Evidenzia il testo mentre viene pronunciato utilizzando Amazon Polly
Usa Amazon Polly per evidenziare il testo durante la pronuncia.
Amazon Polly è un servizio che trasforma il testo in un discorso realistico. Consente lo sviluppo di una vasta gamma di applicazioni che possono convertire il testo in discorso in più lingue.
Questo servizio può essere utilizzato da chatbot, audiolibri e altre applicazioni di text-to-speech in combinazione con altri servizi AI o di machine learning (ML) di AWS. Ad esempio, Amazon Lex e Amazon Polly possono essere combinati per creare un chatbot che intrattiene una conversazione bidirezionale con un utente e svolge determinate attività in base ai comandi dell’utente. Amazon Transcribe, Amazon Translate e Amazon Polly possono essere combinati per trascrivere il discorso in testo nella lingua di origine, tradurlo in una lingua diversa e pronunciarlo.
In questo articolo, presentiamo un approccio interessante per evidenziare il testo mentre viene pronunciato utilizzando Amazon Polly. Questa soluzione può essere utilizzata in molte applicazioni di text-to-speech per fare quanto segue:
- Aggiungere capacità visive all’audio in libri, siti web e blog
- Aumentare la comprensione quando i clienti cercano di capire rapidamente il testo mentre viene pronunciato
La nostra soluzione offre al client (il browser, in questo esempio) la possibilità di sapere quale testo (parola o frase) viene pronunciato da Amazon Polly in ogni istante. Ciò consente al client di evidenziare dinamicamente il testo mentre viene pronunciato. Una tale capacità è utile per fornire un aiuto visivo al discorso per i casi d’uso menzionati in precedenza.
- Un Cambiamento nel Meteo IA, Calcolo Accelerato Promettono Previsioni Più Veloci ed Efficienti
- XPENG lancia la G6 Coupe SUV per il mercato di massa
- NVIDIA CEO, dirigenti europei di AI generativa discutono le chiavi del successo
La nostra soluzione può essere estesa per svolgere compiti aggiuntivi oltre all’evidenziazione del testo. Ad esempio, il browser può mostrare immagini, riprodurre musica o eseguire altre animazioni sul front-end mentre il testo viene pronunciato. Questa capacità è utile per creare audiolibri dinamici, contenuti educativi e applicazioni di text-to-speech più ricche.
Panoramica della soluzione
Alla base, la soluzione utilizza Amazon Polly per convertire una stringa di testo in discorso. Il testo può essere inserito dal browser o tramite una chiamata API all’endpoint esposto dalla nostra soluzione. Il discorso generato da Amazon Polly viene archiviato come file audio (formato MP3) in un bucket di Amazon Simple Storage Service (Amazon S3).
Tuttavia, utilizzando solo il file audio, il browser non può individuare quali parti del testo vengono pronunciate in ogni istante perché non abbiamo informazioni dettagliate su quando vengono pronunciate singole parole.
Amazon Polly fornisce un modo per ottenere ciò utilizzando i segni di discorso. I segni di discorso vengono memorizzati in un file di testo che mostra il tempo (misurato in millisecondi dall’inizio dell’audio) in cui vengono pronunciate singole parole o frasi.
Amazon Polly restituisce oggetti di segno di discorso in un flusso JSON delimitato da righe. Un oggetto di segno di discorso contiene i seguenti campi:
- Time – Il timestamp in millisecondi dall’inizio del flusso audio corrispondente
- Type – Il tipo di segno di discorso (frase, parola, visema o SSML)
- Start – L’offset in byte (non caratteri) dell’inizio dell’oggetto nel testo di input (senza includere i segni di visema)
- End – L’offset in byte (non caratteri) della fine dell’oggetto nel testo di input (senza includere i segni di visema)
- Value – Questo varia a seconda del tipo di segno di discorso:
- SSML – Tag SSML <mark>
- Visema – Il nome del visema
- Parola o frase – Una sottostringa del testo di input delimitata dai campi di inizio e fine
Ad esempio, la frase “Mary had a little lamb” può fornire il seguente file di segni di discorso se si utilizza SpeechMarkTypes = [“word”, “sentence”] nella chiamata API per ottenere i segni di discorso:
{"time":0,"type":"sentence","start":0,"end":23,"value":"Mary aveva un piccolo agnello."}
{"time":6,"type":"word","start":0,"end":4,"value":"Mary"}
{"time":373,"type":"word","start":5,"end":8,"value":"aveva"}
{"time":604,"type":"word","start":9,"end":10,"value":"un"}
{"time":643,"type":"word","start":11,"end":17,"value":"piccolo"}
{"time":882,"type":"word","start":18, "end":22,"value":"agnello"}La parola “aveva” (alla fine della riga 3) inizia 373 millisecondi dopo l’inizio del flusso audio, inizia al byte 5 e termina al byte 8 del testo di input.
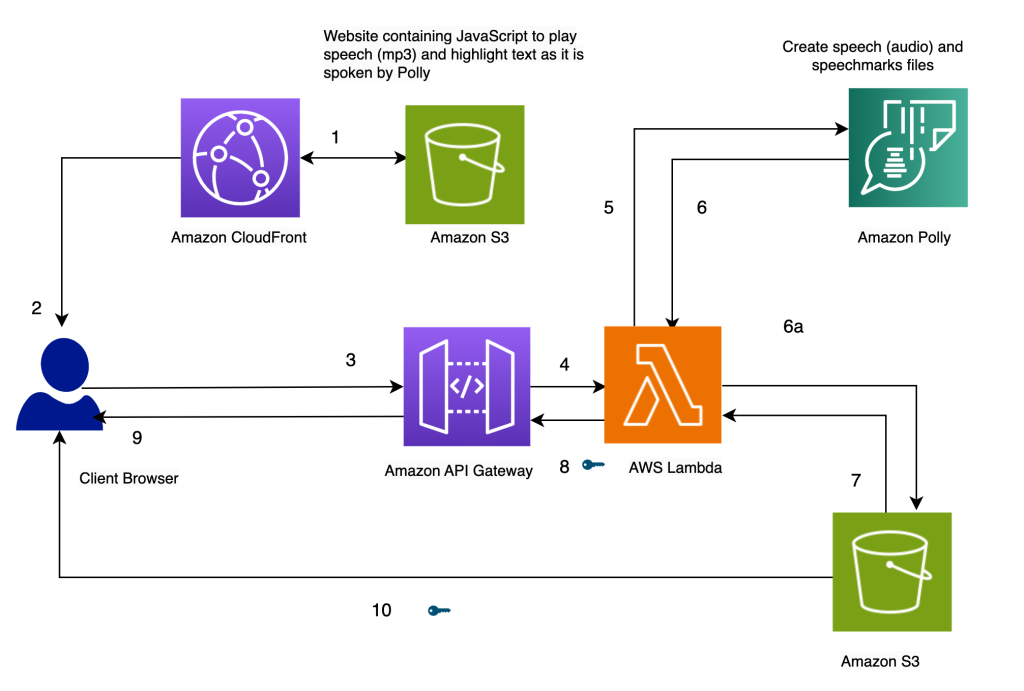
Panoramica dell’architettura
L’architettura della nostra soluzione è presentata nel seguente diagramma.
Evidenzia il testo mentre viene pronunciato, utilizzando Amazon Polly
Il nostro sito web per la soluzione è memorizzato su Amazon S3 come file statici (JavaScript, HTML), che sono ospitati su Amazon CloudFront (1) e serviti al browser dell’utente finale (2).
Quando l’utente inserisce del testo nel browser tramite un semplice modulo HTML, viene elaborato da JavaScript nel browser. Questo chiama un’API (3) tramite Amazon API Gateway, per invocare una funzione AWS Lambda (4). La funzione Lambda chiama Amazon Polly (5) per generare file audio e file di segni di pronuncia (JSON). Vengono effettuate due chiamate a Amazon Polly per recuperare i file audio e di segni di pronuncia. Le chiamate vengono effettuate utilizzando funzioni asincrone JavaScript. L’output di queste chiamate sono i file audio e di segni di pronuncia, che vengono memorizzati su Amazon S3 (6a). Per evitare che più utenti sovrascrivano i file degli altri nel bucket S3, i file vengono memorizzati in una cartella con un timestamp. Questo riduce al minimo le possibilità che due utenti sovrascrivano i file degli altri su Amazon S3. Per un rilascio di produzione, possiamo utilizzare approcci più robusti per segregare i file degli utenti in base all’ID utente o al timestamp e ad altre caratteristiche uniche.
La funzione Lambda crea URL prefirmati per i file audio e di segni di pronuncia e li restituisce al browser sotto forma di un array (7, 8, 9).
Quando il browser invia il file di testo al punto di accesso dell’API (3), riceve due URL prefirmati per il file audio e il file di segni di pronuncia in una singola invocazione sincrona (9). Questo è indicato dal simbolo chiave accanto alla freccia.
Una funzione JavaScript nel browser recupera il file di segni di pronuncia e l’audio dai loro URL (10). Configura il lettore audio per riprodurre l’audio. (A questo scopo viene utilizzata l’etichetta audio HTML).
Quando l’utente fa clic sul pulsante di riproduzione, analizza i segni di pronuncia recuperati nel passaggio precedente per creare una serie di eventi temporizzati utilizzando i timeout. Gli eventi richiamano una funzione di callback, che è un’altra funzione JavaScript utilizzata per evidenziare il testo pronunciato nel browser. Allo stesso tempo, la funzione JavaScript trasmette il file audio dal suo URL.
Il risultato è che gli eventi vengono eseguiti nei tempi appropriati per evidenziare il testo mentre viene pronunciato mentre l’audio viene riprodotto. L’uso dei timeout di JavaScript ci fornisce la sincronizzazione dell’audio con il testo evidenziato.
Prerequisiti
Per eseguire questa soluzione, è necessario un account AWS con un utente di AWS Identity and Access Management (IAM) che abbia l’autorizzazione per utilizzare Amazon CloudFront, Amazon API Gateway, Amazon Polly, Amazon S3, AWS Lambda e AWS Step Functions.
Utilizzare Lambda per generare audio e segni di pronuncia
Il seguente codice invoca la funzione synthesize_speech di Amazon Polly due volte per recuperare il file audio e di segni di pronuncia. Vengono eseguiti come funzioni asincrone e coordinati per restituire il risultato contemporaneamente utilizzando le promesse.
const p1 = new Promise(doSynthesizeSpeechMarks);
const p2 = new Promise(doSynthesizeSpeech);
var result;
await Promise.all([p1, p2])
.then((values) => {
//ritorna un array di URL prefirmati
console.log('Valori:', values);
result = { "output" : values };
})
.catch((err) => {
console.log("Errore:" + err);
result = err;
});Da parte di JavaScript, l’evidenziazione del testo viene eseguita da highlighter(start, finish, word) e gli eventi temporizzati vengono impostati da setTimers() :
function highlighter(start, finish, word) {
let textarea = document.getElementById("postText");
//console.log(start + "," + finish + "," + word);
textarea.focus();
textarea.setSelectionRange(start, finish);
}
function setTimers() {
let speechMarksStr = sessionStorage.getItem("speech marks");
//leggi il file di segni di pronuncia e imposta i timer per ogni parola
console.log(speechMarksStr);
let speechMarks = speechMarksStr.split("\n");
for (let i = 0; i < speechMarks.length; i++) {
//console.log(i + ":" + speechMarks[i]);
if (speechMarks[i].length == 0) {
continue;
}
smjson = JSON.parse(speechMarks[i]);
t = smjson["time"];
s = smjson["start"];
f = smjson["end"];
word = smjson["value"];
setTimeout(highlighter, t, s, f, word);
}
}Approcci alternativi
Al posto dell’approccio precedente, è possibile considerare alcune alternative:
- Creare sia le virgolette di discorso che i file audio all’interno di una macchina a stati Step Functions. La macchina a stati può invocare la condizione del ramo parallelo per invocare due diverse funzioni Lambda: una per generare il discorso e un’altra per generare le virgolette di discorso. Il codice per questo può essere trovato nella sottocartella “using-step-functions” nel repository di Github.
- Invocare Amazon Polly in modo asincrono per generare l’audio e le virgolette di discorso. Questo approccio può essere utilizzato se il contenuto del testo è grande o l’utente non ha bisogno di una risposta in tempo reale. Per ulteriori dettagli sulla creazione di file audio lunghi, fare riferimento alla creazione di file audio lunghi.
- Fare in modo che Amazon Polly crei direttamente l’URL prefirmato utilizzando la chiamata “generate_presigned_url” sul client di Amazon Polly in Boto3. Se si sceglie questo approccio, Amazon Polly genera l’audio e le virgolette di discorso nuovamente ogni volta. Nel nostro approccio attuale, archiviamo questi file in Amazon S3. Anche se questi file archiviati non sono accessibili dal browser nella nostra versione del codice, è possibile modificare il codice per riprodurre i file audio precedentemente generati recuperandoli da Amazon S3 (invece di rigenerare l’audio per il testo utilizzando nuovamente Amazon Polly). Abbiamo ulteriori esempi di codice per accedere a Amazon Polly con Python nella AWS Code Library.
Crea la soluzione
L’intera soluzione è disponibile nel nostro repository di Github. Per creare questa soluzione nel tuo account, segui le istruzioni nel file README.md. La soluzione include un modello AWS CloudFormation per il provisioning delle risorse.
Pulizia
Per eliminare le risorse create in questa demo, eseguire i seguenti passaggi:
- Eliminare i bucket S3 creati per archiviare il modello CloudFormation (Bucket A), il codice sorgente (Bucket B) e il sito web (
pth-cf-text-highlighter-website-[Suffisso]). - Eliminare lo stack CloudFormation
pth-cf. - Eliminare il bucket S3 contenente i file audio (
pth-speech-[Suffisso]). Questo bucket è stato creato dal modello CloudFormation per archiviare i file audio e le virgolette di discorso generati da Amazon Polly.
Riassunto
In questo articolo, abbiamo mostrato un esempio di una soluzione che può evidenziare il testo mentre viene pronunciato utilizzando Amazon Polly. È stata sviluppata utilizzando la funzionalità di virgolette di discorso di Amazon Polly, che fornisce marcatori per il punto in cui ogni parola o frase inizia in un file audio.
La soluzione è disponibile come modello CloudFormation. Può essere implementata così com’è in qualsiasi applicazione web che esegue la conversione del testo in voce. Ciò sarebbe utile per aggiungere capacità visive all’audio nei libri, avatar con capacità di sincronizzazione labiale (utilizzando le virgolette di discorso dei visemi), siti web e blog e per aiutare le persone con problemi uditivi.
È possibile estenderla per eseguire attività aggiuntive oltre all’evidenziazione del testo. Ad esempio, il browser può mostrare immagini, riprodurre musica e eseguire altre animazioni sul front end mentre il testo viene pronunciato. Questa capacità può essere utile per creare audiolibri dinamici, contenuti educativi e applicazioni di conversione del testo in voce più ricche.
Vi invitiamo a provare questa soluzione e a saperne di più sui servizi AWS pertinenti ai seguenti link. È possibile estendere la funzionalità per le proprie esigenze specifiche.
- Amazon API Gateway
- Amazon CloudFront
- AWS Lambda
- Amazon Polly
- Amazon S3






