Esplorazione di Diverse Approcci per Generare Curve di Risposta nella Modellizzazione del Mix di Marketing.
Exploring various approaches to generate response curves in marketing mix modeling.
Confronto tra Funzione di Saturazione e Dipendenza Parziale per la Generazione di Curve di Risposta
Le curve di risposta sono un componente essenziale della modellizzazione del mix di marketing, una tecnica statistica utilizzata per analizzare l’impatto di diverse strategie e tattiche di marketing sulle vendite o su altri risultati aziendali. Le curve di risposta rappresentano la relazione tra una variabile di marketing (ad esempio, spesa pubblicitaria, prezzo, promozione, ecc.) e le vendite o il fatturato generato da un prodotto o servizio.
L’importanza delle curve di risposta risiede nella loro capacità di rivelare l’efficacia di ciascuna variabile di marketing e come essa contribuisce alla risposta complessiva. Analizzando le curve di risposta, i marketer possono ottenere preziosi insight su quali tattiche di marketing stanno guidando maggiormente le vendite e quali non stanno fornendo i risultati desiderati.
Ci sono diversi approcci per la costruzione di curve di risposta, e in questo articolo esplorerò due metodi prominenti: l’approccio diretto utilizzando la trasformazione di saturazione e l’approccio basato sulla dipendenza parziale. Valuterò questi approcci utilizzando due diverse famiglie di algoritmi: la regressione lineare e il gradient boosting. Inoltre, mostrerò che l’approccio della dipendenza parziale può essere utilizzato in combinazione con le curve di risposta generate dai valori SHAP quando si utilizzano algoritmi di machine learning complessi.
Funzioni/Trasformazioni di Saturazione
L’approccio diretto alla costruzione di curve di risposta prevede l’utilizzo di funzioni di saturazione (trasformazioni) come la logistica, l’esponenziale negativo o la Hill. Una funzione di saturazione è una funzione matematica che cattura l’effetto di rendimenti decrescenti, dove l’impatto di una variabile di marketing si satura man mano che il suo valore aumenta. Utilizzando una funzione di saturazione, la relazione tra la variabile di marketing e la variabile di risposta può essere trasformata in una forma non lineare. Questo consente al modello di catturare l’effetto di saturazione e di rappresentare più accuratamente la vera relazione tra gli sforzi di marketing e la risposta (vendite o fatturato).
- Decodifica dell’Audizione del Senato degli Stati Uniti sulla Supervisione dell’IA Analisi NLP in Python.
- Le migliori 10 strumenti per rilevare ChatGPT, GPT-4, Bard e Claude
- L’arte dell’Ingegneria di Prompt Decodificare ChatGPT
Modellizzazione del Mix di Marketing utilizzando PyMC3
Esperimenti con priors, normalizzazione dei dati e confronto tra il modeling bayesiano e Robyn, il MMM open-source di Facebook…
towardsdatascience.com
Uno dei vantaggi dell’utilizzo di una trasformazione di saturazione è la sua semplicità e interpretabilità. La curva di risposta è definita da una funzione matematica con parametri fissi che determinano una curva regolare che può essere facilmente visualizzata. Tuttavia, la scelta della funzione di saturazione è una considerazione importante prima della modellizzazione. Diverse funzioni possono produrre risultati diversi, e la scelta dovrebbe essere basata sulle caratteristiche dei dati e sulle assunzioni sottostanti del modello.
Regressione Lineare e la Necessità di Non-Linearità
Nella modellizzazione del mix di marketing, la regressione lineare è una tecnica comunemente utilizzata per analizzare la relazione tra le variabili di marketing e la variabile di risposta. Tuttavia, la regressione lineare assume una relazione lineare tra le variabili predittive e la variabile di risposta. Ciò può rappresentare un limite quando si cerca di catturare le relazioni non lineari che spesso esistono nei dati di marketing.
Per superare questo limite e introdurre la non-linearità nel processo di modellizzazione, diventa necessario applicare una funzione di saturazione o una trasformazione alle variabili di marketing. Questa trasformazione consente di generare una relazione non lineare che altrimenti sarebbe lineare a causa della natura della regressione lineare.
Modellizzazione del Mix di Marketing Utilizzando Smoothing Splines
Catturare la saturazione pubblicitaria non lineare e il declino dei rendimenti senza trasformare esplicitamente le variabili di media
towardsdatascience.com
Approccio della Dipendenza Parziale
L’approccio della dipendenza parziale è un metodo più generale che può essere utilizzato per modellare la relazione tra qualsiasi variabile di marketing e la risposta. Questo approccio prevede di isolare l’effetto di una variabile mantenendo costanti tutte le altre variabili. Variando il valore della variabile di marketing di interesse e osservando la risposta corrispondente, si può creare un grafico della dipendenza parziale.
A differenza della curva di risposta regolare generata dalle trasformazioni di saturazione, il grafico risultante dall’approccio della dipendenza parziale potrebbe non essere necessariamente regolare. La sua forma dipende dall’algoritmo di modellizzazione sottostante e dalla relazione tra una variabile di media e la risposta. L’approccio della dipendenza parziale può essere utile quando la relazione è complessa e non lineare, e può essere applicato nei casi in cui viene utilizzata esplicitamente una trasformazione di saturazione o quando gli algoritmi gestiscono la non-linearità in modo naturale senza la necessità di ulteriori trasformazioni di saturazione.
Migliorare la modellizzazione del mix di marketing utilizzando approcci di apprendimento automatico
Costruzione di modelli MMM utilizzando ensembles basati su alberi e spiegazione della performance dei canali media utilizzando SHAP (Shapley Additive…
towardsdatascience.com
Dati
Continuo ad utilizzare il dataset reso disponibile da Robyn sotto licenza MIT come nei miei articoli precedenti per esempi pratici, e seguo gli stessi passaggi di preparazione dei dati applicando Prophet per decomporre le tendenze, la stagionalità e le festività.
Il dataset consiste in 208 settimane di ricavi (dal 23-11-2015 al 11-11-2019) che hanno:
- 5 canali di spesa media: tv_S, ooh_S, print_S, facebook_S, search_S
- 2 canali media che hanno anche informazioni di esposizione (Impression, Click): facebook_I, search_clicks_P (non utilizzati in questo articolo)
- Media organici senza spesa: newsletter
- Variabili di controllo: eventi, festività , vendite concorrenti ( competitor_sales_B)
Modellizzazione
Ho costruito un completo pipeline di MMM che può essere applicato in uno scenario reale per analizzare la spesa media sulla variabile di risposta, composto dai seguenti componenti:
- Trasformazione di Adstock con tasso di decadimento infinito (0 < α < 1)
- Trasformazione di saturazione Hill con due parametri: parametro di pendenza/forma, che controlla l’inclinazione della curva (s > 0) e punto di saturazione a metà (0 < k ≤ 1)
- Regressione di Ridge da scikit-learn
- Regressione di LightGBM con vincoli monotoni
- Validazione incrociata basata sul tempo
- Tuning degli iperparametri di Optuna
Nota sui coefficienti
In scikit-learn, la Regressione di Ridge non fornisce un’opzione integrata per imporre coefficienti positivi per un sottoinsieme di variabili. Tuttavia, una soluzione potenziale consiste nel rigettare la soluzione di optuna se si scopre che uno qualsiasi dei coefficienti dei media è negativo. Ciò può essere realizzato restituendo un valore eccezionalmente grande, segnalando che i coefficienti negativi non sono accettabili e dovrebbero essere esclusi dal modello. Un approccio alternativo potrebbe essere quello di fare riferimento al mio articolo su come avvolgere un R glmnet in Python, che consente il vincolo dei coefficienti per un sottoinsieme di variabili.
Per la regressione di Ridge, applico una trasformazione di saturazione e genero curve di risposta utilizzando sia la funzione di saturazione che gli approcci di dipendenza parziale. Con LightGBM, permetto al modello di catturare naturalmente non linearità e generare curve di risposta utilizzando l’approccio di dipendenza parziale. Inoltre, sovrappongo i valori SHAP sulla curva di risposta per fornire ulteriori informazioni.
Risultati
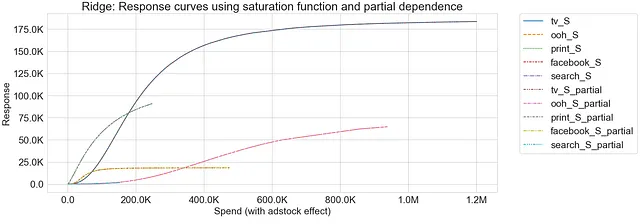
Regressione di Ridge con trasformazione di saturazione
Come si può osservare, entrambe le curve di risposta generate utilizzando la funzione di saturazione e la dipendenza parziale presentano schemi sovrapposti, indicando che i due metodi catturano relazioni simili tra la variabile di marketing e la risposta.
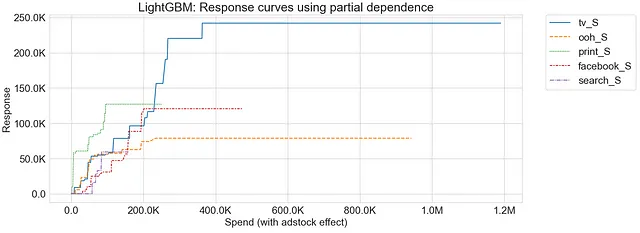
LightGBM
Come già menzionato, la curva di risposta risultante generata dalla dipendenza parziale non è necessariamente liscia. Una delle ragioni per questo può essere attribuita alla natura degli algoritmi di boosting del gradiente, che comportano la suddivisione dello spazio delle caratteristiche in regioni e l’incorporazione di interazioni tra più alberi decisionali.
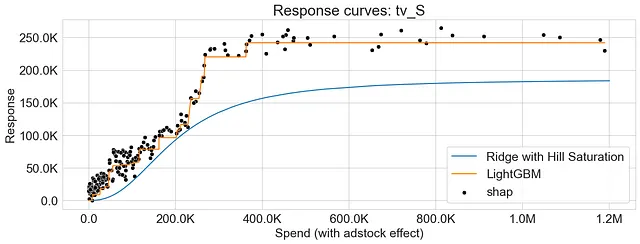
I grafici qui sotto rappresentano le curve di risposta per la Regressione di Ridge e LightGBM, evidenziando le disparità tra i due algoritmi nel catturare i rendimenti decrescenti. Inoltre, osserviamo che i valori SHAP offrono un’accurata approssimazione delle curve di risposta generate dall’approccio di dipendenza parziale.
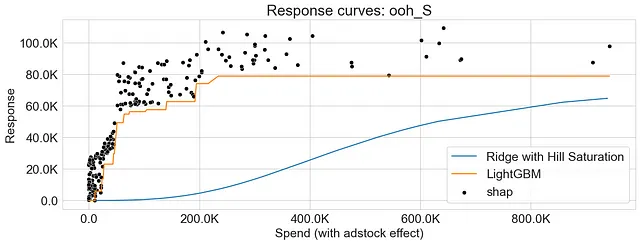
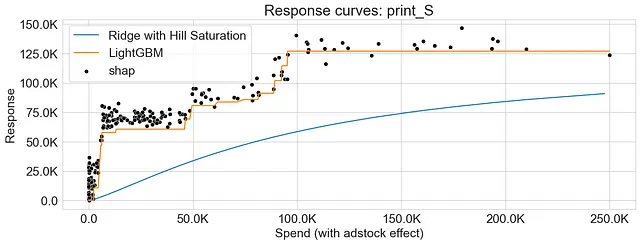
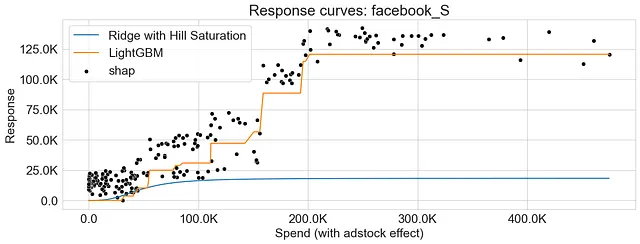
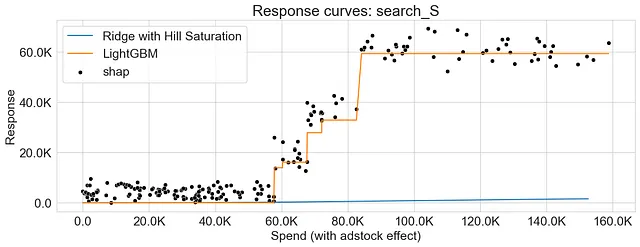
Conclusioni
Le curve di risposta giocano un ruolo cruciale nella modellizzazione del mix di marketing fornendo informazioni sull’efficacia delle diverse variabili di marketing e il loro contributo alla risposta complessiva. In questo articolo, ho esplorato due metodi prominenti per la generazione di curve di risposta: l’approccio diretto utilizzando le trasformazioni di saturazione e l’approccio di dipendenza parziale. Ho valutato questi approcci utilizzando due famiglie di algoritmi, la regressione lineare e il boosting del gradiente, e ho dimostrato i modi contrastanti in cui diversi algoritmi catturano la risposta non lineare. Inoltre, ho confrontato le risposte generate utilizzando i valori SHAP con i risultati ottenuti attraverso l’approccio di dipendenza parziale
Il codice completo può essere scaricato dal mio repository Github
Grazie per la lettura!






