R Toolkit per l’analisi delle persone Raccontare la storia dei dipendenti
'R Toolkit per l'analisi delle persone' significa che c'è uno strumento chiamato R Toolkit che è utilizzato per analizzare le persone. Il testo successivo, 'Raccontare la storia dei dipendenti', suggerisce che questo strumento viene utilizzato per analizzare e raccontare la storia dei dipendenti.
Sfide comuni nell’analisi delle persone risolte usando R
Lavorando nell’analisi delle persone, spesso ti viene chiesto di raccontare la storia dell’organico della tua azienda e come l’azienda si è evoluta fino a diventare quello che è oggi. Spesso vedo questo presentato come un grafico a cascata , che può essere ottimo, ma diventa confuso quando si cerca di condividere i cambiamenti anno dopo anno e a un pubblico meno tecnico.
Per affrontare questa esigenza, ho creato dei grafici iterativi evidenziando ogni anno con alcuni contesti aggiuntivi. I grafici possono quindi essere aggiunti a una presentazione PowerPoint per passare attraverso ogni anno uno alla volta, o possono essere animati insieme in un gif. Facciamolo insieme!
Sfida: Raccontare la storia di come il nostro organico è cambiato anno dopo anno fino a diventare quello che è oggi.
Passaggi: 1. Carica i pacchetti e i dati necessari 2. Calcola l’organico mensile 3. Aggiungi contesto rilevante per ogni anno 4. Crea un grafico 5. Prepara l’automazione per creare automaticamente un grafico per ogni anno 6. Regola il tema e la formattazione del grafico
- Come creare un piano di studio di Data Science di un anno utilizzando la stagionalità del tuo cervello
- Analisi esplorativa dei dati Svelare la storia all’interno del tuo dataset
- Padronanza della segmentazione dei clienti utilizzando i dati delle transazioni con carta di credito
1. Carica i pacchetti e i dati necessari
Per questa sfida, avremo bisogno dei seguenti pacchetti: – tidyverse – hrbrthemes (per rendere i nostri grafici più belli)
Per creare la nostra visualizzazione, avremo bisogno di un file che contenga un identificatore univoco (ad esempio, ID dipendente), la data di assunzione e la data di cessazione. Userò dati di esempio per questo esempio (in fondo ho incluso il codice utilizzato per creare i dati di esempio se vuoi seguirlo passo dopo passo).
# carica i pacchettilibrary(tidyverse)library(hrbrthemes)# carica i datiemployee_data <- mock_data # alternativamente potresti utilizzare qualcosa come employee_data <- read.csv("input.csv")Come nota laterale, generalmente assegno una variabile alla mia lettura originale dei dati e poi creo una nuova variabile che uso per le future manipolazioni. Questo non è sempre necessario, ma rende tutto più veloce quando si lavora con un grande set di dati in modo da non dover ricaricare i dati ogni volta che è necessario modificare il codice.
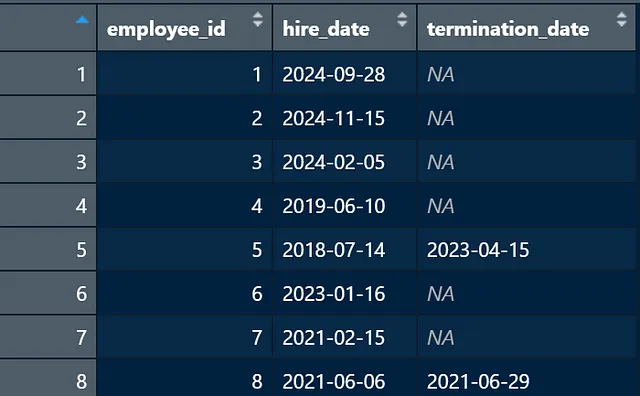
Per i calcoli funzionino correttamente, dobbiamo assicurarci che R sappia che la data di assunzione e la data di cessazione sono effettivamente date. In generale, lavorare con le date in R può essere un vero problema, ma per il fine di questa sfida, dobbiamo formattare le colonne delle date come date e assicurarci che non ci siano NA.
df <- employee_data %>% mutate(Hire.Date = as.Date(Hire.Date, format = "%m/%d/%Y"), Termination.Date = as.Date(Termination.Date, format = "%m/%d/%Y"))Nel mio file di input, i dipendenti ancora attivi hanno un campo vuoto per la data di cessazione, perché ovviamente non sono ancora terminati. R si agiterà in tutti i modi se abbiamo campi vuoti in una colonna di date, quindi aggiungeremo una riga di codice che assegna una data molto lontana nel futuro.
df <- employee_data %>% mutate(Hire.Date = as.Date(Hire.Date, format = "%m/%d/%Y"), Termination.Date = as.Date(Termination.Date, format = "%m/%d/%Y")) %>% mutate(Termination.Date = if_else(is.na(Termination.Date), as.Date("2100-12-31"), Termination.Date))L’ultima riga dice che ovunque ci sia un NA/vuoto nella colonna della data di cessazione, assegna una data molto lontana nel futuro. In questo caso, il 31 dicembre 2100. Speriamo tutti che non stia ancora lavorando a quel tempo.
2. Calcola il numero di dipendenti mensili
Speriamo che questa fase sembri semplice, ma ho avuto un po’ di difficoltà a capirla, quindi per favore sii paziente con te stesso.
Prima creeremo una sequenza che avrà una data per ogni mese, poi configureremo un data frame come segnaposto per il nostro numero di dipendenti mensili e infine utilizzeremo una funzione sapply per calcolare il numero di dipendenti per ogni mese. Ecco fatto!
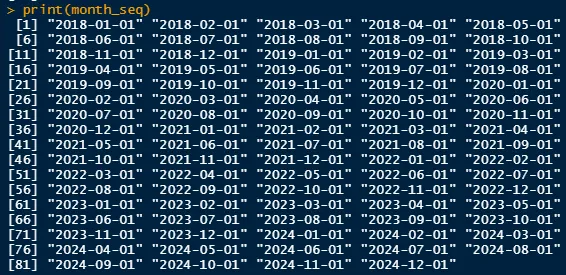
Crea una sequenza per una data per ogni mese (ad esempio, 1/1/2023, 1/2/2023, ecc.):
month_seq <- seq(from = min(df$hire_date),
to = max(df$hire_date),
by = "1 month")Ciò significa iniziare dalla data di assunzione minima, arrivare alla data di assunzione massima e sequenziare per mese. Questo ci lascia con un valore per ogni mese nei nostri dati. Ecco come appare:
Ora utilizzeremo quella sequenza per creare un data frame iniziale che possiamo poi aggiornare con il numero di dipendenti.
headcount_data <- data.frame(Date = month_seq)Ora, passiamo alla parte complicata. Calcoleremo il conteggio dei dipendenti attivi per ogni data nel nostro data frame headcount_data. Quanti dipendenti sono attivi il 1/1/2018, 2/2/2018, ecc.
Diciamo che vogliamo calcolare per il 1/1/2018. Dobbiamo trovare il numero di dipendenti che hanno una data di assunzione inferiore o uguale al 1/1/2018 e una data di terminazione successiva al 1/1/2018. In altre parole, il numero di dipendenti che sono già stati assunti e non sono ancora terminati.
Quindi usiamo semplicemente sapply per farlo per ogni data in headcount_data.
headcount_data <- headcount_data %>% mutate(Dipendenti.Attivi = sapply(Date, function(x) { sum(x >= df$hire_date & (is.na(df$termination_date) | x < df$termination_date)) })) Sei ancora con me? Se sei riuscito a far funzionare tutto fino a questo punto, fatti una grande pacca sulla spalla! Se stai incontrando un problema, fatti comunque una grande pacca sulla spalla per essere arrivato fin qui e vai al codice completo qui per vedere se riesci a individuare eventuali incongruenze nel tuo codice.
3. Aggiungi contesto rilevante
Qui entra in gioco la parte della narrazione. A seconda della tua esperienza o familiarità con l’organizzazione, potresti dover intervistare alcuni esperti in materia o dipendenti con una lunga anzianità. Fondamentalmente, stai cercando di aggiungere un contesto importante che aiuti a spiegare eventuali aumenti o diminuzioni del numero di dipendenti.
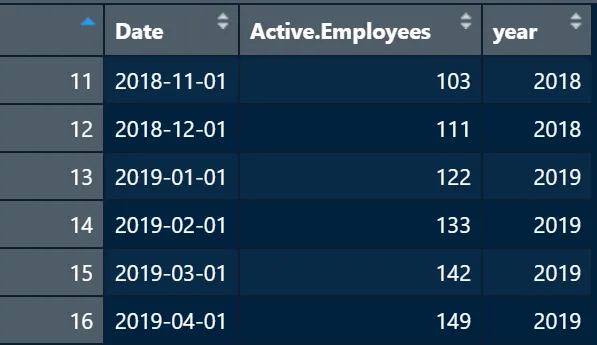
Voglio aggiungere del contesto per ogni anno (potresti farlo anche a livello mensile), quindi aggiungerò una colonna per l’anno a headcount_data.
headcount_data <- headcount_data %>% mutate(anno = as.integer(year(Date)))Questo aggiunge una colonna con l’anno per ogni data:
Ora, aggiungeremo del contesto per ogni anno. Diciamo che per il 2020 vogliamo aggiungere il contesto “COVID-19” e vogliamo che venga mostrato per ogni mese del 2020.
Per fare ciò, useremo case_when per aggiungere una colonna “contesto” in base all’anno.
headcount_data <- headcount_data %>% mutate(contesto = case_when( anno == 2018 ~ "Contesto per il 2018", anno == 2019 ~ "Contesto per il 2019", anno == 2020 ~ "COVID-19", TRUE ~ "Nessun contesto aggiuntivo"))Nel caso sopra, stiamo dicendo che per ogni riga in cui l’anno è 2018, vogliamo che la colonna del contesto sia “Contesto per il 2018”. Puoi aggiungere il contesto per ogni anno di interesse, e poi nella clausola TRUE, puoi specificare quale contesto vuoi per tutti gli anni non specificati sopra.
A questo punto, il tuo headcount_data dovrebbe apparire così:
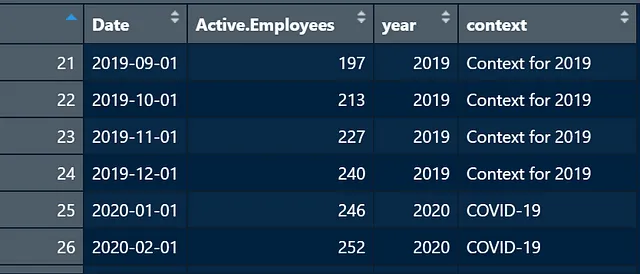
Ora arriva la parte divertente! Iniziamo a creare i grafici.
4. Crea il grafico
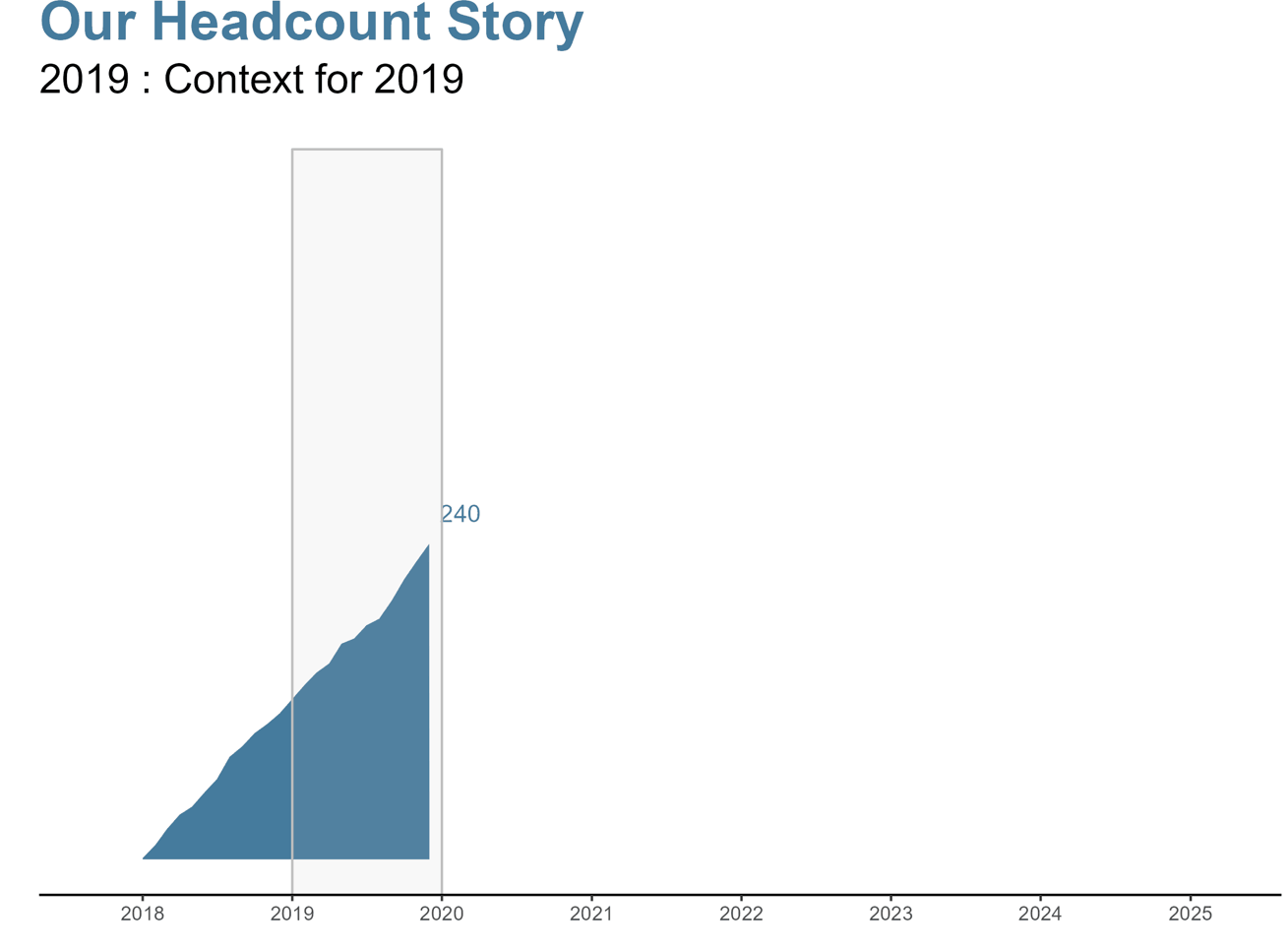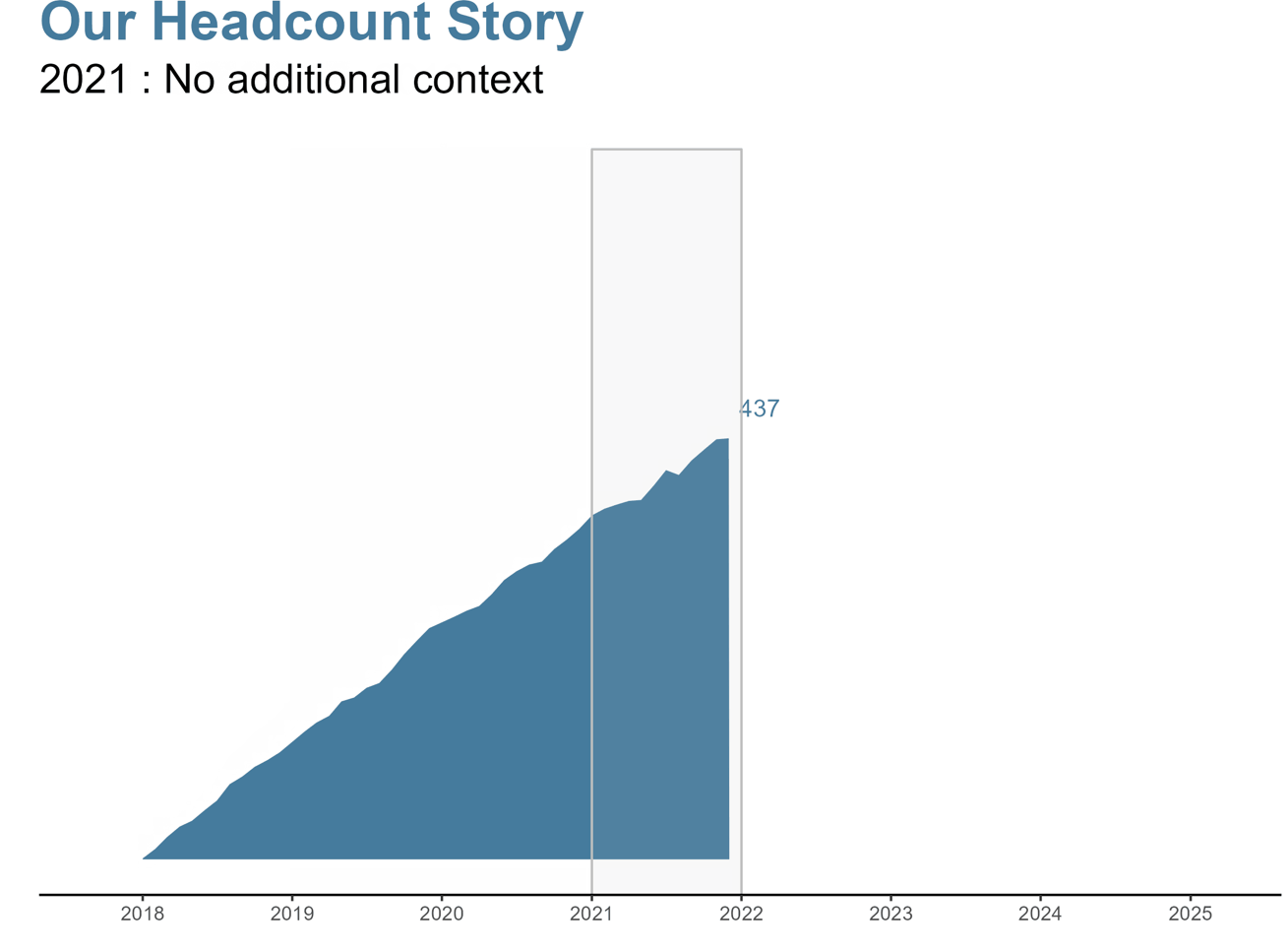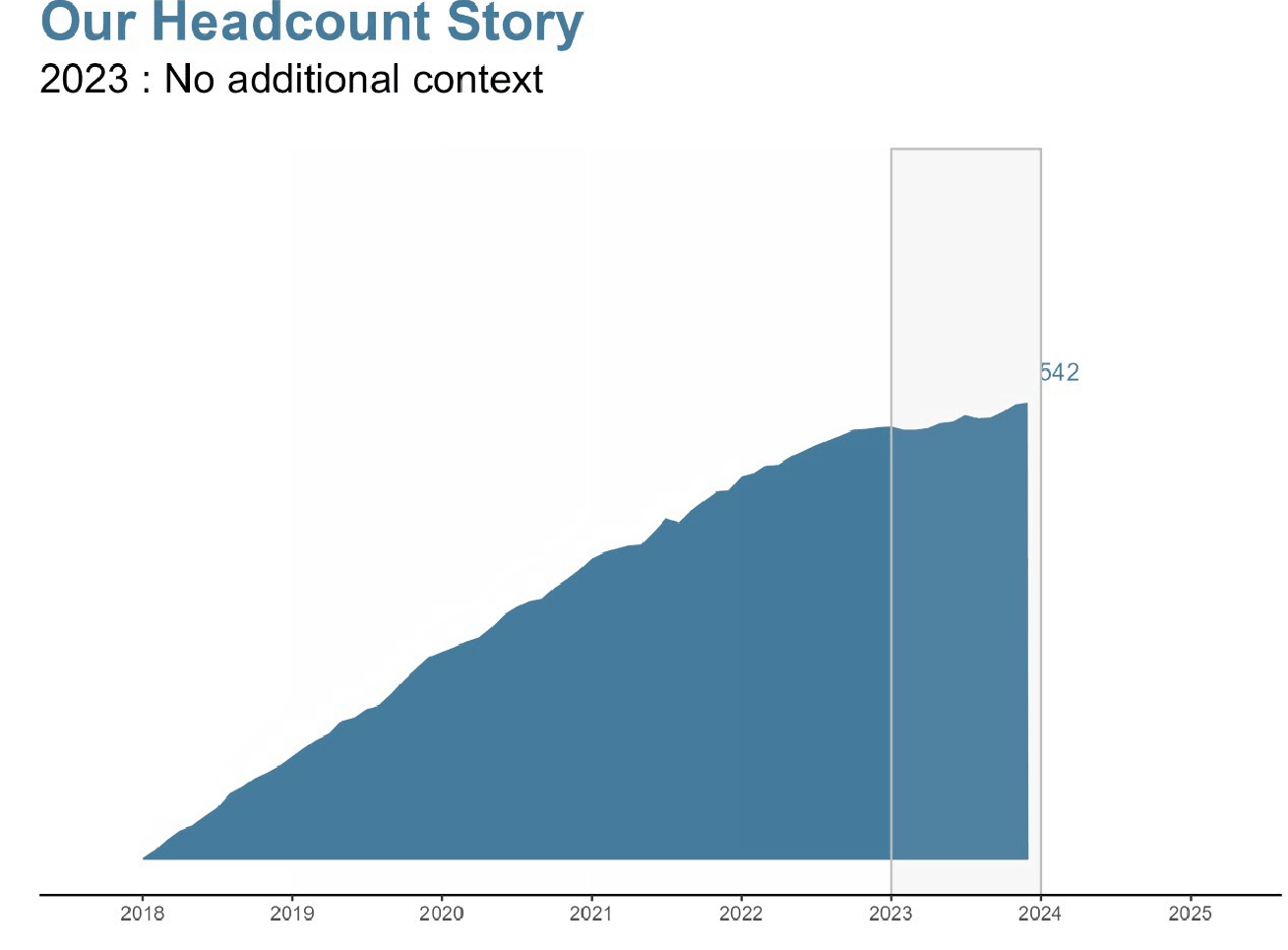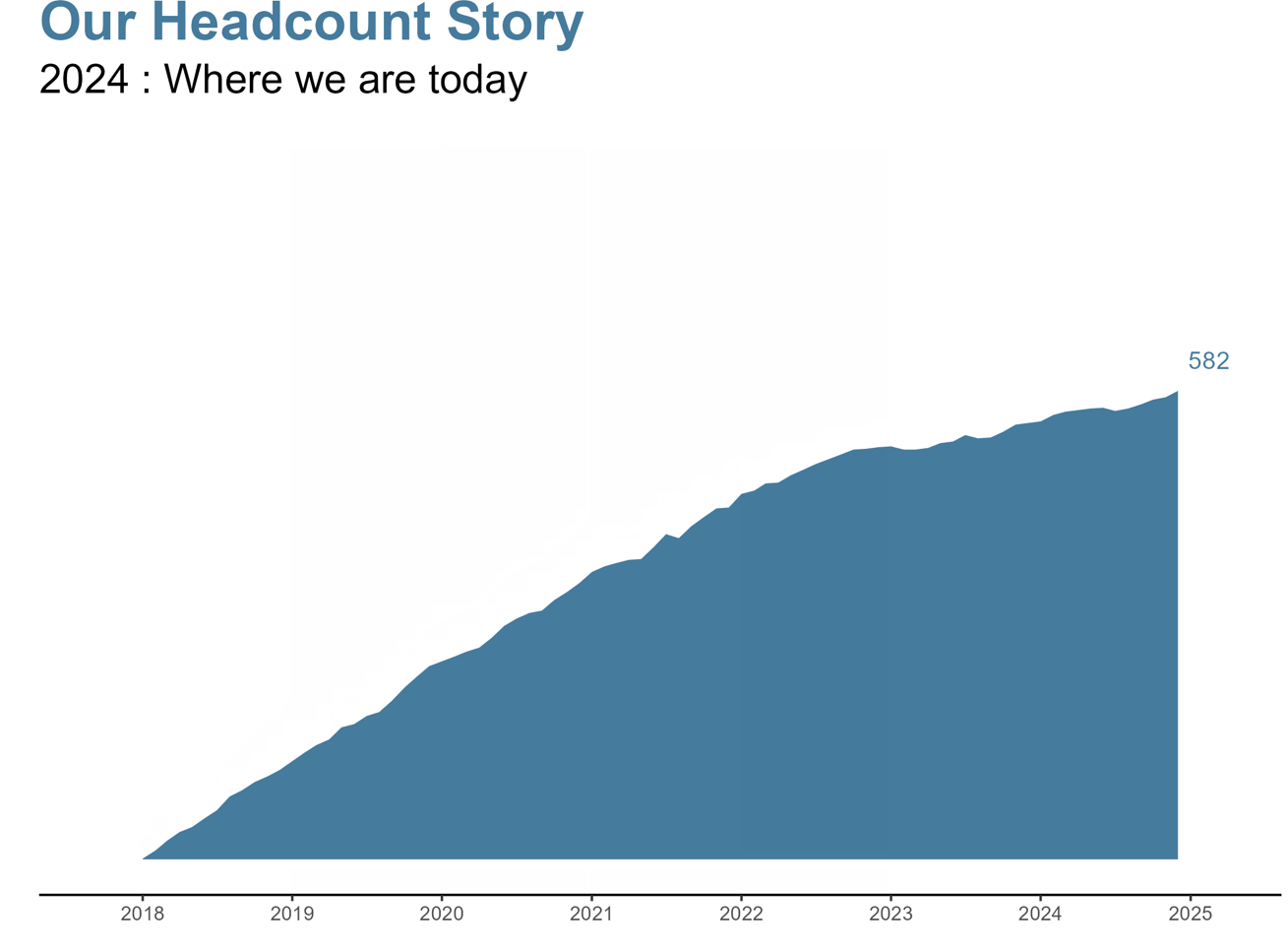
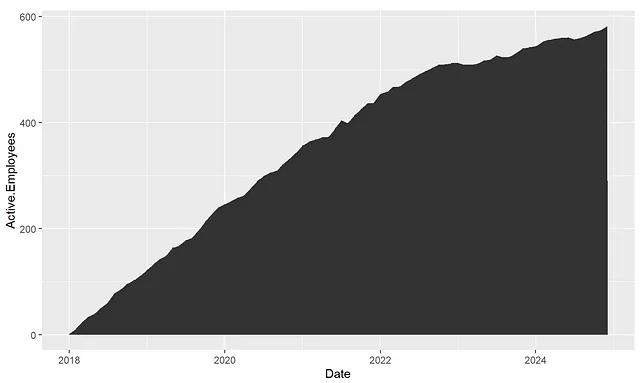
Per cominciare, creeremo un grafico ad area di base con tutti i nostri dati utilizzando ggplot. Avremo la data sull’asse x e gli Active.Employees sull’asse y in modo da poter vedere il nostro headcount nel tempo.
headcount_data %>% ggplot(aes(x = Date, y = Active.Employees)) + geom_area()Questo ti darà questo grafico di base:
Ora iniziamo il processo di qualche zhushing di base prima di passare a qualche zhushing più avanzato: 1. Aggiungi annotazioni 2. Aggiungi titolo e sottotitolo
Aggiungeremo delle annotazioni con il conteggio finale e l’anno (questo diventerà più rilevante quando creeremo un grafico per ogni anno). Iniziamo assegnandoli a delle variabili per renderlo più facile da aggiornare per ogni anno:
# annotazioniannotation_ending_year <- max(headcount_data$year)annotation_ending_headcount <- max(headcount_data$Active.Employees)# titololabels_title <- "La nostra storia di headcount"labels_subtitle <- last(headcount_data$context)Ora andremo ad aggiungerli al nostro grafico di base:
headcount_data %>% ggplot(aes(x = Date, y = Active.Employees)) + geom_area() + labs(title = labels_title, subtitle = labels_subtitle) + annotate("text", x = max(headcount_data$Date), y = max(headcount_data$Active.Employees), label = annotation_ending_headcount, hjust = -.25)Questo ci darà il nostro grafico di base con un contesto aggiuntivo:
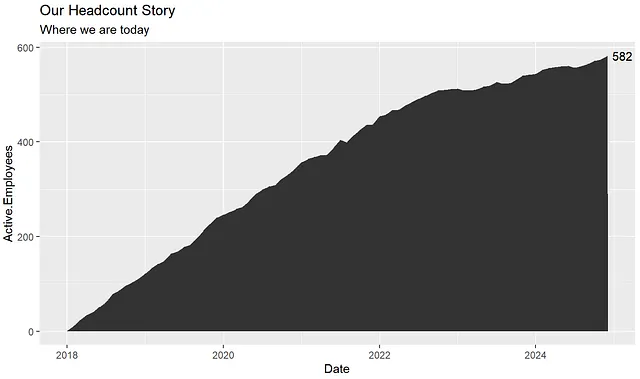
Ora che abbiamo creato il nostro grafico di base, vogliamo creare automaticamente un grafico additivo per ogni anno. Quindi ci sarà un grafico dal 2018 alla fine del 2018, dal 2018 alla fine del 2019, dal 2018 alla fine del 2020, ecc.
5. Crea automaticamente un grafico per ogni anno
Utilizzeremo un ciclo for per creare un grafico per ogni anno nel nostro set di dati.
In pratica, otterremo ogni anno unico nel nostro dataset in un vettore chiamato “years”. Quindi per ogni anno in “years” creeremo un sottoinsieme dei nostri dati e quindi un grafico di quel sottoinsieme. Probabilmente sembra confuso, ma guardando il codice avrà probabilmente più senso.
Prima una preparazione:
# crea un vettore per gli anni uniciyears <- unique(headcount_data$year)# lista vuota per i graficiplots <- list()Ora per il ciclo! Potrebbe sembrare travolgente, ma prendilo passo dopo passo:
# loop su ogni anno in years e creare i grafici for (i in 2:length(years)) { # crea un sottoinsieme aggiungendo un anno alla volta subset_df <- headcount_data %>% filter(year <= years[i]) # calcoli per l'annotazione annotation_ending_year <- max(subset_df$Date) annotation_ending_active <- subset_df %>% filter(Date == ending_year) %>% select(Active.Employees) %>% as.numeric() # crea un grafico (p) utilizzando il sottoinsieme p <- subset_df %>% ggplot(aes(x = Date, y = Active.Employees)) + geom_area() + labs(title = labels_title, subtitle = labels_subtitle) + annotate("text", x = max(subset_df$Date), y = max(subset_df$Active.Employees), label = ending_active, hjust = -.25) # salva ogni graficoggsave(p, file = paste("example_plot_", years[i], ".png"), height = 6, width = 8, units = "in")}Ora dovresti avere un grafico salvato per ogni anno nella tua directory di lavoro chiamato “example_plot_year”. Mi piace avere un grafico separato per ogni anno in modo da poter mettere ciascuno in una diapositiva e mettere in pausa quando le persone hanno domande. In alternativa, puoi animare i grafici insieme e creare un gif o utilizzare un registratore dello schermo come ScreenToGif e ottenere qualcosa del genere:
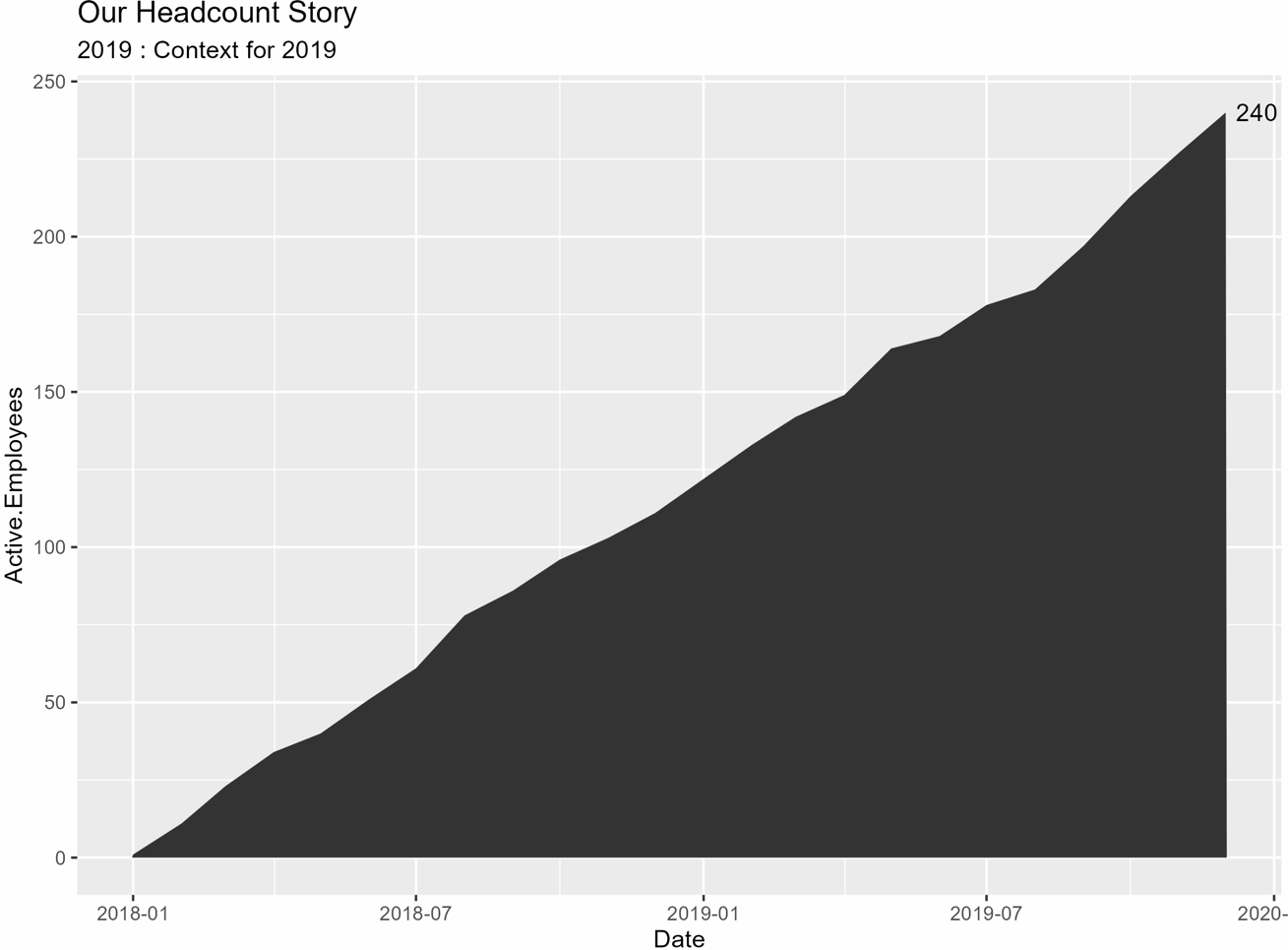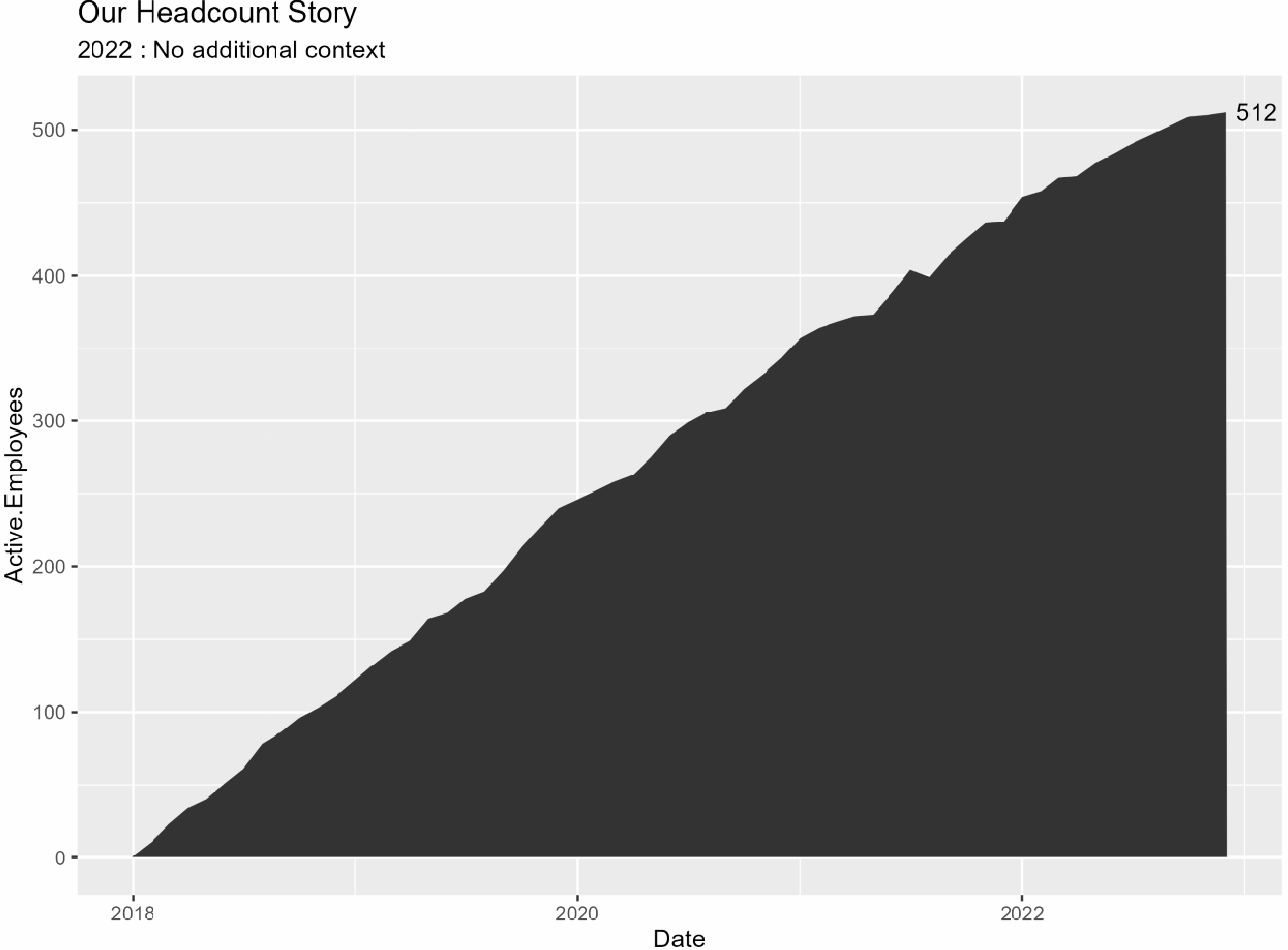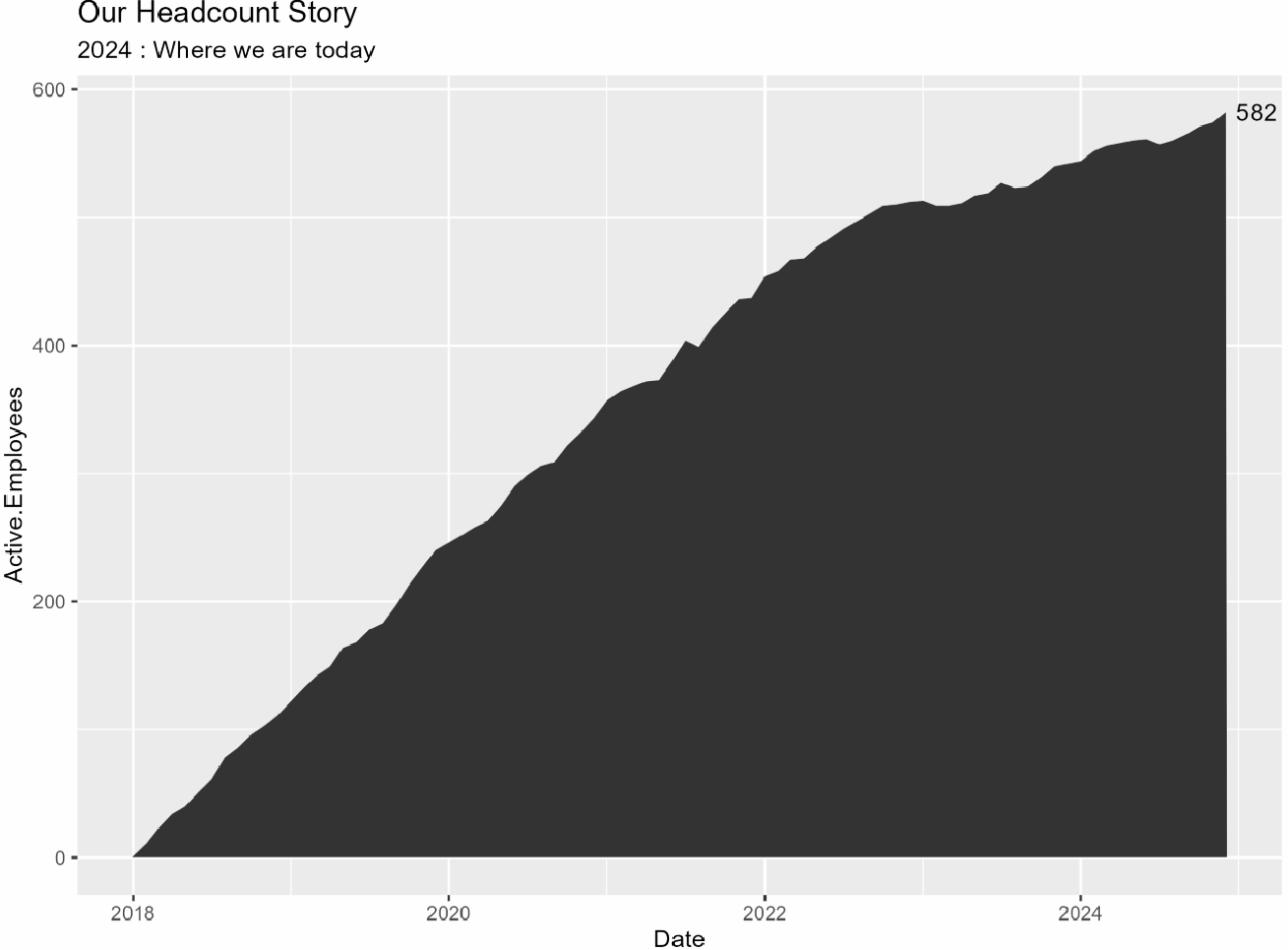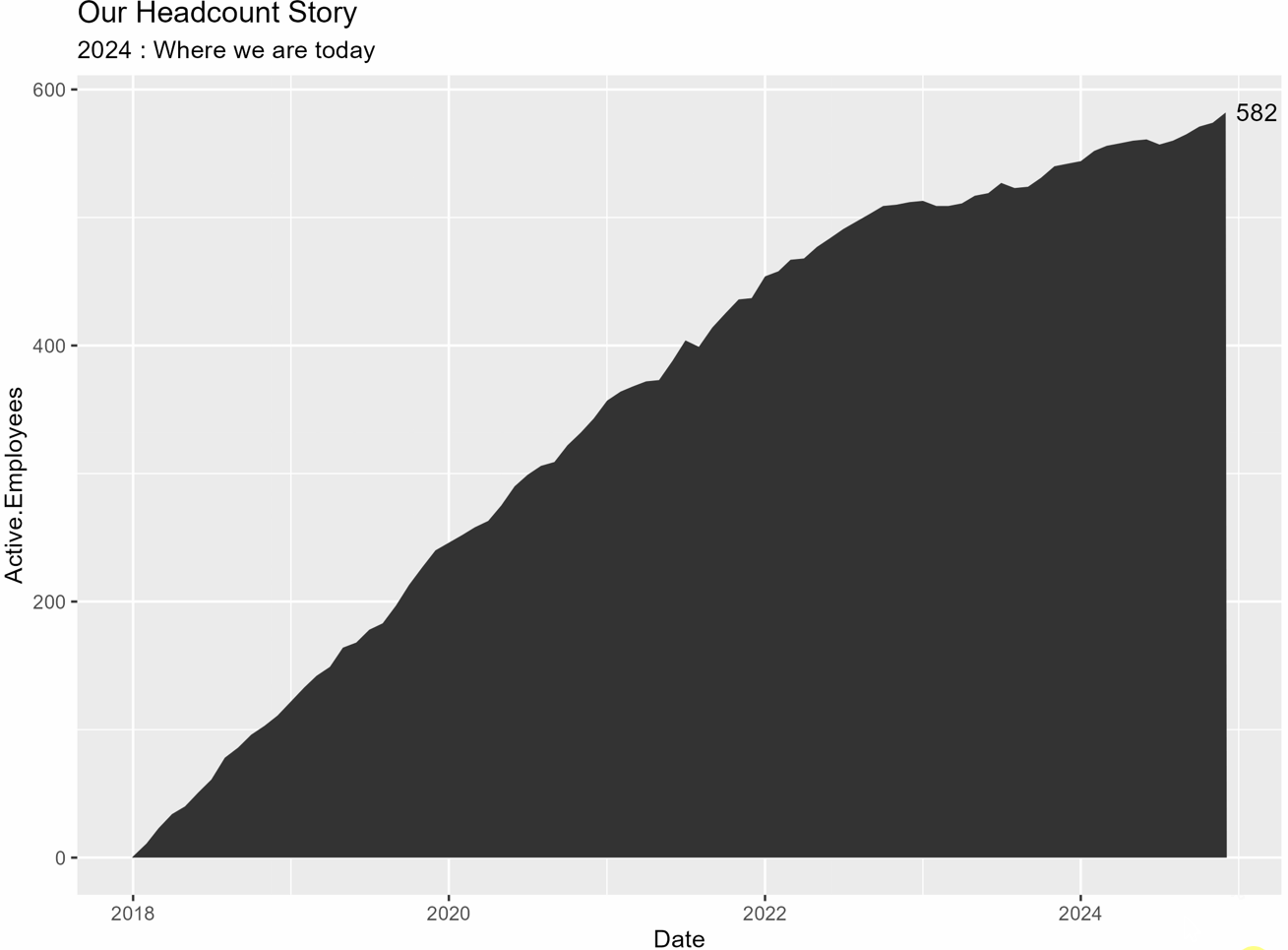
Ci siamo riusciti!!!! Tutto ciò che resta è aggiungere qualche stile per rendere il grafico più fedele al tuo marchio e aggiungere un rettangolo per evidenziare l’anno più recente.
6. Modifica del tema e formattazione del grafico
La prima cosa che voglio fare è aggiungere un rettangolo che evidenzi l’anno più recente. Questo aiuterà lo spettatore a sapere dove concentrarsi e si aggiornerà in ogni grafico in modo da poter guardare un anno alla volta, all’interno del contesto più ampio.
Lo faremo aggiungendo un’altra annotazione “rect” che assomiglierà a qualcosa del genere:
annotate("rect", xmin = , xmax = , ymin = , ymax = )Anche questo è un aspetto che mi ha impiegato un po’ di tempo per ottenere come volevo, ma le chiavi qui sono:
Asse delle X : Voglio che il rettangolo inizi alla prima (detta anche “floor”) data dell’anno specifico (detto anche “max year” nel nostro sottoinsieme di dati) e finisca all’ultima (detta anche “ceiling”) data dell’anno specifico (detto anche “max year” nel nostro sottoinsieme di dati). Quindi per il grafico del 2019, vogliamo che il rettangolo inizi il 1/1/2019 e finisca il 12/1/2019.
annotate("rect", xmin = floor_date(max(subset_df$Date), "year"), xmax = ceiling_date(max(subset_df$Date), "year")Asse delle Y : Voglio che il rettangolo inizi dall’asse delle y e finisca sopra (+300) dal conteggio finale dei dipendenti di quell’anno, in modo che sia più facile da leggere senza essere affollato. Guardando di nuovo al 2019, voglio che il rettangolo inizi proprio sull’asse delle y e finisca sopra (+300) dal conteggio finale di 240.
annotate("rect", xmin = floor_date(max(subset_df$Date), "year"), xmax = ceiling_date(max(subset_df$Date), "year"), ymin = -Inf, ymax = ending_active + 300)Stile : Infine, farò in modo che il rettangolo sia grigio e cambierò l’alpha a 0,1 in modo che sia abbastanza trasparente e si possa vedere l’area del grafico sottostante:
annotate("rect", xmin = floor_date(max(subset_df$Date), "year"), xmax = ceiling_date(max(subset_df$Date), "year"), ymin = -Inf, ymax = ending_active + 300, alpha = .1, color = "gray", fill = "gray")Limitare gli assi : Per rendere le transizioni più fluide, metterò dei limiti sugli assi x e y in modo che ogni grafico abbia la stessa scala.
scale_x_date(breaks = "1 year", date_labels = "%Y", expand = c(.1,.1), limits = c(min(headcount_data$Date), max(headcount_data$Date)))Wahoo! Siamo così vicini, ora apporterò alcune modifiche al tema e poi verserò un bicchiere di vino. Ora è il momento di mettere il tuo tocco personale, il mio ha finito per avere un aspetto simile a questo:
Ecco il codice del mio ciclo for finale:
# loop over the each year in years and create plotsfor (i in 2:length(years)) { # create subset adding one year at a time subset_df <- headcount_data %>% filter(year <= years[i]) # calculations for annotation ending_year <- max(subset_df$Date) ending_active <- subset_df %>% filter(Date == ending_year) %>% select(Active.Employees) %>% as.numeric() # create a plot (p) using the subset p <- subset_df %>% ggplot(aes(x = Date, y = Active.Employees)) + geom_area(fill = "#457b9d") + labs(title = "La Nostra Storia del Numero di Dipendenti", subtitle = paste(years[i],":", last(subset_df$context)), x = "", y = "") + scale_x_date(breaks = "1 year", date_labels = "%Y", expand = c(.1,.1), limits = c(min(headcount_data$Date), max(headcount_data$Date))) + theme_classic(base_family = "Arial") + theme(plot.title = element_text(size = 24, face = "bold", color = "#457b9d"), plot.subtitle = element_text(size = 18), panel.grid.major = element_blank(), panel.grid.minor = element_blank(), axis.ticks.y = element_blank(), axis.text.y = element_blank(), axis.line.y = element_blank()) + annotate("text", x = ending_year, y = ending_active, label = ending_active, vjust = -1.25, hjust = -.25, color = "#457b9d") + annotate("rect", xmin = floor_date(max(subset_df$Date), "year"), xmax = ceiling_date(max(subset_df$Date), "year"), ymin = -Inf, ymax = ending_active + 300, alpha = .1, color = "gray", fill = "gray") # save each plot ggsave(p, file = paste("example_plot_final", years[i], ".png"), height = 6, width = 8, units = "in") }TTTTUUUUUUTTTTTOOOOOOOO FFFFAAAATTTTTTOOOOO!
Ora abbiamo una visione dinamica di come il nostro organico sia cambiato nel tempo con ulteriori contesti nel nostro sottotitolo. Alcune idee per future iterazioni: creare i grafici con gganimate, aggiungere una variazione percentuale all’organico di ogni anno, cambiare il colore del grafico se l’organico è aumentato o diminuito, aggiungere una proiezione della linea di tendenza di crescita, le possibilità sono infinite!
Hai provato a farne uno? In tal caso, mi piacerebbe vedere cosa hai creato!
Codice completo su Github, qui.
Vuoi altre risorse di People Analytics in generale?
12+ Risorse gratuite per iniziare in People Analytics
Le risorse gratuite che consiglio a coloro che vogliono iniziare una carriera in People Analytics.
jeagleson.medium.com
Se vuoi ulteriori risorse come questa e accesso a tutti i contenuti fantastici su questo sito, puoi utilizzare il mio link per iscriverti a $5 al mese (riceverò una piccola commissione senza alcun costo aggiuntivo per te).
Unisciti a VoAGI con il mio link di referral – Jenna Eagleson
Leggi tutte le storie di Jenna Eagleson (e migliaia di altri scrittori su VoAGI). La tua quota di iscrizione sostiene direttamente…
jeagleson.medium.com
Jenna Eagleson Il mio background è in Psicologia Industriale-Organizzativa e ho trovato la mia casa in People Analytics. La visualizzazione dei dati è ciò che dà vita al mio lavoro. Mi diverto ad imparare e sviluppare con Power BI, R, Tableau e altri strumenti che incontro. Mi piacerebbe sentire di più sul tuo percorso! Trovami su Linkedin o Twitter.