Esplorazione di NLP – Avvio di NLP (Passaggio #1)
NLP Exploration - NLP Introduction (Step #1)
Se sei nuovo nella mia serie “Esplorando l’NLP”, controlla il mio articolo introduttivo qui.
Esplorare e padroneggiare l’NLP – Un viaggio nelle profondità
Ciao, sono Deepthi Sudharsan, una studentessa universitaria di terzo anno che frequenta il corso di laurea in Intelligenza Artificiale. Dato che sono già…
VoAGI.com
In questo semestre, ho l’NLP come parte del mio curriculum. YAY. Quindi, come parte di una valutazione imminente per la materia, stavo rivedendo i materiali dati e ho preso appunti che condividerò oggi. Spero che sia utile. Approfitto anche di questo momento per ringraziare i miei docenti del dipartimento CEN, Amrita Vishwa Vidhyapeetham, Coimbatore, India. È grazie alla loro guida, motivazione e supporto che ho iniziato questa serie. Sono tutti i loro insegnamenti che mi hanno fatto seguire la mia passione per l’NLP. Desidero ringraziare in particolare il signor Sachin Kumar S del CEN, Amrita Coimbatore, per aver tenuto questo corso per me in questo semestre alcune delle informazioni e immagini raccolte qui provengono da risorse e materiali forniti o creati da lui.
Cos’è l’NLP?
Lo studio dell’interazione tra computer e linguaggi umani è chiamato Elaborazione del Linguaggio Naturale. Cerca di dare ai computer la capacità di comprendere il testo e i contenuti del discorso in modo simile a quanto possono fare gli esseri umani.
- Esplorazione di NLP – Avviamento di NLP (Passo #2)
- Esplorazione NLP – Avvio di NLP (Passaggio #3)
- Esplorazione dell’NLP – Avvio dell’NLP (Step #4)
Obiettivo: Catturare completamente il significato contestuale. (Il contesto si riferisce alle informazioni derivate dal significato di un testo)

- Fonetica: studia come gli esseri umani producono e percepiscono i suoni o gli aspetti equivalenti del linguaggio dei segni
- Fonologia: studia come le lingue o i dialetti organizzano sistematicamente i loro suoni o le parti costituenti dei segni nelle lingue dei segni
- Morfologia: lo studio della struttura interna delle parole – Il morfema è il mattoncino della morfologia – Una parola è l’unità indipendente più piccola di una lingua – Le parole semplici non hanno una struttura interna (o consistono in un solo morfema). Esempio: lavoro, corsa – Le parole complesse hanno una struttura interna (composta da uno o più morfemi). Esempio: lavoratore (lavoro+ore), edificio (costruisci+ndo)
- Sintassi: lo studio di come le parole e i morfemi si combinano per formare unità più grandi come frasi e frasi
- Semantica: lo studio del riferimento, del significato o della verità
- Pragmatica: lo studio di come il contesto contribuisce al significato
Alcuni termini importanti:
- I token possono essere considerati come parole, caratteri, sottoparole, ecc.
- La tokenizzazione è il processo di separazione delle parti di testo delle frasi in token.
- Il corpus è una collezione di dati testuali.
- Il vocabolario è una collezione di token unici nel corpus.
- Il lessico si riferisce alle parole e ai loro significati.

Tipi di tokenizzazione
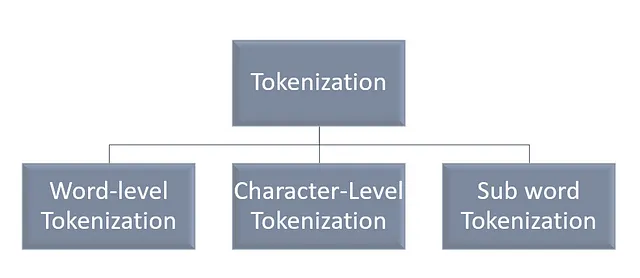
Tokenizzazione a livello di parole
Suddivide la frase data in parole basandosi su un certo delimitatore
“She is smarter” diventa “she”, “is”, “smarter”. Qui il delimitatore è lo spazio.
Svantaggi:
Quando ci sono parole “Out of Vocabulary (OOV)” (Una soluzione è sostituire le parole rare con un token sconosciuto (UNK). In questo caso, il vocabolario conterrà solo le prime k parole più frequenti, ma le informazioni sulla nuova parola andranno perse)
La dimensione del vocabolario creato sarà enorme, portando a problemi di memoria e di prestazioni (una soluzione – passare alla tokenizzazione a livello di caratteri)
Quando si dividono le frasi in base agli spazi vuoti e alla punteggiatura, ci sono problemi nel gestire parole che sono considerate come un singolo token ma sono separate da spazio o punteggiatura come don’t, New York, ecc.
Tokenizzazione a livello di caratteri:
Suddivide la frase data in una sequenza di caratteri.
“Smarter” diventa “s”, “m”, “a”, “r”, “t”, “e”, “r”.
Vantaggi:
Dimensione del vocabolario più piccola (26 lettere dell’alfabeto + caratteri speciali, ecc.)Gestisce gli errori di ortografia
Tokenizzazione a livello di sotto-parole:
Suddivide le parole in pezzi più piccoli.
“Smarter” diventa “Smart”, “er”
Stopwords:
Le stopwords sono le parole comunemente usate nel testo come “the”, “in”, “where”, ecc.
import nltkfrom nltk.corpus import stopwords #Pythonprint(set(stopwords.words('english')))Alcune sfide di NLP:
- Ambiguità (frasi o espressioni con multiple interpretazioni. Due tipi: Sintattico – multiple interpretazioni di una frase e Lessicale – multiple interpretazioni di una parola)
- Abbreviazioni (forme brevi)
- Token non linguistici
- Dati dei social media (in forma code-mixed)
Modellazione del linguaggio:
Prevedere l’unità linguistica possibile (parola, testo, frase, token, simbolo, ecc.) che può verificarsi successivamente considerando il contesto.
I modelli che assegnano valori di probabilità alla sequenza di token sono chiamati modelli linguistici
Il modello più semplice è il “N-gram”. Assegna probabilità a una frase o a una sequenza di “n” token.
Utilizza l’assunzione di Markov; la probabilità della parola successiva dipende solo dalla parola precedente. I modelli N-gram guardano (n-1) parole nel passato per prevedere la parola successiva.


Riferimenti
Panoramica degli algoritmi di tokenizzazione in NLP
Introduzione ai metodi di tokenizzazione, inclusi subword, BPE e SentencePiece
towardsdatascience.com
- ‘Speech & language processing’, Daniel Jurafsky, James H Martin, preparazione [citato il 1 giugno 2020] (Disponibile su: https://web. stanford. edu/~ jurafsky/slp3 (2018))
- https://www.slideshare.net/YuriyGuts/natural-language-processing-nlp
- ‘Foundations of Statistical Natural Language Processing’, Christopher Manning e Hinrich Schütze, MIT press, 1999
- ‘Natural Language Processing with Python’, Steven Bird, Ewan Klein ed Edward Loper, O’Reilly Media, Inc.”, 2009.
- ‘Deep Learning for Natural Language Processing: Develop Deep Learning Models for your Natural Language Problems (Ebook)’, Jason Browlee, Machine Learning Mastery, 2017.
- ‘Speech & language processing’, Daniel Jurafsky, James H Martin, preparazione [citato il 1 giugno 2020]
- https://all-about-linguistics.group.shef.ac.uk/branches-of-linguistics/morphology/what-is-morphology//
- http://sams.edu.eg/en/faculties/flt/academic-programs-and-courses/department-of-english-language/
- https://www.coursehero.com/file/127598328/Human-Comm-Ch-2-4-Notesdocx//
- https://slideplayer.com/slide/7728110/
- https://www.geeksforgeeks.org/removing-stop-words-nltk-python/