Ecco perché dovresti leggere questo prima di usare Pandas nella pulizia dei dati
Leggi questo prima di usare Pandas per la pulizia dei dati
Master Data Cleaning, Processing, and Exploration with Pandas

Benvenuti al tutorial rapido sulla manipolazione dei dati con Pandas!
In questo tutorial, copriremo una vasta gamma di argomenti, che va dalla sostituzione del testo nei dataframe alla combinazione dei dataframe.
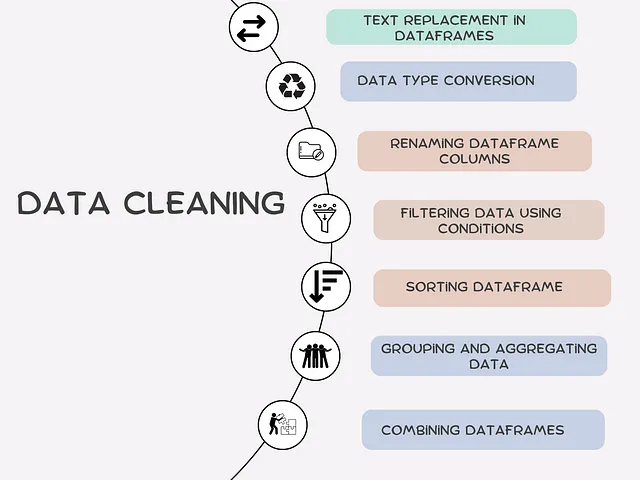
Tabella dei contenuti· Sostituzione del testo nei dataframe· Conversione del tipo di dati· Rinomina delle colonne del dataframe· Filtraggio dei dati utilizzando condizioni· Ordinamento del dataframe· Raggruppamento e aggregazione dei dati· Combinazione dei dataframe· ConclusioniLa libreria Pandas è una delle librerie più importanti per la manipolazione e pulizia dei dati in Python.
Quindi, se hai intenzione di occuparti di qualsiasi tipo di attività legata ai dati, questo articolo sarà utile per te.
- ChatGPT Dethroned Come Claude è diventato il nuovo leader dell’IA
- L’accesso ai dati è gravemente carente nella maggior parte delle aziende e il 71% crede che i dati sintetici possano aiutare
- Justin McGill, Fondatore e CEO di Content at Scale – Serie di interviste
Iniziamo a imparare questi metodi, che potresti utilizzare quotidianamente come data scientist, per preparare i tuoi dati.
Ma prima, carichiamo il nostro dataset.
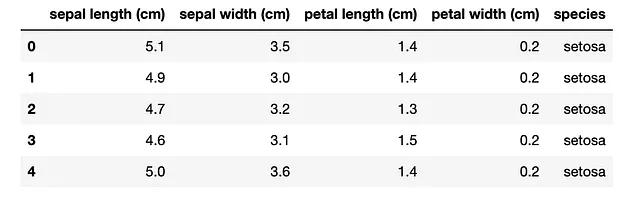
from sklearn.datasets import load_irisimport pandas as pdiris_bunch = load_iris()iris = pd.DataFrame(data=iris_bunch.data, columns=iris_bunch.feature_names)iris['species'] = iris_bunch.targetiris['species'] = iris['species'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})iris.head()Ecco l’output.
Sostituzione del testo nei dataframe
Spesso, è necessario sostituire il contenuto dei dati nei dataframe, per modificarlo nella direzione desiderata, ad esempio per pulire i dati categorici o standardizzarli.
import pandas as pdimport numpy as npiris_replaced = pd.DataFrame(data=iris['data'], columns=iris['feature_names'])iris_replaced['target'] = iris['target']iris_replaced['target'] = np.where(iris_replaced['target'] == 0, 'iris_setosa', iris_replaced['target'])iris_replaced.head()