Una Diffusione per Dominare la Diffusione Modulazione dei Modelli di Diffusione Pre-allenati per la Sintesi di Immagini Multimodali
Modulating Pre-trained Diffusion Models for Multimodal Image Synthesis


I modelli di intelligenza artificiale per la generazione di immagini hanno invaso il settore negli ultimi mesi. Probabilmente hai sentito parlare di midjourney, DALL-E, ControlNet o Stable dDiffusion. Questi modelli sono in grado di generare immagini fotorealistiche con prompt specifici, non importa quanto strano sia il prompt. Vuoi vedere Pikachu che corre su Marte? Fallo pure, chiedi a uno di questi modelli di farlo per te e otterrai il risultato.
I modelli di diffusione esistenti si basano su un’ampia quantità di dati di addestramento. Quando diciamo ampia, intendo davvero ampia. Ad esempio, Stable Diffusion è stato addestrato su oltre 2,5 miliardi di coppie immagine-didascalia. Quindi, se avevi intenzione di addestrare il tuo modello di diffusione a casa, potresti volerlo ripensare, poiché l’addestramento di questi modelli è estremamente costoso in termini di risorse computazionali.
D’altra parte, i modelli esistenti solitamente non sono condizionati o sono condizionati da un formato astratto come prompt di testo. Ciò significa che prendono in considerazione solo una singola cosa durante la generazione dell’immagine e non è possibile passare informazioni esterne come una mappa di segmentazione. Questa limitazione, combinata alla loro dipendenza da dataset di grandi dimensioni, significa che i modelli di generazione su larga scala sono limitati nella loro applicabilità in settori in cui non abbiamo un dataset di grandi dimensioni su cui addestrarli.
- Utilizza modelli di base di intelligenza artificiale generativa in modalità VPC senza connettività Internet utilizzando Amazon SageMaker JumpStart
- Nuovo corso tecnico approfondito Fondamenti di Generative AI su AWS
- Fantastico l’artista 3D si tuffa nel lavoro oceanico potenziato da AI questa settimana ‘Nello Studio NVIDIA
Un approccio per superare questa limitazione è quello di raffinare il modello pre-addestrato per un dominio specifico. Tuttavia, ciò richiede l’accesso ai parametri del modello e risorse computazionali significative per calcolare i gradienti per l’intero modello. Inoltre, il raffinamento di un modello completo limita la sua applicabilità e scalabilità, poiché sono necessari nuovi modelli di dimensioni complete per ogni nuovo dominio o combinazione di modalità. Inoltre, a causa delle dimensioni elevate di questi modelli, tendono a sovraadattarsi rapidamente al subset più piccolo di dati su cui vengono raffinati.
È anche possibile addestrare modelli da zero, condizionati sulla modalità scelta. Ma anche in questo caso siamo limitati dalla disponibilità dei dati di addestramento ed è estremamente costoso addestrare il modello da zero. D’altra parte, le persone hanno provato a guidare un modello pre-addestrato al momento dell’inferenza verso l’output desiderato. Utilizzano gradienti da un classificatore pre-addestrato o da una rete CLIP, ma questo approccio rallenta il campionamento del modello poiché aggiunge molti calcoli durante l’inferenza.
E se potessimo utilizzare qualsiasi modello esistente e adattarlo alla nostra condizione senza richiedere un processo estremamente costoso? E se non dovessimo affrontare il processo complicato e lungo di modificare la modalità di diffusione? Sarebbe comunque possibile condizionarlo? La risposta è sì, e permettimi di presentartelo.

L’approccio proposto, moduli di condizionamento multimodale (MCM), è un modulo che può essere integrato nelle reti di diffusione esistenti. Utilizza una piccola rete simile alla diffusione che viene addestrata a modulare le previsioni della rete di diffusione originale ad ogni passaggio di campionamento in modo che l’immagine generata segua il condizionamento fornito.
MCM non richiede che il modello di diffusione originale sia addestrato in alcun modo. L’unico addestramento viene fatto per la rete di modulazione, che è di piccola scala e non è costoso da addestrare. Questo approccio è computazionalmente efficiente e richiede meno risorse computazionali rispetto all’addestramento di una rete di diffusione da zero o al raffinamento di una rete di diffusione esistente, poiché non è necessario calcolare i gradienti per la grande rete di diffusione.
Inoltre, MCM si generalizza bene anche quando non abbiamo un ampio dataset di addestramento. Non rallenta il processo di inferenza poiché non ci sono gradienti che devono essere calcolati e l’unico overhead computazionale deriva dall’esecuzione della piccola rete di diffusione.
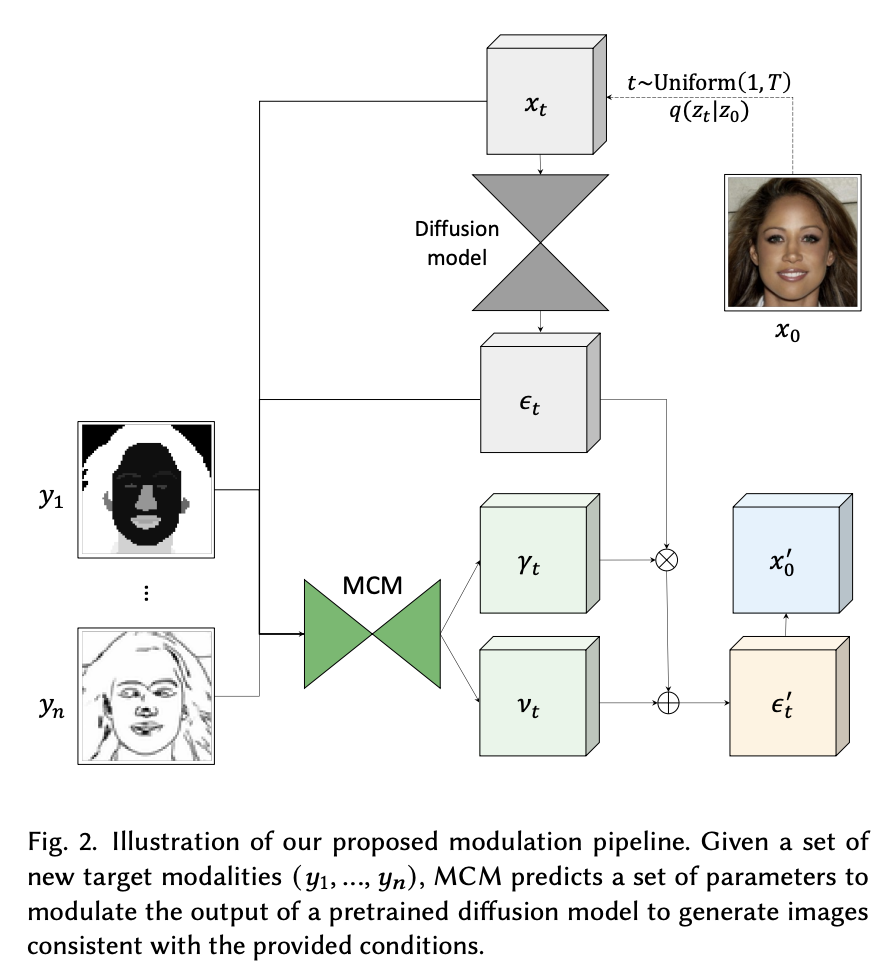
L’incorporazione del modulo di condizionamento multimodale aggiunge maggiore controllo alla generazione di immagini, consentendo di condizionare su modalità aggiuntive come una mappa di segmentazione o uno schizzo. Il principale contributo dell’approccio è l’introduzione dei moduli di condizionamento multimodale, un metodo per adattare modelli di diffusione pre-addestrati per la sintesi di immagini condizionate senza modificare i parametri del modello originale, ottenendo risultati di alta qualità e diversi, con costi inferiori e utilizzando meno memoria rispetto all’addestramento da zero o al fine-tuning di un grande modello.
Consulta il Documento e il Progetto. Tutto il merito di questa ricerca va ai ricercatori di questo progetto. Inoltre, non dimenticare di unirti alla nostra subreddit di intelligenza artificiale con più di 26.000 membri, al nostro canale Discord e alla nostra newsletter via email, dove condividiamo le ultime notizie sulla ricerca in ambito di intelligenza artificiale, progetti interessanti e altro ancora.
Svelare i segreti del deep learning con la piattaforma di spiegabilità di Tensorleap
L’articolo “One Diffusion to Rule Diffusion: Modulating Pre-trained Diffusion Models for Multimodal Image Synthesis” è apparso per la prima volta su MarkTechPost.






