Usare o Non Usare Machine Learning
Usare o Non Usare Machine Learning' can be condensed to 'Usare o Non Usare ML
Come decidere se utilizzare l’apprendimento automatico è una buona idea, e come ciò sta cambiando con GenAI

L’apprendimento automatico è ottimo per risolvere determinati problemi complessi, di solito che coinvolgono relazioni difficili tra caratteristiche e risultati che non possono essere facilmente codificate come euristiche o istruzioni if-else. Tuttavia, ci sono alcune limitazioni o cose da tenere a mente quando si decide se l’apprendimento automatico è una buona soluzione per un determinato problema. In questo post approfondiremo l’argomento “usare o non usare l’apprendimento automatico”, prima comprendendo questo concetto per modelli di apprendimento automatico “tradizionali”, e successivamente discutendo come questa situazione sta cambiando con i progressi dell’Intelligenza Artificiale Generativa.
Per chiarire alcuni dei punti, userò come esempio la seguente iniziativa: “Come azienda, voglio sapere se i miei clienti sono soddisfatti e i principali motivi di insoddisfazione”. Un approccio basato sull’apprendimento automatico “tradizionale” per risolvere questo problema potrebbe essere:
- Ottenere i commenti che i clienti scrivono su di te (app o store, Twitter o altri social network, il tuo sito web…)
- Utilizzare un modello di analisi del sentiment per classificare i commenti in positivi / neutri / negativi.
- Utilizzare il topic modeling sui commenti previsti con “sentimento negativo” per capire di cosa parlano.

I miei dati hanno una qualità e una quantità sufficienti?
Negli modelli di apprendimento automatico supervisionato, i dati di addestramento sono necessari affinché il modello possa imparare ciò che deve prevedere (in questo esempio, il sentiment da un commento). Se i dati hanno una bassa qualità (molti errori di battitura, dati mancanti, errori…), sarà molto difficile per il modello avere un buon rendimento.
Questo è comunemente noto come il problema del “garbage in, garbage out”: se i tuoi dati sono scadenti, anche il tuo modello e le tue previsioni saranno scadenti.
Allo stesso modo, è necessario disporre di una quantità sufficiente di dati per consentire al modello di apprendere le diverse casistiche che influiscono su ciò che deve essere previsto. In questo esempio, se hai solo un caso di etichetta di commento negativo con concetti come “inutile”, “deluso” o simili, il modello non sarà in grado di apprendere che queste parole di solito compaiono quando l’etichetta è “negativa”.
Un’adeguata quantità di dati di addestramento dovrebbe anche aiutare a garantire di avere una buona rappresentazione dei dati necessari per effettuare previsioni. Ad esempio, se i tuoi dati di addestramento non rappresentano una particolare area geografica o una particolare segmento della popolazione, è più probabile che il modello non riesca a fornire buoni risultati per quei commenti al momento delle previsioni.
Per alcuni casi d’uso, è anche importante disporre di dati storici sufficienti, per garantire che siamo in grado di calcolare caratteristiche o etichette ritardate rilevanti (ad esempio, “il cliente paga il credito durante l’anno successivo o meno”).
Le etichette sono chiare da definire e facili da ottenere?
Anche per i modelli di apprendimento automatico supervisionato tradizionali, è necessario disporre di un dataset etichettato: esempi per i quali si conosce l’outcome finale di ciò che si desidera prevedere, per poter addestrare il modello.
La definizione dell’etichetta è fondamentale. In questo esempio, la nostra etichetta sarebbe il sentiment associato al commento. Potremmo pensare di poter avere solo commenti “positivi” o “negativi”, e quindi sostenere che potremmo avere anche commenti “neutrali”. In questo caso, da un dato commento, di solito sarà chiaro se l’etichetta deve essere “positiva”, “neutra” o “negativa”. Ma immaginiamo di avere le etichette “molto positivo”, “positivo”, “neutro”, “negativo” o “molto negativo”… Per un dato commento, sarebbe così facile decidere se è “positivo” o “molto positivo”? Questa mancanza di una definizione chiara dell’etichetta deve essere evitata, poiché addestrare con un’etichetta rumorosa renderà più difficile per il modello imparare.
Ora che la definizione dell’etichetta è chiara, dobbiamo essere in grado di ottenere questa etichetta per un insieme sufficiente e di qualità di esempi, che formeranno i nostri dati di addestramento. Nel nostro esempio, potremmo considerare l’etichettatura manuale di un insieme di commenti, che sia all’interno dell’azienda o del team, o che sia l’esternalizzazione dell’etichettatura ad annotatori professionali (sì, ci sono persone che lavorano a tempo pieno nell’etichettatura di dataset per l’apprendimento automatico!). I costi e la fattibilità associati all’ottenimento di queste etichette devono essere considerati.
Sarà fattibile la deploy del sistema?
Per raggiungere un impatto finale, le previsioni del modello di apprendimento automatico devono essere utilizzabili. A seconda del caso d’uso, l’utilizzo delle previsioni potrebbe richiedere infrastrutture specifiche (ad esempio una piattaforma di apprendimento automatico) ed esperti (ad esempio ingegneri di apprendimento automatico).
Nel nostro esempio, poiché vogliamo utilizzare il nostro modello per scopi analitici, potremmo eseguirlo offline e sfruttare le previsioni sarebbe piuttosto semplice. Tuttavia, se volessimo rispondere automaticamente a un commento negativo nei successivi 5 minuti in cui viene pubblicato, sarebbe un’altra storia: il modello dovrebbe essere implementato e integrato per rendere ciò possibile. In generale, è importante avere un’idea chiara dei requisiti per utilizzare le previsioni, per garantire che sia fattibile con il team e gli strumenti disponibili.
Cosa è in gioco?
I modelli di apprendimento automatico avranno sempre un certo livello di errore nelle loro previsioni. In realtà, è un classico nell’apprendimento automatico dire:
Se il modello non ha errori, allora c’è sicuramente qualcosa di sbagliato nei dati o nel modello
È importante capire questo, poiché se il caso d’uso non consente che si verifichino questi errori, potrebbe non essere una buona idea utilizzare l’apprendimento automatico. Nel nostro esempio, immaginiamo invece di commenti e sentimenti, stiamo utilizzando il modello per classificare le email dei clienti in “presentare accuse o meno”. Non sarebbe una buona idea avere un modello che possa classificare erroneamente una email che presenta accuse contro l’azienda, a causa delle terribili conseguenze che potrebbe avere per l’azienda stessa.
L’utilizzo dell’apprendimento automatico è eticamente corretto?
Ci sono stati molti casi comprovati di modelli predittivi che hanno discriminato in base al genere, alla razza e ad altre caratteristiche personali sensibili. A causa di ciò, i team di apprendimento automatico devono fare attenzione ai dati e alle caratteristiche che utilizzano per i loro progetti, ma anche a interrogarsi se automatizzare determinati tipi di decisioni abbia effettivamente senso da un punto di vista etico. Puoi consultare il mio post precedente sull’argomento per ulteriori dettagli.
Avrò bisogno di spiegabilità?
I modelli di apprendimento automatico agiscono in qualche modo come una scatola nera: si inseriscono alcune informazioni e magicamente producono previsioni. La complessità dietro i modelli è ciò che si trova dietro questa scatola nera, specialmente se confrontiamo con algoritmi più semplici della statistica. Nel nostro esempio, potremmo andare bene senza essere in grado di capire esattamente perché un commento è stato previsto come “positivo” o “negativo”.
In altri casi d’uso, la spiegabilità potrebbe essere un must. Ad esempio, nei settori fortemente regolamentati come assicurazioni o banche. Una banca deve essere in grado di spiegare il motivo per cui sta concedendo (o meno) un credito a una persona, anche se tale decisione si basa su un modello predittivo di punteggio.
Questo argomento ha una forte relazione con quello etico: se non siamo in grado di capire appieno le decisioni dei modelli, è davvero difficile sapere se il modello ha imparato a discriminare o meno.
Tutto questo sta cambiando con l’IA generativa?
Grazie ai progressi dell’IA generativa, una varietà di aziende offre pagine web e API per utilizzare modelli potenti. In che modo ciò sta cambiando le limitazioni e le considerazioni che ho menzionato in precedenza sull’apprendimento automatico?
- Argomenti correlati ai dati (qualità, quantità ed etichette): per i casi d’uso che possono sfruttare modelli esistenti di IA generativa, questo sta sicuramente cambiando. Enormi volumi di dati vengono già utilizzati per addestrare modelli di IA generativa. La qualità dei dati non è stata controllata nella maggior parte di questi modelli, ma sembra che ciò compensi con l’enorme volume di dati che utilizzano. Grazie a questi modelli, potrebbe essere il caso (di nuovo, per casi d’uso molto specifici) che non abbiamo più bisogno di dati di addestramento. Questo è noto come apprendimento senza supervisione (ad esempio, “chiedi a ChatGPT quale è il sentimento di un determinato commento”) e apprendimento con pochi esempi (ad esempio, “fornisci alcuni esempi di commenti positivi, neutri e negativi a ChatGPT, poi chiedi di fornire il sentimento per un nuovo commento”). Una buona spiegazione di questo si trova nella newsletter di deeplearning.ai.
- Fattibilità della distribuzione: per i casi d’uso che possono sfruttare modelli esistenti di IA generativa, la distribuzione diventa molto più facile, poiché molte aziende e strumenti offrono API facili da usare per quei modelli potenti. Se quei modelli devono essere ottimizzati ulteriormente o portati internamente per motivi di privacy, allora la distribuzione ovviamente diventerà molto più difficile.
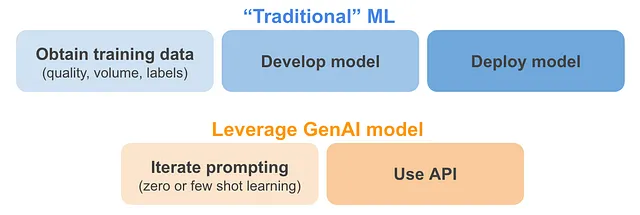
Altre limitazioni o considerazioni non cambiano, indipendentemente dal fatto di sfruttare GenAI o meno:
- Alti rischi: questo rimarrà un problema, poiché i modelli GenAI hanno un livello di errore nelle loro previsioni. Chi non ha mai visto GhatGPT allucinare o fornire risposte che non hanno senso? Ciò che è peggio, è più difficile valutare questi modelli, poiché le risposte suonano sempre sicure indipendentemente dal grado di accuratezza che hanno, e la valutazione diventa soggettiva (ad esempio “questa risposta ha senso per me?”).
- Etica: ancora importante come prima. Ci sono prove che i modelli GenAI possono essere soggetti a pregiudizi a causa dei dati di input con cui sono stati addestrati (link). Man mano che sempre più aziende e funzionalità iniziano a utilizzare questi tipi di modelli, è importante avere chiari i rischi che ciò potrebbe comportare.
- Spiegabilità: poiché i modelli GenAI sono più grandi e complessi rispetto all’IA tradizionale, la spiegabilità delle loro previsioni diventa ancora più difficile. Ci sono ricerche in corso per capire come poter raggiungere questa spiegabilità, ma è ancora molto immatura (link).
Riassumendo
In questo post abbiamo visto le principali cose da considerare quando si decide se utilizzare o meno l’IA e come ciò sta cambiando con i progressi dei modelli di intelligenza generativa. I principali argomenti discussi sono stati la qualità e il volume dei dati, l’ottenimento delle etichette, l’implementazione, i rischi, l’etica e la spiegabilità. Spero che questo riassunto sia utile quando si considera la prossima iniziativa di IA (o non)!
Riferimenti
[1] Bias dell’IA: introduzione, rischi e soluzioni per modelli predittivi discriminatori, di me stesso
[2] Oltre ai set di test: come le sollecitazioni stanno cambiando lo sviluppo dell’apprendimento automatico, di deeplearning.ai
[3] I grandi modelli di linguaggio sono soggetti a pregiudizi, può la logica aiutare a salvarli?, di MIT News
[4] I tentativi di OpenAI di spiegare i comportamenti dei modelli di linguaggio, TechCrunch






