Potenziare l’equità Riconoscere e Affrontare il Pre-giudizio nei Modelli Generativi
'Potenziamento dell'equità Riconoscimento e affronto del pregiudizio nei modelli generativi'
Con l’integrazione dell’IA nella nostra vita quotidiana, un modello biased può avere conseguenze drastiche sugli utenti
Nel 2021, il Centro per la Politica dell’Informazione Tecnologica dell’Università di Princeton ha pubblicato un rapporto in cui si afferma che gli algoritmi di machine learning possono acquisire bias simili a quelli umani dai dati di addestramento. Un esempio eclatante di questo effetto è uno studio sullo strumento di selezione AI per le assunzioni di Amazon [1]. Lo strumento era stato addestrato su curriculum inviati ad Amazon nell’anno precedente e classificava i diversi candidati. A causa del grande squilibrio di genere nelle posizioni tecniche degli ultimi dieci anni, l’algoritmo aveva appreso un linguaggio che associava alle donne, come le squadre sportive femminili, e declassava i curriculum in cui comparivano tali associazioni. Questo esempio sottolinea la necessità di modelli non solo equi e accurati, ma anche di dataset che rimuovano i bias durante l’addestramento. Nel contesto attuale dello sviluppo veloce di modelli generativi come ChatGPT e dell’integrazione dell’IA nella nostra vita quotidiana, un modello biased può avere conseguenze drastiche e minare la fiducia degli utenti e l’accettazione globale. Affrontare questi bias è quindi necessario da un punto di vista aziendale e i Data Scientist (in una definizione ampia) devono essere consapevoli di essi per mitigarli e assicurarsi che siano allineati ai loro principi.
Esempi di Bias nei Modelli Generativi
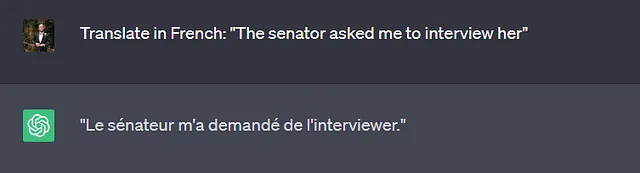
Il primo tipo di attività in cui i modelli generativi sono ampiamente utilizzati è l’attività di traduzione. Gli utenti inseriscono un testo in lingua A e si aspettano una traduzione in lingua B. Le diverse lingue non utilizzano necessariamente lo stesso tipo di pronomi di genere, ad esempio “The senator” in inglese può essere sia femminile che maschile, mentre in francese sarebbe “La senatrice” o “Le senateur”. Anche nel caso in cui il genere venga specificato nella frase (esempio sotto), non è raro che i modelli generativi rafforzino i ruoli stereotipati di genere durante la traduzione.
Similmente alle attività di traduzione, le attività di generazione di didascalie richiedono al modello di generare un nuovo testo basato su un’immagine di input, ad esempio una traduzione da un’immagine a un testo. Uno studio recente [2] ha analizzato le prestazioni di un modello generativo transformer in un’attività di generazione di didascalie (figura sotto) sul dataset Common Objects in Context.

Il modello generativo ha assegnato diverse descrizioni razziali e culturali alle didascalie, nonostante non fossero applicabili a tutte le immagini. Questi descrittori sono stati appresi solo dai modelli generativi più recenti e mostrano un aumento del bias per questi modelli. È importante notare che i modelli transformer presentano anche un bias di genere per questo dataset, esacerbando il rapporto squilibrato tra uomini e donne, ad esempio identificando una persona come donna in base allo sfondo di una casa/stanza.
- Trasformata di Fourier per le serie temporali Spiegazione della convoluzione rapida con numpy
- EDA con Polars Guida passo passo per gli utenti di Pandas (Parte 1)
- Sbloccare il successo della modellazione dei dati 3 tabelle contestuali indispensabili
Perché si verificano i Bias?
La fase di concezione di un generative model lascia ampio spazio al bias nello sviluppo di un modello. Questi bias possono derivare dai dati stessi, dalle etichette e dalle annotazioni, dalle rappresentazioni interne o addirittura dal modello (vedi https://huggingface.co/blog/ethics-soc-4 per un elenco esaustivo incentrato sui modelli Text-to-Image).
I dati necessari per l’addestramento di un modello generativo provengono da una moltitudine di fonti, di solito online. Per garantire l’integrità dei dati di addestramento, le aziende di AI utilizzano spesso noti siti di notizie e simili per costruire il loro database. I modelli addestrati su questo dataset perpetueranno associazioni biasate a causa delle restrittive demografiche considerate (di solito bianche, di mezza età, appartenenti alla classe media-alta).
La Parzialità dell’Etichetta (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3994857/) è forse la più esplicita in quanto porta all’introduzione di pregiudizi, di solito involontariamente, nei dati etichettati. I modelli generativi sono addestrati per riprodurre/approssimare il loro set di dati di addestramento, quindi un pregiudizio nelle etichette avrà un impatto drastico sulle rappresentazioni di output del modello. Fortunatamente, l’utilizzo di più versioni dell’etichetta e il controllo incrociato consentono di mitigare i pregiudizi.
Gli ultimi due tipi di pregiudizi, le rappresentazioni interne e i pregiudizi del modello, derivano entrambi da una fase specifica nella modellizzazione. Il primo è introdotto nella fase di pre-elaborazione, manuale o algoritmica. Questa fase è incline ad incorporare pregiudizi e una perdita di sfumature culturali, specialmente se l’insieme di dati originale manca di diversità. Il pregiudizio del modello deriva semplicemente da una funzione obiettivo basata su caratteristiche discriminatorie e un amplificazione dei pregiudizi per migliorare l’accuratezza del modello.
Rilevare i pregiudizi nei modelli generativi
Come evidenziato in questo articolo, i pregiudizi nei modelli generativi si manifestano in varie forme e in diverse condizioni. I metodi per rilevarli devono essere altrettanto diversi dei pregiudizi che si stanno cercando di individuare.
Una delle principali misure dei pregiudizi nei modelli linguistici consiste nel Test di Associazione dell’Integrazione delle Parole. Questo punteggio misura la similarità, all’interno di uno spazio di integrazione (rappresentazione interna), tra due insiemi di parole. Un punteggio alto indica una forte associazione. Più specificamente, calcola la differenza di similarità tra un insieme di parole di destinazione e due insiemi di input, ad esempio [casa, famiglia] come destinazione e [lui, uomo]/[lei, donna] come input. Un punteggio di 0 indicherebbe un modello perfettamente equilibrato. Questa metrica è stata utilizzata per dimostrare che RoBERTa è uno dei modelli generativi più prevenuti (https://arxiv.org/pdf/2106.13219.pdf).
Un modo innovativo per misurare i pregiudizi nei modelli generativi (valutazione controfattuale) e, più specificamente, il pregiudizio di genere, consiste nello scambiare il genere delle parole e osservare il cambiamento di accuratezza nelle previsioni. Se l’accuratezza modificata e l’accuratezza originale sono diverse, evidenzia la presenza di pregiudizi nel modello, poiché un modello generativo imparziale dovrebbe essere accurato indipendentemente dal genere degli input. La principale limitazione di questa misura è che cattura solo il pregiudizio di genere e quindi deve essere completata da altre misure per valutare completamente le fonti di pregiudizio. Su un’idea simile, si può utilizzare il Misuratore di Valutazione Bilingue (una misura classica di traduzione) per confrontare la similarità tra l’output risultante dall’input con scambio di genere e quello originale.
I modelli generativi attuali si basano su modelli di trasformatori che utilizzano una funzionalità chiamata attenzione per prevedere l’output in base all’output. Studi hanno indagato la relazione tra genere e ruoli utilizzando il punteggio di attenzione direttamente dal modello (https://arxiv.org/abs/2110.15733). Questo permette di confrontare diverse parti del modello tra loro per individuare quale modulo contribuisce maggiormente al pregiudizio. Se è stato dimostrato con questa misura che i modelli generativi introducono un pregiudizio di genere nell’insieme di dati di Wikipedia, una limitazione di questa misura è che i valori di attenzione non rappresentano un effetto diretto e una similarità tra concetti e richiedono un’analisi approfondita per trarre conclusioni.
Come superare i pregiudizi nei modelli generativi?
Sono state sviluppate varie tecniche dai ricercatori per fornire sistemi generativi meno prevenuti. Nella maggior parte dei casi, queste tecniche consistono in passaggi aggiuntivi nella modellizzazione, come impostare una variabile di controllo che fisserà il genere in base alle informazioni precedenti o aggiungere un altro modello per fornire informazioni contestuali. Tuttavia, tutti questi passaggi non affrontano necessariamente l’uso di insiemi di dati intrinsecamente prevenuti. Inoltre, la maggior parte dei modelli generativi si basa su dati di addestramento in inglese, limitando drasticamente la diversità culturale e sociale di questi modelli.
Superare completamente i pregiudizi nei modelli generativi richiederebbe l’istituzione di un quadro formale e di benchmark per testare e valutare i modelli in diverse lingue. Ciò consentirebbe la rilevazione di pregiudizi presenti in modi sfumati in diversi modelli di intelligenza artificiale.
Riferimenti
- Amazon scarta strumento di reclutamento AI segreto che mostrava pregiudizi contro le donne, Jeffrey Dastin, https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G
- Comprensione ed valutazione dei pregiudizi razziali nella didascalia delle immagini, Dora Zhao, Angelina Wang, Olga Russakovsky, https://arxiv.org/pdf/2106.08503.pdf
Seguimi su VoAGI per ulteriori contenuti su Data Science!
Se ti piace leggere storie come queste e vuoi supportarmi come scrittore, considera di iscriverti per diventare un membro di VoAGI. Costa $5 al mese e ti offre accesso illimitato a storie su VoAGI. Se ti iscrivi utilizzando il mio link, guadagnerò una piccola commissione.
Unisciti a VoAGI con il mio link di referral – Kevin Berlemont, PhD
Come membro di VoAGI, una parte della tua quota di iscrizione va agli scrittori che leggi e otterrai accesso completo a ogni storia…
VoAGI.com






