Implementare lo sviluppo guidato dal comportamento nelle pipeline dei dati utilizzando Mage
Implementare il comportamento guidato nello sviluppo delle pipeline dati con Mage.
Massimizza la qualità e la produttività delle tue pipeline di dati
Nei miei articoli precedenti, ho parlato molto dell’importanza dei test nelle pipeline di dati e di come creare rispettivamente test di dati e test di unità. Sebbene i test svolgano un ruolo essenziale, potrebbero non essere sempre la parte più entusiasmante del ciclo di sviluppo. Di conseguenza, molte stack di dati moderne hanno introdotto framework o plugin per accelerare l’implementazione dei test di dati. Inoltre, i framework di test di unità in Python come Pytest, unittest sono stati presenti da molto tempo, aiutando gli ingegneri a creare efficacemente test di unità per le pipeline di dati e qualsiasi applicazione Python.
In questo articolo, voglio presentare una configurazione che utilizza due tecniche moderne: Behaviour Driven Development (BDD) – un framework di test orientato al business, e Mage – uno strumento moderno per le pipeline di dati. Combinando queste due tecniche, l’obiettivo è creare test di unità di alta qualità per le pipeline di dati, garantendo al contempo un’esperienza di sviluppo senza soluzione di continuità.
Cos’è il Behaviour Driven Development (BDD)?
Quando si costruiscono pipeline di dati per il business, è molto probabile che ci si imbatta in logiche aziendali complesse e difficili. Un esempio è definire la segmentazione dei clienti in base a una combinazione di età, reddito e acquisti passati. L’esempio seguente rappresenta solo una frazione della complessità che la logica aziendale può comportare. Può diventare progressivamente complicato man mano che ci sono più attributi e granularità all’interno di ciascun attributo. Pensa a un esempio nel tuo lavoro quotidiano!
1. Le persone tra i 19 e i 60 anni E con alti acquisti passati sono "premium".2. Le persone tra i 19 e i 60 anni E con un alto reddito sono "premium".3. Le persone sopra i 60 anni E con un alto reddito E con alti acquisti passati sono "premium".4. Gli altri sono "base".Quindi la domanda è dove dovrebbero essere documentate le regole aziendali e come garantire la sincronizzazione tra la documentazione e il codice. Un approccio comune è includere commenti insieme al codice o cercare di scrivere codice che sia autoesplicativo e facilmente comprensibile. Ma c’è ancora il rischio di avere commenti obsoleti o codice che gli stakeholder trovano difficili da comprendere.
- Sbocciare il Tokenizer ChatGPT
- Taipy uno strumento per la costruzione di applicazioni di data science pronte per la produzione, facili da usare per gli utenti.
- RAPIDS Usa la GPU per accelerare facilmente i modelli di ML
In definitiva, ciò che stiamo cercando è una soluzione “documentazione-come-codice” che possa beneficiare sia degli ingegneri che degli stakeholder aziendali e questo è esattamente ciò che BDD può offrire. Se conosci il concetto di “contratto di dati”, BDD può essere visto come una forma di contratto di dati, ma con un focus sugli stakeholder piuttosto che sulla sorgente dei dati. Può essere molto vantaggioso, in particolare per le pipeline di dati con logiche aziendali complesse, e aiuta a evitare discussioni su “caratteristica o difetto”.
BDD è essenzialmente un approccio allo sviluppo del software che enfatizza la collaborazione e la comunicazione tra gli stakeholder e gli sviluppatori per garantire che il software soddisfi gli obiettivi aziendali desiderati. Il comportamento è descritto in scenari che illustrano gli input e gli output attesi. Ogni scenario è scritto in un formato specifico di “Dato-Che-Cosa” in cui ogni passaggio descrive una condizione o un’azione specifica.
Vediamo come potrebbero apparire gli scenari per l’esempio di segmentazione dei clienti. Poiché il file delle caratteristiche è scritto in inglese, può essere ben compreso dagli stakeholder aziendali e possono persino contribuirvi. Funziona come un contratto tra gli stakeholder e gli ingegneri, in cui gli ingegneri sono responsabili dell’implementazione accurata dei requisiti e ci si aspetta che gli stakeholder forniscano tutte le informazioni necessarie.
Avere un contratto chiaro tra gli stakeholder e gli ingegneri aiuta a categorizzare correttamente il problema dei dati, distinguendo tra “difetti software” derivanti da errori di implementazione e “richieste di funzionalità” dovute a requisiti mancanti.
File delle caratteristiche (Creato dall’autore)
Il passo successivo è generare il codice di test a partire dalla caratteristica e qui avviene la connessione. Il codice Pytest funge da ponte tra la documentazione e il codice di implementazione. Quando c’è una mancanza di allineamento tra di essi, i test falliranno, evidenziando la necessità di sincronizzazione tra documentazione e implementazione.

Ecco come appare il codice di test. Per mantenere l’esempio breve, implemento solo il codice di test per il primo scenario. I passaggi Dato impostano il contesto iniziale per lo scenario che in questo caso ottiene i dati dell’età del cliente, del reddito e degli acquisti passati dagli esempi. Il passaggio Quando attiva il comportamento in fase di test, ovvero la funzione get_user_segment. Nel passaggio Allora confrontiamo il risultato del passaggio Quando con l’output atteso dell’esempio dello scenario.
Codice di test del primo scenario nel file delle funzionalità (Creato dall’autore)
Immagina una modifica all’intervallo di età specificato nel primo scenario, in cui viene aggiunta un’età di esempio di 62 anni senza aggiornare il codice. In tal caso, il test fallirebbe immediatamente perché il codice ha aspettative in conflitto.
Cos’è Mage?
Fino ad ora, abbiamo visto il potenziale del BDD e imparato come implementarlo usando Python. Ora è il momento di incorporare il BDD nelle nostre pipeline dati. Quando si tratta di orchestrare i dati, Airflow come primo orchestratore basato su Python con un’interfaccia web è diventato lo strumento più comunemente utilizzato per l’esecuzione delle pipeline dati.
Ma certamente non è perfetto. Ad esempio, testare le pipeline al di fuori dell’ambiente di produzione, specialmente quando si utilizzano operatori come KubernetesOperator, può essere una sfida. Inoltre, un DAG può essere appesantito da codice boilerplate e configurazioni complesse, rendendo meno immediato capire lo scopo di ogni attività, che sia ingestione, trasformazione o esportazione. Inoltre, Airflow non è incentrato su essere uno strumento di orchestratura basato sui dati perché si preoccupa più dell’esecuzione corretta delle attività che della qualità dei dati finali.
Con l’aumento della comunità di data engineering, sono emerse molte alternative ad Airflow per colmare il vuoto presente in Airflow. Mage è uno degli strumenti di pipeline dati in crescita che è considerato un sostituto moderno di Airflow. I suoi quattro concetti di design distinguono Mage da Airflow e possiamo percepire la differenza fin dall’inizio del ciclo di sviluppo.

Mage ha un’interfaccia utente molto intuitiva che consente agli ingegneri di modificare e testare rapidamente la pipeline con facilità ed efficienza.
Ogni pipeline è composta da diversi tipi di blocchi: @data_loader, @transformer, @data_exporter, ecc., con uno scopo chiaro. Questa è una delle mie caratteristiche preferite perché posso comprendere immediatamente l’obiettivo di ogni attività e concentrarmi sulla logica di business anziché essere intrappolato nel codice boilerplate.
BDD + Mage
Una pipeline dati regolare ha tre fasi principali: ingestione, trasformazione ed esportazione. La trasformazione è il luogo in cui viene implementata tutta la logica di business complicata ed è comune avere più passaggi di trasformazione incorporati.
La chiara separazione dell’attività di ingestione e dell’attività di trasformazione rende incredibilmente semplice e intuitivo applicare il BDD alla logica di trasformazione. Infatti, sembra proprio come testare una normale funzione Python, ignorando il fatto che fa parte di una pipeline dati.
Torniamo all’esempio di segmentazione degli utenti. Le regole di business dovrebbero trovarsi nel blocco @transformer e sono decouplate dal caricatore e dall’esportatore.
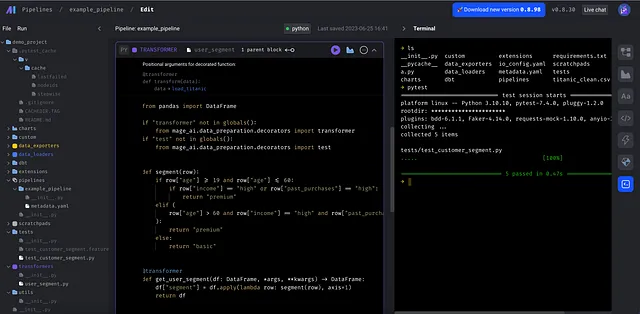
Lo stesso blocco @transformer può essere collegato a più pipeline purché il caricatore restituisca un dataframe pandas. Per eseguire il test, è sufficiente eseguire il comando pytest nel terminale o nella pipeline CI/CD. La configurazione della pipeline, come il trigger, si trova in un file separato che mantiene il file principale della pipeline il più pulito possibile.
Immaginiamo cosa succederebbe se implementassimo questo in Airflow. Poiché non si tratta di un esempio complicato, Airflow può gestirlo senza problemi. Ma ci sono alcuni dettagli che mi fanno sentire “errrr” quando passo da Mage ad Airflow.
- Il file DAG si appesantisce poiché ogni DAG ha un grande blocco di codice per definire i metadati. In Mage, la configurazione viene spostata in un file yaml, in modo che il file della pipeline rimanga conciso.
@dag( dag_id="user_segment", schedule_interval="0 0 * * *", start_date=pendulum.datetime(2023, 1, 1, tz="UTC"), catchup=False, dagrun_timeout=datetime.timedelta(minutes=60),)2. Il passaggio dei dati è complicato in Airflow. XCOM in Airflow viene utilizzato per passare dati tra i task. Tuttavia, non è consigliato passare grandi set di dati come i dataframe direttamente tramite XCOM. Come soluzione alternativa, è necessario persistere i dati in uno storage temporaneo, il che sembra essere uno sforzo ingegneristico superfluo. Mage gestisce naturalmente il passaggio dei dati per noi e non dobbiamo preoccuparci delle dimensioni del set di dati.
3. Tecnicamente, Airflow supporta diverse versioni di pacchetti Python, ma a un costo elevato. KubernetesPodOperator e PythonVirtualenvOperator consentono di eseguire un task in un ambiente isolato. Tuttavia, perderai tutte le comodità fornite da Airflow, come l’utilizzo di un altro operatore. Al contrario, Mage affronta questa sfida utilizzando un requirements.txt centralizzato, garantendo che tutti i task abbiano accesso a tutte le funzionalità native di Mage.
Conclusioni
In questo articolo, ho unito due tecnologie con l’obiettivo di migliorare la qualità dei test e l’esperienza dello sviluppatore. BDD mira a migliorare la collaborazione tra le parti interessate e gli ingegneri creando un contratto nel formato di un file di funzionalità incorporato direttamente nel codice. D’altra parte, Mage è un ottimo strumento per la pipeline dei dati che tiene l’esperienza dello sviluppatore come priorità assoluta e tratta davvero i dati come cittadini di prima classe.
Spero che tu lo trovi ispirante e ti senta motivato a esplorare e incorporare almeno una di queste tecnologie nel tuo lavoro quotidiano. La scelta degli strumenti giusti può sicuramente amplificare la produttività del tuo team. Sono curioso di sapere cosa ne pensi. Fammi sapere nei commenti. Saluti!





