La migliore alternativa a Seaborn Distplot in Python
The best alternative to Seaborn Distplot in Python.
Scienza dei dati
Seaborn Distplot è deprecato – esploriamo le sue alternative

Seaborn è una nota libreria di visualizzazione dei dati in Python.
In quanto costruita su matplotlib e che funziona perfettamente con le strutture dei dati di pandas, è utile durante il lavoro con i dati in Python, in quanto trasforma i dati in visualizzazioni utili. Ciò aiuta a concentrarsi sulle informazioni richieste e a comprendere i risultati più rapidamente.
Tuttavia, ogni libreria evolve nel tempo e così fa Seaborn.
Quando ho utilizzato Seaborn per creare i grafici di distribuzione nel mio progetto, ho incontrato l’avviso di deprecazione della funzione come di seguito.
- Le Competenze Trasversali Battono le Competenze Tecniche nell’Analisi dei Dati
- Costruisci dataset pronti per il machine learning dall’Amazon SageMaker offline Feature Store utilizzando l’Amazon SageMaker Python SDK.
- Come Scrivere Istruzioni Condizionali in R Quattro Metodi

Quindi, ho iniziato a cercare alternative e oggi condivido i miei risultati.
In questa breve lettura, scoprirai perché Seaborn ha deprecato la fantastica funzione distplot(), la migliore alternativa attuale e come utilizzarla per creare grafici identici a distplot().
Ecco un’anteprima dei contenuti:
· Distplot in Seaborn · Perché Seaborn Distplot è deprecato? · Quali sono le alternative a Seaborn Distplot()? ∘ displot() in Seaborn · Casi d’uso di displot() in seaborn ∘ Distribuzione bivariata ∘ Grafici con i sottoinsiemi dei dati
Ho preso esempi fantastici per rendere questa lettura interessante e ho usato il set di dati Dry Beans dal repository di apprendimento automatico UCI che è disponibile con licenza CC BY 4.0.

Immergiamoci!
Prima di guardare le alternative, capiamo prima la funzione distplot() e come è utile.
Distplot in Seaborn
Distplot() è una funzione versatile nella libreria Seaborn che viene ampiamente utilizzata per l’analisi dei dati univariati. Ti aiuta a creare un istogramma e una stima della densità del kernel (KDE) nella stessa visualizzazione.
Cos’è l’analisi dei dati univariati?
Viene utilizzata per esplorare le caratteristiche e la distribuzione di una singola variabile alla volta, senza considerare la sua relazione con altre variabili nel dataset.
Quindi torniamo a distplot(), che è composto da un istogramma e una stima della densità del kernel.
L’istogramma in distplot() mostra la frequenza o il conteggio dei punti dati che cadono in diversi bucket, cioè i bin.
L’intera serie o lista di punti dati viene suddivisa in diversi bucket della stessa dimensione. La visualizzazione è semplicemente un grafico a barre in cui l’asse X sono solitamente i bucket o i bin e l’asse Y rappresenta il numero di punti dati nei bucket.
Tale grafico aiuta a capire come i dati sono distribuiti nell’intervallo di valori.
Mentre il grafico KDE ti aiuta a visualizzare la distribuzione di una variabile analizzando la funzione di distribuzione di probabilità sottostante. In parole più semplici, ti aiuta a capire la probabilità di osservare i punti dati in diversi bucket o bin.
Utilizzando i grafici KDE, puoi apprendere la forma della distribuzione dei dati, i suoi picchi e la sua diffusione.
Ad esempio, utilizziamo la funzione distplot() sulla colonna – Perimetro.
import pandas as pdimport seaborn as snsdf = pd.read_excel("Dry_Bean_Dataset.xlsx")sns.distplot(df["Perimetro"])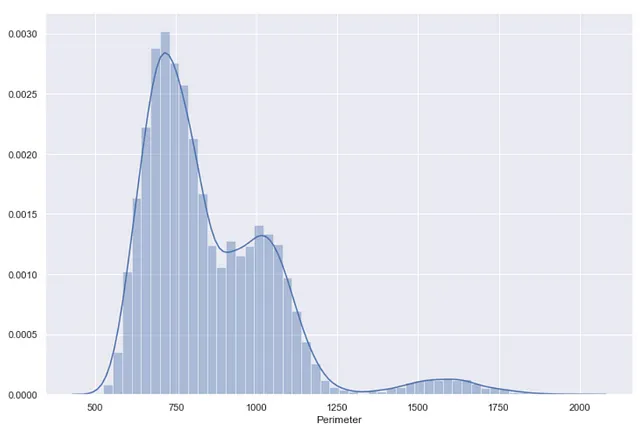
Come si può vedere nella visualizzazione sopra, le barre rappresentano l’istogramma, mentre la linea liscia è per il KDE plot.
Come ho detto, distplot() crea un KDE plot sulla parte superiore dell’istogramma già creato, ed è per questo che sull’asse Y si possono vedere i valori di densità di probabilità.
Non confondere la Probabilità con la Densità di Probabilità!
È necessario moltiplicare la densità di probabilità per l’area sotto la curva per ottenere la probabilità da ciascun valore di densità di probabilità.
Tali valori KDE possono essere utilizzati solo per il confronto relativo tra diversi bin.
Ora, capiamo perché non dovresti usarlo in futuro.
Perché Seaborn Distplot è Obsoleto?
Distplot() è una delle prime funzioni aggiunte alla libreria Seaborn, quindi la sua definizione di funzione è significativamente diversa dalle altre funzioni che sono state aggiunte in un secondo momento.
Ecco la definizione della funzione distplot() come da documentazione ufficiale di Seaborn.
seaborn.distplot(a=None, bins=None, hist=True, kde=True, rug=False,fit=None, hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None,color=None, vertical=False, norm_hist=False, axlabel=None, label=None,ax=None, x=None)Michael Waskom lo spiega precisamente – l’API distplot() non ha i parametri x, y per selezionare le colonne del DataFrame né ha la mappatura hue condizionale.
Quando gli sviluppatori di Seaborn stavano aggiornando i moduli di distribuzione in Seaborn v0.11.0, non hanno trovato un modo migliore dell’obsolescenza di distplot() per essere più coerenti con le altre funzioni di tracciamento delle distribuzioni.
Di conseguenza, Seaborn distplot() è obsoleto in Seaborn v0.11.0.
Chiamare questa funzione non ti impedisce realmente di creare grafici, ma emetterà un avviso di obsolescenza come ho già menzionato.
Ecco perché ho iniziato ad esplorare le alternative.
Quali Sono le Alternative a Seaborn Distplot()?
La documentazione di Seaborn suggerisce due alternative – displot() e histplot(). Ma personalmente ho trovato displot() come soluzione versatile.
Ti mostrerò come sia simile o diverso rispetto a distplot() deprecato.
displot() in Seaborn
Questa è una soluzione completa per tutti i tipi (univariati e bivariati) di grafici di distribuzione. Tutto ciò che devi fare è passare un DataFrame e il nome della colonna la cui distribuzione vuoi vedere.
Quindi, per ottenere un grafico di distribuzione simile a quello sopra, per la colonna ‘Perimetro’ puoi usare il codice qui sotto.
sns.displot(df, x="Perimetro")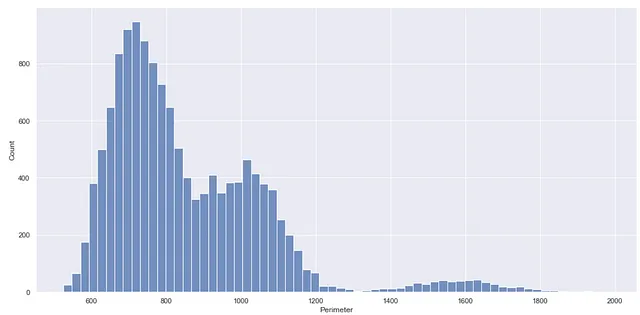
Crea semplicemente un istogramma che è lo stesso di quello creato dalla funzione distplot() deprecata. Puoi ottenere questo tipo di grafico utilizzando la funzione histplot(), un’altra alternativa alla funzione deprecata.
Ma cosa succede al KDE plot?
Puoi ottenere anche un grafico KDE usando questa funzione displot(). In questo caso il parametro kind della funzione è utile. Puoi assegnare kde al parametro kind per ottenere il grafico di stima della densità del kernel come mostrato di seguito.
sns.displot(df, x="Perimeter", kind='kde')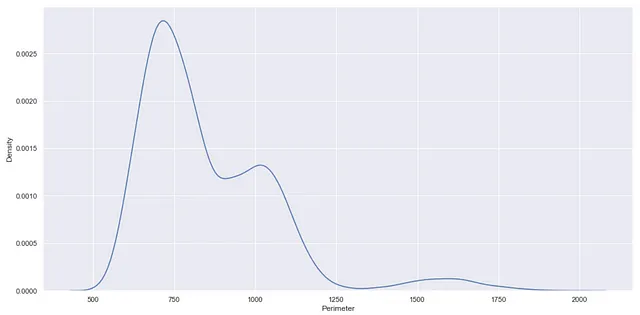
Fino ad ora, tutto bene!
Ma potresti avere ancora una domanda: come fa la funzione displot() a creare un grafico simile a quello creato usando distplot dove il KDE è rappresentato sopra l’istogramma?
E la risposta è: il parametro kde.
Come hai visto, di default displot() crea un istogramma. Quindi per creare un grafico KDE sopra un istogramma, puoi impostare il parametro kde su True, come mostrato di seguito.
sns.displot(df, x="Perimeter", kde=True)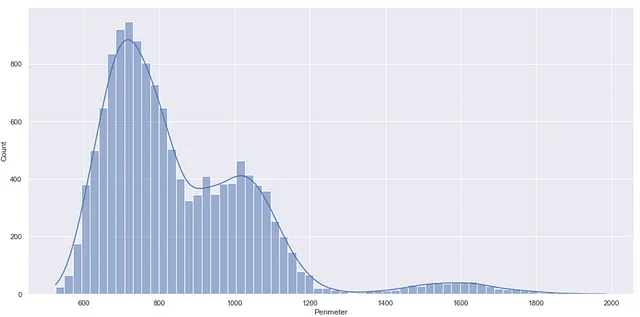
Ciò che rende veramente diversa la funzione displot da distplot è l’asse Y del grafico sopra.
Nella funzione deprecata distplot() l’asse Y rappresenta la densità di probabilità, mentre nella funzione displot() l’asse Y rappresenta il conteggio, cioè il numero di punti dati in ogni bin.
Il conteggio sull’asse Y può essere utile per capire immediatamente quale bin o intervallo di valori contiene il massimo/minimo numero di punti dati, il che non è il caso della densità di probabilità.
Bene, la flessibilità della funzione displot() non si ferma qui. Ti mostrerò cosa puoi fare con questa funzione che non era un compito facile con distplot().
Casi d’uso di displot() in seaborn
La funzione displot() ha una vasta gamma di parametri che puoi regolare per creare una varietà di grafici.
seaborn.displot(data=None, *, x=None, y=None, hue=None, row=None, col=None, weights=None, kind='hist', rug=False, rug_kws=None, log_scale=None, legend=True, palette=None, hue_order=None, hue_norm=None, color=None, col_wrap=None, row_order=None, col_order=None, height=5, aspect=1, facet_kws=None, **kwargs)Come puoi vedere nella definizione sopra, il parametro kind è impostato di default su 'hist', il che spiega perché displot() crea un istogramma quando il parametro kind non è specificato.
Non sto analizzando ogni singolo parametro, ma devo menzionare alcuni dei più interessanti.
Distribuzione bivariata
La capacità della funzione displot() di ottenere in input un DataFrame e le variabili dell’asse X-Y da quel DataFrame la rende molto utile quando si vuole ottenere una distribuzione bivariata, cioè la distribuzione di due variabili.
Ad esempio, supponiamo che si voglia ottenere la distribuzione dei punti dati quando vengono considerate due variabili Perimetro e rotondità. È sufficiente menzionare questi nomi di variabile nei parametri X e Y come mostrato di seguito.
sns.displot(df, x="Perimeter", y="roundness")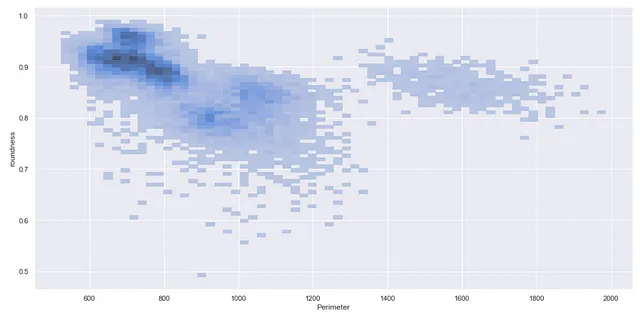
Il grafico sopra presenta chiaramente che il numero massimo di punti dati cade nella regione scura in cui il perimetro è compreso tra 600 e 800 e la rotondità è superiore a 0,85.
Quindi è possibile ottenere questo tipo di distribuzione bivariata per tutte le colonne numeriche.
Ma per le colonne categoriche?
Nel dataset, si può vedere che c’è una colonna categorica – Classe, che rappresenta le diverse classi di fagioli. Si può utilizzare questa variabile per creare sottoinsiemi dei dati che possono essere facilmente rappresentati tramite displot.
Grafici con i Sottoinsiemi dei Dati
Mentre si utilizza la funzione displot(), non è mai necessario creare separatamente sottoinsiemi del DataFrame. Si può semplicemente utilizzare il parametro hue per creare istogrammi o grafici KDE per ogni sottoinsieme dei dati.
Vediamo come funziona:
sns.displot(df, x="Perimeter", hue='Class')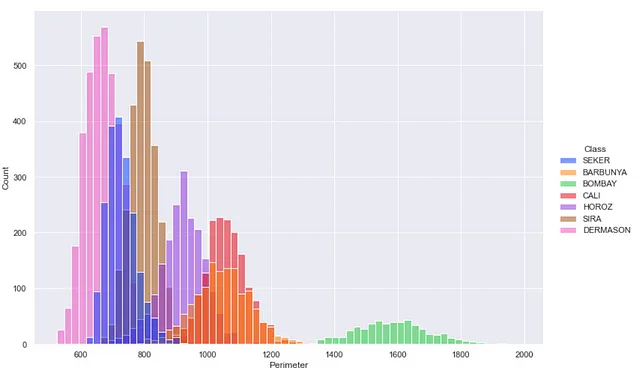
In questo modo si possono vedere diversi istogrammi per ogni sottoinsieme dei dati.
Se si desidera ottenere questi diversi istogrammi su diversi subplot. In tal caso, invece di hue, si dovrebbe utilizzare il parametro col come mostrato di seguito.
sns.displot(df, x="Perimeter", col='Class')
In questo modo, displot() creerà tanti subplot quanti sono i diversi sottoinsiemi che si hanno.
Si possono esplorare i parametri restanti in displot() quando necessario nel proprio progetto.
Spero che questo articolo sia stato utile. Ogni libreria di analisi dati evolve nel tempo. Di conseguenza, alcune funzioni diventano obsolete e vengono sostituite con funzioni migliorate che offrono un’esperienza utente migliore e più facile.
Anche se distplot() in Seaborn è obsoleto, non è completamente fuori dal mercato. Si può ancora utilizzarlo, ma è meglio passare alla funzione migliore – displot per ottenere diversi grafici di distribuzione.
Interessato a leggere altre storie su Nisoo??
💡 Considera di Diventare un Membro di Nisoo per accedere illimitatamente alle storie su Nisoo e alla Newsletter giornaliera interessante di Nisoo. Riceverò una piccola porzione della tua quota e nessun costo aggiuntivo per te.
💡 Assicurati di Registrarti e unirti ad altri 100+ per non perdere mai un altro articolo su guide, trucchi e consigli sulla scienza dei dati, e le migliori pratiche in SQL e Python.
Grazie per aver letto!
Dataset: Dry Beans Dataset Citation: Dry Bean Dataset. (2020). UCI Machine Learning Repository. https://doi.org/10.24432/C50S4B . Licenza: CC BY 4.0