Sull’apprendimento nella presenza di gruppi sottorappresentati
Apprendimento con gruppi sottorappresentati
Il cambiamento è difficile: Uno sguardo più approfondito al cambio di sottopopolazione (ICML 2023)
Permettetemi di presentarvi il nostro ultimo lavoro, che è stato accettato da ICML 2023: Il cambiamento è difficile: Uno sguardo più approfondito al cambio di sottopopolazione. I modelli di apprendimento automatico hanno mostrato un grande potenziale in molte applicazioni, ma spesso si comportano male su sottogruppi che sono sottorappresentati nei dati di addestramento. Comprendere la variazione dei meccanismi che causano tali cambiamenti di sottopopolazione e come gli algoritmi generalizzano su diverse variazioni su larga scala rimane una sfida. In questo lavoro, cerchiamo di colmare questa lacuna fornendo un’analisi dettagliata dei cambiamenti di sottopopolazione e del loro impatto sugli algoritmi di apprendimento automatico.
Presentiamo innanzitutto un framework unificato che scompone e spiega i cambiamenti comuni nei sottogruppi. Inoltre, introduciamo un benchmark completo composto da 20 algoritmi all’avanguardia, che valutiamo su 12 set di dati reali che coprono i domini della visione, del linguaggio e della salute. Attraverso la nostra analisi e benchmarking, forniamo osservazioni intriganti e una comprensione dei cambiamenti di sottopopolazione e di come gli algoritmi di apprendimento automatico generalizzano in presenza di tali cambiamenti del mondo reale. Il codice, i dati e i modelli sono stati resi open source su GitHub: https://github.com/YyzHarry/SubpopBench.
Background e Motivazione
I modelli di apprendimento automatico mostrano frequentemente cali di prestazioni in presenza di cambiamenti nella distribuzione. Tali cambiamenti si verificano quando la distribuzione dei dati sottostante cambia (ad esempio, la distribuzione di addestramento è diversa da quella di test), portando a cali di prestazioni durante la distribuzione dei modelli. Costruire modelli di apprendimento automatico che siano robusti a questi cambiamenti è fondamentale per la distribuzione sicura di tali modelli nel mondo reale. Un tipo ubiquo di cambiamento nella distribuzione è il cambio di sottopopolazione, caratterizzato da cambiamenti nella proporzione di alcuni sottopopolazioni tra addestramento e distribuzione. In tali contesti, i modelli possono avere alte prestazioni complessive ma ancora prestazioni scadenti in sottogruppi rari.
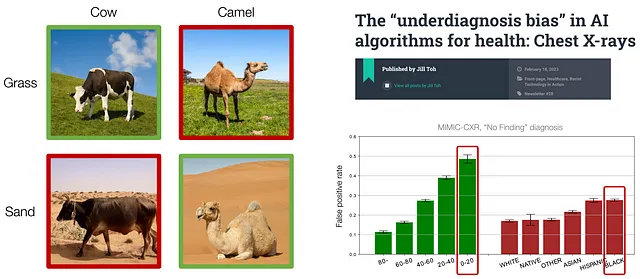
Ad esempio, nel compito di classificazione tra mucche e cammelli, le mucche sono spesso trovate in aree con erba verde e i cammelli sono spesso trovati in aree con sabbia gialla. Tuttavia, tale correlazione è spuria perché la presenza di mucche o cammelli non ha nulla a che fare con il colore dello sfondo. Di conseguenza, il modello addestrato si comporta bene sulle immagini sopra menzionate, ma non può generalizzare agli animali con diversi colori di sfondo che sono rari nei dati di addestramento, come mucche su sabbia o cammelli sull’erba.
- Incontra il concorrente di ChatGPT di Alibaba Tongyi Qianwen, un grande modello di linguaggio che sarà incorporato nei suoi altoparlanti intelligenti Tmall Genie e nella piattaforma di messaggistica aziendale DingTalk.
- Esplorare i contenuti dei file DLIS con Python
- Come utilizzare l’interprete di codice di OpenAI per analizzare i dati
Inoltre, quando si tratta di diagnosi medica, studi hanno scoperto che i modelli di apprendimento automatico spesso si comportano peggio nei gruppi di età o etnia sottorappresentati, sollevando importanti preoccupazioni di equità.
Tutti questi cambiamenti sono generalmente definiti come cambio di sottopopolazione, ma si comprende poco sulla variazione dei meccanismi che causano i cambiamenti di sottopopolazione e su come gli algoritmi generalizzano su tali cambiamenti diversi su larga scala. Quindi, come modellare il cambio di sottopopolazione?
Un Framework Unificato del Cambio di Sottopopolazione
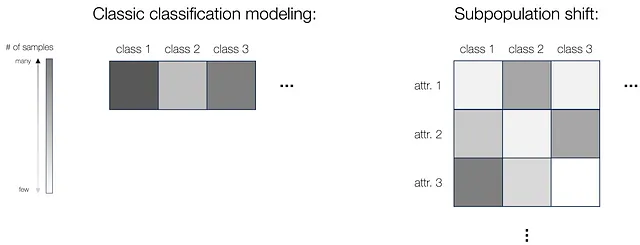
Prima di tutto forniamo un framework unificato per la modellazione del cambio di sottopopolazione. Nella configurazione classica di classificazione, abbiamo dati di addestramento da più classi (dove utilizziamo densità di colore diverse per rappresentare diversi numeri di campioni in ciascuna classe). Tuttavia, quando si tratta di cambio di sottopopolazione, esistono attributi oltre alla classe, come i colori dello sfondo nel problema mucche-cammelli. In questo caso, potremmo definire le sottopopolazioni discrete basate sia sull’attributo che sull’etichetta, e qui il numero di campioni per diversi attributi all’interno della stessa classe potrebbe variare anche (vedi figura sotto). E naturalmente, per testare il modello, simile all’impostazione di classificazione in cui valutiamo le prestazioni su tutte le classi, nel cambio di sottopopolazione testiamo il modello su tutti i sottogruppi, per garantire che le peggiori prestazioni su tutte le sottopopolazioni siano sufficientemente buone, o garantire una prestazione altrettanto buona su tutti i gruppi.
In particolare, per fornire una formulazione matematica generica, riscriviamo prima il modello di classificazione utilizzando il teorema di Bayes. Inoltre, consideriamo ogni input x come completamente descritto o generato da un insieme di caratteristiche di base sottostanti (X_core) e un elenco di attributi (a). Qui, X_core indica i componenti invarianti sottostanti che sono specifici dell’etichetta e supportano una classificazione robusta, mentre gli attributi a possono avere distribuzioni inconsistenti e non sono specifici dell’etichetta. Pertanto, possiamo integrare questo modello nell’equazione e scomporlo in tre termini, come mostrato di seguito:
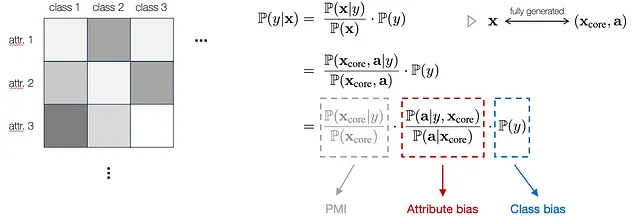
In particolare, il primo termine rappresenta l’informazione mutua punto a punto (PMI) tra X_core e y, che è l’indicatore robusto correlato alle etichette di classe sottostanti. Il secondo e il terzo termine corrispondono al possibile bias che si verifica nella distribuzione degli attributi e nella distribuzione delle etichette, rispettivamente. Questa modellazione spiega come l’attributo e la classe influenzano i risultati sotto la variazione delle sottopopolazioni. Pertanto, dato X_core invariante tra le distribuzioni di training e di testing, possiamo ignorare le variazioni nel primo termine e concentrarci su come l’attributo e la classe influenzano i risultati sotto la variazione delle sottopopolazioni.
Basandoci su questo framework, definiamo e caratterizziamo formalmente quattro tipi di variazioni delle sottopopolazioni: correlazioni spurie, squilibrio degli attributi, squilibrio delle classi e generalizzazione degli attributi. Ciascun tipo costituisce un componente di variazione di base che può verificarsi sotto la variazione delle sottopopolazioni.
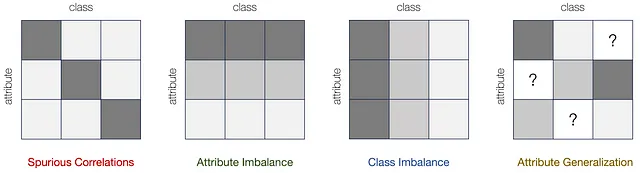
In primo luogo, quando un certo attributo è correlato in modo spurio all’etichetta y nel training ma non nei dati di test, si parla di correlazioni spurie. Inoltre, quando alcuni attributi sono campionati con una probabilità molto più piccola rispetto agli altri, si verifica uno squilibrio degli attributi. Allo stesso modo, le etichette di classe possono presentare distribuzioni sbilanciate, causando una preferenza inferiore per le etichette minoritarie. Questo porta ad uno squilibrio delle classi. Infine, alcuni attributi possono essere completamente assenti nel training, ma presenti nel testing per determinate classi, il che giustifica la necessità di una generalizzazione degli attributi. Le fonti di bias degli attributi / classi per ciascuna di queste variazioni, così come l’impatto sul modello di classificazione, sono riassunte nella tabella seguente:

Questi quattro casi costituiscono i componenti di variazione di base e sono elementi importanti per spiegare le complesse variazioni dei sottogruppi nei dati reali. Nella pratica, i dataset spesso presentano contemporaneamente più tipi di variazione, invece di uno solo.
SubpopBench: Benchmarking delle Variazioni delle Sottopopolazioni
Ora, dopo aver impostato la formulazione, proponiamo SubpopBench, una completa batteria di test che include algoritmi all’avanguardia valutati su 12 dataset reali. In particolare, questi dataset provengono da una varietà di modalità e compiti, tra cui visione, linguaggio e applicazioni nel settore sanitario, con modalità di dati che vanno da immagini naturali, testo, testo clinico a raggi X del torace. Essi presentano anche diversi componenti di variazione.
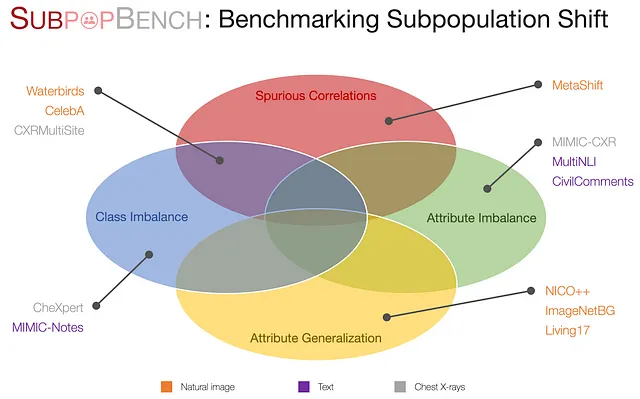

Per maggiori dettagli su questo benchmark, si prega di fare riferimento al nostro articolo. Con il benchmark stabilito e oltre 10.000 modelli addestrati utilizzando 20 algoritmi all’avanguardia, sveliamo osservazioni intriganti per future ricerche in questo campo.
Un’Analisi Dettagliata sullo Spostamento delle Sotto-popolazioni
Gli Algoritmi SOTA Migliorano Solo Certi Tipi di Spostamento
Innanzitutto, osserviamo che gli algoritmi SOTA migliorano solo la robustezza dei sottogruppi su certi tipi di spostamento, ma non su altri.
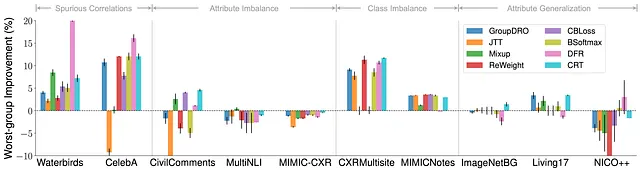
Rappresentiamo qui il miglioramento dell’accuratezza del gruppo peggiore rispetto all’ERM per vari algoritmi SOTA. Per correlazioni spurie e squilibrio di classe, gli algoritmi esistenti possono fornire miglioramenti costanti del gruppo peggiore rispetto all’ERM, indicando che sono stati compiuti progressi per affrontare questi due tipi specifici di spostamento.
Tuttavia, interessantemente, quando si tratta di squilibrio degli attributi, si osserva un miglioramento limitato tra i dataset. Inoltre, le prestazioni peggiorano ancora di più per la generalizzazione degli attributi.
Questi risultati sottolineano che gli avanzamenti attuali sono stati fatti solo per spostamenti specifici, mentre non ci sono stati progressi per gli spostamenti più sfidanti come AG.
Il Ruolo delle Rappresentazioni e dei Classificatori
Inoltre, siamo motivati a esplorare il ruolo della rappresentazione e del classificatore nello spostamento delle sotto-popolazioni. In particolare, separiamo l’intera rete in due parti: l’estratore di caratteristiche f e il classificatore g, dove f estrae le caratteristiche latenti dall’input e g restituisce la previsione finale. Ci poniamo la domanda, come influiscono la rappresentazione e il classificatore sulle prestazioni dei sottogruppi?
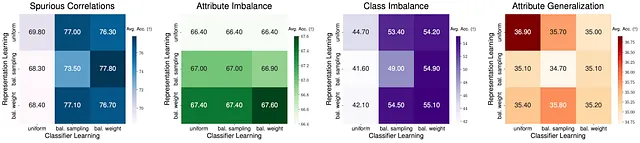
Innanzitutto, dato un modello ERM di base, quando si ottimizza solo l’apprendimento del classificatore mantenendo fissa la rappresentazione, si può migliorare notevolmente le prestazioni per correlazioni spurie e squilibrio di classe, indicando che le rappresentazioni apprese da ERM sono già abbastanza buone. Tuttavia, interessantemente, migliorare l’apprendimento della rappresentazione invece del classificatore può portare a guadagni notevoli per lo squilibrio degli attributi, indicando che potremmo aver bisogno di caratteristiche più potenti per certi spostamenti. Infine, nessun metodo di apprendimento stratificato porta a guadagni di prestazioni nella generalizzazione degli attributi. Questo sottolinea che è necessario considerare la progettazione del modello pipeline di fronte a diversi tipi di spostamento nella realtà.
Sulla Selezione del Modello e la Disponibilità degli Attributi
Inoltre, osserviamo che la selezione del modello e la disponibilità degli attributi influiscono notevolmente sulla valutazione dello spostamento delle sotto-popolazioni.
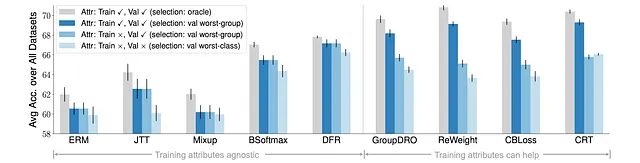
In particolare, rimuovendo gradualmente le annotazioni degli attributi nei dati di addestramento e/o validazione, tutti gli algoritmi hanno subito notevoli cali di prestazione, soprattutto quando non è disponibile nessun attributo sia nei dati di addestramento che di validazione.
Questo indica che l’accesso agli attributi gioca ancora un ruolo significativo nel ottenere prestazioni ragionevoli nello spostamento delle sotto-popolazioni, e gli algoritmi futuri dovrebbero considerare scenari più realistici per la selezione del modello e la disponibilità degli attributi.
Misure Oltre all’Accuratezza del Gruppo Peggiore
Infine, riveliamo il tradeoff fondamentale tra le misure di valutazione. L’accuratezza del gruppo peggiore, o WGA, è considerata come lo standard d’oro nella valutazione dello spostamento delle sotto-popolazioni. Tuttavia, migliorare il WGA migliora sempre altre misure significative?

Prima mostriamo che migliorare WGA potrebbe portare a un miglioramento delle prestazioni per determinate metriche, come l’accuratezza regolata mostrata qui. Tuttavia, se consideriamo ulteriormente la precisione nel caso peggiore, sorprendentemente mostra una correlazione lineare negativa molto forte con WGA. Questo rivela la limitazione fondamentale nell’utilizzare WGA come unica metrica per valutare le prestazioni del modello nel cambiamento delle sottopopolazioni: un modello ben eseguito con un alto WGA può tuttavia avere una precisione nel caso peggiore bassa, il che è particolarmente preoccupante in applicazioni critiche come la diagnosi medica.
Le nostre osservazioni sottolineano la necessità di avere un set di metriche di valutazione più realistico e ampio nel cambiamento delle sottopopolazioni. Mostriamo anche molte altre metriche che mostrano una correlazione inversa con WGA nel nostro articolo.
Conclusioni
Per concludere questo articolo, abbiamo investigato sistematicamente il problema del cambiamento delle sottopopolazioni, formalizzato un framework unificato per definire e quantificare diversi tipi di cambiamento delle sottopopolazioni e creato un benchmark completo per una valutazione realistica su dati del mondo reale. Il nostro benchmark include 20 metodi SOTA e 12 set di dati del mondo reale in diversi domini. Sulla base di oltre 10K modelli addestrati, riveliamo proprietà intriganti nel cambiamento delle sottopopolazioni che hanno implicazioni per la ricerca futura. Speriamo che il nostro benchmark e le nostre scoperte promuovano valutazioni realistiche e rigorose e ispirino nuovi progressi nel cambiamento delle sottopopolazioni. Alla fine, allego diversi link pertinenti del nostro articolo; grazie per aver letto!
Codice: https://github.com/YyzHarry/SubpopBench
Pagina del Progetto: https://subpopbench.csail.mit.edu/
Presentazione: https://www.youtube.com/watch?v=WiSrCWAAUNI


