Un’immersione nei modelli di testo-a-video
'Esplorazione dei modelli di testo-a-video'
 Esempi di video generati con ModelScope .
Esempi di video generati con ModelScope .
Il text-to-video è il prossimo passo nella lunga lista di incredibili avanzamenti nei modelli generativi. Come suggerisce il nome stesso, il text-to-video è un compito di computer vision abbastanza nuovo che consiste nella generazione di una sequenza di immagini da descrizioni testuali che siano coerenti sia temporalmente che spazialmente. Sebbene questo compito possa sembrare estremamente simile al text-to-image, è notoriamente più difficile. Come funzionano questi modelli, in cosa si differenziano dai modelli text-to-image e quale tipo di prestazioni possiamo aspettarci da loro?
In questo post sul blog, discuteremo del passato, del presente e del futuro dei modelli text-to-video. Inizieremo esaminando le differenze tra i compiti text-to-video e text-to-image e discuteremo le sfide uniche della generazione di video incondizionati e condizionati al testo. Inoltre, copriremo gli sviluppi più recenti nei modelli text-to-video, esplorando come funzionano questi metodi e cosa sono in grado di fare. Infine, parleremo di ciò su cui stiamo lavorando in Hugging Face per agevolare l’integrazione e l’uso di questi modelli e condivideremo alcuni demo e risorse interessanti sia all’interno che all’esterno dell’Hugging Face Hub.
 Esempi di video generati da diversi input di descrizione testuale, immagine tratta da Make-a-Video .
Esempi di video generati da diversi input di descrizione testuale, immagine tratta da Make-a-Video .
- Generazione Assistita una nuova direzione verso la generazione di testi a bassa latenza
- Presentando RWKV – Una RNN con i vantaggi di un transformer
- Esegui un Chatbot simile a Chatgpt su una singola GPU con ROCm
Text-to-Video vs. Text-to-Image
Con così tanti sviluppi recenti, può essere difficile tenere il passo con lo stato attuale dei modelli generativi text-to-image. Iniziamo con un breve riepilogo.
Solo due anni fa sono emersi i primi modelli generativi di alta qualità per il text-to-image con vocabolario aperto. Questa prima ondata di modelli text-to-image, tra cui VQGAN-CLIP, XMC-GAN e GauGAN2, aveva tutte architetture GAN. A questi sono seguiti rapidamente il popolarissimo DALL-E di OpenAI, basato su trasformatori, all’inizio del 2021, il DALL-E 2 nell’aprile 2022 e una nuova ondata di modelli di diffusione sviluppati da Stable Diffusion e Imagen. L’enorme successo di Stable Diffusion ha portato a molti modelli di diffusione prodotti, come DreamStudio e RunwayML GEN-1, e all’integrazione con prodotti esistenti, come Midjourney.
Nonostante le impressionanti capacità dei modelli di diffusione nella generazione text-to-image, i modelli text-to-video basati sulla diffusione e non, sono significativamente più limitati nelle loro capacità generative. I modelli text-to-video sono tipicamente addestrati su clip molto brevi, il che richiede un approccio di finestra scorrevole computazionalmente costoso e lento per generare video lunghi. Di conseguenza, questi modelli sono notoriamente difficili da implementare e scalare e rimangono limitati nel contesto e nella durata.
Il compito text-to-video presenta sfide uniche su più fronti. Alcune di queste principali sfide includono:
- Sfide computazionali: Garantire la coerenza spaziale e temporale tra i fotogrammi crea dipendenze a lungo termine che comportano un alto costo computazionale, rendendo l’addestramento di tali modelli non accessibile per la maggior parte dei ricercatori.
- Mancanza di dataset di alta qualità: I dataset multimodali per la generazione text-to-video sono scarsi e spesso scarsamente annotati, rendendo difficile apprendere la semantica del movimento complesso.
- Indeterminatezza della descrizione dei video: Descrivere i video in modo che siano più facili da apprendere per i modelli è una questione aperta. È necessario più di un breve prompt di testo per fornire una descrizione video completa. Un video generato deve essere condizionato da una sequenza di prompt o una storia che narra ciò che accade nel tempo.
Nella prossima sezione, discuteremo la cronologia degli sviluppi nel dominio del text-to-video e i vari metodi proposti per affrontare separatamente queste sfide. A un livello più alto, i lavori text-to-video propongono una di queste soluzioni:
- Nuovi dataset di qualità superiore che sono più facili da apprendere.
- Metodi per addestrare tali modelli senza dati testo-video accoppiati.
- Metodi più efficienti dal punto di vista computazionale per generare video più lunghi e ad alta risoluzione.
Come Generare Video da Testo?
Diamo un’occhiata a come funziona la generazione text-to-video e agli ultimi sviluppi in questo campo. Esploreremo come i modelli text-to-video si sono evoluti, seguendo un percorso simile alla ricerca text-to-image, e come finora sono state affrontate le sfide specifiche della generazione text-to-video.
Come per il compito text-to-image, i primi lavori sulla generazione text-to-video risalgono solo a pochi anni fa. Le prime ricerche hanno principalmente utilizzato approcci basati su GAN e VAE per generare in modo auto-regressivo i fotogrammi dati una didascalia (vedi Text2Filter e TGANs-C ). Sebbene questi lavori abbiano fornito le basi per un nuovo compito di computer vision, sono limitati a basse risoluzioni, a breve raggio e a movimenti singoli e isolati.
 I modelli iniziali di generazione di testo in video erano estremamente limitati in risoluzione, contesto e durata, immagine tratta da TGANs-C.
I modelli iniziali di generazione di testo in video erano estremamente limitati in risoluzione, contesto e durata, immagine tratta da TGANs-C.
Prendendo ispirazione dal successo dei modelli di trasformatori preaddestrati su larga scala nel campo del testo (GPT-3) e delle immagini (DALL-E), la successiva ondata di ricerca sulla generazione di testo in video ha adottato architetture basate su trasformatori. Phenaki, Make-A-Video, NUWA, VideoGPT e CogVideo propongono tutti framework basati su trasformatori, mentre opere come TATS propongono metodi ibridi che combinano VQGAN per la generazione di immagini e un modulo trasformatore sensibile al tempo per la generazione sequenziale dei fotogrammi. Tra queste opere della seconda ondata, Phenaki è particolarmente interessante in quanto consente di generare video di lunghezza arbitraria condizionati a una sequenza di prompt, in altre parole, una trama. Allo stesso modo, NUWA-Infinity propone un meccanismo di generazione autoregressivo su generazione autoregressiva per la sintesi infinita di immagini e video dai testi di input, consentendo la generazione di video di lunga durata e di alta qualità. Tuttavia, né i modelli Phenaki né quelli NUWA sono disponibili pubblicamente.
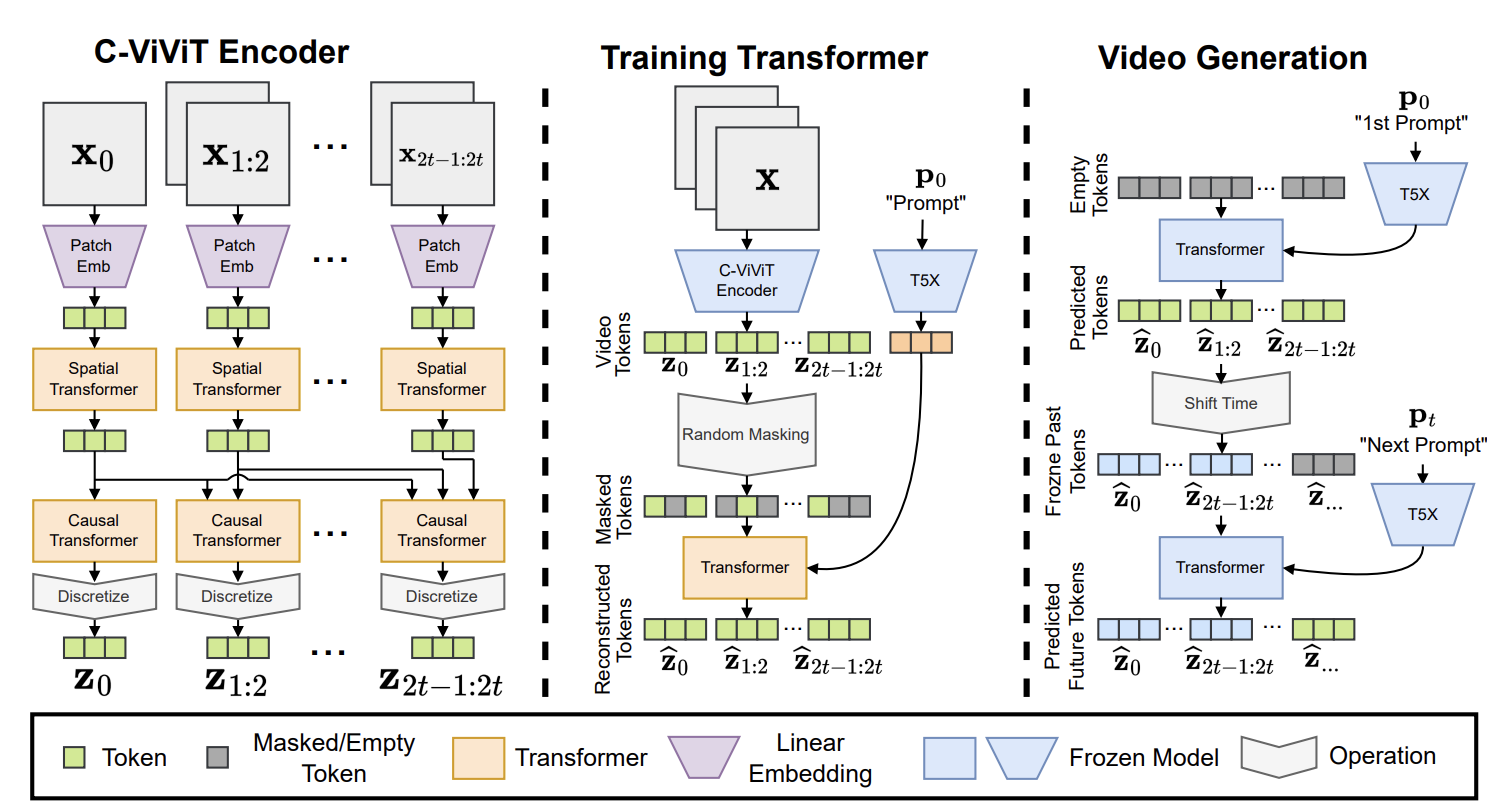 Phenaki presenta un’architettura basata su trasformatori, immagine tratta da qui.
Phenaki presenta un’architettura basata su trasformatori, immagine tratta da qui.
La terza e attuale ondata di modelli di testo in video presenta prevalentemente architetture basate sulla diffusione. Il notevole successo dei modelli di diffusione nella generazione di immagini diverse, iperrealistiche e ricche di contesto ha suscitato interesse nell’estendere i modelli di diffusione ad altri domini come l’audio, il 3D e, più recentemente, il video. Questa ondata di modelli è stata inaugurata dai Video Diffusion Models (VDM), che estendono i modelli di diffusione al dominio dei video, e da MagicVideo, che propone un framework per generare clip video in uno spazio latente a bassa dimensione e riporta enormi miglioramenti in termini di efficienza rispetto a VDM. Un’altra menzione degna di nota è Tune-a-Video, che adatta un modello preaddestrato di testo-immagine con una singola coppia di testo-video e consente di modificare il contenuto video preservando il movimento. La lista in continua espansione dei modelli di diffusione di testo in video che sono seguiti include Video LDM, Text2Video-Zero, Runway Gen1 e Gen2 e NUWA-XL.
Text2Video-Zero è un framework di generazione e manipolazione di video guidato dal testo che funziona in modo simile a ControlNet. Può generare direttamente (o modificare) video basati su input testuali, nonché input di dati combinati testo-posa o testo-bordo. Come suggerisce il nome, Text2Video-Zero è un modello zero-shot che combina un modulo di dinamiche di movimento addestrabile con un modello di diffusione stabile preaddestrato di testo-immagine senza utilizzare alcun dato testo-video accoppiato. Analogamente a Text2Video-Zero, i modelli Gen-1 e Gen-2 di Runway consentono di sintetizzare video guidati da contenuti descritti attraverso testo o immagini. La maggior parte di queste opere è addestrata su brevi clip video e si basa sulla generazione autoregressiva con una finestra scorrevole per generare video più lunghi, risultando inevitabilmente in una lacuna di contesto. NUWA-XL affronta questo problema e propone un metodo di “diffusione su diffusione” per addestrare i modelli su 3376 fotogrammi. Infine, ci sono modelli e framework di testo in video open-source come ModelScope di Alibaba / DAMO Vision Intelligence Lab e VideoCrafter di Tencel, che non sono stati pubblicati in conferenze o riviste peer-reviewed.
Set di dati
Come altri modelli di visione-linguaggio, i modelli di testo in video sono tipicamente addestrati su grandi set di dati accoppiati di video e descrizioni testuali. I video in questi set di dati sono solitamente suddivisi in brevi segmenti di lunghezza fissa e spesso limitati ad azioni isolate con pochi oggetti. Questo è in parte dovuto a limitazioni computazionali e in parte alla difficoltà di descrivere il contenuto video in modo significativo, ma si nota che gli sviluppi nei set di dati multimodali video-testo e nei modelli di testo in video sono spesso intrecciati. Mentre alcuni lavori si concentrano nello sviluppare set di dati migliori e più generalizzabili che siano più facili da apprendere, opere come Phenaki esplorano soluzioni alternative come la combinazione di coppie testo-immagine con coppie testo-video per il compito di testo in video. Make-a-Video va ancora oltre proponendo di utilizzare solo coppie testo-immagine per apprendere come appare il mondo e dati video unimodali per apprendere le dipendenze spazio-temporali in modo non supervisionato.
Questi grandi set di dati presentano problemi simili a quelli riscontrati nei set di dati di testo-immagine. Il set di dati testo-video più comunemente utilizzato, WebVid, è composto da 10,7 milioni di coppie di testo-video (52.000 ore di video) e contiene una quantità considerevole di campioni rumorosi con descrizioni video non rilevanti. Altri set di dati cercano di superare questo problema focalizzandosi su compiti o domini specifici. Ad esempio, il set di dati Howto100M è composto da 136 milioni di clip video con didascalie che descrivono come eseguire compiti complessi come cucinare, fare lavori manuali, fare giardinaggio e fitness passo dopo passo. Allo stesso modo, il set di dati QuerYD si concentra sul compito di localizzazione degli eventi in modo che le didascalie dei video descrivano la posizione relativa di oggetti e azioni in dettaglio. CelebV-Text è un ampio set di dati di testo-video facciale composto da oltre 70.000 video per generare video con volti, emozioni e gesti realistici.
Text-to-Video su Hugging Face
Utilizzando Hugging Face Diffusers, è possibile scaricare, eseguire e addestrare facilmente vari modelli preaddestrati di text-to-video, tra cui Text2Video-Zero e ModelScope di Alibaba / DAMO Vision Intelligence Lab. Attualmente stiamo lavorando per integrare altri lavori interessanti in Diffusers e 🤗 Transformers.
Demo di Hugging Face
Da Hugging Face, il nostro obiettivo è rendere più facile utilizzare e sviluppare ricerche all’avanguardia. Vai al nostro hub per vedere e giocare con le demo di Spaces contribuite dal team 🤗, innumerevoli contributori della community e autori di ricerche. Al momento, ospitiamo demo per VideoGPT, CogVideo, ModelScope Text-to-Video e Text2Video-Zero, con molti altri in arrivo. Per vedere cosa possiamo fare con questi modelli, diamo un’occhiata alla demo di Text2Video-Zero. Questa demo non solo illustra la generazione di video da testo, ma consente anche di utilizzare modalità di generazione multiple per l’editing video guidato dal testo e la generazione congiunta condizionale di video utilizzando input di posa, profondità e bordi insieme a prompt di testo.
Oltre all’utilizzo delle demo per sperimentare con modelli preaddestrati di text-to-video, è anche possibile utilizzare la demo di addestramento Tune-a-Video per addestrare ulteriormente un modello di immagine da testo esistente con la propria coppia di testo-video. Per provarlo, carica un video e inserisci un prompt di testo che descrive il video. Una volta completato l’addestramento, è possibile caricarlo nell’Hub nella community Tune-a-Video o nel proprio nome utente, pubblicamente o privatamente. Una volta completato l’addestramento, vai semplicemente alla scheda Esegui della demo per generare video da qualsiasi prompt di testo.
Tutti gli Spazi sull’Hub di 🤗 sono repository Git che è possibile clonare ed eseguire sul proprio ambiente locale o di deploy. Cloniamo la demo di ModelScope, installiamo le dipendenze e avviamola in locale.
git clone https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis
cd modelscope-text-to-video-synthesis
pip install -r requirements.txt
python app.pyE questo è tutto! La demo di Modelscope è ora in esecuzione in locale sul tuo computer. Nota che il modello di text-to-video di ModelScope è supportato in Diffusers e puoi caricare e utilizzare direttamente il modello per generare nuovi video con poche righe di codice.
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
prompt = "Spiderman sta surfando"
video_frames = pipe(prompt, num_inference_steps=25).frames
video_path = export_to_video(video_frames)Contributi della community e progetti open source di Text-to-Video
Infine, ci sono vari progetti e modelli open source che non si trovano nell’hub. Alcuni menzioni degne di nota sono le implementazioni non ufficiali di Phil Wang (aka lucidrains) di Imagen, Phenaki, NUWA, Make-a-Video e Video Diffusion Models. Un altro progetto interessante di ExponentialML si basa su 🤗 diffusers per affinare ModelScope Text-to-Video.
Conclusione
La ricerca sul text-to-video sta progredendo in modo esponenziale, ma il lavoro esistente è ancora limitato nel contesto e affronta molte sfide. In questo post del blog, abbiamo affrontato i vincoli, le sfide uniche e lo stato attuale dei modelli di generazione di text-to-video. Abbiamo anche visto come paradigmi architetturali originariamente progettati per altre attività consentano grandi passi avanti nel compito di generazione di text-to-video e cosa ciò significhi per la ricerca futura. Nonostante gli sviluppi siano impressionanti, i modelli di text-to-video hanno ancora molta strada da fare rispetto ai modelli di text-to-image. Infine, abbiamo mostrato come è possibile utilizzare questi modelli per svolgere varie attività utilizzando le demo disponibili sull’Hub o come parte delle pipeline di 🤗 Diffusers.
E questo è tutto! Continuiamo a integrare i modelli più impattanti di computer vision e multi-modalità e saremmo lieti di ricevere i tuoi feedback. Per rimanere aggiornati sulle ultime novità nella ricerca in computer vision e multi-modalità, puoi seguirci su Twitter: @adirik, @a_e_roberts, @osanseviero, @risingsayak e @huggingface.






