Etica dell’IA generativa
Ethics of Generative AI
Considerazioni chiave nell’era del contenuto autonomo

Con tutto il trambusto che circonda l’intelligenza artificiale generativa (AI), ci sono sempre più domande senza risposta su come implementare in modo responsabile questa tecnologia trasformativa. Questo blog esaminerà le linee guida etiche dell’Unione Europea (UE) sull’AI e discuterà le considerazioni chiave per l’implementazione di un quadro etico sull’AI quando vengono utilizzati grandi modelli di linguaggio (LLM).
Linee guida etiche per un’AI affidabile
Il 8 aprile 2019, l’Unione Europea ha messo in pratica un quadro per l’uso etico e responsabile dell’intelligenza artificiale (AI). Il rapporto definisce tre principi guida per la costruzione di un’AI affidabile:
- Legale: L’AI deve rispettare lo stato di diritto e le normative locali.
- Etico: Il sistema AI deve essere etico e rispettare principi e valori etici.
- Robusto: Poiché l’AI può causare notevoli danni a grandi popolazioni in poco tempo, deve essere tecnicamente e socialmente robusta.
Per le società multinazionali, ciò solleva un’interessante questione su come applicare questo quadro oltre i confini geopolitici, poiché ciò che è considerato legale ed etico in una regione del mondo potrebbe non esserlo in un’altra. Molte aziende adottano le normative più rigorose e le applicano unilateralmente in tutte le aree geografiche. Tuttavia, un approccio “taglia unica” potrebbe non essere appropriato o accettabile.
Il quadro dell’UE può essere visto di seguito nella Figura 1.1.
- Come utilizzare la chiamata di funzione di OpenAI
- Questa newsletter sull’IA è tutto ciò di cui hai bisogno #57
- Il ciclo di feedback dell’IA mantenere la qualità della produzione del modello nell’era dei contenuti generati dall’IA
Figura 1.1: Quadro etico sull’AI dell’Unione Europea
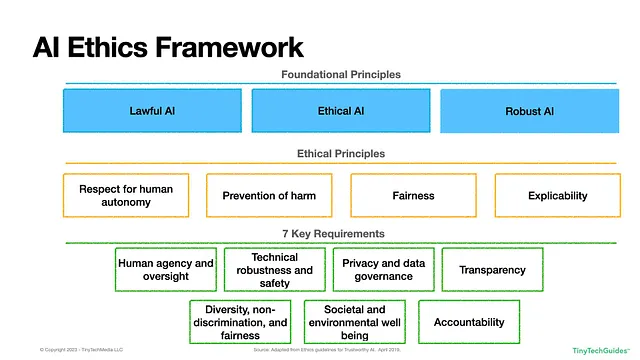
Sulla base dei tre principi fondamentali, si ottengono quattro principi etici e sette requisiti chiave. I principi etici includono:
- Rispetto dell’autonomia umana: Questo principio sottolinea che gli esseri umani dovrebbero mantenere il controllo e la libertà nelle loro interazioni con l’AI. “I sistemi AI non dovrebbero sottomettere, costringere, ingannare, manipolare o condizionare ingiustificatamente gli esseri umani.” [1] Fondamentalmente, l’AI dovrebbe supportare la partecipazione umana ai processi democratici. Abbiamo visto alcuni paesi implementare il “social scoring” sui propri cittadini, cosa che dovrebbe preoccupare.
- Prevenzione del danno: I sistemi AI non dovrebbero causare danni fisici, mentali o emotivi. Data la pervasività e l’impatto rapido dell’AI, è importante monitorare attentamente gli output dell’AI per evitare la manipolazione involontaria di cittadini, dipendenti, aziende, consumatori e governi “a causa di asimmetrie di potere o informazioni”. [2] Abbiamo visto i produttori di veicoli autonomi lottare con questo principio nel cosiddetto problema del carrello dell’AI. Naturalmente, questo non si limita ai sistemi robotici; le persone si affidano a ChatGPT per consigli medici e dato il suo atteggiamento a inventarsi cose, dobbiamo fare attenzione.
- Equità: I sistemi AI dovrebbero essere imparziali e non discriminatori, mirando a “una distribuzione equa dei benefici e dei costi”. [3] L’equità implica che le scelte umane non dovrebbero essere compromesse e che “gli specialisti AI dovrebbero bilanciare interessi e obiettivi contrastanti, rispettando il principio di proporzionalità tra mezzi e fini”. [4] Sulla superficie, sembra semplice, ma sapevi che esistono oltre venti definizioni matematiche di equità? [5]
- Spiegabilità: I sistemi AI devono essere trasparenti, verificabili, riproducibili e interpretabili. Se l’AI viene utilizzata per prendere una decisione che ti riguarda, hai il diritto di una spiegazione su come quella decisione è stata presa dall’algoritmo. Ad esempio, se ti viene negato un credito, l’operatore di quel sistema AI dovrebbe essere in grado di fornirti tutti i fattori che hanno contribuito alla decisione. Ciò può essere problematico quando vengono utilizzati modelli “black-box” – come le reti neurali e le reti avversarie generali (GAN) che sono alla base di molti LLM.
Questo ci porta ai sette requisiti:
- Agency e controllo umani: Fondamentalmente, questo requisito stabilisce che i sistemi di intelligenza artificiale dovrebbero rispettare i diritti umani e non dovrebbero operare interamente in modo autonomo. L’intelligenza artificiale dovrebbe migliorare, non sostituire, le decisioni umane. Dovrebbe esserci un processo per contestare le decisioni dell’intelligenza artificiale e un essere umano dovrebbe poter annullare le decisioni dell’intelligenza artificiale quando necessario. Questo suona bene, ma quando centinaia e migliaia di decisioni vengono prese automaticamente, come si può tracciare efficacemente tutte per assicurarsi che le cose non vadano storte?
- Robustezza tecnica e sicurezza: I sistemi di intelligenza artificiale devono essere sicuri, robusti e resilienti contro attori maligni e attacchi informatici. Dovrebbero fornire previsioni accurate, affidabili e riproducibili. Le organizzazioni devono dare priorità alla sicurezza informatica e avere piani di contingenza per gli attacchi e su come operare se il sistema va offline. Devono prestare particolare attenzione all’avvelenamento dei dati avversari, in cui attori malintenzionati alterano i dati di addestramento per causare previsioni errate.
- Privacy e governance: “I sistemi di intelligenza artificiale devono garantire la privacy e la protezione dei dati durante l’intero ciclo di vita di un sistema.” Gli sviluppatori dei sistemi di intelligenza artificiale devono mettere in atto misure di salvaguardia per evitare che dati o codice maligno vengano alimentati nel sistema. Le linee guida sottolineano anche che solo gli utenti autorizzati dovrebbero accedere ai dati di un individuo, che devono essere equi, imparziali e rispettare tutte le normative sulla privacy durante il loro ciclo di vita. Un’area su cui le organizzazioni devono riflettere è cosa costituisce un “utente autorizzato”? Hai visto il caso del Roomba che ha fatto delle foto a una donna sul water che poi sono finite su Facebook?
- Trasparenza: Le organizzazioni devono essere in grado di tracciare la genealogia dei dati, comprendendone la fonte, come sono stati raccolti, trasformati e utilizzati. Questo processo dovrebbe essere verificabile e le uscite dell’intelligenza artificiale dovrebbero essere spiegabili. Questo rappresenta una sfida per i data scientist perché spesso i modelli spiegabili sono meno accurati rispetto agli algoritmi “black-box”. Questo requisito afferma anche che le persone che interagiscono con l’intelligenza artificiale dovrebbero essere consapevoli di farlo, in altre parole, l’intelligenza artificiale non dovrebbe fingere di essere umana e dovrebbe essere chiaro che stiamo interagendo con un bot.
- Diversità, non discriminazione e equità: L’intelligenza artificiale dovrebbe trattare tutti i gruppi in modo equo, il che può essere più facile a dirsi che a farsi. Il requisito suggerisce che i designer dovrebbero includere persone provenienti da culture, esperienze e background diversi per contribuire a mitigare alcuni dei pregiudizi storici che permeano molte culture. L’intelligenza artificiale dovrebbe essere accessibile a tutti, indipendentemente dalla disabilità o da altri fattori. Questo suscita la domanda, cosa definisce un “gruppo”? Ci sono le classi protette ovvie – età, razza, colore, regione/credo, origine nazionale, sesso, età, disabilità fisica o mentale o stato di veterano. Ci sono altri fattori che dovrebbero essere considerati? Se sono un’azienda di assicurazioni, posso addebitare meno alle persone che hanno abitudini “più salutari” rispetto a quelle considerate “non sane”?
- Benessere sociale ed ambientale: I sistemi di intelligenza artificiale dovrebbero mirare a migliorare la società, promuovere la democrazia e creare sistemi ecologici e sostenibili. Solo perché puoi fare qualcosa, non significa che dovresti farlo. I dirigenti aziendali devono valutare attentamente gli impatti sociali potenziali dell’intelligenza artificiale. Quali sono i costi di addestramento dei tuoi modelli di intelligenza artificiale? Contrastano con le tue politiche ambientali, sociali e di governance aziendale (ESG)? Abbiamo già visto esempi in cui piattaforme di social media come TikTok diffondono contenuti dannosi ai bambini.
- Responsabilità: I designer dei sistemi di intelligenza artificiale dovrebbero essere responsabili dei loro sistemi, che dovrebbero essere verificabili e fornire un modo per coloro che sono influenzati dalle decisioni di rettificare e correggere eventuali decisioni ingiuste. I designer possono essere ritenuti responsabili per qualsiasi danno causato a individui o gruppi. Questo solleva una questione interessante: chi è responsabile se il sistema va fuori controllo? È il fornitore del modello di base o l’azienda che utilizza l’intelligenza artificiale generativa?
Anche se questi principi sembrano intuitivi a prima vista, c’è una “divergenza sostanziale riguardo a come questi principi vengono interpretati, perché vengono considerati importanti, a quale problema, dominio o attori si riferiscono e come dovrebbero essere implementati”.
Considerazioni sull’etica dell’IA per i LLM
Ora che comprendiamo le linee guida etiche dell’UE sull’IA, approfondiamo le considerazioni uniche per i LLM.
In un precedente articolo dal titolo GenAIOps: Evolving the MLOps Framework, ho delineato tre capacità chiave dell’intelligenza artificiale generativa e dei LLM, che includono:
● Generazione di contenuti: L’intelligenza artificiale generativa può generare contenuti di qualità simili a quelli umani, inclusi testi, audio, immagini/video e persino codice software. Tuttavia, si noti che il contenuto generato potrebbe non essere accurato dal punto di vista fattuale: spetta all’utente finale assicurarsi che il contenuto generato sia vero e non fuorviante. Gli sviluppatori devono assicurarsi che il codice generato sia privo di bug e virus.
● Riassunto dei contenuti e personalizzazione: La capacità di selezionare grandi corpora di documenti e riassumere rapidamente il contenuto è una caratteristica dell’IA generativa. Oltre a creare rapidamente riassunti di documenti, email e messaggi su Slack, l’IA generativa può personalizzare questi riassunti per individui specifici o personaggi.
● Scoperta dei contenuti e domande e risposte: Molte organizzazioni hanno una quantità significativa di contenuti e dati sparsi in diverse silos di dati. Molti fornitori di dati e analisi utilizzano LLM e IA generativa per scoprire e collegare automaticamente fonti disparate. Gli utenti finali possono quindi interrogare questi dati, in linguaggio semplice, per comprendere i punti chiave e approfondire i dettagli.
Dati questi vari vantaggi, quali fattori dobbiamo considerare quando creiamo un quadro etico per l’IA?
Agency umana e supervisione
Dato che l’IA generativa può produrre contenuti autonomamente, c’è il rischio di ridurre il coinvolgimento e la supervisione umana. Se ci pensi, quante email di spam ricevi al giorno? I team di marketing creano queste email, le caricano in un sistema di automazione del marketing e premendo il pulsante “Avvia”. Queste si eseguono automaticamente e spesso vengono dimenticate e rimangono in esecuzione in modo perpetuo.
Dato che l’IA generativa può produrre testo, immagini, audio, video e codice software a velocità vertiginose, quali misure possiamo adottare per assicurarci che ci sia un coinvolgimento umano, specialmente in applicazioni critiche? Se automatizziamo consulenze sanitarie, consulenze legali e altri tipi di contenuti più “sensibili”, le organizzazioni devono riflettere attentamente su come possono mantenere la loro agenzia e supervisione su questi sistemi. Le aziende devono mettere in atto misure di salvaguardia per garantire che le decisioni prese siano in linea con i valori e le intenzioni umane.
Robustezza tecnica e sicurezza
È ben noto che i modelli di IA generativa possono creare contenuti inaspettati o addirittura dannosi. Le aziende devono testare e convalidare rigorosamente i loro modelli di IA generativa per assicurarsi che siano affidabili e sicuri. Inoltre, se i contenuti generati sono errati, è necessario avere un meccanismo per gestire e correggere quell’output. Internet è pieno di contenuti orribili e divisivi e alcune aziende hanno assunto moderatori di contenuti per cercare di revisionare i contenuti sospetti, ma sembra un compito impossibile. Di recente, è stato riferito che alcuni di questi contenuti possono essere molto dannosi per la salute mentale delle persone (AP News – I moderatori di contenuti di Facebook in Kenya definiscono il lavoro come “tortura”. La loro causa potrebbe avere ripercussioni in tutto il mondo.)
Privacy e governance
I modelli di IA generativa sono stati addestrati su dati raccolti da Internet. Molti dei produttori di LLM non rivelano i dettagli precisi sui dati utilizzati per addestrare il modello. Ora, i modelli potrebbero essere stati addestrati su dati sensibili o privati che non dovrebbero essere pubblicamente disponibili. Basta guardare a Samsung che ha involontariamente divulgato dati proprietari (TechCrunch – Samsung vieta l’uso di strumenti di IA generativa come ChatGPT dopo la fuga di dati interna di aprile). Cosa succede se l’IA generativa genera output che includono o assomigliano a dati reali e privati? Secondo Bloomberg Law, OpenAI è stata recentemente citata in giudizio per diffamazione a causa di un’allucinazione di ChatGPT.
Possiamo certamente dire che le aziende devono avere una comprensione dettagliata delle fonti dei dati utilizzati per addestrare i modelli di IA generativa. Mentre affini e adatti i tuoi modelli utilizzando i tuoi dati, è in tuo potere rimuovere o anonimizzare quei dati. Tuttavia, potresti ancora essere a rischio se il fornitore del modello di base ha utilizzato dati inappropriati per l’addestramento del modello. In tal caso, chi è responsabile?
Trasparenza
Per loro natura, i modelli “black-box” sono difficili da interpretare. Infatti, molti di questi LLM hanno miliardi di parametri, quindi suggerirei che non siano interpretabili. Le aziende dovrebbero cercare la trasparenza e creare documentazione su come funziona il modello, le sue limitazioni, i rischi e i dati utilizzati per addestrarlo. Di nuovo, questo è più facile a dirsi che a farsi.
Diversità, non discriminazione e equità
In relazione a quanto sopra, se non addestrata e considerata correttamente, l’IA generativa può produrre output di parte o discriminatori. Le aziende possono fare del loro meglio per garantire che i dati siano diversi e rappresentativi, ma è una sfida difficile dato che molti fornitori di LLM non rivelano quali dati sono stati utilizzati per l’addestramento. Oltre ad adottare tutte le precauzioni possibili per comprendere i dati di addestramento utilizzati, i rischi e le limitazioni, le aziende devono mettere in atto un sistema di monitoraggio per individuare questi contenuti dannosi e un meccanismo per segnalare, prevenire la loro distribuzione e correggere se necessario.
Benessere sociale e ambientale
Per le aziende con iniziative ESG, addestrare LLM (linguistic models) richiede una quantità significativa di calcolo, il che significa che consuma molta energia elettrica. Man mano che inizi a implementare la capacità di intelligenza artificiale generativa, le organizzazioni devono essere consapevoli dell’impronta ambientale e cercare modi per ridurla. Ci sono diversi ricercatori che stanno cercando modi per ridurre la dimensione dei modelli e accelerare il processo di addestramento. Man mano che questa evoluzione avanza, le aziende dovrebbero almeno tener conto dell’impatto ambientale nei loro rapporti annuali.
Responsabilità
Questo sarà un settore attivo di contenzioso per diversi anni a venire. Chi è responsabile se l’intelligenza artificiale generativa produce contenuti dannosi o fuorvianti? Chi ne è legalmente responsabile? Ci sono diverse cause legali pendenti nel sistema giudiziario statunitense che stabiliranno le basi per altre controversie mentre le cose vanno avanti. Oltre ai contenuti dannosi, cosa succede se il tuo LLM produce un’opera derivata? Il tuo LLM è stato addestrato su materiale coperto da copyright o legalmente protetto? Se produce un derivato di dati, come affronteranno i tribunali questa situazione? Man mano che le aziende implementano la capacità di intelligenza artificiale generativa, dovrebbero mettere in atto controlli e meccanismi di feedback in modo che possa essere intrapresa un’azione correttiva.
Sommario
L’intelligenza artificiale generativa ha un enorme potenziale nel rivoluzionare il modo in cui le cose vengono fatte nel mondo, ma la sua rapida evoluzione porta con sé una miriade di dilemmi etici. Quando le aziende si avventurano nel campo dell’intelligenza artificiale generativa, è fondamentale navigare nella sua implementazione con una profonda comprensione delle linee guida etiche stabilite. In questo modo, le organizzazioni possono sfruttare il potere trasformativo dell’IA, garantendo al contempo il rispetto di standard etici e proteggendosi da possibili insidie e danni.
[1] Commissione europea. 2021. “Linee guida etiche per l’IA affidabile | Modellare il futuro digitale dell’Europa”. Digital-Strategy.ec.europa.eu. 8 marzo 2021. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
[2] Commissione europea. 2021. “Linee guida etiche per l’IA affidabile | Modellare il futuro digitale dell’Europa”. Digital-Strategy.ec.europa.eu. 8 marzo 2021. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
[3] Commissione europea. 2021. “Linee guida etiche per l’IA affidabile | Modellare il futuro digitale dell’Europa”. Digital-Strategy.ec.europa.eu. 8 marzo 2021. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
[4] Commissione europea. 2021. “Linee guida etiche per l’IA affidabile | Modellare il futuro digitale dell’Europa”. Digital-Strategy.ec.europa.eu. 8 marzo 2021. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
[5] Verma, Sahil, e Julia Rubin. 2018. “Definizioni di equità spiegate”. Atti del Workshop internazionale su Fairness del software – FairWare ’18. https://doi.org/10.1145/3194770.3194776.
[6] Commissione europea. 2021. “Linee guida etiche per l’IA affidabile | Modellare il futuro digitale dell’Europa”. Digital-Strategy.ec.europa.eu. 8 marzo 2021. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
[7] Jobin, Anna, Marcello Ienca e Effy Vayena. 2019. “Il panorama globale delle linee guida etiche sull’IA”. Nature Machine Intelligence 1 (9): 389-99. https://doi.org/10.1038/s42256-019-0088-2.