Introduzione pratica ai modelli Transformer BERT
Introduzione ai modelli Transformer BERT
Tutorial pratici
Tutorial pratico su come creare il tuo primo modello di analisi del sentiment utilizzando BERT
Prefazione: Questo articolo presenta un riassunto di informazioni sul tema dato. Non dovrebbe essere considerato come ricerca originale. Le informazioni e il codice inclusi in questo articolo potrebbero essere influenzati da cose che ho letto o visto in passato da vari articoli online, documenti di ricerca, libri e codice open-source.
Indice
- Introduzione a BERT
- Pre-training e Fine-tuning
- Pratico: Utilizzare BERT per l’analisi del sentiment
- Interpretazione dei risultati
- Riflessioni finali
NLP, l’architettura del modello transformer è stata una rivoluzione che ha notevolmente migliorato la capacità di comprendere e generare informazioni testuali.
In questo tutorial, andremo in profondità su BERT, un noto modello basato su transformer, e forniremo un esempio pratico per migliorare il modello base di BERT per l’analisi del sentiment.
Introduzione a BERT
BERT, introdotto dai ricercatori di Google nel 2018, è un potente modello di linguaggio che utilizza l’architettura dei transformer. Superando i limiti delle precedenti architetture dei modelli, come LSTM e GRU, che erano unidirezionali o sequenzialmente bidirezionali, BERT considera il contesto sia dal passato che dal futuro contemporaneamente. Questo è dovuto all’innovativo “meccanismo di attenzione”, che consente al modello di valutare l’importanza delle parole in una frase durante la generazione delle rappresentazioni.
- Principi efficaci di ingegneria delle indicazioni per l’applicazione di AI generativa
- Ecco perché dovresti leggere questo prima di usare Pandas nella pulizia dei dati
- ChatGPT Dethroned Come Claude è diventato il nuovo leader dell’IA
Il modello BERT è pre-allenato sui seguenti due compiti di NLP:
- Masked Language Model (MLM)
- Next Sentence Prediction (NSP)
e viene generalmente utilizzato come modello di base per vari compiti di NLP successivi, come l’analisi del sentiment che tratteremo in questo tutorial.
Pre-training e Fine-tuning
La potenza di BERT deriva dal suo processo in due fasi:
- Pre-training è la fase in cui BERT viene allenato su grandi quantità di dati. Di conseguenza, impara a prevedere le parole mascherate in una frase (compito MLM) e a prevedere se una frase segue un’altra (compito NSP). Il risultato di questa fase è un modello NLP pre-allenato con una “comprensione” generica del linguaggio
- Fine-tuning è dove il modello BERT pre-allenato viene ulteriormente allenato su un compito specifico. Il modello viene inizializzato con i parametri pre-allenati e l’intero modello viene allenato su un compito successivo, consentendo a BERT di migliorare la sua comprensione del linguaggio in base alle specificità del compito in questione.
Pratico: Utilizzare BERT per l’analisi del sentiment
Il codice completo è disponibile come Jupyter Notebook su GitHub
In questo esercizio pratico, addestreremo il modello di analisi del sentiment sul dataset delle recensioni dei film IMDB [4] (licenza: Apache 2.0), che indica se una recensione è positiva o negativa. Caricheremo anche il modello utilizzando la libreria transformers di Hugging Face.
Carichiamo tutte le librerie
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.metrics import confusion_matrix, roc_curve, aucfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer# Variabili per impostare il numero di epoche e campioninum_epochs = 10num_samples = 100 # impostare questo a -1 per utilizzare tutti i datiPrima di tutto, dobbiamo caricare il dataset e il tokenizer del modello.
# Passaggio 1: Caricare il dataset e il tokenizer del modellodataset = load_dataset('imdb')tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')Successivamente, creeremo un grafico per visualizzare la distribuzione delle classi positive e negative.
# Esplorazione dei datitrain_df = pd.DataFrame(dataset["train"])sns.countplot(x='label', data=train_df)plt.title('Distribuzione delle classi')plt.show()
In seguito, preprocessiamo il nostro dataset suddividendo i testi in token. Utilizziamo il tokenizer di BERT, che convertirà il testo in token corrispondenti al vocabolario di BERT.
# Passo 2: Preprocessare il datasetdef tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True)tokenized_datasets = dataset.map(tokenize_function, batched=True)
Dopo di ciò, prepariamo i nostri dataset di addestramento e valutazione. Ricorda, se desideri utilizzare tutti i dati, puoi impostare la variabile num_samples su -1.
if num_samples == -1: small_train_dataset = tokenized_datasets["train"].shuffle(seed=42) small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42)else: small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(num_samples)) small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(num_samples)) Successivamente, carichiamo il modello pre-addestrato di BERT. Utilizzeremo la classe AutoModelForSequenceClassification, un modello di BERT progettato per compiti di classificazione.
Per questo tutorial, utilizzeremo la versione ‘bert-base-uncased’ di BERT, addestrata su testo in inglese in minuscolo.
# Passo 3: Caricare il modello pre-addestratomodel = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)Ora siamo pronti a definire i nostri argomenti di addestramento e creare un’istanza di Trainer per addestrare il nostro modello.
# Passo 4: Definire gli argomenti di addestramentotraining_args = TrainingArguments("test_trainer", evaluation_strategy="epoch", no_cuda=True, num_train_epochs=num_epochs)# Passo 5: Creare un'istanza di Trainer e addestrare il modellotrainer = Trainer( model=model, args=training_args, train_dataset=small_train_dataset, eval_dataset=small_eval_dataset)trainer.train()Interpretazione dei risultati
Dopo aver addestrato il nostro modello, valutiamolo. Calcoleremo la matrice di confusione e la curva ROC per capire quanto bene si comporta il nostro modello.
# Passo 6: Valutazionepredictions = trainer.predict(small_eval_dataset)# Matrice di confusione (confusion matrix)cm = confusion_matrix(small_eval_dataset['label'], predictions.predictions.argmax(-1))sns.heatmap(cm, annot=True, fmt='d')plt.title('Matrice di confusione')plt.show()# Curva ROCfpr, tpr, _ = roc_curve(small_eval_dataset['label'], predictions.predictions[:, 1])roc_auc = auc(fpr, tpr)plt.figure(figsize=(1.618 * 5, 5))plt.plot(fpr, tpr, color='darkorange', lw=2, label='Curva ROC (area = %0.2f)' % roc_auc)plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('Tasso di falsi positivi')plt.ylabel('Tasso di veri positivi')plt.title('Caratteristica operativa del ricevitore')plt.legend(loc="lower right")plt.show()
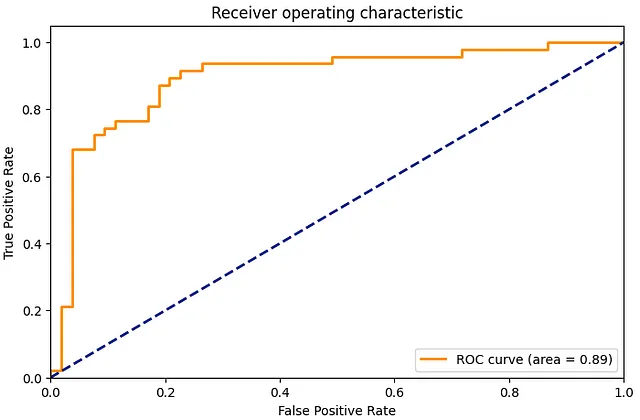
Il matrix di confusione fornisce una dettagliata analisi di come le nostre previsioni si confrontano con le etichette effettive, mentre la curva ROC ci mostra il compromesso tra il tasso di veri positivi (sensibilità) e il tasso di falsi positivi (1 – specificità) a diversi livelli di soglia.
Infine, per vedere il nostro modello in azione, utilizziamolo per inferire il sentimento di un testo di esempio.
# Passaggio 7: Inferenza su un nuovo campione
sample_text = “Questo è un film fantastico. Mi è piaciuto molto.”
sample_inputs = tokenizer(sample_text, padding=”max_length”, truncation=True, max_length=512, return_tensors=”pt”)
# Sposta gli input sul dispositivo (se è disponibile una GPU)
sample_inputs.to(training_args.device)
# Effettua la previsione
predictions = model(**sample_inputs)
predicted_class = predictions.logits.argmax(-1).item()
if predicted_class == 1:
print(“Sentimento positivo”)
else:
print(“Sentimento negativo”)

## Pensieri finali
Attraverso questo esempio di analisi del sentimento su recensioni di film su IMDb, spero che tu abbia acquisito una chiara comprensione di come applicare BERT a problemi di NLP nel mondo reale. Il codice Python incluso qui può essere adattato ed esteso per affrontare diversi compiti e set di dati, aprendo la strada a modelli di linguaggio ancora più sofisticati e accurati.
## Riferimenti
[1] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998–6008).
[3] Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., … & Rush, A. M. (2019). Huggingface’s transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771.
[4] Lhoest, Q., Villanova del Moral, A., Jernite, Y., Thakur, A., von Platen, P., Patil, S., Chaumond, J., Drame, M., Plu, J., Tunstall, L., Davison, J., Šaško, M., Chhablani, G., Malik, B., Brandeis, S., Le Scao, T., Sanh, V., Xu, C., Patry, N., McMillan-Major, A., Schmid, P., Gugger, S., Delangue, C., Matussière, T., Debut, L., Bekman, S., Cistac, P., Goehringer, T., Mustar, V., Lagunas, F., Rush, A., & Wolf, T. (2021). Datasets: A Community Library for Natural Language Processing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (pp. 175–184). Online and Punta Cana, Dominican Republic: Association for Computational Linguistics. Retrieved from https://aclanthology.org/2021.emnlp-demo.21
Grazie per la lettura. Se hai dei feedback, non esitare a commentare questo post, a scrivermi su LinkedIn o a inviarmi un’e-mail (smhkapadia[at]gmail.com).
Se hai apprezzato questo articolo, visita gli altri miei articoli.
## Adattamento di Dominio: Perfezionamento di Modelli NLP Pre-Addestrati
## Una guida passo-passo per il perfezionamento di modelli NLP pre-addestrati per qualsiasi dominio
towardsdatascience.com
## L’Evolutione del Natural Language Processing
## Una prospettiva storica sullo sviluppo dei modelli di linguaggio
VoAGI.com
Sistema di Raccomandazione in Python: LightFM
Una guida passo passo per la creazione di un sistema di raccomandazione in Python utilizzando LightFM
towardsdatascience.com
Valutare i modelli di argomento: Latent Dirichlet Allocation (LDA)
Una guida passo passo per la creazione di modelli di argomento interpretabili
towardsdatascience.com