Annunciamo la prima Sfida di Machine Unlearning
'Sfida di Machine Unlearning'
Pubblicato da Fabian Pedregosa ed Eleni Triantafillou, Scienziati della Ricerca, Google
L’apprendimento approfondito ha recentemente guidato un enorme progresso in una vasta gamma di applicazioni, che vanno dalla generazione realistica di immagini e impressionanti sistemi di recupero a modelli di linguaggio in grado di sostenere conversazioni simili a quelle umane. Sebbene questo progresso sia molto eccitante, l’uso diffuso dei modelli di reti neurali profonde richiede cautela: come indicato dai Principi di IA di Google, cerchiamo di sviluppare tecnologie di IA in modo responsabile comprendendo e mitigando potenziali rischi, come la propagazione e l’amplificazione di bias ingiusti e la protezione della privacy degli utenti.
Cancellare completamente l’influenza dei dati richiesti da cancellare è una sfida, poiché, oltre a cancellarli semplicemente dai database in cui sono archiviati, richiede anche di cancellarne l’influenza su altri artefatti come i modelli di apprendimento automatico addestrati. Inoltre, ricerche recenti [1, 2] hanno dimostrato che in alcuni casi potrebbe essere possibile inferire con elevata precisione se un esempio è stato utilizzato per addestrare un modello di apprendimento automatico utilizzando attacchi di inferenza di appartenenza (MIAs). Questo può sollevare preoccupazioni sulla privacy, poiché implica che anche se i dati di un individuo vengono cancellati da un database, potrebbe comunque essere possibile inferire se i dati di quell’individuo sono stati utilizzati per addestrare un modello.
Data la situazione descritta, il disapprendimento automatico è un sottocampo emergente dell’apprendimento automatico che mira a rimuovere l’influenza di un subset specifico di esempi di addestramento, il “set di dimenticanza”, da un modello addestrato. Inoltre, un algoritmo di disapprendimento ideale dovrebbe rimuovere l’influenza di determinati esempi mantenendo altre proprietà vantaggiose, come l’accuratezza sul resto del set di addestramento e la generalizzazione a esempi detenuti. Un modo semplice per ottenere questo modello disappreso è ritr addestrare il modello su un set di addestramento modificato che esclude i campioni del set di dimenticanza. Tuttavia, questa non è sempre una soluzione praticabile, poiché il ritraining dei modelli profondi può essere computazionalmente costoso. Un algoritmo di disapprendimento ideale dovrebbe invece utilizzare il modello già addestrato come punto di partenza e apportare efficientemente modifiche per rimuovere l’influenza dei dati richiesti.
- Ecco l’offerta giochi in streaming della Steam Summer Sale su GeForce NOW
- ‘La mia app 3D preferita’ Un appassionato di Blender condivide la sua scena ispirata al Giappone questa settimana ‘Nello Studio NVIDIA’
- 10 milioni di persone si iscrivono all’app di rivalità di Meta con Twitter, Threads
Oggi siamo entusiasti di annunciare che ci siamo uniti a un ampio gruppo di ricercatori accademici e industriali per organizzare la prima sfida di disapprendimento automatico. La competizione considera uno scenario realistico in cui, dopo l’addestramento, un certo subset delle immagini di addestramento deve essere dimenticato per proteggere la privacy o i diritti delle persone interessate. La competizione si svolgerà su Kaggle e le sottoposizioni saranno valutate automaticamente in termini di qualità del dimenticamento e utilità del modello. Speriamo che questa competizione contribuisca ad avanzare lo stato dell’arte nel disapprendimento automatico e incoraggi lo sviluppo di algoritmi di disapprendimento efficienti, efficaci ed etici.
Applicazioni del disapprendimento automatico
Il disapprendimento automatico ha applicazioni oltre alla protezione della privacy degli utenti. Ad esempio, è possibile utilizzare il disapprendimento per cancellare informazioni inesatte o obsolete dai modelli addestrati (ad esempio, a causa di errori nell’etichettatura o dei cambiamenti nell’ambiente) o rimuovere dati dannosi, manipolati o anomali.
Il campo del disapprendimento automatico è correlato ad altre aree dell’apprendimento automatico come la privacy differenziale, l’apprendimento continuo e l’equità. La privacy differenziale mira a garantire che nessun esempio di addestramento abbia un’influenza troppo grande sul modello addestrato; un obiettivo più forte rispetto a quello del disapprendimento, che richiede solo di cancellare l’influenza del set di dimenticanza designato. La ricerca sull’apprendimento continuo mira a progettare modelli in grado di imparare continuamente mantenendo le competenze acquisite in precedenza. Man mano che progredisce il lavoro sul disapprendimento, potrebbe anche aprire ulteriori modi per promuovere l’equità nei modelli, correggendo bias ingiusti o il trattamento disparato dei membri appartenenti a diversi gruppi (ad esempio, demografici, gruppi di età, ecc.).
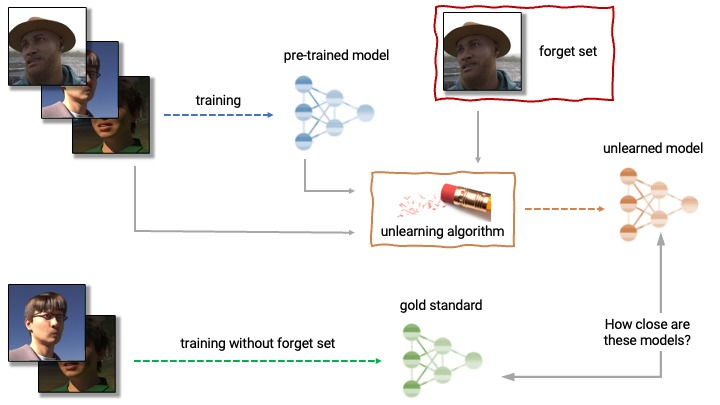 |
| Anatomia del disapprendimento automatico. Un algoritmo di disapprendimento prende in input un modello preaddestrato e uno o più campioni dal set di addestramento da disapprendere (il “set di dimenticanza”). Dall’insieme di modelli, set di dimenticanza e set di conservazione, l’algoritmo di disapprendimento produce un modello aggiornato. Un algoritmo di disapprendimento ideale produce un modello indistinguibile dal modello addestrato senza il set di dimenticanza. |
Sfide dell’apprendimento non supervisionato delle macchine
Il problema dell’apprendimento non supervisionato è complesso e sfaccettato poiché coinvolge diversi obiettivi contrastanti: dimenticare i dati richiesti, mantenere l’utilità del modello (ad esempio, l’accuratezza sui dati mantenuti e quelli esclusi) ed efficienza. A causa di ciò, gli algoritmi di apprendimento non supervisionato esistenti fanno diversi compromessi. Ad esempio, il completo ritraining ottiene una dimenticanza di successo senza danneggiare l’utilità del modello, ma con una scarsa efficienza, mentre l’aggiunta di rumore ai pesi ottiene una dimenticanza a spese dell’utilità.
Inoltre, l’valutazione degli algoritmi di dimenticanza nella letteratura finora è stata estremamente inconsistente. Mentre alcuni lavori riportano l’accuratezza della classificazione sui campioni da dimenticare, altri riportano la distanza dal modello completamente ritrained e altri ancora utilizzano il tasso di errore degli attacchi di inferenza di appartenenza come metrica di qualità della dimenticanza [4, 5, 6].
Riteniamo che l’inconsistenza delle metriche di valutazione e la mancanza di un protocollo standardizzato sia un serio ostacolo al progresso nel campo: non siamo in grado di fare confronti diretti tra diversi metodi di dimenticanza nella letteratura. Questo ci lascia con una visione miope dei relativi meriti e svantaggi di diversi approcci, nonché sfide aperte e opportunità per lo sviluppo di algoritmi migliorati. Per affrontare il problema dell’valutazione inconsistente e per far avanzare lo stato dell’arte nel campo dell’apprendimento non supervisionato delle macchine, ci siamo uniti a un ampio gruppo di ricercatori accademici e industriali per organizzare la prima sfida di dimenticanza.
Annuncio della prima sfida di apprendimento non supervisionato delle macchine
Siamo lieti di annunciare la prima sfida di apprendimento non supervisionato delle macchine, che si svolgerà come parte della traccia di competizione NeurIPS 2023. L’obiettivo della competizione è duplice. In primo luogo, unificando e standardizzando le metriche di valutazione per l’apprendimento non supervisionato, speriamo di identificare i punti di forza e debolezza di diversi algoritmi attraverso confronti paritetici. In secondo luogo, aprendo questa competizione a tutti, speriamo di favorire soluzioni innovative e gettare luce su sfide aperte e opportunità.
La competizione sarà ospitata su Kaggle e si svolgerà tra metà luglio 2023 e metà settembre 2023. Come parte della competizione, oggi annunciamo la disponibilità del kit di partenza . Questo kit di partenza fornisce una base per i partecipanti per costruire e testare i loro modelli di dimenticanza su un dataset di prova.
La competizione considera uno scenario realistico in cui un predittore di età è stato addestrato su immagini facciali e, dopo l’addestramento, un certo sottoinsieme delle immagini di addestramento deve essere dimenticato per proteggere la privacy o i diritti delle persone interessate. A tale scopo, renderemo disponibile come parte del kit di partenza un dataset di volti sintetici (campioni mostrati di seguito) e utilizzeremo anche diversi dataset di volti reali per la valutazione delle sottomissioni. Ai partecipanti viene chiesto di inviare il codice che prende in input il predittore addestrato, i set di dimenticanza e di ritenzione e restituisce i pesi di un predittore che ha dimenticato il set di dimenticanza designato. Valuteremo le sottomissioni sia in base alla forza dell’algoritmo di dimenticanza che all’utilità del modello. Applicheremo anche un limite rigido che respinge gli algoritmi di dimenticanza che eseguono più lentamente di una frazione del tempo necessario per il ritraining. Un risultato prezioso di questa competizione sarà caratterizzare i compromessi di diversi algoritmi di dimenticanza.
 |
| Estratto di immagini dal dataset Face Synthetics insieme ad annotazioni di età. La competizione considera lo scenario in cui un predittore di età è stato addestrato su immagini facciali come quelle sopra, e, dopo l’addestramento, un certo sottoinsieme delle immagini di addestramento deve essere dimenticato. |
Per valutare la dimenticanza, utilizzeremo strumenti ispirati alle MIAs (Membership Inference Attacks), come LiRA . Le MIAs sono state sviluppate per la prima volta nella letteratura sulla privacy e sulla sicurezza e il loro obiettivo è inferire quali esempi facevano parte del set di addestramento. In modo intuitivo, se l’apprendimento non supervisionato ha successo, il modello dimenticato non contiene tracce degli esempi dimenticati, causando il fallimento delle MIAs: l’attaccante non sarebbe in grado di inferire che il set di dimenticanza faceva parte del set di addestramento originale. Inoltre, utilizzeremo anche test statistici per quantificare quanto diversa sia la distribuzione dei modelli dimenticati (prodotti da un particolare algoritmo di dimenticanza sottomesso) rispetto alla distribuzione dei modelli ritrained da zero. Per un algoritmo di dimenticanza ideale, queste due distribuzioni saranno indistinguibili.
Conclusione
Il disimparare automatico è uno strumento potente che ha il potenziale per affrontare diversi problemi aperti nell’apprendimento automatico. Con la continuazione della ricerca in questo settore, speriamo di vedere nuovi metodi che siano più efficienti, efficaci e responsabili. Siamo entusiasti di avere l’opportunità, tramite questa competizione, di suscitare interesse in questo campo e non vediamo l’ora di condividere le nostre intuizioni e i nostri risultati con la comunità.
Ringraziamenti
Gli autori di questo post fanno ora parte di Google DeepMind. Stiamo scrivendo questo post a nome del team organizzatore della Competizione di Disimparare: Eleni Triantafillou*, Fabian Pedregosa* (*contributo paritario), Meghdad Kurmanji, Kairan Zhao, Gintare Karolina Dziugaite, Peter Triantafillou, Ioannis Mitliagkas, Vincent Dumoulin, Lisheng Sun Hosoya, Peter Kairouz, Julio C. S. Jacques Junior, Jun Wan, Sergio Escalera e Isabelle Guyon.






