Presentazione dell’integrazione di BERTopic con Hugging Face Hub
Integrazione di BERTopic con Hugging Face Hub.
![]()
Siamo entusiasti di annunciare un importante aggiornamento della libreria Python BERTopic, che espande le sue capacità e semplifica ulteriormente il flusso di lavoro per gli appassionati e i professionisti del topic modelling. BERTopic supporta ora il caricamento e il recupero di modelli di topic addestrati direttamente da e verso il Hugging Face Hub. Questa nuova integrazione apre interessanti possibilità per sfruttare la potenza di BERTopic in casi d’uso di produzione con facilità.
Che cos’è il Topic Modelling?
Il topic modelling è un metodo che può aiutare a scoprire temi nascosti o “topic” all’interno di un gruppo di documenti. Analizzando le parole nei documenti, possiamo trovare pattern e connessioni che rivelano questi topic sottostanti. Ad esempio, un documento sul machine learning è più probabile che utilizzi parole come “gradient” e “embedding” rispetto a un documento sulla panificazione del pane.
Ogni documento di solito copre più topic in proporzioni diverse. Esaminando le statistiche delle parole, possiamo identificare cluster di parole correlate che rappresentano questi topic. Ciò ci consente di analizzare un insieme di documenti e determinare i topic di cui parlano, così come l’equilibrio dei topic all’interno di ciascun documento. Più di recente, nuovi approcci al topic modelling hanno superato l’uso delle parole per utilizzare rappresentazioni più ricche come quelle offerte dai modelli basati su Transformer.
- Presentazione del contenitore di inferenza LLM di Hugging Face per Amazon SageMaker
- Hugging Face selezionata per il Programma di Supporto Avanzato dell’Agenzia Francese per la Protezione dei Dati
- Annunciamo la Open Source AI Game Jam 🎮
Che cos’è BERTopic?
BERTopic è una libreria Python all’avanguardia che semplifica il processo di topic modelling utilizzando varie tecniche di embedding e c-TF-IDF per creare cluster densi che consentono di interpretare facilmente i topic mantenendo le parole importanti nelle descrizioni dei topic.
Una panoramica della libreria BERTopic
Sebbene BERTopic sia facile da iniziare, supporta una serie di approcci avanzati al topic modelling, inclusi il topic modelling guidato, supervisionato, semi-supervisionato e manuale. Più di recente, BERTopic ha aggiunto il supporto per i modelli di topic multimodali. BERTopic dispone anche di un ricco set di strumenti per produrre visualizzazioni.
BERTopic fornisce uno strumento potente agli utenti per scoprire topic significativi all’interno di collezioni di testo, ottenendo così preziose informazioni. Con BERTopic, gli utenti possono analizzare recensioni dei clienti, esplorare articoli di ricerca o categorizzare articoli di notizie con facilità, rendendolo uno strumento essenziale per chiunque cerchi di estrarre informazioni significative dai propri dati di testo.
Gestione dei modelli BERTopic con il Hugging Face Hub
Con l’ultima integrazione, gli utenti di BERTopic possono facilmente caricare e scaricare i loro modelli di topic addestrati da e verso il Hugging Face Hub. Questa integrazione segna una tappa significativa nel semplificare la distribuzione e la gestione dei modelli BERTopic su diversi ambienti.
Il processo di addestramento e caricamento di un modello BERTopic sul Hub può essere fatto in poche righe
from bertopic import BERTopic
topic_model = BERTopic("english")
topics, probs = topic_model.fit_transform(docs)
topic_model.push_to_hf_hub('davanstrien/transformers_issues_topics')Poi è possibile caricare questo modello in due righe e utilizzarlo per effettuare previsioni su nuovi dati.
from bertopic import BERTopic
topic_model = BERTopic.load("davanstrien/transformers_issues_topics")Sfruttando la potenza del Hugging Face Hub, gli utenti di BERTopic possono condividere, versionare e collaborare facilmente sui loro modelli di topic. Il Hub funge da deposito centrale, consentendo agli utenti di archiviare e organizzare i propri modelli, semplificando così la distribuzione dei modelli in produzione, la condivisione con i colleghi o persino la presentazione alla più ampia comunità di NLP.
È possibile utilizzare il filtro libraries sul Hub per trovare modelli BERTopic.
Una volta trovato un modello BERTopic di interesse, è possibile utilizzare il widget di inferenza del Hub per provare il modello e vedere se potrebbe essere adatto al proprio caso d’uso.
Una volta ottenuto un modello di topic addestrato, è possibile caricarlo sul Hugging Face Hub in una sola riga. Il caricamento del modello sul Hub creerà automaticamente una scheda iniziale per il modello, includendo una panoramica dei topic creati. Di seguito puoi vedere un esempio dei topic risultanti da un modello addestrato sui dati di ArXiv.
Fai clic qui per una panoramica di tutti i topic.
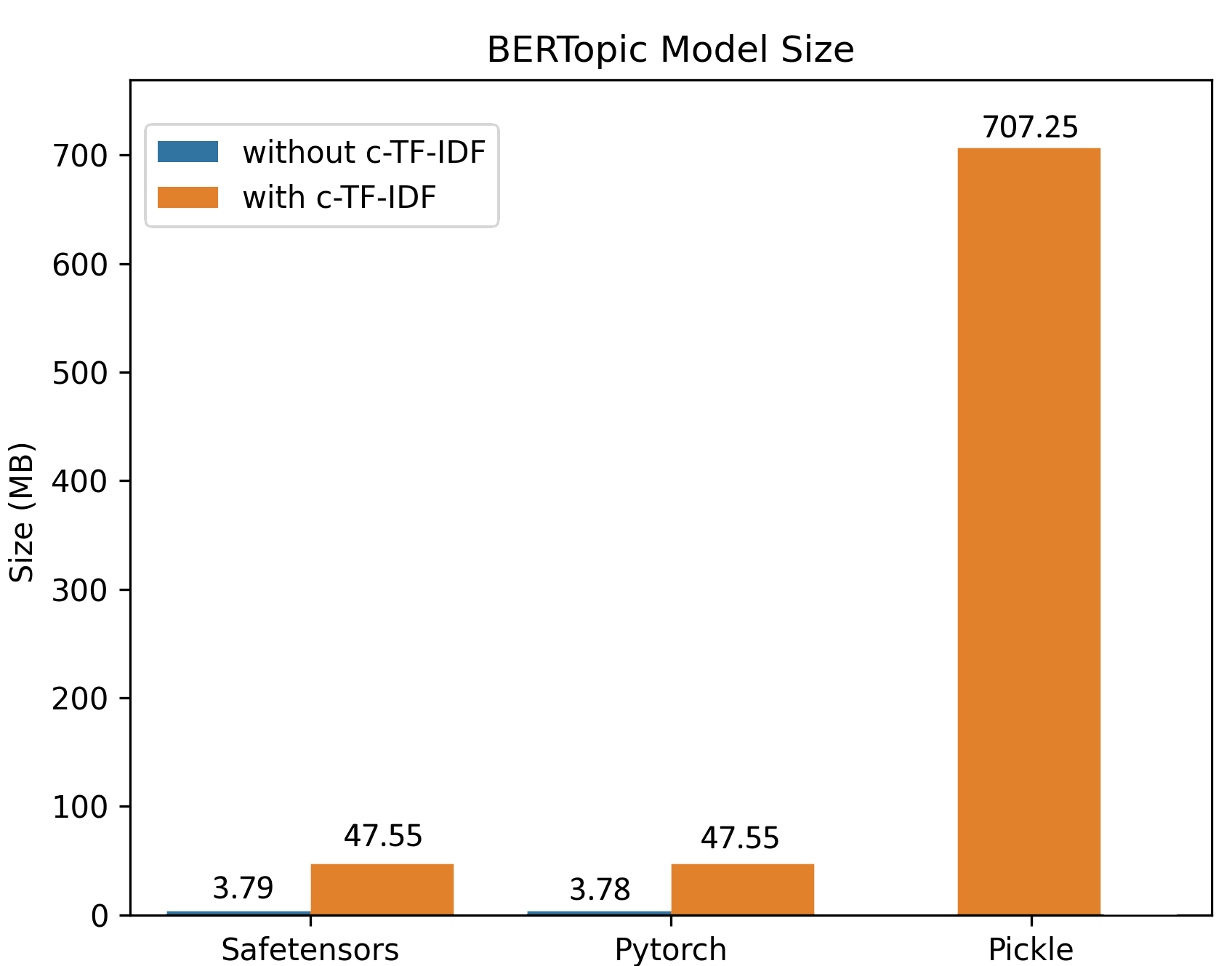
Grazie al miglioramento della procedura di salvataggio, l’addestramento su grandi dataset genera dimensioni di modello ridotte. Nell’esempio qui sotto, un modello BERTopic è stato addestrato su 100.000 documenti, con un modello di circa 50 MB che mantiene tutte le funzionalità dell’originale. Per l’inferenza, il modello può essere ulteriormente ridotto a soli ~3 MB!
 I vantaggi di questa integrazione sono particolarmente notevoli per casi d’uso in produzione. Gli utenti ora possono facilmente implementare modelli BERTopic nelle loro applicazioni o sistemi esistenti, garantendo un’integrazione senza soluzione di continuità all’interno delle loro pipeline di dati. Questo flusso di lavoro efficiente consente un’iterazione più rapida e aggiornamenti efficienti del modello e garantisce coerenza tra diversi ambienti.
I vantaggi di questa integrazione sono particolarmente notevoli per casi d’uso in produzione. Gli utenti ora possono facilmente implementare modelli BERTopic nelle loro applicazioni o sistemi esistenti, garantendo un’integrazione senza soluzione di continuità all’interno delle loro pipeline di dati. Questo flusso di lavoro efficiente consente un’iterazione più rapida e aggiornamenti efficienti del modello e garantisce coerenza tra diversi ambienti.
safetensors: Garantire una gestione sicura del modello
Oltre all’integrazione di Hugging Face Hub, BERTopic supporta ora la serializzazione utilizzando la libreria safetensors. Safetensors è un nuovo formato semplice per memorizzare tensori in modo sicuro (anziché pickle), che è comunque veloce (zero-copy). Siamo entusiasti di vedere sempre più librerie che sfruttano safetensors per una serializzazione sicura. Puoi leggere di più su un recente audit della libreria in questo post del blog.
Un esempio di utilizzo di BERTopic per esplorare dataset RLFH
Per illustrare parte della potenza di BERTopic, vediamo un esempio di come può essere utilizzato per monitorare i cambiamenti negli argomenti nei dataset utilizzati per addestrare modelli di chat.
L’ultimo anno ha visto il rilascio di diversi dataset per il Reinforcement Learning con Feedback Umano. Uno di questi dataset è il dataset delle Conversazioni di OpenAssistant. Questo dataset è stato prodotto attraverso uno sforzo di crowd-sourcing a livello mondiale che ha coinvolto oltre 13.500 volontari. Anche se questo dataset ha già alcuni punteggi per tossicità, qualità, umorismo, ecc., potremmo voler avere una migliore comprensione dei tipi di conversazioni rappresentate in questo dataset.
BERTopic offre un modo per ottenere una migliore comprensione degli argomenti in questo dataset. In questo caso, addestriamo un modello sulle risposte degli assistenti in inglese dei dataset, ottenendo così un modello di argomento con 75 argomenti.
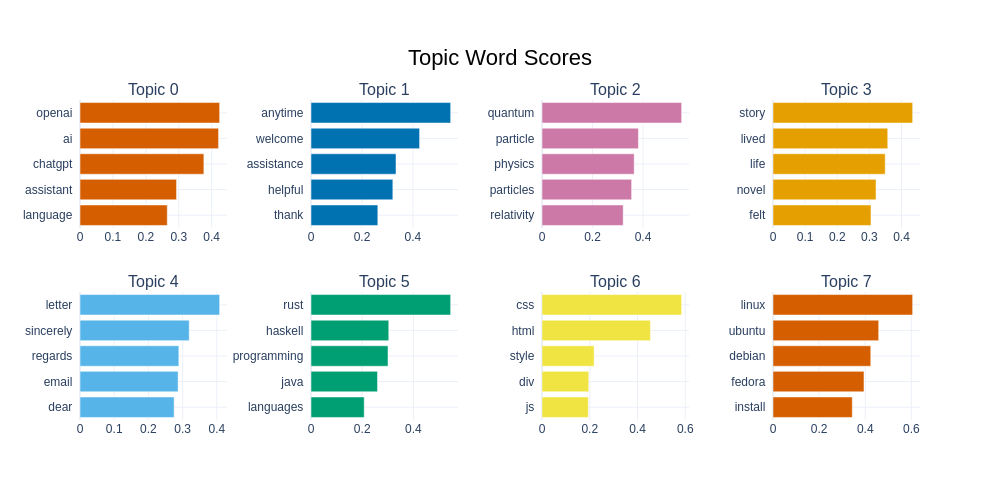
BERTopic ci offre vari modi per visualizzare un dataset. Possiamo vedere i primi 8 argomenti e le parole associate di seguito. Possiamo notare che il secondo argomento più frequente consiste principalmente di ‘parole di risposta’, che spesso vediamo frequentemente nei modelli di chat, cioè risposte che mirano ad essere ‘gentili’ e ‘utili’. Possiamo anche vedere un gran numero di argomenti legati alla programmazione o agli argomenti informatici, così come alla fisica, alle ricette e agli animali domestici.
databricks/databricks-dolly-15k è un altro dataset che può essere utilizzato per addestrare un modello RLFH. L’approccio seguito per la creazione di questo dataset è stato molto diverso rispetto al dataset delle Conversazioni di OpenAssistant, poiché è stato creato da dipendenti di Databricks anziché tramite crowd-sourcing tramite volontari. Forse possiamo utilizzare il nostro modello BERTopic addestrato per confrontare gli argomenti tra questi due dataset?
Le nuove integrazioni di BERTopic Hub significano che possiamo caricare questo modello addestrato e applicarlo a nuovi esempi.
topic_model = BERTopic.load("davanstrien/chat_topics")Possiamo fare una previsione su un singolo esempio di testo:
example = "Lo stallo è una posizione pareggiata. Non importa chi ha catturato più pezzi o è in una posizione vincente"
argomento, probabilità = topic_model.transform(example)Possiamo ottenere ulteriori informazioni sull’argomento previsto:
topic_model.get_topic_info(argomento)Possiamo vedere qui che gli argomenti previsti sembrano avere senso. Potremmo voler estendere questo confronto per confrontare gli argomenti previsti per l’intero dataset.
from datasets import load_dataset
dataset = load_dataset("databricks/databricks-dolly-15k")
dolly_docs = dataset['train']['response']
dolly_argomenti, dolly_probabilità = topic_model.transform(dolly_docs)Poi possiamo confrontare la distribuzione degli argomenti tra entrambi i dataset. Possiamo vedere qui che sembra esserci una distribuzione più ampia degli argomenti nel dataset dolly secondo il nostro modello BERTopic. Questo potrebbe essere il risultato di approcci diversi alla creazione di entrambi i dataset (probabilmente vorremmo addestrare nuovamente un BERTopic su entrambi i dataset per assicurarci di non perdere argomenti per confermare questo).
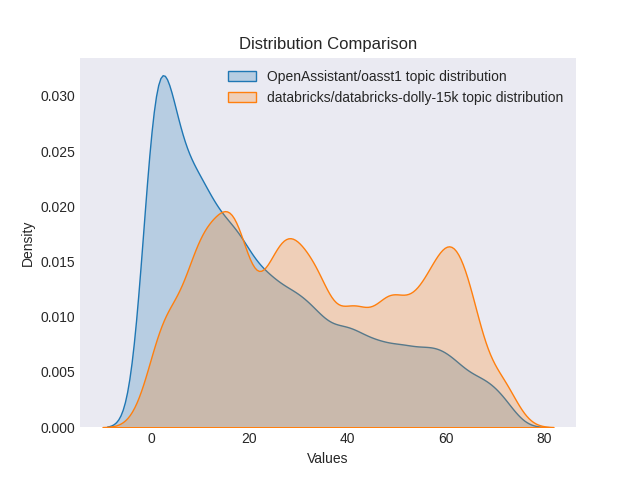
Confronto della distribuzione degli argomenti tra i due set di dati
Potremmo potenzialmente utilizzare modelli di argomenti in un ambiente di produzione per monitorare se gli argomenti si discostano troppo da una distribuzione attesa. Questo può fungere da segnale che c’è stato un cambiamento tra i tuoi dati di addestramento originali e i tipi di conversazioni che stai vedendo in produzione. Potresti anche decidere di utilizzare un modello di argomenti durante la raccolta dei dati di addestramento per assicurarti di ottenere esempi per gli argomenti che potrebbero interessarti particolarmente.
Inizia con BERTopic e Hugging Face Hub
Puoi visitare la documentazione ufficiale per una guida rapida per ottenere aiuto nell’uso di BERTopic.
Puoi trovare un notebook di Colab di avvio qui che mostra come puoi addestrare un modello BERTopic e caricarlo sul Hub.
Alcuni esempi di modelli BERTopic già presenti nel hub:
- MaartenGr/BERTopic_ArXiv : un modello addestrato su ~30000 articoli di Computation and Language di ArXiv (cs.CL) dopo il 1991.
- MaartenGr/BERTopic_Wikipedia : un modello addestrato su 1000000 pagine in inglese di Wikipedia.
- davanstrien/imdb_bertopic : un modello addestrato sulla suddivisione non supervisionata del dataset IMDB
Puoi trovare una panoramica completa dei modelli BERTopic presenti nel hub utilizzando il filtro delle librerie
Ti invitiamo a esplorare le possibilità di questa nuova integrazione e a condividere i tuoi modelli addestrati sul hub!






