Integrare la distribuzione di Ray Serve con Kafka
Integrare Ray Serve con Kafka
Scopri come combinare semplicemente la distribuzione di Ray Serve con un consumatore asincrono di Kafka

Ray è un moderno framework open source che ti consente di creare applicazioni distribuite in Python con facilità. Puoi creare semplici pipeline di addestramento, fare l’ottimizzazione degli iperparametri, il processamento dei dati e il servizio dei modelli.
Ray ti permette di creare API di inferenza online con Ray Serve. Puoi facilmente combinare diversi modelli di machine learning e logica di business personalizzata in un’unica applicazione. Ray Serve crea automaticamente un’interfaccia HTTP per le tue distribuzioni, occupandosi di tolleranza agli errori e replicazione.
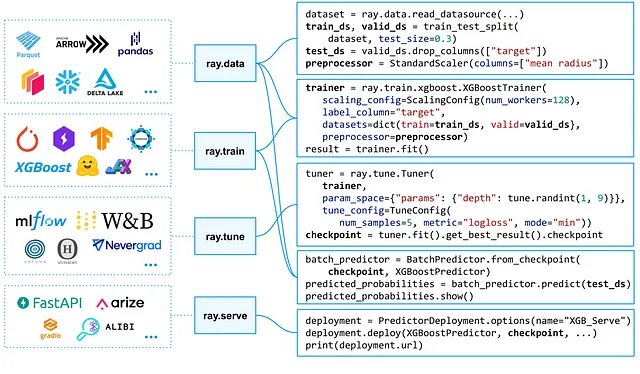
Ma c’è una cosa che Ray Serve non supporta al momento. Molte moderne applicazioni distribuite comunicano tramite Kafka, ma non c’è un modo out-of-the-box per collegare il servizio Ray Serve al topic di Kafka.
Ma non preoccuparti. Non ci vorrà troppo sforzo per insegnare a Ray Serve a comunicare con Kafka. Quindi, cominciamo.
- Guida completa alle metriche di valutazione del ranking
- Scoprire equazioni differenziali con reti neurali informate dalla fisica e regressione simbolica
- Incontra Mentat uno strumento di intelligenza artificiale che ti assiste in qualsiasi compito di programmazione dalla tua riga di comando, consentendo di coordinare modifiche su più file.
Prima di tutto dovremo preparare il nostro ambiente locale. Utilizzeremo un file docker-compose con i container Docker di Kafka e Kafdrop UI per avviare ed esplorare la nostra istanza locale di Kafka (quindi assumiamo che tu abbia Docker e Docker Compose installati). Inoltre, dovremo installare alcuni requisiti Python per completare il lavoro:
- Ray stesso
- aiokafka
Tutti i requisiti possono essere scaricati da questo link.
Ora creeremo un file ray-consumer.py con una distribuzione Ray che verrà servita con Ray Serve. Non entrerò nei dettagli sui concetti di Ray Serve, poiché puoi leggere a riguardo nella documentazione. Fondamentalmente, prende la solita classe Python e la converte in una distribuzione asincrona di Ray Serve con il decoratore @serve.deployment:




