mobile. Si prega di consultare Appendice – Quantizzazione del modello GPTQ se si desidera quantizzare il modello a virgola mobile.
2.1 Scarica il modello Vicuna-13b quantizzato
Utilizza lo script download-model.py dal seguente repository Git.
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
python download-model.py anon8231489123/vicuna-13b-GPTQ-4bit-128g- Esecuzione del modello Vicuna 13B GPTQ su GPU AMD
git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda
cd GPTQ-for-LLaMa
python setup_cuda.py installQuesti comandi compileranno e linkeranno i binari dei kernel equivalenti a CUDA HIPIFIED in
python come estensioni C. I kernel di questa implementazione sono composti da dequantizzazione + matrice FP32. Se si desidera utilizzare dequantizzazione + matrice FP16 per un ulteriore aumento delle prestazioni, si prega di consultare Appendice – Kernel GPTQ Dequantizzazione + FP16 per GPU AMD
git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda
cd GPTQ-for-LLaMa/
python setup_cuda.py install
# inferenza del modello
python llama_inference.py ../../models/vicuna-13b --wbits 4 --load \
../../models/vicuna-13b/vicuna-13b_4_actorder.safetensors --groupsize 128 --text "Inserisci qui il tuo testo di input"Ora che hai tutto configurato, è il momento di eseguire il modello Vicuna 13B sulla tua GPU AMD. Utilizza i comandi sopra per eseguire il modello. Sostituisci “Il tuo testo di input qui” con il testo che desideri utilizzare come input per il modello. Se tutto è stato configurato correttamente, dovresti vedere il modello generare un testo di output in base al tuo input.
3. Esponi il modello Vicuna quantizzato al server API Web
Cambia il percorso dei moduli Python GPTQ (GPTQ-for-LLaMa) nella seguente riga:
https://github.com/thisserand/FastChat/blob/4a57c928a906705404eae06f7a44b4da45828487/fastchat/serve/load_gptq_model.py#L7
Per avviare l’interfaccia utente Web dalla libreria gradio, è necessario configurare il controller, il worker (Vicuna model worker) e il server web eseguendoli come processi in background.
nohup python0 -W ignore::UserWarning -m fastchat.serve.controller &
nohup python0 -W ignore::UserWarning -m fastchat.serve.model_worker --model-path /percorso/verso/pesi_vicuna_quantizzati \
--model-name vicuna-13b-quantization --wbits 4 --groupsize 128 &
nohup python0 -W ignore::UserWarning -m fastchat.serve.gradio_web_server &Ora il modello Vicuna-13B quantizzato a 4 bit può essere adattato alla memoria DDR della GPU RX6900XT, che dispone di 16GB di DDR. Sono necessari solo 7,52GB di DDR (46% dei 16GB) per eseguire modelli da 13B, mentre il modello ha bisogno di più di 28GB di spazio DDR nel formato fp16. La penalità di latenza e la penalità di accuratezza sono anche molto minime e le metriche correlate sono fornite alla fine di questo articolo.

Testa il modello Vicuna quantizzato nel server API Web
Diamo un’occhiata. Innanzitutto, utilizziamo il modello Vicuna fp16 per la traduzione del linguaggio.

Lo fa meglio di me. Successivamente, chiediamo qualcosa sul calcio. La risposta sembra buona.
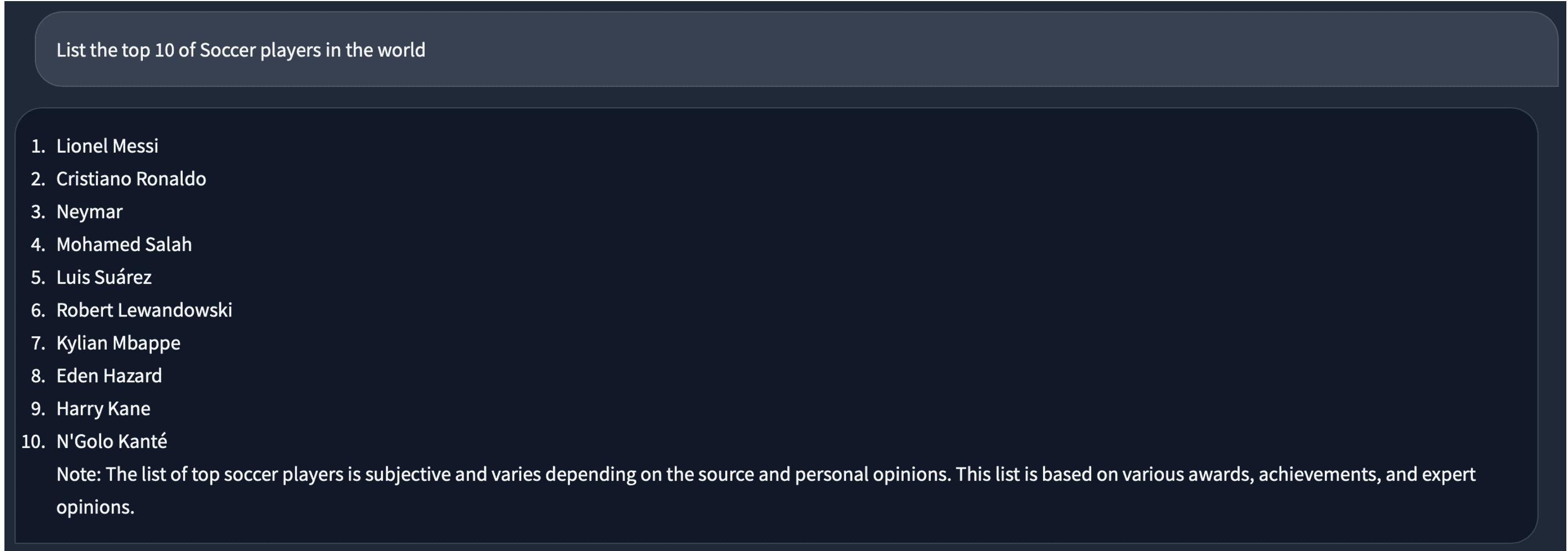
Quando passiamo al modello a 4 bit, per la stessa domanda, la risposta è leggermente diversa. C’è un duplicato di “Lionel Messi” in essa.
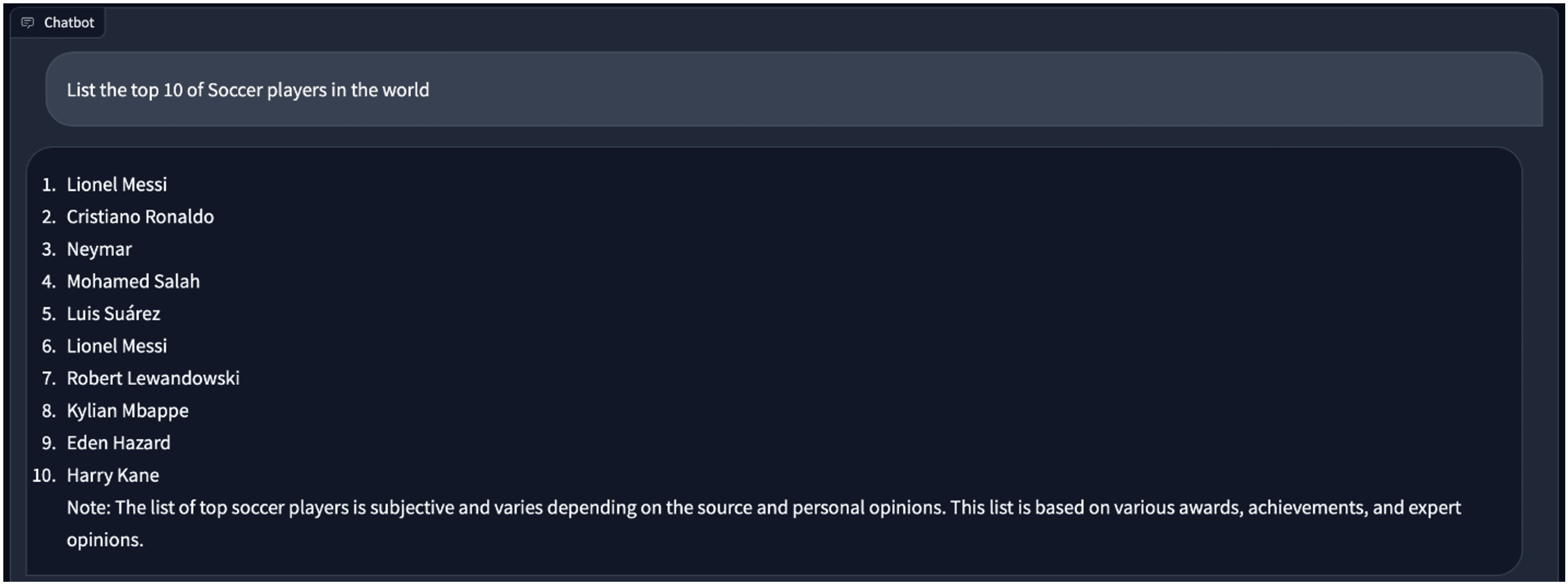
Confronto tra il modello Vicuna fp16 e il modello quantizzato a 4 bit
Ambiente di test:
– GPU: Instinct MI210, RX6900XT
– python: 3.10
– pytorch: 2.1.0a0+gitfa08e54
– rocm: 5.4.3
Metriche – Dimensione del modello (GB)
- Dimensione dei parametri del modello. Quando i modelli vengono precaricati nella memoria DDR della GPU, il consumo effettivo di DDR è maggiore rispetto al modello stesso a causa della memorizzazione nella cache per gli spazi di token di input e output.

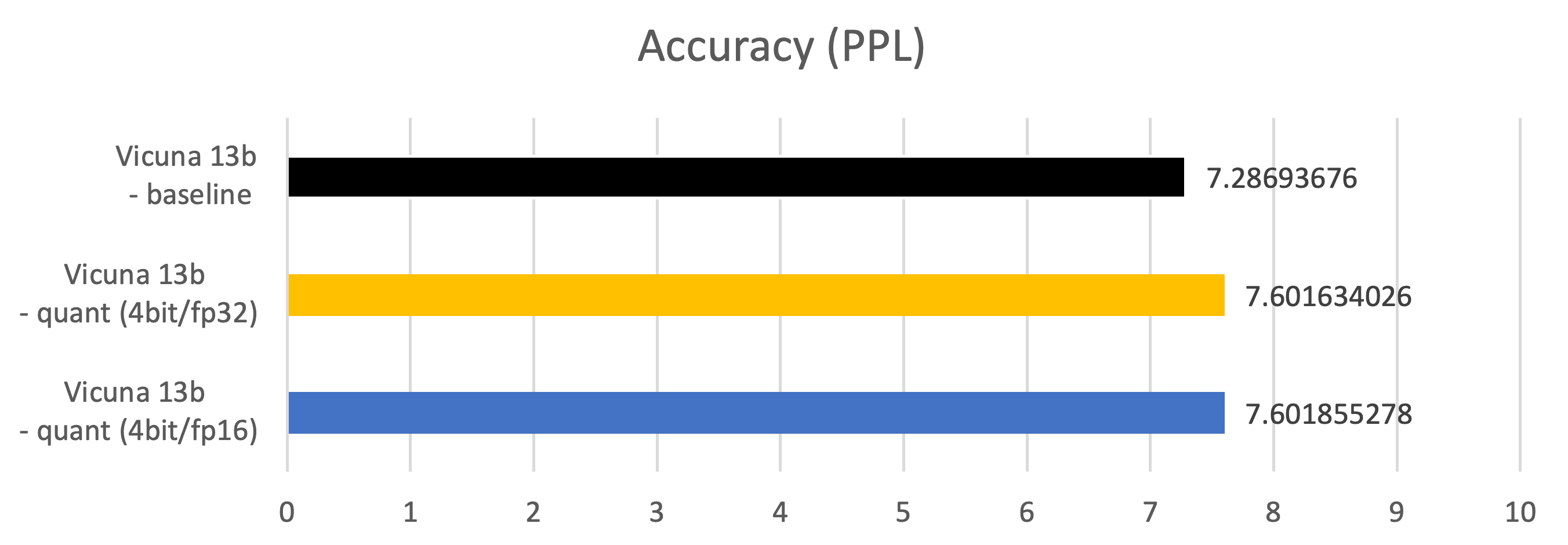
Metriche – Precisione (PPL: Perplexity)
-
Misurato su 2048 esempi del dataset C4 (https://paperswithcode.com/dataset/c4)
-
Vicuna 13b – baseline: parametro di tipo fp16, matrice di tipo fp16
-
Vicuna 13b – quant (4bit/fp32): parametro di tipo 4 bit, matrice di tipo fp32
-
Vicuna 13b – quant (4bit/fp16): parametro di tipo 4 bit, matrice di tipo fp16
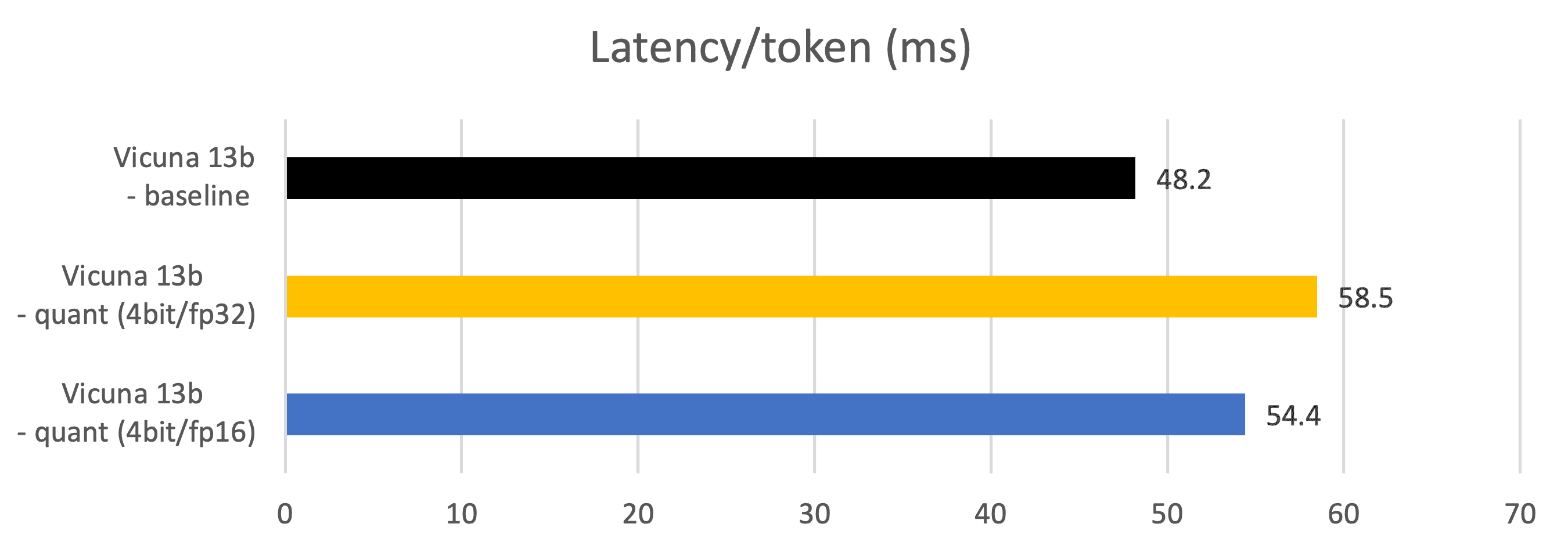
Metriche – Latenza (Latenza di generazione dei token, ms)
-
Misurato durante le fasi di generazione dei token.
-
Vicuna 13b – baseline: parametro di tipo fp16, matrice di tipo fp16
-
Vicuna 13b – quant (4bit/fp32): parametro di tipo 4 bit, matrice di tipo fp32
-
Vicuna 13b – quant (4bit/fp16): parametro di tipo 4 bit, matrice di tipo fp16
Conclusion
I modelli di linguaggio di grandi dimensioni (LLM) hanno fatto progressi significativi nei sistemi di chatbot, come si vede in ChatGPT di OpenAI. Vicuna-13B, un modello LLM open-source, è stato sviluppato e ha dimostrato un’eccellente capacità e qualità.
Seguendo questa guida, ora dovresti avere una migliore comprensione di come configurare e eseguire il modello Vicuna 13B su una GPU AMD con ROCm. Ciò ti permetterà di sfruttare appieno il potenziale di questo modello di linguaggio all’avanguardia per le tue ricerche e progetti personali.
Grazie per la lettura!
Appendice – Quantizzazione del modello GPTQ
Costruzione del modello Vicuna quantizzato a partire dal modello LLaMA in floating point
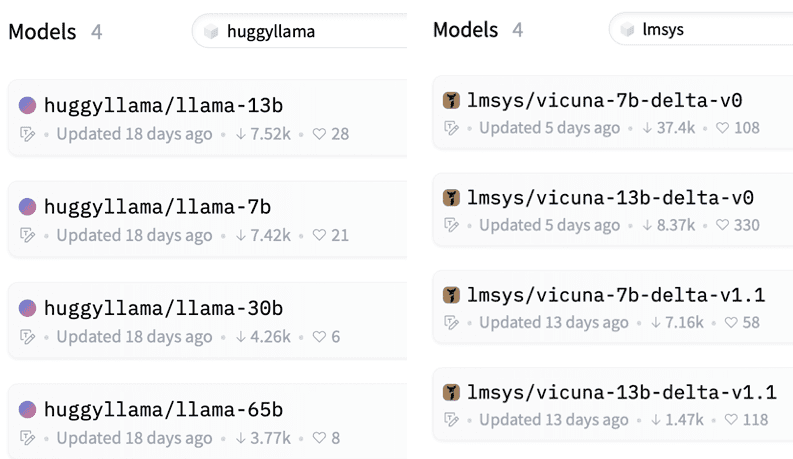
a. Scarica i modelli LLaMA e Vicuna delta da Huggingface
Gli sviluppatori di Vicuna (lmsys) forniscono solo modelli delta che possono essere applicati al modello LLaMA. Scarica LLaMA nel formato di huggingface e i parametri delta di Vicuna separatamente. Attualmente sono disponibili i modelli delta di Vicuna da 7b e 13b.
https://huggingface.co/models?sort=downloads&search=huggyllama
https://huggingface.co/models?sort=downloads&search=lmsys
b. Converti LLaMA in Vicuna utilizzando il modello Vicuna-delta
git clone https://github.com/lm-sys/FastChat
cd FastChatConverti i parametri LLaMA utilizzando questo comando:
(Nota: non utilizzare vicuna-{7b, 13b}-*delta-v0 perché ha una dimensione del vocabolario diversa da quella di LLaMA e il modello non può essere convertito)
python -m fastchat.model.apply_delta --base /path/to/llama-13b --delta lmsys/vicuna-13b-delta-v1.1 \
--target ./vicuna-13b Ora il modello Vicuna-13b è pronto.
c. Quantizza Vicuna a 2/3/4 bit
Per applicare il GPTQ a LLaMA e Vicuna,
git clone https://github.com/oobabooga/GPTQ-for-LLaMa -b cuda
cd GPTQ-for-LLaMa(Nota, al momento non utilizzare https://github.com/qwopqwop200/GPTQ-for-LLaMa. Poiché la quantizzazione a 2,3,4 bit + i kernel MatMul implementati in questo repository non parallelizzano il dequant+matmul e quindi mostrano una performance di generazione di token inferiore)
Quantizza il modello Vicuna-13b con questo comando. L’addestramento quantizzato è basato sul data-set c4, ma è possibile utilizzare anche altri data-set, come wikitext2
(Nota. Cambia la dimensione del gruppo con diverse combinazioni fintanto che l’accuratezza del modello aumenta significativamente. Con alcune combinazioni di wbit e dimensione del gruppo, l’accuratezza del modello può aumentare significativamente.)
python llama.py ./Vicuna-13b c4 --wbits 4 --true-sequential --act-order \
--save_safetensors Vicuna-13b-4bit-act-order.safetensorsOra il modello è pronto e salvato come Vicuna-13b-4bit-act-order.safetensors.
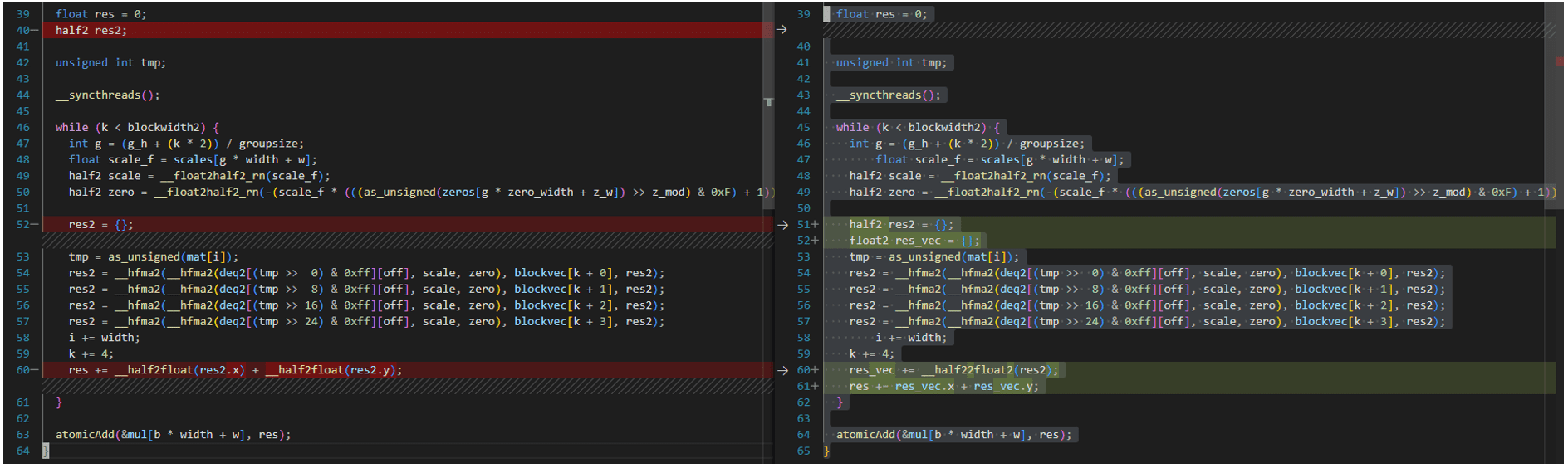
GPTQ Dequantization + Kernel Mamul FP16 per GPU AMD
L’implementazione del kernel più ottimizzata in https://github.com/oobabooga/GPTQ-for-LLaMa/blob/57a26292ed583528d9941e79915824c5af012279/quant_cuda_kernel.cu#L891
è rivolta alla GPU A100 e non è compatibile con gli strumenti ROCM5.4.3 HIPIFY. Deve essere modificato come segue. Lo stesso vale per i kernel VecQuant2MatMulKernelFaster, VecQuant3MatMulKernelFaster, VecQuant4MatMulKernelFaster.
Per comodità, tutti i codici modificati sono disponibili su Github Gist.




