Esaminare i voli negli Stati Uniti con AWS e Power BI
'Analizzare voli negli USA con AWS e Power BI'
Quali informazioni possiamo ottenere utilizzando ETL e BI?
Indice
∘ Introduzione ∘ Problema ∘ Dati ∘ Architettura AWS ∘ Archiviazione dati con AWS S3 ∘ Progettazione dello schema ∘ ETL con AWS Glue ∘ Data warehousing con AWS Redshift ∘ Estrazione di informazioni con AWS Redshift ∘ Visualizzazione dei dati con Power BI ∘ Prossimi passi ∘ Conclusioni ∘ Riferimenti
Introduzione
Il viaggio aereo è diventato una parte integrante delle nostre vite. È un mezzo per le imprese per creare connessioni e condurre commercio e per le famiglie per visitare i propri cari o viaggiare.
Nonostante la sua influenza, l’industria dell’aviazione è nota per affrontare turbolenze. È soggetta a continui cambiamenti dovuti a fattori esterni come periodi di crisi e di boom economico, cambiamenti climatici, la pandemia di Covid-19 e la spinta a fare maggiormente affidamento su fonti di energia rinnovabile.
Per essere consapevoli di tali cambiamenti e del loro impatto sui viaggi aerei, vale la pena monitorare questi voli nel tempo. Un tale sforzo richiede una strategia robusta per l’archiviazione dei dati, l’analisi dei dati e la visualizzazione dei dati.
- Comprensione del codice sul proprio hardware
- Come automatizzare l’estrazione di entità da un PDF utilizzando LLMs
- Costruzione di applicazioni alimentate da LLM con LangChain
Problema
Questo progetto ha 2 obiettivi principali. Il primo è utilizzare le risorse fornite da Amazon Web Services (AWS) per costruire un flusso di dati che faciliti l’archiviazione, la trasformazione e l’analisi dei dati sui voli negli Stati Uniti.
Il secondo obiettivo è costruire uno strumento di visualizzazione con Power BI che possa illustrare efficacemente le principali scoperte provenienti dai dati.
Dati
Il dataset utilizzato per questo progetto è ottenuto dal Bureau of Transportation Statistics. Riporta principalmente il numero totale di voli, ritardi e cancellazioni negli aeroporti e nelle compagnie aeree dal 2003 al 2023.
Ecco una anteprima del dataset:

A prima vista, ci sono alcuni problemi con il dataset grezzo.
Innanzitutto, le informazioni nel campo airport_name comprendono più informazioni. Non presenta solo il nome dell’aeroporto, ma anche la città e lo stato. Per accedere facilmente a queste informazioni, questo campo dovrà essere diviso in 3 campi separati.
In secondo luogo, questi dati attualmente adottano un modello piatto (cioè 1 tabella). Tuttavia, questa non è la configurazione ottimale poiché i dati contengono più entità con relazioni.
Questi problemi dovranno essere affrontati prima che i dati possano essere utilizzati per l’analisi o la visualizzazione.
Architettura AWS
Discutiamo dell’architettura AWS necessaria per costruire il flusso di dati.
Le risorse richieste sono meglio illustrate con il seguente diagramma:

La soluzione cloud utilizza Amazon S3 per archiviare i dati grezzi e i dati trasformati, AWS Glue per creare un lavoro di ETL che facilita la trasformazione dei dati e AWS Redshift per creare il data warehouse cloud che consente agli utenti di estrarre informazioni dai dati con SQL.
Infine, Power BI viene utilizzato per visualizzare le principali metriche fornite dai dati sotto forma di dashboard.
Archiviazione dati con AWS S3
Il progetto utilizza due bucket S3: flights-data-raw e flights-data-processed.

Il bucket flights-data-raw contiene il dataset raw.

Il bucket flights-data-processed conterrà i dati dopo essere stati trasformati (al momento è vuoto).
Progettazione dello schema
Successivamente, è importante determinare uno schema adatto per questi dati. I dati grezzi sono archiviati in un file piatto, che contiene una singola tabella:
Purtroppo, questo schema ha solo una singola tabella, che comprende più entità, come data, aeroporto e vettore. Per ottimizzare il database per il recupero più rapido dei dati, questo schema piatto può essere convertito in uno schema a stella con l’uso di modellazione dimensionale:
In questo nuovo schema, la tabella flights serve come tabella dei fatti, mentre le tabelle date, carrier e airport fungono da tabelle delle dimensioni.
ETL con AWS Glue
Un lavoro ETL creato con AWS Glue può trasformare i dati grezzi nelle tabelle dei fatti e delle dimensioni e caricarli nel bucket flights-data-processed.
Il lavoro ETL utilizza uno script Python importato per eseguire la modellazione dimensionale.
Lo script utilizza boto3, l’SDK di Python, per estrarre il dataset grezzo dal bucket flights-data-raw, creare le 4 tabelle nello schema a stella e caricarle nel bucket flights-data-processed come file CSV.
Ad esempio, il seguente snippet viene utilizzato per creare la tabella carrier.
L’intero script utilizzato per creare le 4 tabelle nello schema può essere consultato nel repository GitHub .
Il lavoro ETL viene eseguito senza problemi:

Il dataset è stato convertito in una tabella dei fatti e 3 tabelle delle dimensioni sotto forma di file CSV, che sono tutti archiviati nel bucket flights-data-processed.

Data Warehousing con AWS Redshift
Con AWS Glue, i dati che erano inizialmente in un modello piatto possono ora essere rappresentati con uno schema a stella più appropriato in un data warehouse.
Il data warehouse cloud per questi dati verrà creato con AWS Redshift Serverless. Ciò comporta la creazione di uno spazio dei nomi chiamato flights-namespace e un database chiamato dev. Inoltre, richiede un gruppo di lavoro chiamato flights-workgroup, che verrà utilizzato per scrivere query SQL.
Nota: Il workgroup è stato configurato per consentire ai dispositivi al di fuori della VPC di accedere al database. Questo sarà utile durante la creazione della visualizzazione con Power BI

Ora possiamo aprire l’editor di query in Redshift e iniziare a creare le tabelle di fatto e di dimensione nel database dev.
Prima, le 4 tabelle nello schema devono essere create nel data warehouse utilizzando i seguenti comandi:
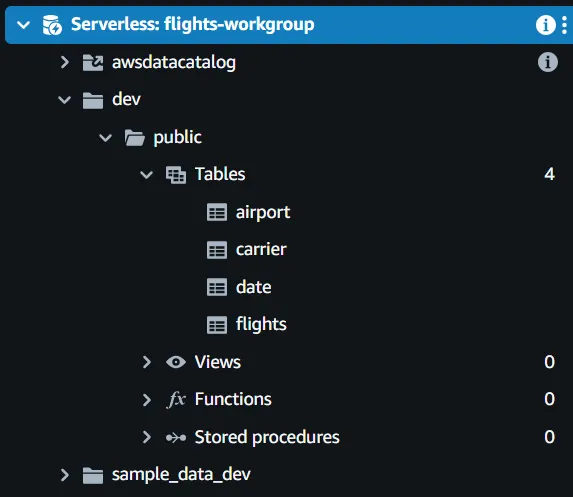
Le quattro tabelle sono ora nel data warehouse, ma sono tutte vuote poiché i dati sono ancora nel bucket flights-data-processed.
I dati possono essere copiati in questo data warehouse utilizzando il comando COPY.
Ad esempio, i dati in flights.csv possono essere copiati nella tabella flights utilizzando la seguente sintassi del comando:
Nota: la variabile
iam_roledovrebbe essere assegnata al ruolo iam selezionato durante la creazione del workgroup.
Eseguendo il comando COPY per ciascuno dei file csv nel bucket flights-data-processed, le 4 tabelle dovrebbero essere riempite con i dati necessari.
A titolo di esempio, ecco una anteprima della tabella dell’aeroporto:

Estrazione di Insight con AWS Redshift
Ora che tutte le tabelle sono caricate con i dati, possiamo effettuare analisi con le query SQL!
Dato che i dati sono stati precedentemente trasformati in uno schema a stella con modellazione dimensionale, è facile recuperare i dati in modo efficiente con un breve tempo di esecuzione, rendendo questa configurazione ideale per analisi ad hoc.
Ecco alcuni esempi di domande che possono essere risposte con le query SQL.
- Quali aeroporti hanno avuto il maggior numero di voli nel 2022?

2. Quale tipo di ritardo ha contribuito maggiormente al ritardo totale a partire dal 2019?
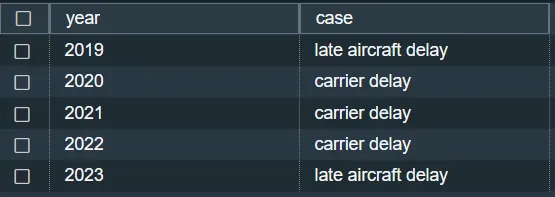
3. All’aeroporto John F. Kennedy, qual è la variazione percentuale dei ritardi per ogni anno?
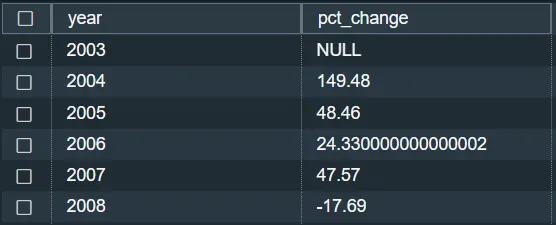
Visualizzazione dei dati con Power BI
Il data warehouse cloud attuale consente agli utenti di rispondere a domande chiave con poco tempo e costi.
Tuttavia, possiamo fare un passo avanti creando una visualizzazione che gli utenti finali possono utilizzare per rispondere a domande simili.
Un modo per ottenere questo è creare un cruscotto con Power BI, un popolare strumento di business intelligence.
Sebbene ci siano molte metriche che possono essere scoperte attraverso le visualizzazioni, il cruscotto si concentrerà nell’esaminare quanto segue:
- un riepilogo del numero di voli, ritardi e cancellazioni
- il tracciamento del numero di voli, ritardi e cancellazioni nel tempo
- l’identificazione degli aeroporti e dei vettori più utilizzati
- una suddivisione dei diversi tipi di ritardi
Inoltre, il cruscotto includerà filtri che consentiranno agli utenti di selezionare tempi e luoghi specifici.
Nel complesso, queste funzionalità possono essere combinate nella forma del seguente cruscotto:

Utilizzando uno strumento del genere, gli utenti senza accesso ai dati o senza conoscenza di SQL possono rispondere a domande chiave con poco sforzo.
Tali domande possono includere:
- Quale vettore effettua il maggior numero di voli nell’aeroporto JFK?

2. Quanti voli sono stati cancellati in California dal 2019 al 2022?

3. Quale tipo di ritardo contribuisce maggiormente al ritardo complessivo nella American Airlines?

Prossimi Passi

L’attuale configurazione in AWS e Power BI promuove un’analisi e una visualizzazione rapida ed economica dei dati. Tuttavia, vale la pena considerare nuove applicazioni per i dati in futuro.
- Incorporazione di nuove fonti di dati
Se si desidera includere nuove fonti di dati, lo schema dovrà essere modificato di conseguenza. Inoltre, sarà necessario creare ulteriori lavori ETL per integrare senza soluzione di continuità i dati provenienti da queste fonti nel data warehouse esistente.
2. Eseguire l’analisi delle serie temporali
I dati forniti da BTS sono una serie temporale. Pertanto, vale la pena considerare l’utilizzo dell’analisi delle serie temporali e la creazione di modelli di previsione per prevedere la domanda di viaggi aerei in futuro.
Conclusione
I dataset con numerosi record, come quello fornito da BTS, possono essere difficili da gestire. Tuttavia, con le risorse fornite da AWS, è possibile creare un flusso di dati che elabora i dati e li struttura in una forma che consente agli utenti di estrarre informazioni in modo conveniente.
Inoltre, le visualizzazioni come il dashboard Power BI creato sono un metodo efficace per contestualizzare determinate metriche e creare una storia di impatto per il pubblico.
Per il codice utilizzato per creare il lavoro ETL in AWS Glue o le query SQL utilizzate per creare le tabelle e svolgere l’analisi, visitare il repository GitHub:
GitHub – anair123/Tracking-U.S.-Flights-With-AWS-and-Power-BI
Contribuisci allo sviluppo di anair123/Tracking-U.S.-Flights-With-AWS-and-Power-BI creando un account su GitHub.
github.com
Grazie per la lettura!
Riferimenti
- Statistiche sulle compagnie aeree puntuali e cause dei ritardi. BTS. (s.d.). https://www.transtats.bts.gov/ot_delay/OT_DelayCause1.asp?20=E



