Approfondimento sulle Unità Ricorrenti con Porte (GRU) Comprensione della Matematica dietro le RNN
Approfondimento GRU e Matematica delle RNN
La Gated Recurrent Unit (GRU) è una versione semplificata della Long Short-Term Memory (LSTM). Vediamo come funziona in questo articolo.
Questo articolo spiegherà il funzionamento delle unità ricorrenti con gate (GRU). Poiché le GRU possono essere comprese facilmente se si ha conoscenza preliminare delle Long Short-Term Memory (LSTM), consiglio vivamente di apprendere prima delle LSTM. Puoi leggere il mio articolo sulle LSTM.
Da RNN Vanilla a LSTM: una guida pratica alla Long Short-Term Memory | di Shivamshinde | Gen, 2023 | VoAGI
Le unità ricorrenti con gate, alias GRU, sono una versione ridotta o semplificata delle unità di Long Short-Term Memory (LSTM). Entrambe sono utilizzate per far sì che la nostra rete neurale ricorrente mantenga informazioni utili per un periodo più lungo. Entrambe sono altrettanto valide. Le prestazioni di entrambe varieranno in base ai diversi casi di utilizzo. Per un caso di utilizzo, le LSTM potrebbero funzionare meglio, mentre per un altro caso le GRU potrebbero funzionare meglio. Dovremo provare entrambi i modelli e utilizzare quello con prestazioni superiori per l’addestramento effettivo del nostro modello.
- Esplorazione di NLP – Avvio di NLP (Passaggio #1)
- Esplorazione di NLP – Avviamento di NLP (Passo #2)
- Esplorazione NLP – Avvio di NLP (Passaggio #3)
Tuttavia, ci sono alcuni vantaggi nell’utilizzare le GRU nella tua rete.
- Come vedremo in questo articolo, le GRU hanno due gate, il che le rende più veloci da addestrare. Questo è utile quando si dispone di meno memoria e potenza di elaborazione.
- Inoltre, forniscono ottimi risultati su piccoli set di dati.
Ora comprendiamo il funzionamento delle GRU.
Nota il significato dei simboli nei diagrammi seguenti:

Significato delle variabili nelle equazioni seguenti
Wxz, Wxr, Wxg sono le matrici di peso di ciascuno dei tre gate per la loro connessione con il vettore di input x(t).
Whz, Whr, Whg sono le matrici di peso di ciascuno dei tre gate per la loro connessione con lo stato precedente h(t-1).
bz, br, bg sono i termini di bias per ciascuno dei tre gate.
Informazioni di base sulle GRU
A un livello elevato, le GRU possono essere considerate una versione migliore delle unità RNN semplici con lo stesso numero di input e output. Tuttavia, la struttura interna delle GRU è leggermente diversa.
A differenza delle LSTM, le GRU hanno un solo vettore di stato. Si potrebbe dire che i vettori a lungo termine e a breve termine sono combinati in uno solo nel caso delle GRU.
La GRU è composta da tre blocchi. Sono
- Blocco RNN di base, g(t)
- Un gate che svolge il compito di dimenticare le informazioni inutili e ricordare le nuove informazioni importanti, z(t)
- Un gate che determina quale porzione dello stato precedente deve essere utilizzata come input, r(t)
La GRU prende due input. Sono
- Stato della cella precedente, h(t-1)
- Input dei dati di addestramento, x(t)
La cella GRU produce due termini in output. Sono
- Stato attuale della cella, h(t)
- Predizione per la cella corrente, y(t)
Ora, comprendiamo come vengono calcolati ciascuno dei risultati utilizzando gli input.
Calcolo dello stato attuale della cella
Fondamentalmente, lo stato della cella viene ottenuto dall’addizione di due quantità. La prima quantità ci dice quanto deve essere dimenticato dallo stato precedente. E la seconda quantità ci dice quanto deve essere ricordato dall’input dei dati di addestramento.
Comprendiamo la prima quantità.
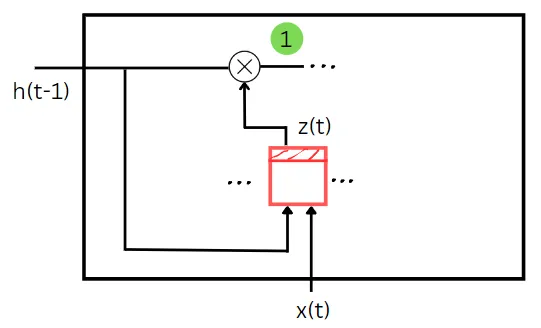
Come puoi vedere nel diagramma sopra, z(t) prende lo stato precedente e i dati di addestramento come input. Agisce un po’ come un cancello di dimenticanza qui. Il valore del cancello z(t) determina quale parte dello stato precedente deve essere dimenticata in questo passaggio temporale. Lo stato precedente e l’input di addestramento vengono moltiplicati per i loro pesi corrispondenti e viene aggiunto il bias alla loro somma. Dopo aver applicato una funzione sigmoide a questa somma, otterremo il valore di z(t). La moltiplicazione elemento per elemento dello stato precedente e del valore di z(t) ci fornisce la prima quantità necessaria per calcolare lo stato del passaggio temporale corrente. La prima quantità è mostrata in colore verde nel diagramma sopra.
Cerchiamo di capire la seconda quantità.
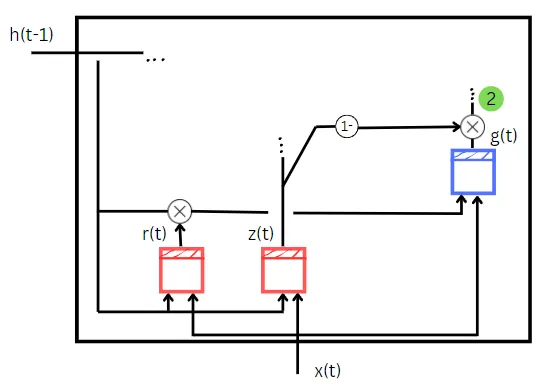
Il valore di z(t) viene calcolato come spiegato nel calcolo della prima quantità. Ma qui (1 — z(t)) agisce come un cancello di input. La cella RNN di base g(t) prende due input. Sono
- Input dei dati di addestramento, x(t)
- Moltiplicazione elemento per elemento di r(t) e dello stato precedente, h(t-1)
Il calcolo per trovare r(t) è lo stesso di z(t) tranne per i pesi e i bias utilizzati nel calcolo. Il valore di r(t) ci dice quale parte dello stato precedente deve essere fornita come input alla semplice cella RNN g(t).
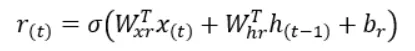
Entrambi gli input di g(t) vengono moltiplicati per i loro pesi corrispondenti e quindi il termine di bias viene aggiunto alla loro somma. Quindi questo valore di somma finale viene passato alla funzione tangente iperbolica che ci dà il valore di g(t).
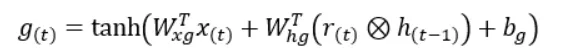
Ora la moltiplicazione elemento per elemento di g(t) con (1 — z(t)), aka cancello di input, ci fornirà la seconda quantità necessaria per calcolare lo stato del passaggio temporale corrente. La seconda quantità è mostrata in colore verde nel diagramma sopra.
Ora che abbiamo trovato entrambe le quantità, la loro somma ci darà lo stato del passaggio temporale corrente.
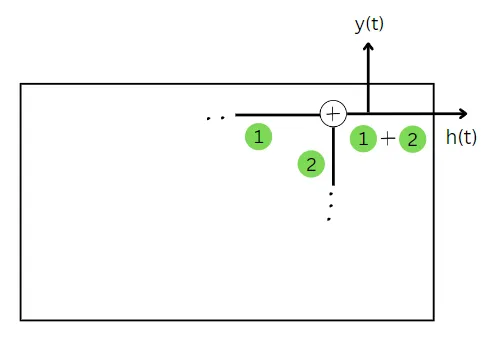
Nelle celle GRU, il valore dello stato corrente è uguale alla previsione. Pertanto, poiché abbiamo già calcolato lo stato corrente, abbiamo anche calcolato la previsione per il passaggio temporale corrente.

Fino ad ora abbiamo visto le diverse parti che compongono l’intera GRU per comprenderla meglio. Quindi, uniamo tutte le parti che abbiamo esaminato fino ad ora.
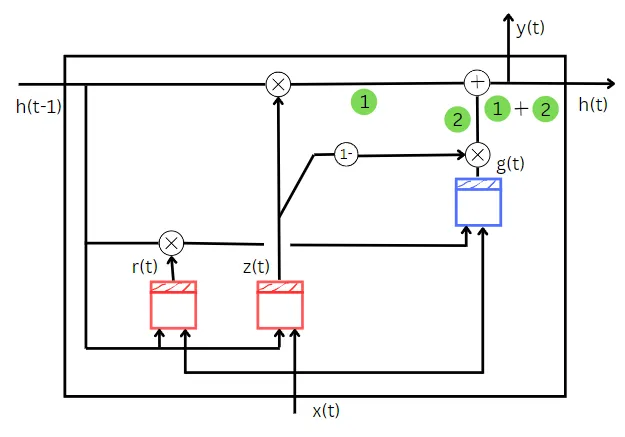
Questo è l’intero diagramma del network GRU.
Spero che ti piaccia l’articolo. I diagrammi nell’articolo sono disegnati da me a mano. Spero siano sufficientemente intuitivi (e non troppo disordinati) per comprendere chiaramente la GRU. Se hai qualche pensiero sull’articolo, per favore fammelo sapere. Inoltre, se ti è piaciuto l’articolo, per favore apprezzalo.
Contattami su
Sito web
Scrivimi a [email protected]
Passa una splendida giornata!