Come le aziende possono costruire il proprio grande modello linguistico simile al ChatGPT di OpenAI
Come le aziende possono creare un proprio grande modello linguistico simile a ChatGPT di OpenAI.
Vuoi creare il tuo proprio ChatGPT? Ecco tre modi per farlo
Introduzione
I modelli di linguaggio hanno guadagnato notevole attenzione negli ultimi anni, rivoluzionando vari campi come l’elaborazione del linguaggio naturale, la generazione di contenuti e gli assistenti virtuali. Uno degli esempi più importanti è ChatGPT di OpenAI, un grande modello di linguaggio in grado di generare testi simili a quelli umani ed essere coinvolto in conversazioni interattive. Questo ha suscitato la curiosità delle aziende, spingendole ad esplorare l’idea di costruire i propri grandi modelli di linguaggio (LLM).
Tuttavia, la decisione di intraprendere la costruzione di un LLM dovrebbe essere valutata attentamente. Richiede risorse significative, sia in termini di potenza di calcolo che di disponibilità dei dati. Le aziende devono valutare i vantaggi rispetto ai costi, valutare l’expertise tecnica richiesta e valutare se si allinea con i loro obiettivi a lungo termine.
In questo articolo, ti mostriamo tre modi per costruire il tuo LLM, simile a ChatGPT di OpenAI. Alla fine di questo articolo, avrai una comprensione più chiara delle sfide, dei requisiti e delle potenziali ricompense associate alla costruzione del tuo grande modello di linguaggio. Quindi immergiamoci!
Le aziende dovrebbero creare il loro proprio LLM?
Per capire se le aziende dovrebbero creare il loro proprio LLM, esploriamo i tre modi principali in cui possono sfruttare tali modelli.
- Utilizzare i Data Frame di Pandas in modo più efficace con le 7 principali operazioni sulle colonne
- Esaminare i voli negli Stati Uniti con AWS e Power BI
- Comprensione del codice sul proprio hardware

1. LLM con codice sorgente chiuso: Le aziende possono utilizzare servizi LLM preesistenti come ChatGPT di OpenAI, Bard di Google o offerte simili di diversi fornitori. Questi servizi forniscono una soluzione pronta all’uso, consentendo alle aziende di sfruttare la potenza dei LLM senza la necessità di un investimento significativo in infrastrutture o di competenze tecniche.
Pro:
- Implementazione rapida e semplice, risparmiando tempo e sforzi.
- Buone prestazioni nelle attività di generazione di testo generiche.
Contro:
- Controllo limitato sul comportamento e sulle risposte del modello
- Meno preciso sui dati specifici del dominio o dell’azienda
- Preoccupazioni sulla privacy dei dati poiché i dati vengono inviati al terzo che ospita il servizio
- Dipendenza dai fornitori di terze parti e potenziali fluttuazioni dei prezzi.
2. Utilizzo di LLM specifici del dominio: Un altro approccio consiste nell’utilizzare modelli di linguaggio specifici del dominio, come BloombergGPT per le finanze, BioMedLM per le applicazioni biomediche, MarketingGPT per le applicazioni di marketing, CommerceGPT per le applicazioni di e-commerce, ecc. Questi modelli vengono addestrati su dati specifici del dominio, consentendo risposte più accurate e personalizzate nei rispettivi settori.
Pro:
- Miglior precisione in domini specifici grazie all’addestramento su dati pertinenti.
- Disponibilità di modelli preaddestrati adattati a settori specifici.
Contro:
- Flessibilità limitata nell’adattare il modello oltre il suo dominio designato.
- Dipendenza dagli aggiornamenti del provider e dalla disponibilità di modelli specifici del dominio.
- Precisione leggermente migliore ma comunque limitata in quanto non specifica per i dati aziendali
- Preoccupazioni sulla privacy dei dati poiché i dati vengono inviati al terzo che ospita il servizio
3. Costruire e ospitare un LLM personalizzato: L’opzione più completa è per le aziende costruire e ospitare il proprio LLM utilizzando i propri dati specifici. Questo approccio offre il più alto livello di personalizzazione e controllo sulla privacy dei contenuti generati. Consente alle organizzazioni di ottimizzare il modello secondo i loro requisiti unici, garantendo precisione specifica del dominio e allineamento con la loro voce di marca.
Pro:
- Personalizzazione e controllo completi: Un modello personalizzato consente alle aziende di generare risposte che si allineano precisamente con la loro voce di marca, terminologia specifica del settore e requisiti unici.
- Costo efficace: se configurato correttamente (costo di perfezionamento dell’ordine di centinaia di dollari)
- Trasparenza: Dati e modello sono conosciuti dall’azienda
- Migliore precisione: Allenando il modello sui dati e sui requisiti specifici dell’azienda, può comprendere e rispondere meglio alle query specifiche dell’azienda, producendo output più accurati e contestualmente rilevanti.
- Riservato: I dati e il modello rimangono nel tuo ambiente. Avere un modello personalizzato consente alle aziende di mantenere il controllo sui propri dati sensibili, riducendo al minimo le preoccupazioni legate alla privacy dei dati e alle violazioni della sicurezza.
- Vantaggio competitivo: Un grande modello di linguaggio personalizzato può essere un elemento differenziante significativo in settori in cui il trattamento del linguaggio personalizzato e accurato svolge un ruolo cruciale.
Contro:
- Necessità di competenze significative in ML & LLM per costruire un modello di linguaggio personalizzato di grandi dimensioni
È importante notare che l’approccio al LLM personalizzato dipende da vari fattori, tra cui il budget dell’azienda, i vincoli di tempo, l’accuratezza richiesta e il livello di controllo desiderato. Tuttavia, come si può vedere dall’elenco sopra, la costruzione di un LLM personalizzato sui dati specifici dell’azienda offre numerosi vantaggi.
I modelli di linguaggio personalizzati di grandi dimensioni offrono una personalizzazione, un controllo e un’accuratezza senza precedenti per domini specifici, casi d’uso e requisiti aziendali. Pertanto, le aziende dovrebbero cercare di costruire il proprio modello di linguaggio personalizzato di grandi dimensioni specifico per l’azienda, per sbloccare un mondo di possibilità su misura per le proprie esigenze, il settore e la base di clienti.
Tre modi per costruire il proprio modello di linguaggio personalizzato di grandi dimensioni
È possibile costruire il proprio LLM personalizzato in tre modi e questi vanno da una bassa complessità a una alta complessità come mostrato nell’immagine sottostante.
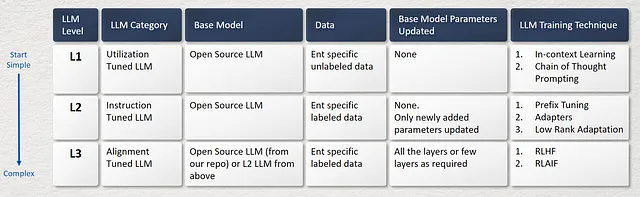
L1. LLM a Utilizzo Ottimizzato
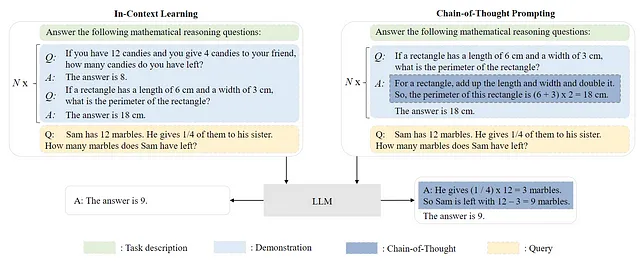
Un metodo prevalente per sfruttare i LLM pre-addestrati consiste nello sviluppare tecniche di prompting efficaci per affrontare diverse attività. Un esempio di un approccio di prompting comune è l’Apprendimento in Contesto (ICL), che prevede l’espressione di descrizioni e/o dimostrazioni di attività in testo in linguaggio naturale. Inoltre, l’utilizzo di Catena di Pensiero (CoT) può arricchire l’apprendimento in contesto incorporando una sequenza di passaggi di ragionamento intermedi all’interno dei prompting. Per costruire un L1 LLM,
Per costruire un L1 LLM,
- Iniziare selezionando un LLM pre-addestrato adatto (che può essere trovato nella libreria di modelli di Hugging Face o altre risorse online), assicurandosi che sia compatibile con l’uso commerciale attraverso la revisione della licenza.
- Successivamente, individuare fonti di dati rilevanti per il proprio dominio specifico o caso d’uso, assemblando un dataset diversificato e completo che comprenda una vasta gamma di argomenti e variazioni linguistiche. Per il L1 LLM, non è necessario avere dati etichettati.
- Nel processo di personalizzazione, i parametri del modello del LLM pre-addestrato scelto rimangono inalterati. Invece, vengono utilizzate tecniche di prompting per adattare le risposte del LLM al dataset.
- Come accennato in precedenza, l’Apprendimento in Contesto e il Prompting Catena di Pensiero sono due approcci comuni per la tecnica di prompting. Queste tecniche, collettivamente note come Resource Efficient Tuning (RET), offrono un modo efficiente per ottenere risposte senza richiedere risorse di infrastruttura significative.
L2. LLM a Istruzioni Ottimizzate
L’ottimizzazione delle istruzioni è l’approccio per il fine-tuning dei LLM pre-addestrati su una collezione di istanze formattate in forma di linguaggio naturale, che è strettamente correlato al fine-tuning supervisionato e all’addestramento multi-task con prompt. Con l’ottimizzazione delle istruzioni, i LLM sono in grado di seguire le istruzioni delle nuove attività senza l’uso di esempi espliciti (simile alla capacità zero-shot), acquisendo così una migliore capacità di generalizzazione. Per costruire questo L2 LLM ottimizzato tramite istruzioni,
- Iniziare selezionando un LLM pre-addestrato adatto (che può essere trovato nella libreria di modelli di Hugging Face o altre risorse online), assicurandosi che sia compatibile con l’uso commerciale attraverso la revisione della licenza.
- Successivamente, individuare fonti di dati rilevanti per il proprio dominio o caso d’uso di destinazione. È necessario un dataset etichettato che contenga una varietà di istruzioni specifiche per il proprio dominio o caso d’uso. Ad esempio, è possibile fare riferimento al dataset dolly-15k fornito da Databricks, che offre istruzioni in diversi formati come closed-qa, open-qa, classificazione, recupero delle informazioni e altro ancora. Questo dataset può servire come modello per costruire il proprio dataset di istruzioni.
- Passando al processo di fine-tuning supervisionato, si introducono nuovi parametri di modello nel LLM base originale scelto nel passaggio 1. Aggiungendo questi parametri, è possibile addestrare il modello per un determinato numero di epoche per ottimizzarlo per le istruzioni fornite. Il vantaggio di questo approccio è che evita la necessità di aggiornare miliardi di parametri presenti nel LLM base, concentrandosi invece su un numero inferiore di parametri aggiuntivi (migliaia o milioni) pur ottenendo risultati accurati nell’attività desiderata. Questo approccio aiuta anche a ridurre i costi.
- Il passo successivo è il fine-tuning. Saranno illustrate in futuro varie tecniche di fine-tuning come il prefix tuning, gli adattatori, l’attenzione a basso rango e altro ancora. Il processo di aggiunta di nuovi parametri di modello discusso al punto 3 dipende anche da queste tecniche. Per informazioni più dettagliate, fare riferimento alla sezione delle referenze. Queste tecniche rientrano nella categoria di Parameter Efficient Fine Tuning (PEFT), in quanto consentono la personalizzazione senza aggiornare tutti i parametri del LLM base.
L3. LLM allineato
Dato che gli LLM sono addestrati per catturare le caratteristiche dei dati dei corpus di pre-training (che includono sia dati di alta qualità che di bassa qualità), è probabile che generino contenuti tossici, di parte o addirittura dannosi per gli esseri umani. Pertanto potrebbe essere necessario allineare gli LLM ai valori umani, ad esempio utili, onesti e innocui. A questo scopo, utilizziamo la tecnica del reinforcement learning con il feedback umano (RLHF), un approccio efficace che consente agli LLM di seguire le istruzioni attese. Incorpora gli esseri umani nel ciclo di addestramento con strategie di etichettatura accuratamente progettate. Per costruire questo LLM allineato all’ L3,
- Inizia selezionando un LLM pre-addestrato open-source (che può essere trovato nella libreria dei modelli di Hugging Face o su altre risorse online) o il tuo LLM L2 come modello di base.
- La tecnica principale per la costruzione di un LLM allineato è RLHF, che combina apprendimento supervisionato e reinforcement learning. Inizia prendendo un LLM sintonizzato su un dominio specifico o un corpus di istruzioni (dal passaggio 1) e utilizzalo per generare risposte. Quindi queste risposte vengono annotate utilizzando un essere umano per addestrare un modello di ricompensa supervisionato (tipicamente utilizzando un altro LLM pre-addestrato come modello di base). Infine, il LLM (dal passaggio 1) viene nuovamente sintonizzato utilizzando il reinforcement learning (PPO) con il modello di ricompensa per generare la risposta finale.
- In questo modo vengono addestrati due LLM: uno per il modello di ricompensa e un altro per la sintonizzazione fine del LLM per generare la risposta finale. I parametri del modello di base in entrambi i casi possono essere aggiornati selettivamente, a seconda dell’accuratezza desiderata nella risposta. Ad esempio, in alcuni metodi RLHF, vengono aggiornati solo i parametri di specifici strati o componenti coinvolti nel reinforcement learning per evitare l’overfitting e mantenere le conoscenze generali acquisite dall’LLM pre-addestrato.
Un aspetto interessante di questo processo è che i sistemi RLHF di successo finora hanno utilizzato modelli di linguaggio di ricompensa con dimensioni variabili rispetto alla generazione del testo (ad esempio, OpenAI 175B LM, modello di ricompensa da 6B, Anthropic ha utilizzato LM e modelli di ricompensa da 10B a 52B, DeepMind utilizza modelli Chinchilla da 70B sia per LM che per ricompensa). L’intuizione sarebbe che questi modelli di preferenza devono avere una capacità simile per comprendere il testo loro fornito come un modello avrebbe bisogno per generare tale testo.
Esiste anche RLAIF (Reinforcement Learning with AI Feedback) che può essere utilizzato al posto di RLHF. La differenza principale qui è che invece del feedback umano, un modello AI funge da valutatore o critico, fornendo feedback all’agente AI durante il processo di reinforcement learning.
Conclusioni
Le aziende possono sfruttare il potenziale straordinario degli LLM personalizzati per ottenere una personalizzazione, un controllo e una precisione eccezionali che si allineano con i loro domini specifici, casi d’uso e richieste organizzative. La costruzione di un LLM personalizzato specifico per l’azienda consente alle imprese di sbloccare una moltitudine di opportunità su misura, perfettamente adatte alle loro esigenze uniche, alla dinamica del settore e alla base di clienti.
Il percorso per la costruzione del proprio LLM personalizzato ha tre livelli, partendo da una complessità, accuratezza e costo del modello bassi a una complessità, accuratezza e costo del modello elevati. Le aziende devono bilanciare questo compromesso per soddisfare al meglio le proprie esigenze ed estrarre un ROI dalla propria iniziativa LLM.

Riferimenti
- Cos’è l’ingegneria delle istruzioni?
- In-Context Learning (ICL) — Q. Dong, L. Li, D. Dai, C. Zheng, Z. Wu, B. Chang, X. Sun, J. Xu, L. Li e Z. Sui, “A survey for in-context learning,” CoRR, vol. abs/2301.00234, 2023.
- Come funziona l’apprendimento in contesto? Un framework per comprendere le differenze rispetto all’apprendimento supervisionato tradizionale | SAIL Blog (stanford.edu)
- Chain of Thought Prompting — J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. H. Chi, Q. Le e D. Zhou, “Chain of thought prompting elicits reasoning in large language models,” CoRR, vol. abs/2201.11903, 2022.
- I modelli di linguaggio eseguono il ragionamento tramite catena di pensieri — Google AI Blog (googleblog.com)
- Instruction Tuning — J. Wei, M. Bosma, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai e Q. V. Le, “Fine-tuned language models are zero-shot learners,” in The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25–29, 2022. OpenReview.net, 2022.
- Un sondaggio sui Large Language Models — Wayne Xin Zhao, Kun Zhou*, Junyi Li*, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie e Ji-Rong Wen, arXiv:2303.18223v4 [cs.CL], 12 aprile 2023.




