Creazione di Intelligenza Artificiale con Preservazione della Privacy utilizzando Substra
Creazione di AI privacy-preservante con Substra
Con l’attuale aumento delle tecniche generative, l’apprendimento automatico è in un punto della sua storia estremamente eccitante. I modelli che alimentano questa crescita richiedono ancora più dati per produrre risultati significativi, ed è quindi sempre più importante esplorare nuovi metodi per raccogliere dati in modo etico, garantendo al contempo la privacy e la sicurezza dei dati come priorità assoluta.
In molti ambiti che trattano informazioni sensibili, come la sanità, spesso non è disponibile abbastanza dati di alta qualità per addestrare questi modelli avidi di dati. I dataset sono separati in diversi centri accademici e istituti medici e sono difficili da condividere apertamente a causa di preoccupazioni sulla privacy riguardo alle informazioni dei pazienti e alle informazioni proprietarie. Le normative che proteggono i dati dei pazienti, come l’HIPAA, sono essenziali per salvaguardare le informazioni sanitarie private degli individui, ma possono limitare il progresso della ricerca sull’apprendimento automatico poiché gli scienziati dei dati non possono accedere al volume di dati necessario per addestrare efficacemente i loro modelli. Le tecnologie che lavorano insieme alle normative esistenti proteggendo proattivamente i dati dei pazienti saranno cruciali per sbloccare queste barriere e accelerare il ritmo della ricerca e dell’implementazione dell’apprendimento automatico in questi ambiti.
Ecco dove entra in gioco il Federated Learning. Dai un’occhiata allo spazio che abbiamo creato con Substra per saperne di più!
Cos’è il Federated Learning?
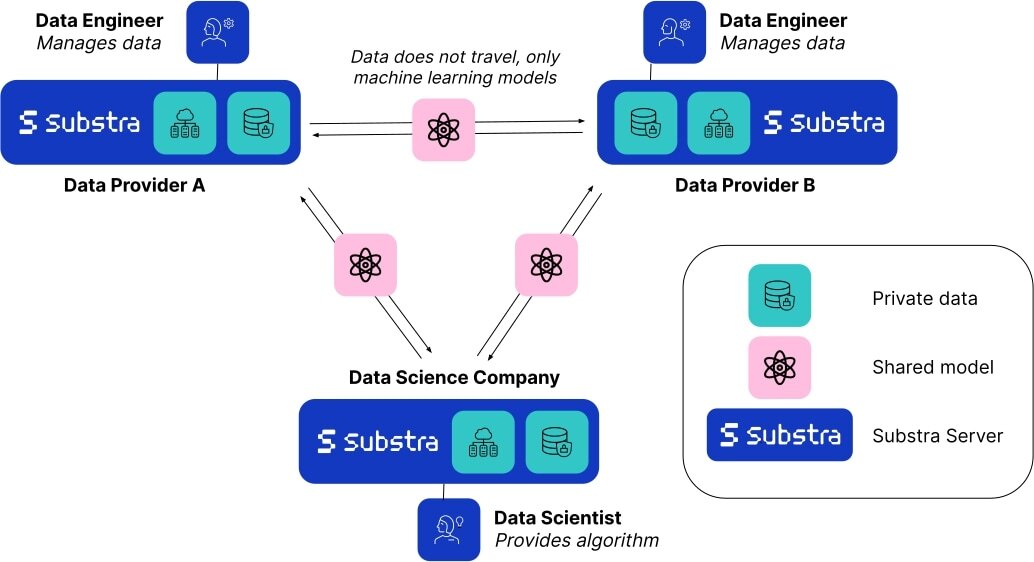
Il Federated Learning (FL) è una tecnica di apprendimento automatico decentralizzata che consente di addestrare modelli utilizzando più fornitori di dati. Invece di raccogliere dati da tutte le fonti su un singolo server, i dati possono rimanere su un server locale e solo i pesi dei modelli risultanti si spostano tra i server.
- Classificazione dei grafi con i trasformatori
- Accelerando i Transformers di Hugging Face con AWS Inferentia2
- Come ospitare un gioco Unity in uno spazio
Dato che i dati non lasciano mai la loro fonte, il Federated Learning è naturalmente un approccio centrato sulla privacy. Questa tecnica non solo migliora la sicurezza e la privacy dei dati, ma consente anche agli scienziati dei dati di costruire modelli migliori utilizzando dati provenienti da diverse fonti, aumentando la robustezza e fornendo una migliore rappresentazione rispetto ai modelli addestrati su dati provenienti da una singola fonte. Questo è prezioso non solo per l’aumento della quantità di dati, ma anche per ridurre il rischio di pregiudizi dovuti a variazioni del dataset sottostante, ad esempio piccole differenze causate dalle tecniche di acquisizione dei dati e dall’attrezzatura utilizzata, o differenze nelle distribuzioni demografiche della popolazione di pazienti. Con più fonti di dati, possiamo costruire modelli più generalizzabili che alla fine si comportano meglio in ambienti reali. Per ulteriori informazioni sul Federated Learning, ti consigliamo di dare un’occhiata a questa illustrazione di Google.

Substra è un framework open source per il Federated Learning sviluppato per ambienti di produzione del mondo reale. Sebbene il Federated Learning sia un campo relativamente nuovo e si sia affermato solo negli ultimi dieci anni, ha già permesso alla ricerca sull’apprendimento automatico di progredire in modi precedentemente impensabili. Ad esempio, 10 aziende biotech concorrenti che tradizionalmente non avrebbero mai condiviso dati tra loro hanno stabilito una collaborazione nel progetto MELLODDY condividendo la più grande collezione di piccole molecole al mondo con attività biochimiche o cellulari note. Ciò ha permesso a tutte le aziende coinvolte di costruire modelli predittivi più accurati per la scoperta di nuovi farmaci, un enorme traguardo nella ricerca medica.
Substra x HF
La ricerca sulle capacità del Federated Learning sta crescendo rapidamente, ma la maggior parte dei lavori recenti è stata limitata a ambienti simulati. Gli esempi e le implementazioni nel mondo reale rimangono ancora limitati a causa della difficoltà di distribuzione e progettazione delle reti federate. Come piattaforma open source leader per la distribuzione del Federated Learning, Substra è stata testata in molteplici complessi ambienti di sicurezza e infrastrutture IT ed ha permesso progressi nella ricerca sul cancro al seno.
Hugging Face ha collaborato con gli sviluppatori di Substra per creare questo spazio, che ha lo scopo di farti capire le sfide reali che i ricercatori e gli scienziati affrontano, principalmente la mancanza di dati centralizzati di alta qualità pronti per l’IA. Poiché puoi controllare la distribuzione di questi campioni, sarai in grado di vedere come un modello semplice reagisce ai cambiamenti dei dati. Potrai quindi esaminare come un modello addestrato con il Federated Learning quasi sempre si comporta meglio sui dati di convalida rispetto ai modelli addestrati su dati provenienti da una singola fonte.
Conclusione
Sebbene il Federated Learning stia guidando l’avanzata, ci sono varie altre tecnologie che migliorano la privacy (PETs), come gli enclave sicuri e i calcoli multi-party, che stanno permettendo risultati simili e possono essere combinate con la federazione per creare ambienti multi-layered di conservazione della privacy. Puoi saperne di più qui se sei interessato a come queste tecnologie stanno permettendo collaborazioni nel campo della medicina.
Indipendentemente dai metodi utilizzati, è importante rimanere vigili sul fatto che la privacy dei dati è un diritto per tutti noi. È fondamentale che proseguiamo in questo boom dell’IA tenendo a mente la privacy e l’etica.
Se desideri giocare con Substra e implementare l’apprendimento federato in un progetto, puoi consultare la documentazione qui.