Guida completa alle metriche di valutazione del ranking
Complete guide to ranking evaluation metrics
Esplora una vasta scelta di metriche e trova la migliore per il tuo problema
Introduzione
Il ranking è un problema nell’apprendimento automatico in cui l’obiettivo è ordinare una lista di documenti per un utente finale nel modo più adatto, in modo che i documenti più rilevanti appaiano in cima. Il ranking compare in diversi ambiti della scienza dei dati, a partire dai sistemi di raccomandazione in cui un algoritmo suggerisce un insieme di elementi da acquistare fino ai motori di ricerca NLP in cui, dato una query, il sistema cerca di restituire i risultati di ricerca più rilevanti.
La domanda che sorge naturalmente è come stimare la qualità di un algoritmo di ranking. Come nell’apprendimento automatico classico, non esiste una singola metrica universale che sia adatta per ogni tipo di compito. Perché? Semplicemente perché ogni metrica ha il suo campo di applicazione che dipende dalla natura di un dato problema e dalle caratteristiche dei dati.
Ecco perché è fondamentale conoscere tutte le principali metriche per affrontare con successo qualsiasi problema di apprendimento automatico. Ed è esattamente ciò che faremo in questo articolo.
- Scoprire equazioni differenziali con reti neurali informate dalla fisica e regressione simbolica
- Incontra Mentat uno strumento di intelligenza artificiale che ti assiste in qualsiasi compito di programmazione dalla tua riga di comando, consentendo di coordinare modifiche su più file.
- Carlos Alcaraz vs. I Big 3
Tuttavia, prima di procedere, cerchiamo di capire perché alcune metriche popolari non dovrebbero essere normalmente utilizzate per la valutazione del ranking. Tenendo conto di queste informazioni, sarà più facile comprendere la necessità dell’esistenza di altre metriche più sofisticate.
Nota. L’articolo e le formule utilizzate si basano sulla presentazione sulla valutazione offline di Ilya Markov.
Metriche
In questo articolo parleremo di diversi tipi di metriche di recupero delle informazioni:
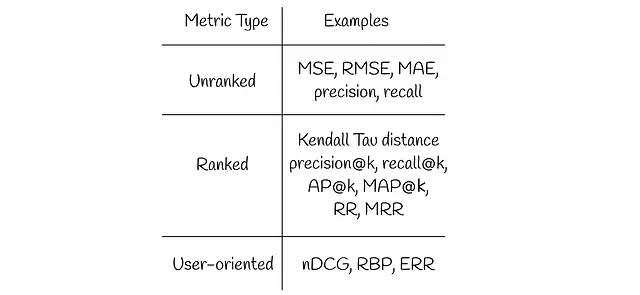
Metriche non rankate
Immagina un sistema di raccomandazione che prevede le valutazioni dei film e mostra agli utenti i film più rilevanti. La valutazione di solito rappresenta un numero reale positivo. A prima vista, una metrica di regressione come MSE (RMSE, MAE, ecc.) sembra una scelta ragionevole per valutare la qualità del sistema su un dataset di test.
MSE prende in considerazione tutti i film previsti e misura l’errore quadratico medio tra le etichette vere e previste. Tuttavia, gli utenti finali sono di solito interessati solo ai primi risultati che appaiono nella prima pagina di un sito web. Ciò indica che non sono realmente interessati ai film con valutazioni più basse che appaiono alla fine dei risultati di ricerca e che sono stimati allo stesso modo dalle metriche standard di regressione.
Un semplice esempio di seguito mostra una coppia di risultati di ricerca e misura il valore di MSE in ognuno di essi.

Anche se il secondo risultato di ricerca ha un MSE più basso, l’utente non sarà soddisfatto di una tale raccomandazione. Guardando solo gli elementi non rilevanti per primi, l’utente dovrà scorrere fino in fondo per trovare il primo elemento rilevante. Ecco perché, dal punto di vista dell’esperienza utente, il primo risultato di ricerca è molto migliore: l’utente è semplicemente felice con il primo elemento e passa ad esso senza preoccuparsi degli altri.
La stessa logica si applica alle metriche di classificazione (precisione, richiamo) che considerano tutti gli elementi.

Cosa hanno in comune tutte le metriche descritte? Tutte considerano tutti gli elementi allo stesso modo e non prendono in considerazione alcuna differenziazione tra risultati altamente rilevanti e poco rilevanti. Ecco perché vengono chiamate non rankate.
Avendo esaminato questi due esempi problematici simili sopra, l’aspetto su cui dovremmo concentrarci durante la progettazione di una metrica di ranking sembra più chiaro:
Una metrica di ranking dovrebbe dare maggior peso ai risultati più rilevanti, riducendo o ignorando quelli meno rilevanti.
Metriche classificate
Distanza di Kendall Tau
La distanza di Kendall Tau si basa sul numero di inversioni di rango.
Un’ inversione è una coppia di documenti (i, j) in cui il documento i ha una rilevanza maggiore del documento j e appare dopo nella ricerca rispetto a j.
La distanza di Kendall Tau calcola il numero di inversioni nel ranking. Minore è il numero di inversioni, migliore è il risultato della ricerca. Nonostante la metrica possa sembrare logica, ha comunque un lato negativo che viene dimostrato nell’esempio seguente.
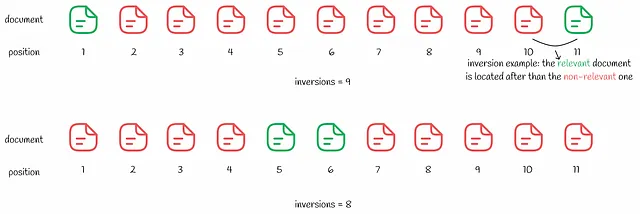
Sembra che il secondo risultato di ricerca sia migliore con solo 8 inversioni rispetto a 9 nel primo. Similmente all’esempio MSE sopra, l’utente è interessato solo al primo risultato rilevante. Passando attraverso diversi risultati di ricerca non rilevanti nel secondo caso, l’esperienza dell’utente sarà peggiore rispetto al primo caso.
Precisione@k e Richiamo@k
Invece della precisione e del richiamo usuali, è possibile considerare solo un certo numero di migliori raccomandazioni k. In questo modo, la metrica non si preoccupa dei risultati a basso rango. A seconda del valore di k scelto, le metriche corrispondenti sono indicate come precisione@k (“precisione a k”) e richiamo@k (“richiamo a k”) rispettivamente. Le loro formule sono mostrate di seguito.

Immaginiamo che i migliori k risultati vengano mostrati all’utente, dove ogni risultato può essere rilevante o meno. La precisione@k misura la percentuale di risultati rilevanti tra i migliori k risultati. Allo stesso tempo, il richiamo@k valuta il rapporto tra i risultati rilevanti tra i migliori k e il numero totale di elementi rilevanti nell’intero dataset.
Per comprendere meglio il processo di calcolo di queste metriche, facciamo riferimento all’esempio seguente.
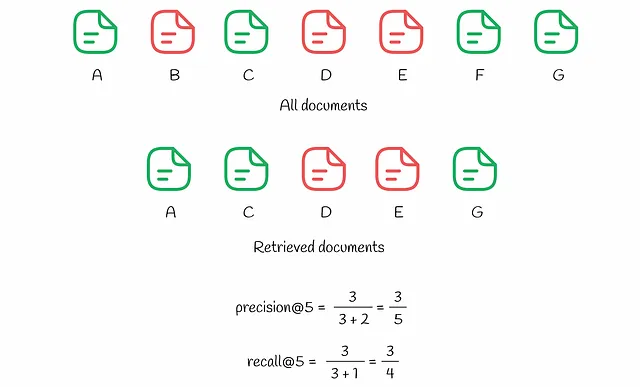
Nel sistema ci sono 7 documenti (denominati da A a G). Sulla base delle sue previsioni, l’algoritmo sceglie k = 5 documenti tra di loro per l’utente. Come possiamo notare, ci sono 3 documenti rilevanti (A, C, G) tra i migliori k = 5, il che comporta una precisione@5 pari a 3/5. Allo stesso tempo, il richiamo@5 tiene conto degli elementi rilevanti nell’intero dataset: ce ne sono 4 (A, C, F e G), il che porta a un richiamo@5 pari a 3/4.
Il richiamo@k aumenta sempre con l’aumento di k, rendendo questa metrica non particolarmente oggettiva in alcuni scenari. Nel caso limite in cui tutti gli elementi del sistema vengono mostrati all’utente, il valore del richiamo@k è del 100%. La precisione@k non ha la stessa proprietà monotona del richiamo@k, poiché misura la qualità del ranking in relazione ai migliori k risultati, non in relazione al numero di elementi rilevanti nell’intero sistema. L’oggettività è una delle ragioni per cui la precisione@k è solitamente una metrica preferita rispetto al richiamo@k nella pratica.
AP@k (Precisione media) e MAP@k (Precisione media media)
Il problema con la precisione@k standard è che non tiene conto dell’ordine degli elementi rilevanti tra i documenti recuperati. Ad esempio, se ci sono 10 documenti recuperati di cui 2 sono rilevanti, la precisione@10 sarà sempre la stessa indipendentemente dalla posizione di questi 2 documenti tra i 10. Ad esempio, se gli elementi rilevanti si trovano nelle posizioni (1, 2) o (9, 10), la metrica non differenzia entrambi questi casi risultando in una precisione@10 uguale a 0.2.
Tuttavia, nella vita reale, il sistema dovrebbe dare un peso maggiore ai documenti rilevanti posizionati in cima piuttosto che in fondo. Questo problema è risolto da un’altra metrica chiamata precisione media (AP). Come la precisione normale, AP assume valori compresi tra 0 e 1.

AP@k calcola il valore medio della precisione@i per tutti i valori di i da 1 a k per i documenti di cui il documento di posizione i è rilevante.
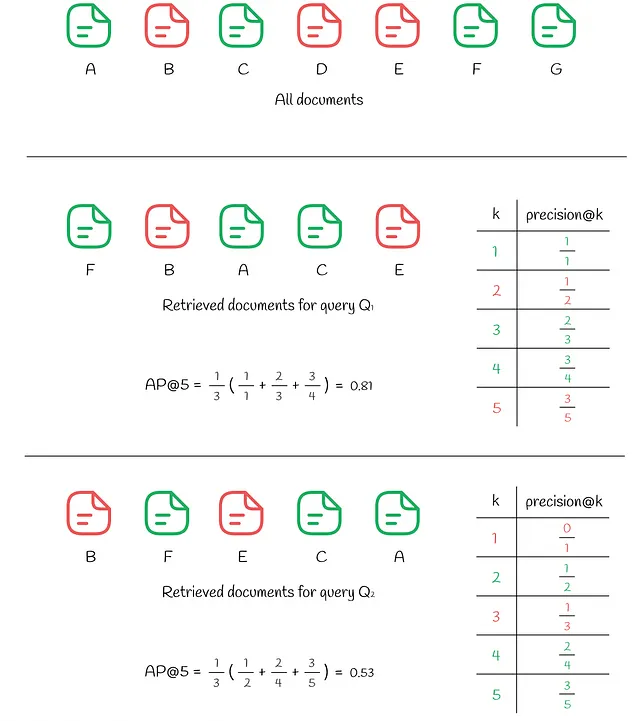
Nella figura sopra, possiamo vedere gli stessi 7 documenti. La risposta alla query Q₁ ha prodotto k = 5 documenti recuperati in cui 3 documenti rilevanti sono posizionati agli indici (1, 3, 4). Per ciascuna di queste posizioni i, viene calcolata la precisione@i:
- precisione@1 = 1 / 1
- precisione@3 = 2 / 3
- precisione@4 = 3 / 4
Tutti gli altri indici i non corrispondenti vengono ignorati. Il valore finale di AP@5 viene calcolato come media delle precisioni sopra:
- AP@5 = (precisione@1 + precisione@3 + precisione@4) / 3 = 0.81
A scopo di confronto, diamo un’occhiata alla risposta a un’altra query Q₂ che contiene anche 3 documenti rilevanti tra i primi k. Tuttavia, questa volta, 2 documenti non rilevanti sono posizionati più in alto nella classifica (alle posizioni (1, 3)) rispetto al caso precedente, il che si traduce in un AP@5 più basso pari a 0.53.
A volte c’è la necessità di valutare la qualità dell’algoritmo non su una singola query ma su più query. A tale scopo, viene utilizzata la precisione media ponderata (MAP). Essa prende semplicemente la media di AP tra diverse query Q:
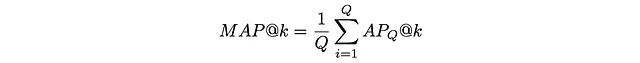
L’esempio qui sotto mostra come viene calcolata MAP per 3 query diverse:

RR (Reciprocal Rank) & MRR (Mean Reciprocal Rank)
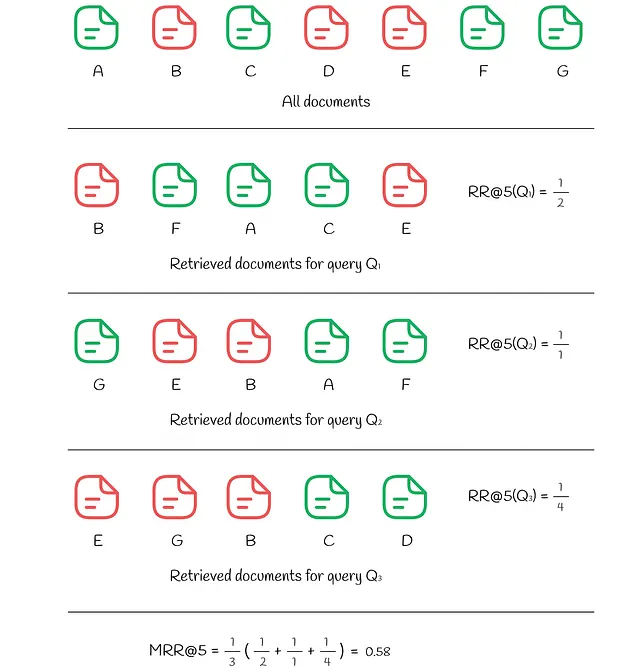
A volte gli utenti sono interessati solo al primo risultato rilevante. Il reciprocal rank è una metrica che restituisce un numero compreso tra 0 e 1 che indica quanto lontano dalla cima si trova il primo risultato rilevante: se il documento si trova nella posizione k, il valore di RR è 1 / k.
In modo simile ad AP e MAP, la mean reciprocal rank (MRR) misura la media di RR tra diverse query.

L’esempio qui sotto mostra come RR e MRR vengono calcolati per 3 interrogazioni:
Metriche orientate all’utente
Anche se le metriche di ranking tengono conto delle posizioni di ranking degli elementi e quindi sono una scelta preferita rispetto a quelle non classificate, hanno comunque un significativo svantaggio: non si tiene conto delle informazioni sul comportamento dell’utente.
Gli approcci orientati all’utente fanno determinate ipotesi sul comportamento dell’utente e, basandosi su di esse, producono metriche più adatte ai problemi di ranking.
DCG (Discounted Cumulative Gain) e nDCG (Normalized Discounted Cumulative Gain)
L’utilizzo della metrica DCG si basa sulla seguente ipotesi:
I documenti altamente rilevanti sono più utili quando appaiono in posizioni avanzate in una lista di risultati di un motore di ricerca (hanno ranghi più alti) – Wikipedia
Questa ipotesi rappresenta naturalmente come gli utenti valutano i risultati di ricerca più alti rispetto a quelli presentati più in basso.
Nel DCG, ogni documento viene assegnato un guadagno che indica quanto un determinato documento sia rilevante. Dato un rilevante vero Rᵢ (valore reale) per ogni elemento, esistono diversi modi per definire un guadagno. Uno dei più popolari è:
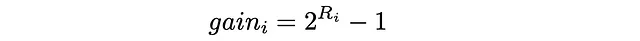
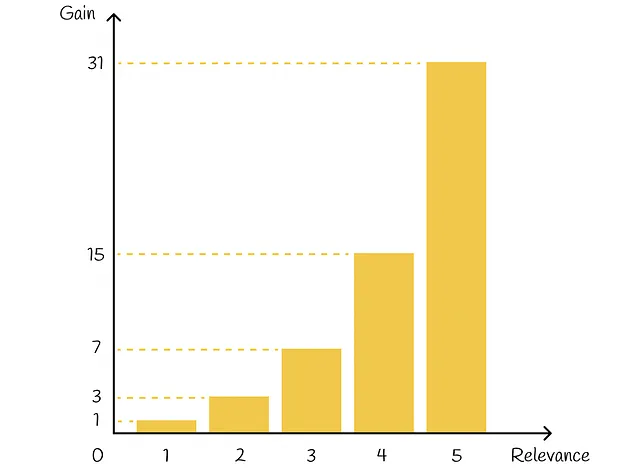
In pratica, l’esponente mette un forte enfasi sugli elementi rilevanti. Ad esempio, se una valutazione di un film viene assegnata un numero intero compreso tra 0 e 5, allora ogni film con una valutazione corrispondente avrà approssimativamente un’importanza doppia rispetto a un film con la valutazione ridotta di 1:
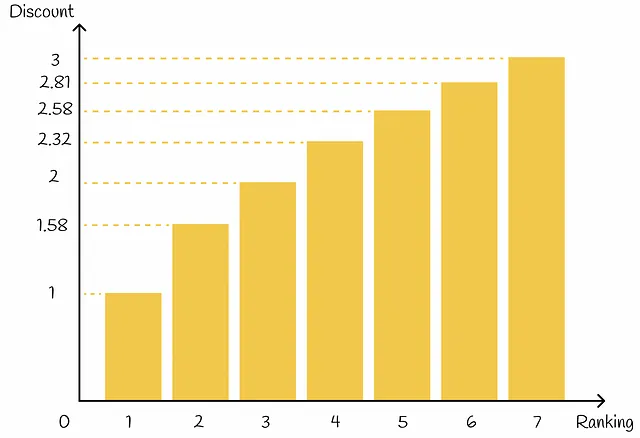
Oltre a ciò, in base alla sua posizione di ranking, ogni elemento riceve un valore di sconto: più alta è la posizione di ranking di un elemento, maggiore è lo sconto corrispondente. Lo sconto agisce come una penalità riducendo proporzionalmente il guadagno dell’elemento. In pratica, lo sconto di solito viene scelto come una funzione logaritmica di un indice di ranking:
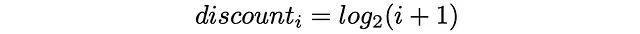
Infine, DCG@k è definito come la somma di un guadagno su uno sconto per tutti i primi k elementi recuperati:
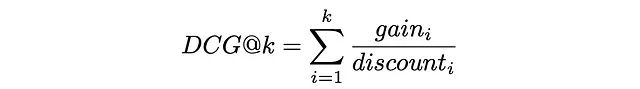
Sostituendo gainᵢ e discountᵢ con le formule sopra indicate, l’espressione assume la seguente forma:
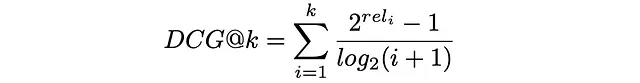
Per rendere la metrica DCG più interpretabile, di solito viene normalizzata dal valore massimo possibile di DCGₘₐₓ nel caso di un ranking perfetto in cui tutti gli elementi sono correttamente ordinati per rilevanza. La metrica risultante si chiama nDCG e assume valori compresi tra 0 e 1.
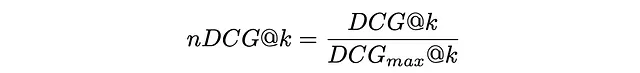
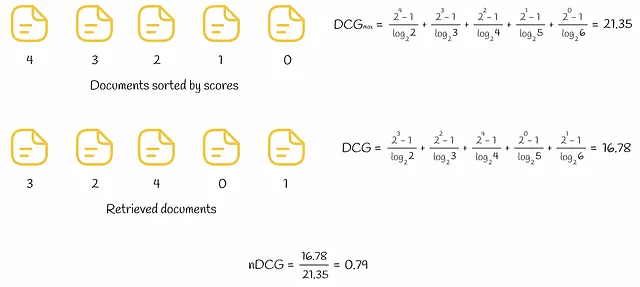
Nella figura sottostante viene mostrato un esempio di calcolo di DCG e nDCG per 5 documenti.
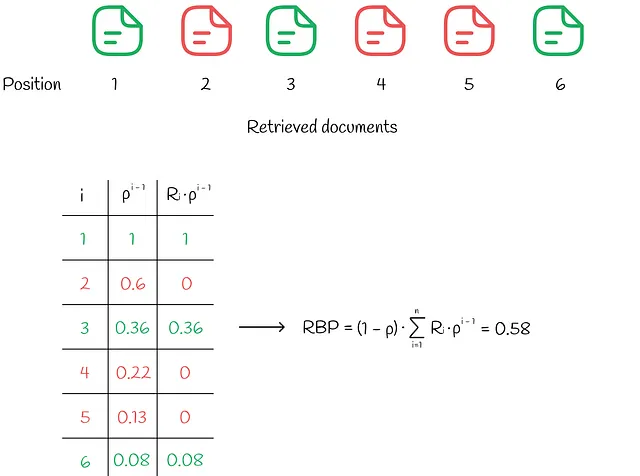
RBP (Rank-Biased Precision)
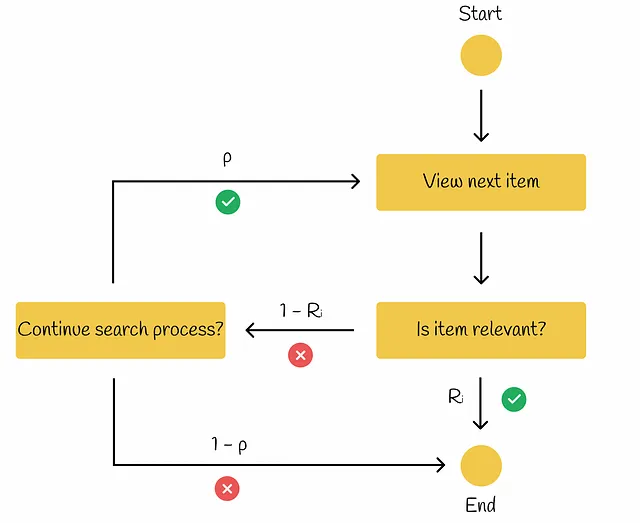
Nel flusso di lavoro RBP, l’utente non ha l’intenzione di esaminare ogni possibile elemento. Invece, procede sequenzialmente da un documento all’altro con una probabilità p e con una probabilità inversa 1 – p interrompe la procedura di ricerca al documento corrente. Ogni decisione di interruzione viene presa indipendentemente e non dipende dalla profondità della ricerca. Secondo la ricerca condotta, tale comportamento dell’utente è stato osservato in molti esperimenti. Sulla base delle informazioni da Rank-Biased Precision for Measurement of Retrieval Effectiveness, il flusso di lavoro può essere illustrato nel diagramma sottostante.
Il parametro p è chiamato persistence.
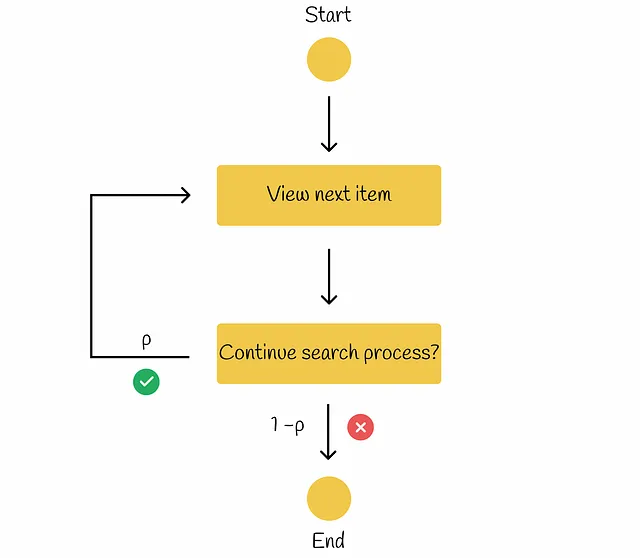
In questo paradigma, l’utente guarda sempre il primo documento, poi guarda il secondo documento con probabilità p, guarda il terzo documento con probabilità p² e così via. Alla fine, la probabilità di guardare il documento i diventa uguale a:
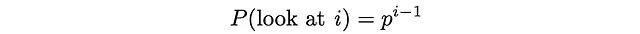
L’utente esamina il documento i solo quando il documento i è già stato guardato e la procedura di ricerca viene immediatamente interrotta con probabilità 1 – p.
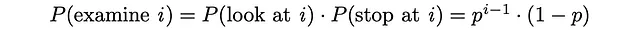
Dopo di ciò, è possibile stimare il numero atteso di documenti esaminati. Poiché 0 ≤ p ≤ 1, la serie sottostante è convergente e l’espressione può essere trasformata nel seguente formato:

Allo stesso modo, dato il rilevamento di rilevanza di ciascun documento Rᵢ, troviamo la rilevanza attesa del documento. Valori più alti di rilevanza attesa indicano che l’utente sarà più soddisfatto del documento che decide di esaminare.
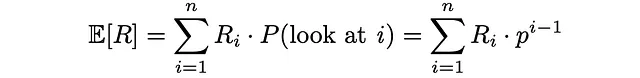
Infine, RPB viene calcolato come rapporto tra la rilevanza attesa del documento (utilità) e il numero atteso di documenti controllati:
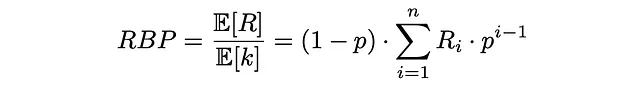
La formulazione RPB assicura che assuma valori compresi tra 0 e 1. Normalmente, i punteggi di rilevanza sono di tipo binario (1 se un documento è rilevante, 0 altrimenti) ma possono assumere anche valori reali compresi tra 0 e 1.
Il valore appropriato di p dovrebbe essere scelto in base a quanto gli utenti sono persistenti nel sistema. Valori piccoli di p (inferiori a 0,5) danno più importanza ai documenti classificati in cima alla classifica. Con valori più grandi di p, il peso sulle prime posizioni viene ridotto e viene distribuito tra le posizioni inferiori. A volte potrebbe essere difficile trovare un buon valore di persistenza p, quindi è meglio eseguire diversi esperimenti e scegliere p che funziona meglio.
ERR (Expected Reciprocal Rank)
Come suggerisce il nome, questa metrica misura la media del reciproco del rango su molte query.
Questo modello è simile a RPB ma con una piccola differenza: se l’elemento corrente è rilevante (Rᵢ) per l’utente, allora la procedura di ricerca termina. Altrimenti, se l’elemento non è rilevante (1 — Rᵢ), allora con probabilità p l’utente decide se desidera continuare il processo di ricerca. In tal caso, la ricerca procede al prossimo elemento. Altrimenti, l’utente termina la procedura di ricerca.
Secondo la presentazione sulla valutazione offline di Ilya Markov, cerchiamo la formula per il calcolo del ERR.
Prima di tutto, calcoliamo la probabilità che l’utente guardi il documento i. Fondamentalmente, significa che tutti i — 1 documenti precedenti non erano rilevanti e ad ogni iterazione, l’utente ha proseguito con probabilità p al prossimo elemento:
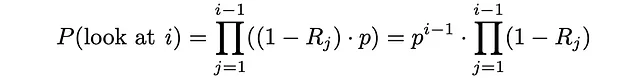
Se un utente si ferma al documento i, significa che questo documento è già stato guardato e con probabilità Rᵢ, l’utente ha deciso di interrompere la procedura di ricerca. La probabilità corrispondente a questo evento è effettivamente la stessa del reciproco del rango uguale a 1 / i.
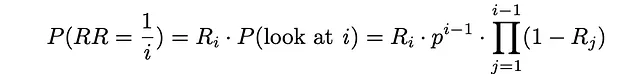
A partire da ora, utilizzando semplicemente la formula per il valore atteso, è possibile stimare il reciproco del rango atteso:
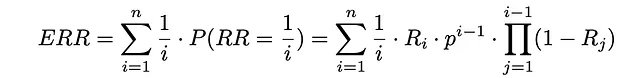
Di solito, il parametro p viene scelto vicino a 1.
Come nel caso di RBP, i valori di Rᵢ possono essere binari o reali nell’intervallo da 0 a 1. Un esempio di calcolo del ERR è mostrato nella figura seguente per un insieme di 6 documenti.
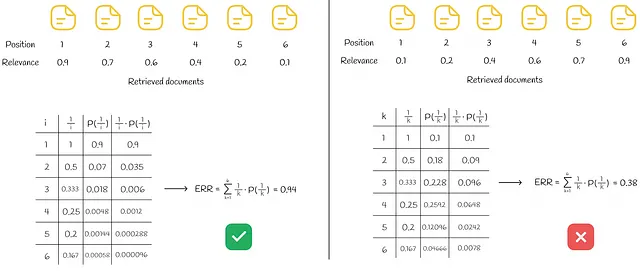
A sinistra, tutti i documenti recuperati sono ordinati in ordine decrescente di rilevanza ottenendo il miglior ERR possibile. Contrariamente alla situazione a destra, i documenti sono presentati in ordine crescente di rilevanza ottenendo il peggior ERR possibile.
La formula del ERR assume che tutti i punteggi di rilevanza siano nell’intervallo da 0 a 1. Nel caso in cui i punteggi di rilevanza iniziali siano dati al di fuori di tale intervallo, devono essere normalizzati. Uno dei modi più popolari per farlo è normalizzarli in modo esponenziale:
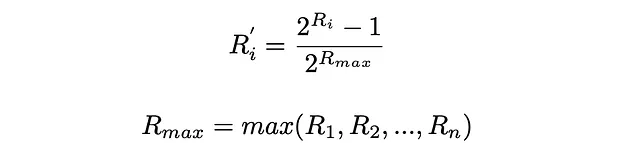
Conclusion
Abbiamo discusso tutte le principali metriche utilizzate per la valutazione della qualità nel reperimento delle informazioni. Le metriche orientate all’utente sono utilizzate più spesso perché riflettono il reale comportamento dell’utente. Inoltre, le metriche nDCG, BPR e ERR hanno un vantaggio rispetto alle altre metriche finora esaminate: lavorano con più livelli di rilevanza rendendole più versatili, rispetto a metriche come AP, MAP o MRR che sono progettate solo per livelli binari di rilevanza.
Purtroppo, tutte le metriche descritte sono o discontinue o piatte, rendendo il gradiente nei punti critici uguale a 0 o addirittura non definito. Di conseguenza, è difficile per la maggior parte degli algoritmi di ranking ottimizzare direttamente queste metriche. Tuttavia, molte ricerche sono state elaborate in questo ambito e molte euristiche avanzate sono emerse dietro le quinte degli algoritmi di ranking più popolari per risolvere questo problema.
Risorse
- Distanza di Kendall Tau | Wikipedia
- Precisione ponderata per il ranking per la misurazione dell’efficacia del recupero
- Guadagno cumulativo scontato | Wikipedia
- Incertezza nella precisione ponderata per il ranking
- Recupero delle informazioni, valutazione offline | Ilya Markov
Tutte le immagini, salvo diversa indicazione, sono dell’autore.